scrapy shell
一、scrapy shell
1、安装pip install Jupyter

2、在pycharm中的启动命令: scrapy shell
注:启动后关键字高亮显示
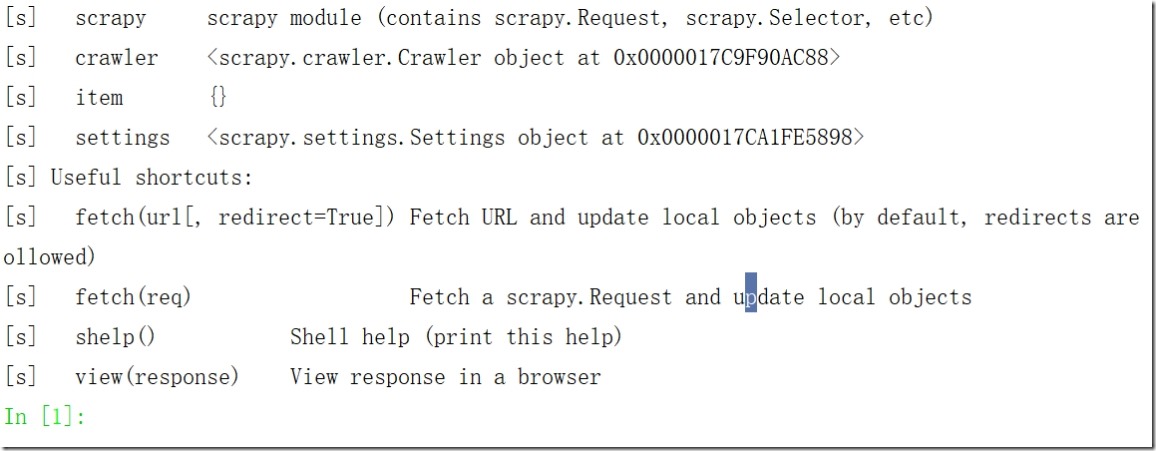
3、查看response
执行scrapy shell http://www.521609.com,查看response
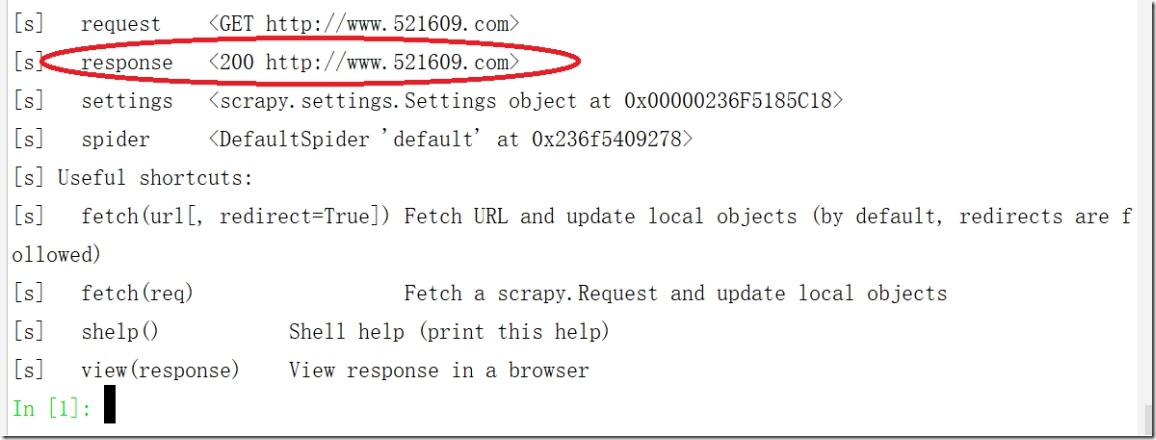
二、Scrapyshell 使用细节
注:调用:scrapy shell https://www.xxx.com/
1、Scrapyshell 终端是一个交互终端
我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据;
2、Jupyter
如果安装了 Jupyter ,Scrapy终端将使用 Jupyter (替代标准Python终端)。 Jupyter 终端与其他相比更为强大,提供智能的自动补全,高亮输出,及其他特性。推荐安装Jupyter;
3、response
当shell载入后,将得到一个包含response数据的本地 response 变量,输入 response.body将输出response的包体,输出 response.headers 可以看到response的响应头;
4、response.selector
输入 response.selector 时, 将获取到一个response 初始化的类 Selector 的对象,此时可以通过使用 response.selector.xpath()或response.selector.css() 来对 response 进行查询;
5、执行命令
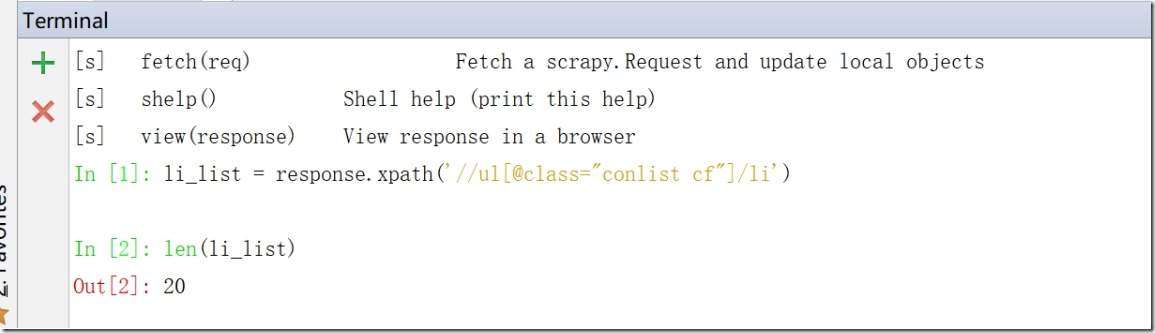
