jemalloc总结
jemalloc支持SMP系统和并发多线程,多线程的支持是依赖于多个‘arenas’,并且一个线程第一次调用内存mallocer,与其相关联的是一个特殊的arena。
线程分配arena只有三种可能的算法:
- TLS启用的情况下就是线程ID的哈希值
- TLS不可用并定义MALLOC_BALANCE的情况下通过内置线性同余随机数生成器
- 使用传统的循环算法
对于后两种情况,线程的整个生命周期中线程和arena的关联不会一直保持不变。
核心概念
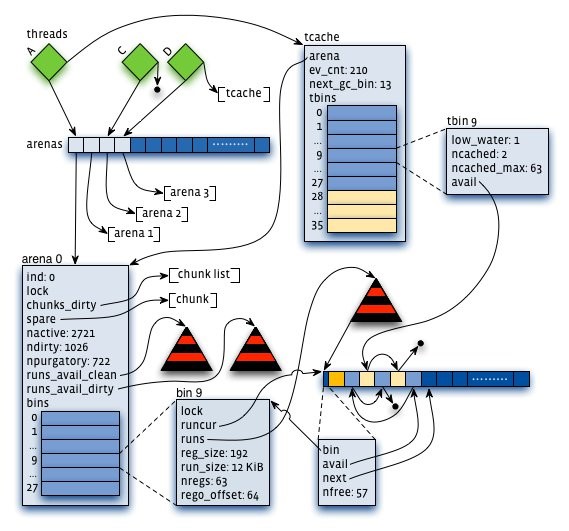
- arena:jemalloc的核心分配管理区域,对于多核系统,会默认分配4*cores的Arena,线程第一次分配small和large对象采用轮询的方式来选择相应的arena来进行内存分配(以后固定)。
struct arena_s {
...
/* 当前arena管理的dirty chunks */
arena_chunk_tree_t chunks_dirty;
/* arena缓存的最近释放的chunk, 每个arena一个spare chunk */
arena_chunk_t *spare;
/* 当前arena中正在使用的page数. */
size_t nactive;
/*当前arana中未使用的dirty page数*/
size_t ndirty;
/* 需要清理的page的大概数目 */
size_t npurgatory;
/* 当前arena可获得的runs构成的红黑树, */
/* 红黑树按大小/地址顺序进行排列。 分配run时采用first-best-fit策略*/
arena_avail_tree_t runs_avail;
/* bins储存不同大小size的内存区域 */
arena_bin_t bins[NBINS];
};
- chunk:具体进行内存分配的区域,目前的默认大小是4M。chunk以page(默认为4K)为单位进行管理,每个chunk的前几个page(默认是6个)用于存储后面所有page的状态,比如是否待分配还是已经分配;而后面的所有page则用于进行实际的分配。
/* Arena chunk header. */
struct arena_chunk_s {
/* 管理当前chunk的Arena */
arena_t *arena;
/* 链接到所属arena的dirty chunks树的节点*/
rb_node(arena_chunk_t) dirty_link;
/* 脏页数 */
size_t ndirty;
/* 空闲run数 Number of available runs. */
