Netty - 3 内存分配
https://www.cnblogs.com/gaoxing/p/4253833.html
netty的buffer引入了缓冲池。该缓冲池实现使用了jemalloc的思想
内存分配是面向虚拟内存的而言的,以页为单位进行管理的,页的大小一般为4kb,当在堆里创建一个对象时(小于4kb),会分配一个页,当再次创建一个对象时会判断该页剩余大小是否够,够的话使用该页剩余的内存,减少系统调用
内存分配的核心思想概括起来有3条
1:首先讲内存区(memory pool)以最小单位(chunk)定义出来 ,然后区分对象大小分别管理内存,小内存定义不同的规格(bins),根据不同的bin分配固定大小的内存块,并用一个表
管理起来,大对象则以页为单位进行管理,配合小对象所在的页,降低碎片,设计一个好的存储方案(metadata)减少对内存的占用,同时优化内存信息的存储。以使对每个bin或大内存区域的访问性能最优且有上限。
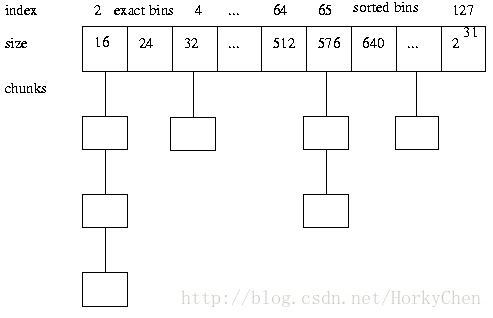
2:当释放内存时,要能够合并小内存为大内存,该保留的保留下次可快速响应,不该保留的释放给系统
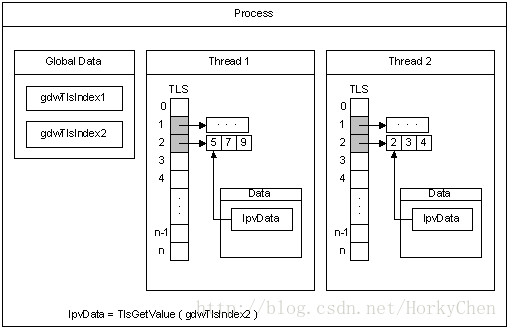
3:多线程环境下,每个线程可以独立的占有一段内存区间(TLS),这样线程内操作可以不加锁
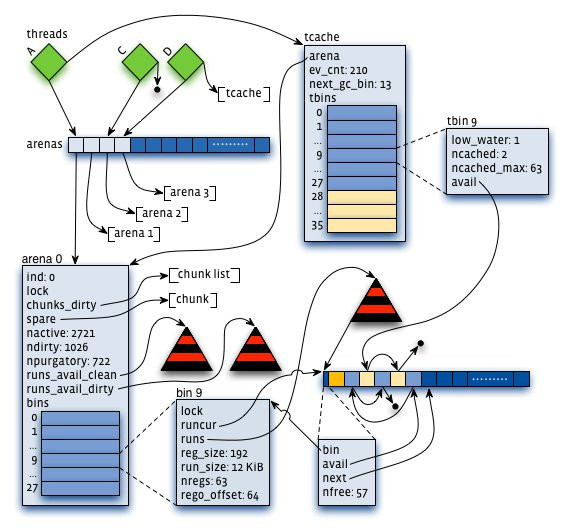
1:arena:把内存分成许多不同的小块来分而治之,该小块便是arena,让我们想象一下,给几个小朋友一张大图纸,让他们随意地画点。结果可想而知,他们肯定相互顾忌对方而不敢肆意地画(synchronization),从而影响画图效率。但是如果老师事先在大图纸上划分好每个人的区域,小朋友们就可以又快又准地在各自地领域上画图。这样的概念就是arena。它是jemalloc的核心分配管理区域,对于多核系统,会默认分配4*cores个arena 。线程采用轮询的方式来选择响应的arena进行内存分配。
2 : chunk。具体进行内存分配的区域,默认大小是4M,chunk以page为单位进行管理,每个chunk的前6个page用于存储后面page的状态,比如是否分配或已经分配
3:bin:用来管理各个不同大小单元的分配,比如最小的Bin管理的是8字节的分配,每个Bin管理的大小都不一样,依次递增。
4:run:每个bin在实际上是通过对它对应的正在运行的Run进行操作来进行分配的,一个run实际上就是chunk里的一块区域,大小是page的整数倍,具体由实际的bin来决定,比如8字节的bin对应的run就只有1个page,可以从里面选取一个8字节的块进行分配。在run的最开头会存储着这个run的信息,比如还有多少个块可供分配。
5:tcache。线程对应的私有缓存空间,默认是使用的。因此在分配内存时首先从tcache中找,miss的情况下才会进入一般的分配流程。
arena和bin的关系:每个arena有个bin数组,每个bin管理不同大小的内存(run通过它的配置去获取相应大小的内存),每个tcahe有一个对应的arena,它本身也有一个bin数组(称为tbin),前面的部分与arena的bin数组是对应的,但它长度更大一些,因为它会缓存一些更大的块;而且它也没有对应的run的概念
chunk与run的关系:chunk默认是4M,而run是在chunk中进行实际分配的操作对象,每次有新的分配请求时一旦tcache无法满足要求,就要通过run进行操作,如果没有对应的run存在就要新建一个,哪怕只分配一个块,比如只申请一个8字节的块,也会生成一个大小为一个page(默认4K)的run;再申请一个16字节的块,又会生成一个大小为4096字节的run。run的具体大小由它对应的bin决定,但一定是page的整数倍。因此实际上每个chunk就被分成了一个个的run。
内存分配的,具体流程如下:
http://www.cnhalo.net/2016/06/13/memory-optimize/
与tcmalloc类似,每个线程同样在<32KB的时候无锁使用线程本地cache。
- Jemalloc在64bits系统上使用下面的size-class分类:
Small: [8], [16, 32, 48, …, 128], [192, 256, 320, …, 512], [768, 1024, 1280, …, 3840]
Large: [4 KiB, 8 KiB, 12 KiB, …, 4072 KiB]
Huge: [4 MiB, 8 MiB, 12 MiB, …] - small/large对象查找metadata需要常量时间, huge对象通过全局红黑树在对数时间内查找。
