大数据开发实战:HDFS和MapReduce优缺点分析
一、 HDFS和MapReduce优缺点
1、HDFS的优势
HDFS的英文全称是 Hadoop Distributed File System,即Hadoop分布式文件系统,它是Hadoop的核心子项目。实际上,Hadoop中有一个综合性的文件系统抽象,它提供了文件系统实现的各类接口,
而HDFS只是这个抽象文件系统
的一种实现,但HDFS是各种抽象接口中应用最为广泛和最广为人知的一个。
HDFS被设计成适合运行在通用和廉价硬件上的分布式文件系统。它和现有的分布式文件系统有很多共同点,但他和其它分布式文件系统的区别也是明显的。HDFS是基于流式数据模式访问和处理超大文件的需求而开发的,
其主要特点如下:
1、处理超大文件
这里的超大文件通常指的是GB、TB甚至PB大小的文件。通过将超大文件拆分为小的HDFS和MapReduce优缺点Split,并分配给数以百计、千计甚至万计的的节点,Hadoop可以很容易地扩展并处理这些超大文件。
2、运行于廉价的商用机器集群上
HDFS设计对硬件需求比较低,只需运行在低廉的的商用机器集群上,而无须使用昂贵的高可用机器。在设计HDFS时要充分考虑数据的可靠性、安全性和高可用性。
3、高容错性和高可靠性
HDFS设计中就考虑到低廉硬件的不可靠性,一份数据会自动保存多个副本(具体可用设置,通常三个副本),通过增加副本的数量来保证它的容错性。如果某一个副本丢失,HDFS会自动复制其它机器上的副本。
当然,有可能多个副本都会出现问题,但是HDFS保存的时候会自动跨节点和跨机架,因此这种概率非常低,HDFS同时也提供了各种副本放置策略来满足不同级别的容错需求。
4、流式的访问数据
HDFS的设计建立在更多低相应“一次写入,多次读写”任务的基础上,这意味着一个数据集一旦有数据源生成,就会被复制分发到不同的存储节点中,然后响应各种各种的数据分析任务需求。在多数情况下,分析任务都
会涉及数据集的大部分数据,也就是说,对HDFS来说,请求读取整个数据集比请求读取单条记录会更加高效。
2、HDFS的局限
HDFS的上述种种特点非常适合于大数据量的批处理,但是对于一些特点问题不但没有优势,而且有一定的局限性,主要表现以下几个方面:
1、不适合低延迟数据访问
如果要处理一些用户要求时间比较短的低延迟应用请求(比如毫秒级、秒级的响应时间),则HDFS不适合。HDFS是为了处理大型数据集而设计的,主要是为了达到高的数据吞吐量而设计的,
延迟时间通常是在分钟乃至小时级别。
对于那些有低延迟要求的应用程序,HBase是一个更好的选择,尤其是对于海量数据集进行访问要求毫秒级响应的情况,单HBase的设计是对单行或少量数据集的访问,对HBase的访问必须提供主键或主键范围。
2、无法高效存储大量小文件
3、不支持多用户写入和随机文件修改
在HDFS的一个文件中只有一个写入者,而且写操作只能在文件末尾完成,即只能执行追加操作。
3、MapReduce 的优势
MapReduce是Google公司的核心计算模型,它将运行于大规模集群上复杂并行计算过程高度抽象为两个函数:Map和Reduce。MapReduce目前非常流行,因为它有如下特点:
1、MapReduce易于理解:简单地实现一些接口,就可以完成一个分布式程序,而且这个分布式程序还可以分布到大量廉价的PC机器运行。也就是说,写一个分布式程序,跟写一个简单的串行程序是一模一样的。MapReduce
易于编程的背后是MapReduce通过抽象模型和计算框架把需要做什么(What need to do)与具体怎么做(How to do)分开了,为程序员提供了一个抽象和高层的编程接口和框架,程序员仅需关心其应用层的具体计算问题,
仅需要编写少量的应用本身计算问题的程序代码;如何具体完成这个并行计算任务所相关的诸多系统层细节被隐藏起来,交给计算框架去处理-----从分布代码的执行到大到数千、小到输几个节点集群的自动调度使用。
2、良好的扩展性
当计算机资源不能得到满足的时候,可以通过简单的增加机器来扩展它的计算能力。多项研究发现,基于MapReduce的计算性可以随节点数目增长保持近似于线性的增长,这个特点是MapReduce处理海量数据的关键,通过
将计算节点增至几百或者几千可以很容易地处理数百TB甚至PB级别的离线数据。
3、高容错性
MapReduce设计的初衷就是使程序能部署在廉价的PC机器上,这就要求它具有很高的容错性。比如,其中一台机器宕机了,它可以把上面的计算任务转移到另一个节点上运行,不至于这个任务运行失败,
而且这个过程不需要人工参与,完全是由Hadoop内部完成的。
4、MapReduce的局限
MapReduce虽然有很多的优势,但是也有它不擅长的。这里的“不擅长”,不代表不能做,而是在有些场景下实现的效果差,并不适合用MapReduce来处理,主要表现在以下结果方面:
1、实时计算:MapReduce无法像Oracle或MySQL那样在毫米或秒级内返回结果,如果需要大数据量的毫秒级响应,可以考虑使用HBase.