size_t nruns_avail;
/* 相邻的run数,清理的时候可以合并的run */
size_t nruns_adjac;
/* 用来跟踪chunk使用状况的关于page的map, 它的下标对应于run在chunk中的位置,通过加map_bias不跟踪chunk 头部的信息
* 通过加map_bias不跟踪chunk 头部的信息
*/
arena_chunk_map_t map[1]; /* Dynamically sized. */
};
- bin:与ptmalloc的bin功能类似
struct arena_bin_s{
// 作用域当前数据结构的锁*
malloc_mutex_t lock;
/* 当前正在使用的run */
arena_run_t *runcur;
/* 可用的run构成的红黑树, 主要用于runcur用完的时候。在查找可用run时,
* 为保证对象紧凑分布,尽量从低地址开始查找,减少快要空闲的chunk的数量
*/
arena_run_tree_t runs;
/* 用于bin统计 */
malloc_bin_stats_t stats;
};
- run:每个bin在实际上是通过对它对应的正在运行的Run进行操作来进行分配的,一个run实际上就是chunk里的一块区域,大小是page的整数倍,具体由实际的bin来决定,比如8字节的bin对应的run就只有1个page,可以从里面选取一个8字节的块进行分配。在run的最开头会存储着这个run的信息,比如还有多少个块可供分配。
struct arena_run_s {
/* 所属的bin */
arena_bin_t *bin;
/*下一块可分配区域的索引 */
uint32_t nextind;
/* 当前run中空闲块数目. */
unsigned nfree;
};
- tcache:线程私有缓存
Jemalloc 把内存分配分为了三个部分:
- Small objects的size以8字节,16字节,32字节等分隔开的,小于页大小
- Large objects的size以分页为单位,等差间隔排列,小于chunk的大小
- Huge objects的大小是chunk大小的整数倍
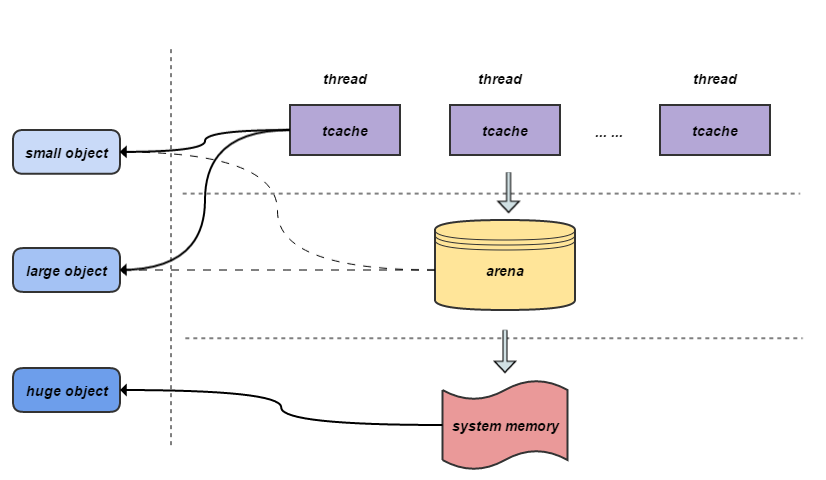
相互关系
arena -> bin数组 -> 通过正在运行的run分配
tcache -> tbin数组(比arena中的长,可以缓存到32K)
chunk(默认4M) -> 多个run(实际分配的操作对象,页的整数倍)
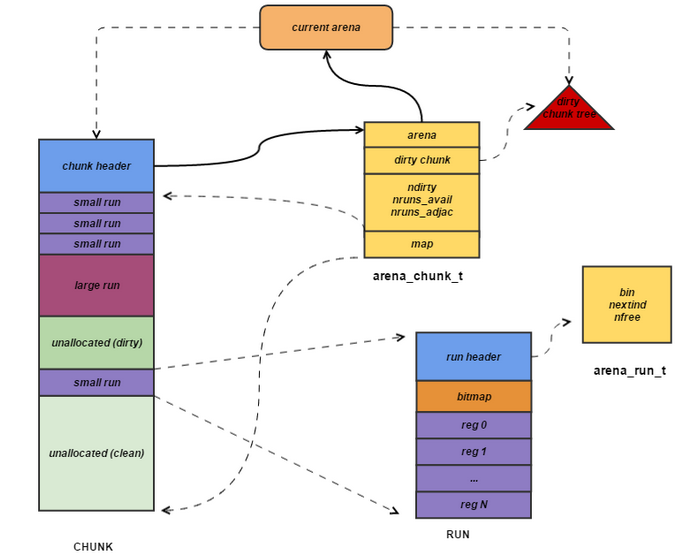
内存分配