- 虚拟内存被逻辑上分割成chunks(默认是4MB,1024个4k页),应用线程通过round-robin算法在第一次malloc的时候分配arena, 每个arena都是相互独立的,维护自己的chunks, chunk切割pages到small/large对象。free()的内存总是返回到所属的arena中,而不管是哪个线程调用free()。

上图可以看到每个arena管理的arena chunk结构, 开始的header主要是维护了一个page map(1024个页面关联的对象状态), header下方就是它的页面空间。 Small对象被分到一起, metadata信息存放在起始位置。 large chunk相互独立,它的metadata信息存放在chunk header map中。
- 通过arena分配的时候需要对arena bin(每个small size-class一个,细粒度)加锁,或arena本身加锁。
并且线程cache对象也会通过垃圾回收指数退让算法返回到arena中。
http://www.cnblogs.com/gaoxing/p/4253892.html
PoolChunk:一大块连续的内存,Netty中,这个值为16M,一次性通过 java.nio.ByteBuf 进行分配,这个内存是Direct Memory,不在JVM的GC范围之内。多个PoolChunk可以共同构成一个PoolArea。每个PoolChunk按照Buddy算法分为多个block,最小的block:order-0 block(称之为一个PoolSubPage)是8K,而后是order-1 block:16K, order-2 block:32 K,一直到 order-11 block: 16M
在PoolChunk中,使用一个int[4096] memoryMap来描述所有的block,这其实是一个二叉树来的:
0
1 2
3 4 5 6
07 08 09 10 11 12 13 14
这里, memoryMap[1] 表示的是order-11的Block,它实际上可以切分为两个order-10的block,他们由 memoryMap[2]和 memoryMap[3]来表示,每个值由3部分组成:
31 17 16 2 1 0
0-1位:标志位,00(未使用,没有这个Block)、01(Branch,当前Block以拆分,由2个低级别的block组成)、02(已分配)、03(已分配的SubPage,这个是最底层分配的Block了,可以是大于8K的Page。)
2-16位:当前块的大小,以Page为单位。
17 – 31位:当前块相对Chunk基地址的偏移量。(以Page为单元)
使用数组来替代二叉树的优势是极大的节约了内存,第N的节点的子节点是2N+1, 2N+2。在这里,16M的Chunk需要使用16K来描述,占比为0.1%
PoolSubPage对应于一个已分配的block,在Slab实现中,每个PoolSubPage都仅用于某个一定size的内存分配,例如,这个值从16、32到512(TinyPool)是按16递增,而后是1K、2K、4K、8K、16K、32K、64K…(smallPool)的递增顺序,每个SubPage都近用于分配固定大小的内存(称之为一个Slab),这样的优势是只需要使用一个bitmap就可以记录哪些内存是已分配的,以最小的16字节为单位,每个Page(8K)只需要64个字节的位图信息(占比为0.78%),而在其它块中,这个值就更小了。(目前Netty的实现在这里有一些不足,每个Page都是用了64个字节的位图,估计是便于简化SubPage自身的Pool)
每个Chunk按照Slab的大小,组织了多条队列,队列中的每个成员是SubPage,因此,当需要进行分配时,是可以最快速的完成的。
每个ByteBuf()维持了对应的Chunk,当需要释放时,可以根据当前的内存地址,迅速的定位到Chunk中对应的page,再在相应的SubPage中进行释放。整个过程只需要更新相应的bitmap即可。
忽略掉其它的内存开销,Slab+Buddy方式的内存管理成本不到1%,分配和释放速度都非常快。但是Slab的方式,整体内存的使用率方面可能会小一些,不同Slab之间的内存是不会共享的,相当于给大猫挖一个大的猫洞的情况下,也得给小猫挖一个小的猫洞。
=========================
总的来说,Netty的ByteBuf带给我们的启示就是,即便在JVM中,我们也不必拘泥于GC的内存管理方式,在更适合使用手工方式管理的情况下,我们也可以这样做,这也为Java管理海量的内存、Cache化的数据、以及高频繁分配的模式下,仍然可以借助于JVM的强大的能力,而又不是去直接管理内存的灵活性
Netty - 3 内存分配的更多相关文章
- Netty内存管理器ByteBufAllocator及内存分配
ByteBufAllocator 内存管理器: Netty 中内存分配有一个最顶层的抽象就是ByteBufAllocator,负责分配所有ByteBuf 类型的内存.功能其实不是很多,主要有以下几个重 ...