2、流计算:流计算的输入数据是动态的,而MapReduce的输入数据是静态的,不能动态变化,这是因为MapReduce自身的设计特点决定了数据源必须是静态的。如果需要处理流式数据可以用Storm,Spark Steaming、Flink
等流计算框架。
3、DGA(有向图)计算:多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce并不是不能做,而是使用后,每个MapReduce作业的输出结果都会写入磁盘,会造成大量的词频IO
导致性能非常低下,此时可以考虑用Spark等迭代计算框架。
二、HDFS和MapReduce基本架构
HDFS和MapReduce是Hadoop的两大核心,它们分工也非常明确,HDFS负责分布式存储,而MapReduce负责分布式计算。
1、HDFS采用了主从(Master/Slave)的结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的,其中NameNode作为主服务器,管理文件系统的命名空间(即文件有几块,分别存储在哪个节点上等)和客户端
对文件的访问操作;
2、集群中DataNode管理存储的数据。HDFS允许用户以文件的形式存储数据。从内部来看,文件被分成若干数据块,而且这若干个数据块存放在一组DataNode上。
3、NameNode执行文件系统的命名空间操作,比如打开、关闭、重命名文件或目录等。它也负责数据块到具体DataNode的映射。
4、DataNode负责处理文件系统客户端的文件读写请求,并在NameNode的统一调度下进行数据块的创建、删除和复制工作。HDFS的体系结构如下:
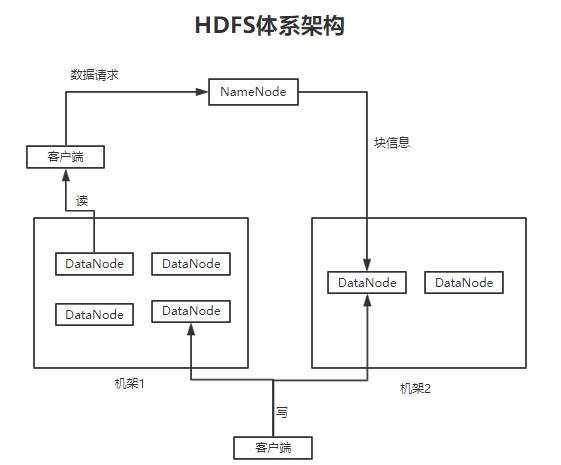
MapReduce也是采用Master/Slave的主从架构,MapReduce包含4个组成部分,分别为Client、JobTracker、TaskTracker和Task,其架构图如下:

1、Client
每个Job都会在用户端通过Client类将应用程序以及配置参数Configuration打包成JAR文件存储在HDFS中,并把路径提交到JobTracker的Master服务,然后由Master创建每一个Task(即Map Task和 Reduce Task)将它们分发
到各个TaskTracker服务中去执行。
2、JobTracker
JobTracker负责资源监控和作业调度。JobTracker负责监控所有TaskTracker与Job的健康状况,一旦发现失败,就将相应的任务转移到其它节点;同时,JobTracker会跟踪任务的执行进度、资源使用量等信息,并将这些信息
告诉任务调度器,而任务调度器会在资源出现空闲时,选择合适的任务使用这些资源。在Hadoop中,任务调度器是一个可插拔的模块,用户可以根据自己的需求设计相应的调度器。
3、TaskTracker
TaskTracker会周期性地通过Heartheat将本节点上的资源使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)。TaskTracker使用“slot”来衡量划分
本节点上资源量。"slot"代表单位的计算资源(CPU、内存能),一个Task获取到一个slot后才有机会运行,而Hadoop调度器的作用就是讲各个TaskTracker上空闲的slot分配给Task使用。slot分为Map slot和Reduce slot两种,分别
供Map Task和Reduce Task使用。TaskTracker通过slot的数目(可配置参数)限定Task的并发度。
4、Task
Task分为Map Task和Reduce Task两种,均有TaskTracker启动。HDFS以固定大小的block为基本单位存储数据,而对于MapReduce而言,其处理单位是split。
从上面的描述可以看出,HFDS和MapReduce共同组成了HDFS体系结构的核心,HDFS在集群上实现了分布式文件系统,MapReduce则在集群上实现了分布式计算和任务处理。HDFS在MapReduce任务处理过程中提供了对文件操作
和存储等的支持。而MapReduce在HDFS的基础上实现任务的分发、跟踪和执行等工作,并收集结果,两种相互作用,完成了Hadoop分布式集群的主要任务。
参考资料:《离线和实时大数据开发实战》
大数据开发实战:HDFS和MapReduce优缺点分析的更多相关文章
- 大数据开发实战:MapReduce内部原理实践
下面结合具体的例子详述MapReduce的工作原理和过程. 以统计一个大文件中各个单词的出现次数为例来讲述,假设本文用到输入文件有以下两个: 文件1: big data offline data on ...