申请small内存(小于4K)
- tcache分配,通过size的大小确定属于哪个tbin。如果tbin中有缓存,分配返回。如果没有,跳到2
- 获取一个arena,对bin加锁。从arena的bin中分配一个run,如果没有剩余run,通过红黑树从bin中里面找到run,然后分配给tcache;如果bin的红黑树也没有run,那么从aarena的红黑树中申请run;如果arena的红黑树也没有run,那就只能申请一个新的chunk了。将这个run,加入tcache,然后资源从tcache返回。
申请large内存(4k - 32k)
- tcache分配,通过size的大小确定属于哪个tbin。如果tbin中有缓存,分配返回。如果没有,跳到2
- 获取一个arena。因为此时申请的size大于bin的最大长度,所以直接从通过areba的红黑树申请一块run;如果arena的红黑树也没有run,那就只能申请一个新的chunk了。
申请large内存(大于32K,小于4M)
同上第2步
申请huge的内存(大于等于4M)
直接mmap分配
内存释放
在内存分配时,jemalloc 按照 small/large/huge allocation 来特殊处理。因此,释放时,需要由地址来判断为何种分配类型。
我们知道分配出去的空间,都属于某个 chunk,首先通过将地址对齐到 标准 chunk 大小,找到所属 chunk
- 对于 huge allocation,free 的地址本身在 chunk 边界上。搜索全局的 huge 树来获得本次分配的长度。
- 对于 small/large allocation,根据 free 的地址所在页在 chunk 内的相对页号,访问 chunk 头部的 arena_chunk_map_t 数组。如下图所示
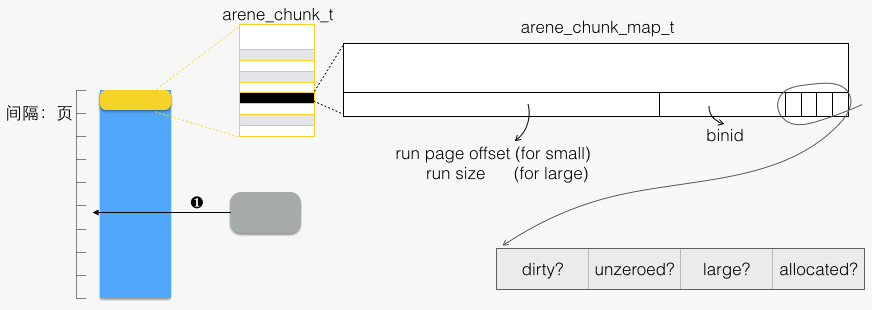
tcache中释放对象
- 释放一段 region,首先要知道所属 bin(tcache_bin_t)。Q:如何找到所属 bin?可以从对应 arena_chunk_map_t 成员中的 binid 域。
- tcache_bin_t 用指针数组来收纳释放的内存,这是一个栈的结构。最近释放的内存放在栈顶,使得下次被先分配出去。如此能保持 cache 热度。
- tcache_bin_t 满了以后,或者 GC 事件被触发,则降低 tcache_bin_t 中缓冲内存的数量(栈底 N 个内存刷回)
- 当region归还给run,这时会产生两个可能影响。Q:如何找到run,通过arena_chunk_map_t 成员中的 run page offset域
