Spark项目之电商用户行为分析大数据平台之(二)CentOS7集群搭建
一、CentOS7集群搭建
1.1 准备3台centos7的虚拟机
IP及主机名规划如下:
192.168.123.110 spark1
192.168.123.111 spark2
192.168.123.112 spark3
1.2 修改IP地址
- [root@bigdata ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
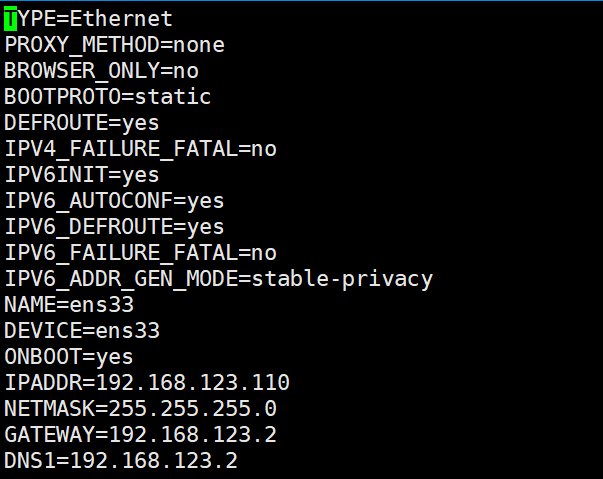
1.3 修改主机映射
- [root@bigdata ~]# vi /etc/hosts

1.4 修改主机名
三台机器分别把主机名修改为spark1、spark2、spark3
- [root@bigdata ~]# vi /etc/hostname

1.5 关闭防火墙
- //临时关闭
- systemctl stop firewalld
- //禁止开机启动
- systemctl disable firewalld

1.6 修改repo
- [root@bigdata ~]# cd /etc/yum.repos.d/
- [root@bigdata yum.repos.d]# wget http://mirrors.163.com/.help/CentOS7-Base-163.repo