1)scrapy shell http://www.ichong123.com/pics/
2)执行:li_list = response.xpath('//ul[@class="conlist cf"]/li')
3)执行:len(li_list) 证明有数据
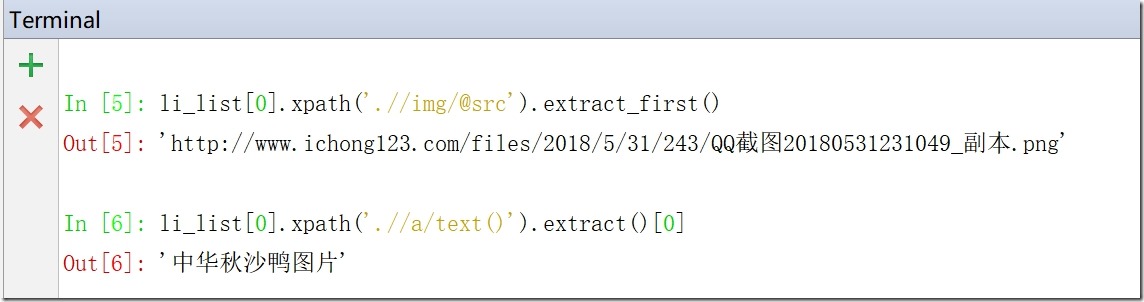
4)执行:li_list[0].xpath('.//img/@src').extract_first()得到图片
5)执行:li_list[0].xpath('.//a/text()').extract()[0]得到图片名字
以上是Scrapyshell 的基本使用,谢谢关注!!!
欢迎关注小婷儿的博客:
csdn:https://blog.csdn.net/u010986753
博客园:http://www.cnblogs.com/xxtalhr/
有问题请在博客下留言或加QQ群:483766429 或联系作者本人 QQ :87605025
OCP培训说明连接:https://mp.weixin.qq.com/s/2cymJ4xiBPtTaHu16HkiuA
OCM培训说明连接:https://mp.weixin.qq.com/s/7-R6Cz8RcJKduVv6YlAxJA
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
重要的事说三遍。。。。。。


scrapy shell的更多相关文章
- Scrapy shell调试网页的信息
通过scrapy shell "http://www.thinkive.cn:10000/zentaopms/www/index.php?m=user&f=login"
- scrapy shell 中文网站输出报错.记录.
