SqlServer共用表达式(CTE)With As
共用表表达式(CTE)可以看成是一个临时的结果集,可以再SELECT,INSERT,UPDATE,DELETE,MARGE语句中多次引用。
一好处:使用共用表表达式可以让语句更加清晰简练。
1.可以定义递归公用表表达式(CTE)
2.当不需要将结果集作为视图被多个地方引用时,CTE可以使其更加简洁
3.GROUP BY语句可以直接作用于子查询所得的标量列
4.可以在一个语句中多次引用公用表表达式(CTE)
二定义:公用表达式的定义非常简单,只包含三部分:
- 公用表表达式的名字(在WITH之后)
- 所涉及的列名(可选)
- 一个SELECT语句(紧跟AS之后)
在MSDN中的原型:
WITH expression_name [ ( column_name [,...n] ) ] AS ( CTE_query_definition )
按照是否递归,可以将公用表(CTE)表达式分为递归公用表表达式和非递归公用表表达式.
非递归公用表表达式(CTE)
非递归公用表表达式(CTE)是查询结果仅仅一次性返回一个结果集用于外部查询调用。并不在其定义的语句中调用其自身的CTE
WITH cte_Test AS
(
SELECT * FROM dbo.SysOrganization
)
SELECT * FROM cte_Test
公用表表达式的好处之一是可以在接下来一条语句中多次引用:
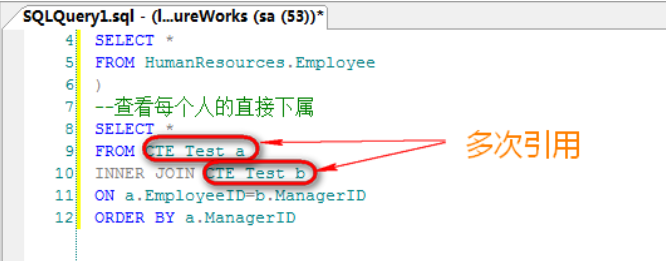
只能接下来一条使用:
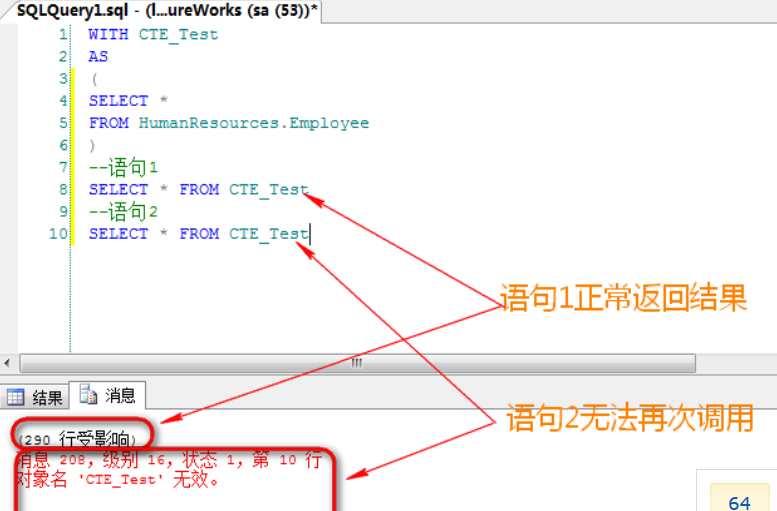
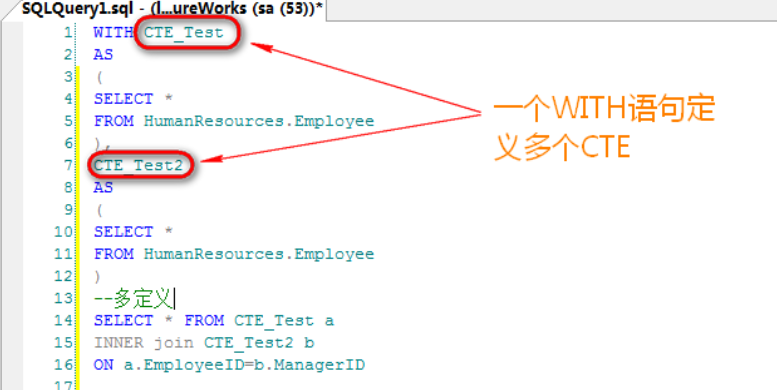
由于CTE只能在接下来一条语句中使用,因此,当需要接下来的一条语句中引用多个CTE时,可以定义多个,中间用逗号分隔:
递归公用表表达式(CTE)
递归公用表表达式很像派生表(Derived Tables ),指的是在CTE内的语句中调用其自身的CTE.与派生表不同的是,CTE可以在一次定义多次进行派生递归.对于递归的概念,是指一个函数或是过程直接或者间接的调用其自身,递归的简单概念图如下:
对于递归公用表达式来说,实现原理也是相同的,同样需要在语句中定义两部分:
- 基本语句
- 递归语句
在SQL这两部分通过UNION ALL连接结果集进行返回:

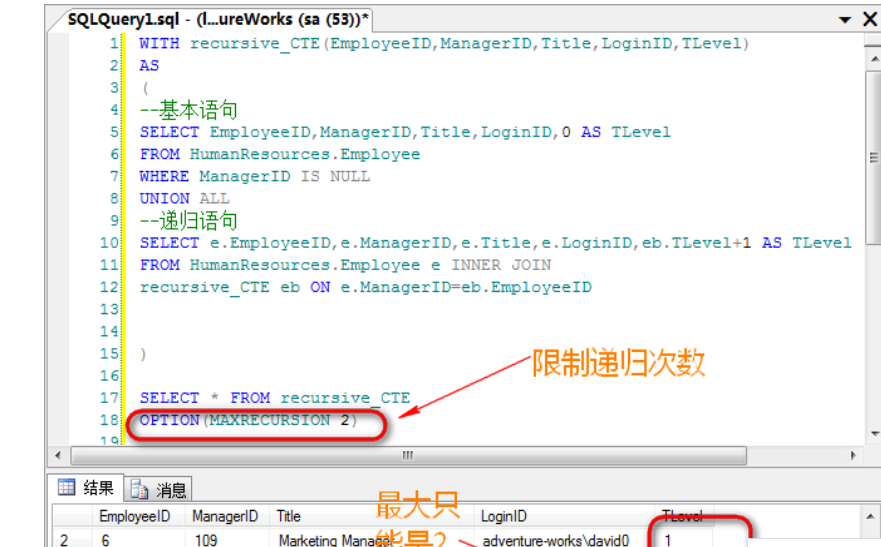
当然,越强大的力量,就需要被约束.如果使用不当的话,递归CTE可能会出现无限递归。从而大量消耗SQL Server的服务器资源.因此,SQL Server提供了OPTION选项,可以设定最大的递归次数:
还是上面那个语句,限制了递归次数:
2. CTE后面也可以跟其他的CTE,但只能使用一个with,多个CTE中间用逗号(,)分隔,如下面的SQL语句所示:
with
cte1 as
(
select * from table1 where name like 'abc%'
),
cte2 as
(
select * from table2 where id > 20
),
cte3 as
(
select * from table3 where price < 100
)
select a.* from cte1 a, cte2 b, cte3 c where a.id = b.id and a.id = c.id
3. 不能在 CTE_query_definition 中使用以下子句:
(1)COMPUTE 或 COMPUTE BY (2)ORDER BY(除非指定了 TOP 子句) (3)INTO (4)带有查询提示的 OPTION 子句 (5)FOR XML (6)FOR BROWSE
4.如果将 CTE 用在属于批处理的一部分的语句中,那么在它之前的语句必须以分号结尾,如下面的SQL所示:
declare @s nvarchar(3)
set @s = 'C%'
; -- 必须加分号
with
t_tree as