- 大数据开发实战:Spark Streaming流计算开发
1.背景介绍 Storm以及离线数据平台的MapReduce和Hive构成了Hadoop生态对实时和离线数据处理的一套完整处理解决方案.除了此套解决方案之外,还有一种非常流行的而且完整的离线和 实时数 ...
- 大数据开发实战:离线大数据处理的主要技术--Hive,概念,SQL,Hive数据库
1.Hive出现背景 Hive是Facebook开发并贡献给Hadoop开源社区的.它是建立在Hadoop体系架构上的一层SQL抽象,使得数据相关人员使用他们最为熟悉的SQL语言就可以进行海量数据的处 ...
- 大数据开发实战:Stream SQL实时开发二
1.介绍 本节主要利用Stream SQL进行实时开发实战,回顾Beam的API和Hadoop MapReduce的API,会发现Google将实际业务对数据的各种操作进行了抽象,多变的数据需求抽象为 ...
- 大数据开发实战:Storm流计算开发
Storm是一个分布式.高容错.高可靠性的实时计算系统,它对于实时计算的意义相当于Hadoop对于批处理的意义.Hadoop提供了Map和Reduce原语.同样,Storm也对数据的实时处理提供了简单 ...
- 大数据开发实战:Hive优化实战2-大表join小表优化
4.大表join小表优化 和join相关的优化主要分为mapjoin可以解决的优化(即大表join小表)和mapjoin无法解决的优化(即大表join大表),前者相对容易解决,后者较难,比较麻烦. 首 ...
- 大数据开发实战:Hive优化实战1-数据倾斜及join无关的优化
Hive SQL的各种优化方法基本 都和数据倾斜密切相关. Hive的优化分为join相关的优化和join无关的优化,从项目的实际来说,join相关的优化占了Hive优化的大部分内容,而join相关的 ...
- 大数据开发实战:Hive表DDL和DML
1.Hive 表 DDL 1.1.创建表 Hive中创建表的完整语法如下: CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [ (col_nam ...
- 大数据开发实战:Stream SQL实时开发三
4.聚合操作 4.1.group by 操作 group by操作是实际业务场景(如实时报表.实时大屏等)中使用最为频繁的操作.通常实时聚合的主要源头数据流不会包含丰富的上下文信息,而是经常需要实时关 ...
随机推荐
- Java程序读取Properties文件
一.如果将properties文件保存在src目录下 1.读取文件代码如下: /** * 配置文件为settings.properties * YourClassName对应你类的名字 * / pri ...
- Android so文件进阶 <一>
0x00 前言 最近一段时间在弄android方面的东西,今天有人发了张截图,问:在要dump多大的内存? 一时之间我竟然想不起来ELF文件的哪个字段表示的是文件大小,虽然最后给出了解决方法,I ...
- Java NIO系列教程(十) Java NIO DatagramChannel
Java NIO中的DatagramChannel是一个能收发UDP包的通道.因为UDP是无连接的网络协议,所以不能像其它通道那样读取和写入.它发送和接收的是数据包. 打开 DatagramChann ...
- git将本地项目发布到远端
如果本地有个项目myapp之前没在git上,想上传到git仓库保存,操作如下 1. 在gitee或者github上创建一个新仓库 仓库 2. 在控制台进入本地已有的项目文件夹下 cd myapp 3. ...
- .NET世界的包管理器——Nuget
NugetServer 使用指南 为什么要使用Nuget 在我们的项目, 存在着一些公共Dll, 这些Dll被大量的项目所引用.同时这些公共dll也同时在进行版本升级, 由于缺乏版本管理,这些Dll会 ...
- HTML 常用标记
一 常用标签  : -- 表示空格 也可以在设计页面中按 ctrl+shift+space <br> 或<br /&g ...
- arm裸板驱动总结(makefile+lds链接脚本+裸板调试)
在裸板2440中,当我们使用nand启动时,2440会自动将前4k字节复制到内部sram中,如下图所示: 然而此时的SDRAM.nandflash的控制时序等都还没初始化,所以我们就只能使用前0~40 ...
- Redis简介及应用场景
一丶Redis介绍 Redis是一个开源的 key—value型 单线程 数据库,支持string.list.set.zset和hash类型数据. 默认端口:6379 默认数据库数量:16 二.优点: ...
- git使用基本教程
黑马的视频,以前看过廖雪峰的git,总是学不懂,这次终于看会了,结合视频更佳,红色字是重点. 基于linux下面git百度云视频教程:http://pan.baidu.com/s/1bpk472B 密 ...
- java - 线程等待与唤醒
Java多线程系列--“基础篇”05之 线程等待与唤醒 概要 本章,会对线程等待/唤醒方法进行介绍.涉及到的内容包括:1. wait(), notify(), notifyAll()等方法介绍2. w ...