- 当原来全用完的 run,现在有一个 region 可分配了,将其插入所属 bin 中,供分配。
- 当 run 全空了,则释放之:从所属 bin中移除,并将空间交还给arena.runs_avail。
- 当chunk中的run完全回收后,可能会导致chunk的回收。对于chunk的回收,如果是mmap分配的页面,会通过ummap释放,而不是放入chunks_szad 全局红黑树。如果是sbrk分配的页面,会通过madvise释放物理页面,虚拟地址放入全局红黑树中。
垃圾回收
jemalloc 中,有两个层面的回收,一是 tcache 中多余缓冲赶到 arena 中;二是将 arena.runs_avail 中多余的物理内存释放掉一些。
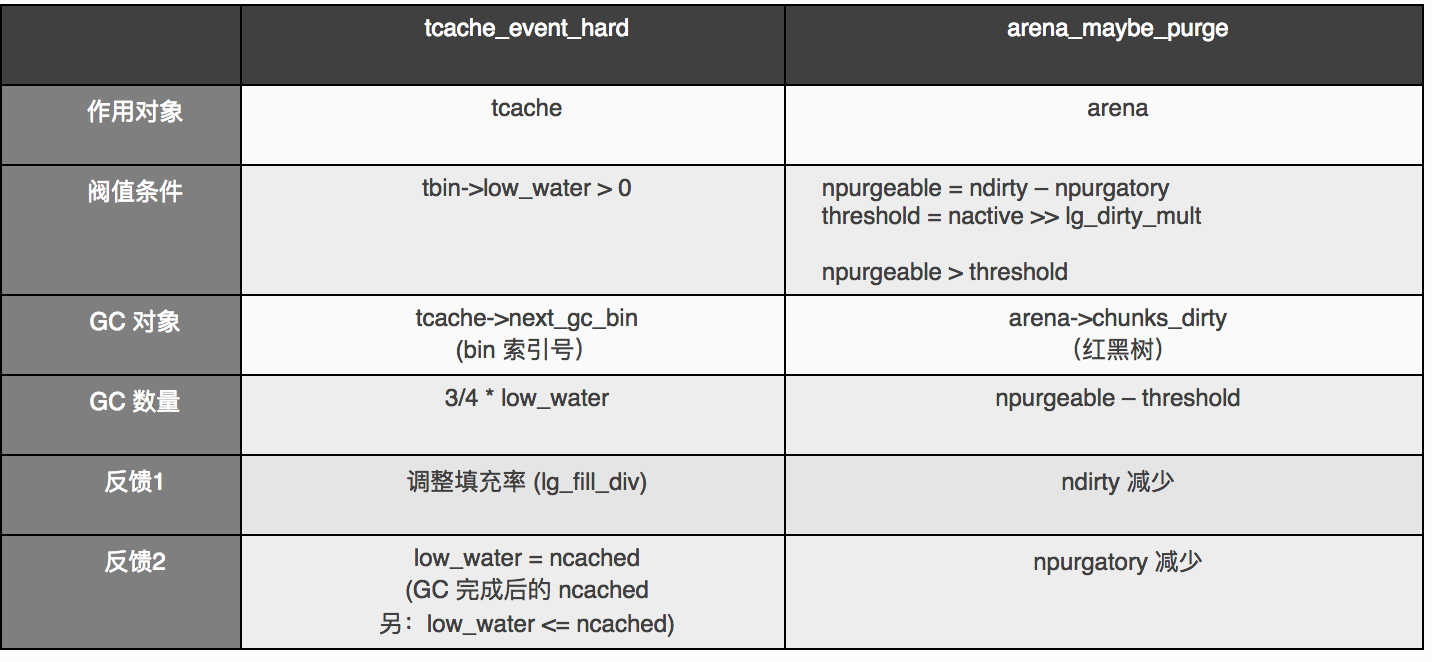
内存区域的额外属性
- dirty: 一个内存区域被分配出去以后,就是“脏”的。
- 一个run回收后会尝试与后半部分干净的run合并。或者与前半部分dirty的run进行合并。
总结
- jemalloc中的层层缓存
- tcache 过多的内存缓冲 —— GC 会处理的。
- arena.bins —— for small allocation,无处理。
- arena.avail_runs —— GC 会处理的。
- arena->spare —— 如果是 dirty 的,无处理。保持直到有新释放的 chunk 进入 spare,挤走本座。
- 内部使用的缓冲 —— 无处理。
- chunks_szad —— 无物理内存占用。
- jemalloc 的设计思路
减少多线程竞争。例如引入 tcache,以及线程均分布到若干个 arena(s)。
地址空间重用,减少碎片:
Small allocation,“归档位”、从各 runs 中分配
红黑树来保证同等条件下,总是从低地址开始分配
合并相邻的空闲空间
保持 cache 热度,例如 tcache,地址空间重用
各种对齐,自然对齐,cache line 对齐
缺点:
- 缓存过多,内部碎片严重
jemalloc总结的更多相关文章
- jemalloc在linux上从安装到使用
jemalloc在linux上从安装到使用 上次在引导大家安装Redis时提到可能会报错: 发现了redis有用到jemalloc. 首先,jemalloc是干什么的? 我们看看作者自己的介绍: j ...
- 利用jemalloc优化mysql
一.下载安装jemalloc #wget http://www.canonware.com/download/jemalloc/jemalloc-3.6.0.tar.bz2 #tar jxvf jem ...