(
select CountryRegionCode from person.CountryRegion where Name like @s
)
select * from person.StateProvince where CountryRegionCode in (select * from t_tree)
. 如果将 CTE 用在属于批处理的一部分的语句中,那么在它之前的语句必须以分号结尾,如下面的SQL所示:
declare @s nvarchar(3)
set @s = 'C%'
; -- 必须加分号
with
t_tree as
(
select CountryRegionCode from person.CountryRegion where Name like @s
)
select * from person.StateProvince where CountryRegionCode in (select * from t_tree)
比较复杂的例子:
;WITH v_targetdetail(ID,ParentID,TargetID,TargetName,
TargetGroupID,ConversionValue,ToTargetID,IsCalculated,IsLeaf,
IDFullPath,IsDisplay,Unit,TargetLevelID,TargetType) AS (
-- DECLARE @accountGroupID NVARCHAR(38)='ac11e71148564dd3a28d07142883ab99'
SELECT p.ID
--父级ID
,p.ParentID
--实际指标ID
,ISNULL(p.TargetID,p.ID) TargetID
--名称
,p.Name TargetName
--指标组ID
,p.GroupID TargetGroupID
--转换值
,p.ConversionValue
--目标指标ID
,p.ToTargetID
--是否计算
,p.IsCalculated
--是否是叶子
,p.IsLeaf
--ID值
,CAST(p.ID AS NVARCHAR(MAX)) IDFullPath
--是否显示
,p.IsDisplay
-- 单位
,p.Unit
--级别
,p.LevelID
--指标类型
,p.TargetType
--指标组表
FROM ToBusinessTargetGroupDetail2(NOLOCK) p
--父级ID为空 是否上报
WHERE (p.ParentID IS NULL OR p.IsReported=0) AND p.GroupID=@accountGroupID--'ac11e71148564dd3a28d07142883ab99'-- --全部关联
UNION ALL
--递归语句
SELECT
p.ID
,p.ParentID
,ISNULL(p.TargetID,p.ID) TargetID
,p.Name TargetName
,p1.TargetGroupID
,p.ConversionValue
,p.ToTargetID
,p.IsCalculated
,p.IsLeaf
,CAST(p1.IDFullPath+'.'+p.ID AS NVARCHAR(MAX))IDFullPath
,p.IsDisplay
,p.Unit
,p.LevelID
,p.TargetType FROM ToBusinessTargetGroupDetail2(NOLOCK) p
--第一次查询的表 p1为 第一次汇总的值 p为指标详细表 得到的指表组ID==原表的指标组ID
INNER JOIN v_targetdetail p1 ON p1.ID=p.ParentID AND p1.TargetGroupID=p.GroupID
--已经上报的
WHERE p.IsReported=1
) --第二次
,v_taregetsummaryref(TargetDetailID,pTargetID,pTargetName,sTargetID,