- 《从HBase offheap到Netty的内存管理》
JVM中的堆外内存(off-heap memory)与堆内内存(on-heap memory) 1. 堆内内存(on-heap memory) 1.1 什么是堆内内存 Java 虚拟机在执行Jav ...
- Netty源码—六、tiny、small内存分配
tiny内存分配 tiny内存分配流程: 如果申请的是tiny类型,会先从tiny缓存中尝试分配,如果缓存分配成功则返回 否则从tinySubpagePools中尝试分配 如果上面没有分配成功则使用a ...
- Netty源码—五、内存分配概述
Netty中的内存管理应该是借鉴了FreeBSD内存管理的思想--jemalloc.Netty内存分配过程中总体遵循以下规则: 优先从缓存中分配 如果缓存中没有的话,从内存池看看有没有剩余可用的 如果 ...
- Netty源码分析第5章(ByteBuf)---->第7节: page级别的内存分配
Netty源码分析第五章: ByteBuf 第六节: page级别的内存分配 前面小节我们剖析过命中缓存的内存分配逻辑, 前提是如果缓存中有数据, 那么缓存中没有数据, netty是如何开辟一块内存进 ...
- Netty源码分析第5章(ByteBuf)---->第8节: subPage级别的内存分配
Netty源码分析第五章: ByteBuf 第八节: subPage级别的内存分配 上一小节我们剖析了page级别的内存分配逻辑, 这一小节带大家剖析有关subPage级别的内存分配 通过之前的学习我 ...
- Netty之Page级别的内存分配
Page 级别的内存分配: 之前我们介绍过, netty 内存分配的单位是chunk, 一个chunk 的大小是16MB, 实际上每个chunk, 都以双向链表的形式保存在一个chunkList 中, ...
- Netty 中的内存分配浅析
Netty 出发点作为一款高性能的 RPC 框架必然涉及到频繁的内存分配销毁操作,如果是在堆上分配内存空间将会触发频繁的GC,JDK 在1.4之后提供的 NIO 也已经提供了直接直接分配堆外内存空间的 ...
- Netty 中的内存分配浅析-数据容器
本篇接续前一篇继续讲 Netty 中的内存分配.上一篇 先简单做一下回顾: Netty 为了更高效的管理内存,自己实现了一套内存管理的逻辑,借鉴 jemalloc 的思想实现了一套池化内存管理的思路: ...
随机推荐
- Oracle 故障整理
#created at 18-10-28 by nod #提示磁盘空间已满 不能登录数据库 18-10-28 [oracle@oracle ~]$ sqlplus / as sysdba SQL*Pl ...
- C语言强化——学生管理系统
系统模块设计 a.预处理模块 系统在启动时会根据配置文件里的内容去相应文件里去加载账户信息和学生信息. b.登陆模块 输入用户名和密码,输密码的时候用"*" 代表用户当前输入的内容 ...
- switch语句的功能是否完全可以使用if else多选择结构来代替?如果是,为什么还需要switch结构?
- 【PHP】五分钟教你编写一个实时弹幕网站
由于博主是个忠实的英雄联盟粉丝,所以经常观看一些明星大神的直播.而一谈到直播,肯定会看到满屏幕飘来飘去的弹幕.那么问题来了,这些视频弹幕网站如何做到实时同步的?PHP如何开发一个类似的网站? 首先要搞 ...
- es5中类与继承
<!doctype html> <html> <head> <meta charset="utf-8"> <meta name ...
- React 懒加载组件
//组件第一次初始化的时候加载. import React, {PropTypes} from 'react'; //import AppComposer from './views/App/AppC ...
- cocos源码分析--RenderTexture
cocos中RenderTexture主要用来实现截屏,然后把截取出来的图片保存到磁盘中,除了保存图片和渲染纹理,它还可以得到一些预渲染结果,并将这些结果作为一种纹理数据. 例如我们可以用RGB5_A ...
- jQuery操作DOM节点的方法总结
1.parent():获得当前匹配元素集合中每个元素的父元素,该方法只会向上一级对 DOM 树进行遍历 $('li.item-a').parent().css('background-color', ...
- python 27 获取时区转换后的时间
python3的datetime有timezone属性,这里介绍python2.7环境下,获取时区转换后的时间. 利用第三方插件,pytz,没有安装的话安装一下. #!/usr/bin/env pyt ...
- WPF 去除系统窗体边框,自定义移动窗体
方法一: 去除系统窗体边框: <Window x:Class="PracticeProject.MainWindow" xmlns="http://schemas. ...