UnicodeDecodeError: 'gbk' codec can't decode bytes in position 381-382: illegal multibyte sequence 上 ...
- 安装ipython,使用scrapy shell来验证xpath选择的结果 | How to install iPython and how does it work with Scrapy Shell
1. scrapy shell 是scrapy包的一个很好的交互性工具,目前我使用它主要用于验证xpath选择的结果.安装好了scrapy之后,就能够直接在cmd上操作scrapy shell了. 具 ...
- python爬虫scrapy之scrapy终端(Scrapy shell)
Scrapy终端是一个交互终端,供您在未启动spider的情况下尝试及调试您的爬取代码. 其本意是用来测试提取数据的代码,不过您可以将其作为正常的Python终端,在上面测试任何的Python代码. ...
- Scrapy Shell的使用
Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据. 如果安装了 IPyth ...
- 14.Scrapy Shell
Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据. 如果安装了 IPyth ...
- scrapy shell的作用
1.可以方便我们做一些数据提取的测试代码: 2.如果想要执行scrapy命令,那么毫无疑问,肯定是要先进入到scrapy所在的环境中: 3.如果想要读取某个项目的配置信息,那么应该先进入到这个项目中. ...
- Scrapy shell调试返回403错误
一.问题描述 有时候用scrapy shell来调试很方便,但是有些网站有防爬虫机制,所以使用scrapy shell会返回403,比如下面 C:\Users\fendo>scrapy shel ...
- 在Scrapy项目【内外】使用scrapy shell命令抓取 某网站首页的初步情况
Windows 10家庭中文版,Python 3.6.3,Scrapy 1.5.0, 时隔一月,再次玩Scrapy项目,希望这次可以玩的更进一步. 本文展示使用在 Scrapy项目内.项目外scrap ...
随机推荐
- jdk源码->集合->HashMap
一.hash算法 1.1 hash简介 hash,一般翻译为散列,就是把任意长度的输入,通过散列算法,变换成固定长度的输出,该输出值就是散列值,这种转换是一种压缩映射,也就是散列的空间小于输入的空间, ...
- 华中农业大学第五届程序设计大赛网络同步赛-G
G. Sequence Number In Linear algebra, we have learned the definition of inversion number: Assuming A ...
- 【学习笔记】--- 老男孩学Python,day6 字典
详细方法:http://www.runoob.com/python/python-dictionary.html 1. dict 用大括号{} 括起来. 内部使用key:value的形式来保存数据 { ...
- 使用PHPExcel实现数据批量导入到数据库
此例子只使用execel2003的.xls文档,若使用的是其他版本,可以保存格式为“Execel 97-2003 工作簿(*.xls)”即.xls文件类型即可! 功能说明:只能上传Excel2003类 ...
- drupal 去掉视图中字段默认的HTML标签
1.格式--设置 去掉复选框 2.具体字段:
- 工作记录(JS向textarea添加固定内容、通过固定字符将字符串分割为数组)
第一个是在 textarea 输入框中添加固定的内容. 代码如下: <textarea id="text" cols="30" rows="10 ...
- 正则匹配身份证有bug你知道么?
在开发中,我们需要验证用户的输入信息,多半采用正则验证,下面就是身份证证号的几种常用的正则表达式: var reg = /(^\d{15}$)|(^\d{18}$)|(^\d{17}(\d|X|x) ...
- 【Java入门提高篇】Day4 Java中的回调
又忙了一周,事情差不多解决了,终于有可以继续写我的博客了(各位看官久等了). 这次我们来谈一谈Java里的一个很有意思的东西——回调. 什么叫回调,一本正经的来讲,在计算机程序设计中,回调函数是指通过 ...
- 6.1 函数的返回值、匿名函数lambda、filter函数、map函数、reduce函数
函数的返回值: 函数一旦执行到 return,函数就会结束,并会返回return 后面的值,如果不使用显式使用return返回,会默认返回None . return None可以简写为 r ...
- LeetCode题解之Number of Segments in a String
1.题目描述 2.题目分析 找到字符串中的空格即可 3.代码 int countSegments(string s) { ){ ; } vector<string> v; ; i < ...