- redis make时 提示 zmalloc.h:50:31: error: jemalloc/jemalloc.h:
redis安装需要环境必备 gcc 但是若未先安装好gcc,make失败后再次 make 会提示如下错误 zmalloc.h:50:31: error: jemalloc/jemalloc.h: 这时 ...
- 【GoLang】tcmalloc && jemalloc
https://www.douban.com/note/512625720/ http://blog.csdn.net/hanxin1987216/article/details/8156010 ht ...
- 如何验证 jemalloc 优化 Nginx 是否生效
Jemalloc 源于 Jason Evans 2006年在 BSDcan conference 发表的论文:<A Scalable Concurrent malloc Implementati ...
- jemalloc优化MySQL、Nginx内存管理
上一篇文章<TCMalloc优化MySQL.Nginx.Redis内存管理>,下面来看下jemalloc jemalloc源于Jason Evans 2006年在BSDcan confer ...
- Inside of Jemalloc
INSIDE OF JEMALLOCThe Algorithm and Implementation of Jemalloc author: vector03mail: mmzsmm@163.co ...
- jemalloc源码结构分析(一):内存申请处理过程
一.5种malloc方法 1)tcache_alloc_small 2)arena_malloc_small 3)tcache_alloc_large 4)arena_malloc_large 5)h ...
- jemalloc/jemalloc.h: No such file or directory
Redis 2.6.9 安装报错,提示: zmalloc.h:50:31: error: jemalloc/jemalloc.h: No such file or directoryzmalloc.h ...
- jemalloc Mongodb Nginx 优化
下载 http://www.canonware.com/jemalloc/download.html 下载 wget http://www.canonware.com/download/jemallo ...
随机推荐
- ArrayBlockingQueue和LinkedBlockingQueue
1.BlockingQueue接口定义了一种阻塞的FIFO queue ArrayBlockingQueue和LinkedBlockingQueue的区别: 1. 队列中锁的实现不同 ArrayBlo ...
- java 判断手机号码和邮箱的正则表达式
很多场合会用到判断输入框输入的是否为手机或者邮箱,下面是这个正则表达式: Pattern patternMailBox = Pattern .compile( "^([a-zA-Z0-9 ...
- scikit-FEM
from skfem import * m = MeshTri() m.refine(4) e = ElementTriP1() basis = InteriorBasis(m, e) @biline ...
- 微擎 人人商城 merchant.php源码
<?php define('IN_SYS', true); require '../framework/bootstrap.inc.php'; load()->web('common'); ...
- WPF用户控件库 嵌入外部(VLC)exe
综合网上资源完成的自己的第一篇博客 ------------------------------------------------------------------------ 网上类似的贴子挺多 ...
- .Net下EF的简单实现
1.连接SQLServer,创建数据库TestDB; 2.添加EF引用,点击工具-NuGet包管理器-管理解决方案的NuGet程序包, 搜索EntityFramework包,点击安装: 3.在Web. ...
- 面向对象——单例模式,五种方式
单例模式:多次实例化的结果指向同一个实例 实现方式 一.使用类方法(调用创新对象,函数返回原定对象) import settings class Mysql: __instance = None de ...
- Flask系列08--Flask中flask_session, redis插件
一.安装 1.flask_session 不想将Session的信息存放在Cookie 将Session存放在Redis Cookie中保存Session的ID flask中的session是直接将数 ...
- 学习人工智还死拽着Python不放?大牛都在用Anaconda5.2.0
前言 最近有很多的小白想学习人工智能,可是呢?依旧用Python在学习.我说大哥们,现在都什么年代了,还在把那个当宝一样拽着死死不放吗?懂的人都在用Anaconda5.2.0,里面的功能可强大多了,里 ...
- postgresql和redis
redis 和postgresql区别以及其优缺点 一刹那者为一念,二十念为一瞬,二十瞬为一弹指,二十弹指为一罗预,二十罗预为一须臾,一日一夜有三十须臾. 那么,经过周密的计算,一瞬间为0.36 秒, ...