sTargetName,ConversionValue,pToTargetID,sIsLeaf,
TargetLevelID,Unit,TargetType,TargetOrderID) AS (
SELECT p.ID
,p.TargetID pTargetID
,p.TargetName pTargetName
,p1.TargetID sTargetID
,p1.TargetName sTargetName
,p.ConversionValue
--,p1.ConversionValue
,p.ToTargetID
,p1.IsLeaf
,p.TargetLevelID
,p.Unit
,p.TargetType
,NULL
--第一次
FROM v_targetdetail p
INNER JOIN v_targetdetail p1 ON p1.TargetGroupID=p.TargetGroupID AND p1.IDFullPath LIKE p.IDFullPath+'%'
WHERE p.IsDisplay=1
) --插入到临时表
INSERT INTO #t_target(TargetDetailID,pTargetID,pTargetName,sTargetID,sTargetName,ConversionValue,pToTargetID,TargetOrderID,TargetLevelID,Unit,TargetType,isleaf)
--从最终的表里面查询结果出来
SELECT TargetDetailID,pTargetID,pTargetName,sTargetID,sTargetName,
ConversionValue,pToTargetID,TargetOrderID,TargetLevelID,
--第二次递归的表
Unit,TargetType, sIsLeaf FROM v_taregetsummaryref
UNION ALL
SELECT p1.TargetDetailID
,p1.pTargetID
,p1.pTargetName
,p2.ID sTargetID
,p2.Name sTargetName
,p1.ConversionValue
,p1.pToTargetID
,p1.TargetOrderID
,p1.TargetLevelID+p2.LevelID
,p1.Unit
,10
,p2.IsLeaf
--科目表
FROM ToFinanceAccount(NOLOCK) p
--最终的结构表 最终结果表ID ==科目表的ID 最终结果表 是叶子结点的数据
INNER JOIN v_taregetsummaryref p1 WITH(NOLOCK) ON p1.sTargetID=p.ID AND p1.sIsLeaf=1
--科目表 名称全路径 和没有删除的数据
INNER JOIN dbo.ToFinanceAccount p2 WITH(NOLOCK) ON p2.FullPath LIKE p.FullPath+'\%' AND ISNULL(p2.IsDelete,0)=0
--没有删除的数据
WHERE ISNULL(p.IsDelete,0)=0
--科目表中不是叶节点的数据
AND p.IsLeaf!=1
SqlServer共用表达式(CTE)With As的更多相关文章
- SqlServer共用表达式(CTE)With As 处理递归查询
共用表表达式(CTE)可以看成是一个临时的结果集,可以再SELECT,INSERT,UPDATE,DELETE,MARGE语句中多次引用. 一好处:使用共用表表达式可以让语句更加清晰简练. 1.可以定 ...
- SQLServer中的CTE通用表表达式
开发人员正在研发的许多项目都涉及编写由基本的 SELECT/FROM/WHERE 类型的语句派生而来的复杂 SQL 语句.其中一种情形是需要编写在 FROM 子句内使用派生表(也称为内联视图)的 Tr ...