如果还有其他源,可以暂且把他们重命名成其他扩展名,比如 CentOS-Base.repo.bak
- [root@bigdata yum.repos.d]# mv CentOS-Base.repo CentOS-Base.repo.bak
- [root@bigdata yum.repos.d]# mv CentOS7-Base-163.repo CentOS7-Base.repo
- [root@bigdata yum.repos.d]# yum clean all
- [root@bigdata yum.repos.d]# yum makecache
安装 epel 源
- [root@bigdata yum.repos.d]# yum install epel-release
- [root@bigdata yum.repos.d]# yum makecache
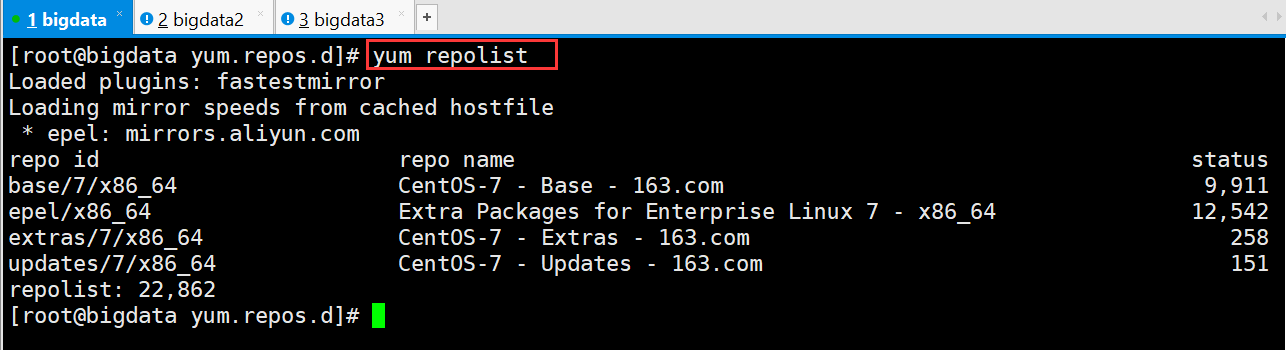
检查是否安装成功
- [root@bigdata yum.repos.d]# yum repolist
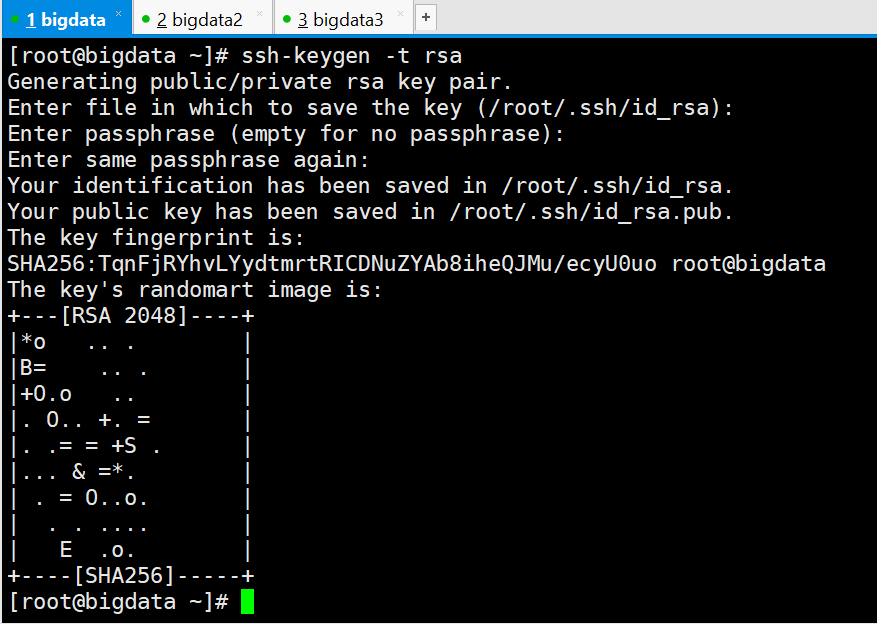
1.7 配置免密登录
- [root@bigdata ~]# ssh-keygen -t rsa
三次回车
将spark1上的公钥复制到文件authorized_keys中
- [root@spark1 ~]# cd .ssh
- [root@spark1 .ssh]# cat id_rsa.pub > authorized_keys
将spark2、和spark3机器上的公钥发送到spark1上
- [root@spark2 .ssh]# scp -r id_rsa.pub root@192.168.123.110:~/spark2.pub
- [root@spark3 .ssh]# scp -r id_rsa.pub root@192.168.123.110:~/spark3.pub
在spark1上将spark2、和spark3的公钥追加到authorized_keys中
- [root@bigdata ~]# cat spark2.pub > .ssh/authorized_keys
- [root@bigdata ~]# cat spark3.pub > .ssh/authorized_keys
在spark1上验证ssh免密登录是否设置成功

二、软件的安装
2.1 JDK的安装
上传并解压
- [root@spark1 ~]# tar -zxvf jdk-8u73-linux-x64.tar.gz -C apps/
修改环境变量
- [root@spark1 apps]# vi /etc/profile
- #JAVA
- export JAVA_HOME=/root/apps/jdk1..0_73
- export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
- export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH:$HOME/bin
保存并使其生效
- [root@spark1 apps]# source /etc/profile
检查