- 公用表表达式 (CTE)、递归、所有子节点、sqlserver
指定临时命名的结果集,这些结果集称为公用表表达式 (CTE).公用表表达式可以包括对自身的引用.这种表达式称为递归公用表表达式. 对于递归公用表达式来说,实现原理也是相同的,同样需要在语句中定义两部分 ...
- SQLServer中的CTE(Common Table Expression)通用表表达式使用详解
概述 我们经常会编写由基本的 SELECT/FROM/WHERE 类型的语句派生而来的复杂 SQL 语句.其中一种方案是需要编写在 FROM 子句内使用派生表(也称为内联视图)的 Transact-S ...
- SQL Server中公用表表达式 CTE 递归的生成帮助数据,以及递归的典型应用
本文出处:http://www.cnblogs.com/wy123/p/5960825.html 我们在做开发的时候,有时候会需要一些帮助数据,必须需要连续的数字,连续间隔的时间点,连续的季度日期等等 ...
- 公用表表达式CTE
公用表表达式CTE表面上和派生表非常相似,看起来只是语义上的区别.但和派生表比较起来,CTE具有几个优势:第一,如果须要在一个CTE中引用另一个CTE,不需要像派生表那样嵌套,相反,只要简单地在同一个 ...
- T-SQL 公用表表达式(CTE)
公用表表达式(CTE) 在编写T-SQL代码时,往往需要临时存储某些结果集.前面我们已经广泛使用和介绍了两种临时存储结果集的方法:临时表和表变量.除此之外,还可以使用公用表表达式的方法.公用表表达式( ...
- 详解公用表表达式(CTE)
简介 对于SELECT查询语句来说,通常情况下,为了使T-SQL代码更加简洁和可读,在一个查询中引用另外的结果集都是通过视图而不是子查询来进行分解的.但是,视图是作为系统对象存在数据库中,那对于结果集 ...
- T-SQL查询进阶--详解公用表表达式(CTE)
简介 对于SELECT查询语句来说,通常情况下,为了使T-SQL代码更加简洁和可读,在一个查询中引用另外的结果集都是通过视图而不是子查询来进行分解的. 但是,视图是作为系统对象存在数据库中,那对于结果 ...
随机推荐
- jmeter正则提取值 同级目录下的值
https://www.v2ex.com/api/nodes/show.json?name=python 接口返回: { "avatar_large": "//cdn.v ...
- c/c++ 函数说明以及技巧总结
1. memset函数: void *memset(void *s, int ch, size_t n); 函数解释:将s中当前位置后面的n个字节 (typedef unsigned int size ...
- java 枚举 封装操作方法
前言: 由于刚转java项目,所以对于java语言比较陌生,尤其是lambda和一些诸如(一个java文件只能有一个public class)等等的零散知识点之类... 使我觉得就语言的层级来说..n ...
- (转)DATATABLE(DATASET)与实体类之间的互转.
转自:http://www.cnblogs.com/zzyyll2/archive/2010/07/20/1781649.html dataset和实体类 之间的转换 //dataset转实体类 代 ...
- System.gc()与Runtime.gc()的区别
(1) GC是垃圾收集的意思(Gabage Collection),内存处理是编程人员容易出现问题的地方,忘记或者错误的内存回收会导致程序或系统的不稳定甚至崩溃,Java提供的GC功能可以自动监测对象 ...
- webpack插件去除没用到的css
去除没用到的css需要用到purifycss-webpack插件,而这个插件又依赖于purify-css 1.安装 npm i purifycss-webpack purify-css -D 2.加入 ...
- Kafka 0.8 sever:源代码High level分析
本文主要介绍了Kafka High level的代码架构和主要的类. 这张图是0.8版本的架构 Boker 架构 1 network layer Kafka使用NIO自己实现了网络层的代码, 而不是采 ...
- JAVA-Servlet内容
Servlet重定向 HttpServletResponse接口的sendRedirect()方法可以用于将响应重定向到另一个资源,资源可能是servlet,jsp或html文件. 它接受相对和绝对U ...
- bzoj千题计划205:bzoj3529: [Sdoi2014]数表
http://www.lydsy.com/JudgeOnline/problem.php?id=3529 有一张n*m的数表,其第i行第j列(1 < =i < =n,1 < =j & ...
- [iOS]图片高清度太高, 导致内存过大Crash
先说一下状况, 后台提供的图片太高清了, 每个图片都在2-4MB, iOS上每个页面需要同时下载并展示10-15张. 这个时候, 如果我多滑动collectionView几次, 直接App就崩溃了(r ...