Spark项目之电商用户行为分析大数据平台之(二)CentOS7集群搭建的更多相关文章
- Spark项目之电商用户行为分析大数据平台之(三)大数据集群的搭建
Zookeeper集群搭建 http://www.cnblogs.com/qingyunzong/p/8619184.html Hadoop集群搭建 http://www.cnblogs.com/qi ...
- Spark项目之电商用户行为分析大数据平台之(六)用户访问session分析模块介绍
一.对用户访问session进行分析 1.可以根据使用者指定的某些条件,筛选出指定的一些用户(有特定年龄.职业.城市): 2.对这些用户在指定日期范围内发起的session,进行聚合统计,比如,统计出 ...
- Spark项目之电商用户行为分析大数据平台之(一)项目介绍
一.项目概述 本项目主要用于互联网电商企业中,使用Spark技术开发的大数据统计分析平台,对电商网站的各种用户行为(访问行为.购物行为.广告点击行为等)进行复杂的分析.用统计分析出来的数据,辅助公司中 ...
- Spark项目之电商用户行为分析大数据平台之(七)数据调研--基本数据结构介绍
一.user_visit_action(Hive表) 1.1 表的结构 date:日期,代表这个用户点击行为是在哪一天发生的user_id:代表这个点击行为是哪一个用户执行的session_id :唯 ...
- Spark项目之电商用户行为分析大数据平台之(十二)Spark上下文构建及模拟数据生成
一.模拟生成数据 package com.bw.test; import java.util.ArrayList; import java.util.Arrays; import java.util. ...
- Spark项目之电商用户行为分析大数据平台之(十)IDEA项目搭建及工具类介绍
一.创建Maven项目 创建项目,名称为LogAnalysis 二.常用工具类 2.1 配置管理组建 ConfigurationManager.java import java.io.InputStr ...
- Spark项目之电商用户行为分析大数据平台之(九)表的设计
一.概述 数据设计,往往包含两个环节: 第一个:就是我们的上游数据,就是数据调研环节看到的项目基于的基础数据,是否要针对其开发一些Hive ETL,对数据进行进一步的处理和转换,从而让我们能够更加方便 ...
- Spark项目之电商用户行为分析大数据平台之(八)需求分析
1.按条件筛选session 搜索过某些关键词的用户.访问时间在某个时间段内的用户.年龄在某个范围内的用户.职业在某个范围内的用户.所在某个城市的用户,发起的session.找到对应的这些用户的ses ...
- Spark项目之电商用户行为分析大数据平台之(十一)JSON及FASTJSON
一.概述 JSON的全称是”JavaScript Object Notation”,意思是JavaScript对象表示法,它是一种基于文本,独立于语言的轻量级数据交换格式.XML也是一种数据交换格式, ...
- Spark项目之电商用户行为分析大数据平台之(五)实时数据采集
随机推荐
- PowerDesigner Constraint name uniqueness 错误
使用PowerDesigner生成数据库脚本时报 Constraint name uniqueness 错误: 双击每行错误,发现外键引用的名字有重复的: 惯性去网上找解决办法,找到的主要是两个方法: ...
- 用MSBuild和Jenkins搭建持续集成环境(1)[收集]
你或其他人刚刚写完了一段代码,提交到项目的版本仓库里面.但等一下,如果新提交的代码把构建搞坏了怎么办?万一出现编译错误,或者有的测试失败了,或者代码不符合质量标准所要求的底限,你该怎么办? 最不靠谱的 ...
- python基础训练题2-元组,字典
1,判断值在元组中 >>> a = ( 1, 2, 3, 4, 10 ) >>> 10 in a True >>> ' in a False 2, ...
- Object of type 'ListSerializer' is not JSON serializable “listserializer”类型的对象不可JSON序列化
Object of type 'ListSerializer' is not JSON serializable “listserializer”类型的对象不可JSON序列化 一般原因为 序列化的对象 ...
- CentOS 修改用户密码
CentOS 修改用户密码 1.普通用户 ①获取超级用户root权限 命令:su 或者 su- 或者 su -root ②输入命令: passwd 用户名 ③输入新密码 2.超级用户 ①打开syste ...
- element-ui Steps步骤条组件源码分析整理笔记(九)
Steps步骤条组件源码: steps.vue <template> <!--设置 simple 可应用简洁风格,该条件下 align-center / description / ...
- equals与hashcode区别
哈希码: hashCode的作用是用来获取哈希码,也可以称作散列码.实际返回值为一个int型数据.用于确定对象在哈希表中的位置. Object中有hashcode方法,也就意味着所有的类都有has ...
- Linux nohup命令应用简介--让Linux的进程不受终端影响
nohup命令应用简介--让Linux的进程不受终端影响 by:授客 QQ:1033553122 #开启ping进程 [root@localhost ~]# ping localhost & ...
- ESLint 使用方法
一.全局安装 npm install -g eslint 二.生成配置文件 在项目根目录执行init,生成.eslintrc文件.在init时,要求根目录存在package.json.当然也可以直接复 ...
- MySQL: Building the best INDEX for a given SELECT
Table of Contents The ProblemAlgorithmDigressionFirst, some examplesAlgorithm, Step 1 (WHERE "c ...