SQLServer中的事务与锁
事务:保持逻辑数据一致性与可恢复性,必不可少的利器。
锁:多用户访问同一数据库资源时,对访问的先后次序权限管理的一种机制,没有他事务或许将会一塌糊涂,不能保证数据的安全正确读写。
死锁:是数据库性能的重量级杀手之一,而死锁却是不同事务之间抢占数据资源造成的。
事务具有原子性,一致性,隔离性,持久性。
- 原子性:事务必须是一个自动工作的单元,要么全部执行,要么全部不执行。
- 一致性:事务结束的时候,所有的内部数据都是正确的。
- 隔离性:并发多个事务时,各个事务不干涉内部数据,处理的都是另外一个事务处理之前或之后的数据。
- 持久性:事务提交之后,数据是永久性的,不可再回滚。
在SQL Server中事务被分为3类常见的事务:
- 自动提交事务:是SQL Server默认的一种事务模式,每条Sql语句都被看成一个事务进行处理,你应该没有见过,一条Update 修改2个字段的语句,只修该了1个字段而另外一个字段没有修改。。
- 显式事务:T-sql标明,由Begin Transaction开启事务开始,由Commit Transaction 提交事务、Rollback Transaction 回滚事务结束。
- 隐式事务:使用Set IMPLICIT_TRANSACTIONS ON 将将隐式事务模式打开,不用Begin Transaction开启事务,当一个事务结束,这个模式会自动启用下一个事务,只用Commit Transaction 提交事务、Rollback Transaction 回滚事务即可。
显示事务的应用:
常用语句就四个。
- Begin Transaction:标记事务开始。
- Commit Transaction:事务已经成功执行,数据已经处理妥当。
- Rollback Transaction:数据处理过程中出错,回滚到没有处理之前的数据状态,或回滚到事务内部的保存点。
- Save Transaction:事务内部设置的保存点,就是事务可以不全部回滚,只回滚到这里,保证事务内部不出错的前提下。
---开启事务
begin tran
--错误扑捉机制,看好啦,这里也有的。并且可以嵌套。
begin try
--语句正确
insert into lives (Eat,Play,Numb) values ('猪肉','足球',)
--Numb为int类型,出错
insert into lives (Eat,Play,Numb) values ('猪肉','足球','abc')
--语句正确
insert into lives (Eat,Play,Numb) values ('狗肉','篮球',)
end try
begin catch
select Error_number() as ErrorNumber, --错误代码
Error_severity() as ErrorSeverity, --错误严重级别,级别小于10 try catch 捕获不到
Error_state() as ErrorState , --错误状态码
Error_Procedure() as ErrorProcedure , --出现错误的存储过程或触发器的名称。
Error_line() as ErrorLine, --发生错误的行号
Error_message() as ErrorMessage --错误的具体信息
if(@@trancount>) --全局变量@@trancount,事务开启此值+,他用来判断是有开启事务
rollback tran ---由于出错,这里回滚到开始,第一条语句也没有插入成功。
end catch
if(@@trancount>)
commit tran --如果成功Lives表中,将会有3条数据。 --表本身为空表,ID ,Numb为int 类型,其它为nvarchar类型
select * from lives

使用set xact_abort
设置 xact_abort on/off , 指定是否回滚当前事务,为on时如果当前sql出错,回滚整个事务,为off时如果sql出错回滚当前sql语句,其它语句照常运行读写数据库。
需要注意的时:xact_abort只对运行时出现的错误有用,如果sql语句存在编译时错误,那么他就失灵。
delete lives --清空数据
set xact_abort off
begin tran
--语句正确
insert into lives (Eat,Play,Numb) values ('猪肉','足球',)
--Numb为int类型,出错,如果1234..那个大数据换成'132dsaf' xact_abort将失效
insert into lives (Eat,Play,Numb) values ('猪肉','足球',)
--语句正确
insert into lives (Eat,Play,Numb) values ('狗肉','篮球',)
commit tran
select * from lives

为on时,结果集为空,因为运行是数据过大溢出出错,回滚整个事务。
并发事务产生锁
打开两个查询窗口,把下面的语句,分别放入2个查询窗口,在5秒内运行2个事务模块。
begin tran
update lives set play='羽毛球'
waitfor delay '0:0:5'
update dbo.Earth set Animal='老虎'
commit tran
begin tran
update Earth set Animal='老虎'
waitfor delay '0:0:5' --等待5秒执行下面的语句
update lives set play='羽毛球'
commit tran
select * from lives
select * from Earth
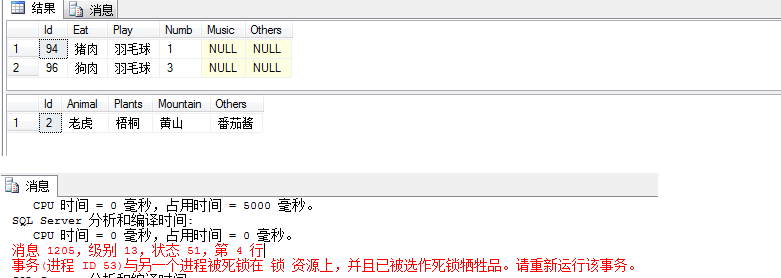
锁就是在一段时间内禁止用户做某些操作以避免产生数据不一致
对锁机制的研究要具备两个条件:
1.数据量大
2.多个用户同时并发
如果缺少这两个条件,数据库不容易产生死锁问题。研究起来可能会事倍功半。如果这两个条件都有,但你还是按数据库缺省设置来处理数据,则会带来很多的问题,比如:
丢失更新
A,B两个用户读同一数据并进行修改,其中一个用户的修改结果破坏了另一个修改的结果,比如订票系统
脏读
A用户修改了数据,随后B用户又读出该数据,但A用户因为某些原因取消了对数据的修改,数据恢复原值,此时B得到的数据就与数据库内的数据产生了不一致
不可重复读
A用户读取数据,随后B用户读出该数据并修改,此时A用户再读取数据时发现前后两次的值不一致
SQL SERVER 作为多用户数据库系统,以事务为单位,使用锁来实现并发控制。SQLSERVER使用“锁”确保事务完整性和数据一致性。
锁的模式
- 共享(S) 用于不更改或不更新数据(只读操作),如SELECT语句
- 更新(U) 用于可更新的资源中。防止当多个会话在读取、锁定以及随后可能进行的资源更新时发生常见形式的死锁。
- 排它(X) 用于数据修改操作,例如 INSERT、UPDATE或DELETE。确保不会同时对同一资源进行多重更新
- 意向 当 Microsoft SQL Server 数据库引擎获取低级别的锁时,它还将在包含更低级别对象的对象上放置意向锁.例如: 当锁定行或索引键范围时,数 据库引擎将在包含行或键的页上放置意向锁。当锁定页时,数据库引擎将在包含页的更高级别的对象上放置意向锁。
意向锁的类型为:意向共享(IS)、意向排它(IX)以及意向排它共享(SIX) - 架构 在执行依赖于表架构的操作时使用。架构锁的类型为:架构修改(Sch-M)和架构稳定(Sch-S)
- 大容量更新(BU) 向表中大容量复制数据并指定了TABLOCK提示时使用
- 锁模式 描述
死锁
第一个事务(称为A):先更新lives表 --->>停顿5秒---->>更新earth表
第二个事务(称为B):先更新earth表--->>停顿5秒---->>更新lives表
先执行事务A----5秒之内---执行事务B,出现死锁现象。
过程是这样子的:
- A更新lives表,请求lives的排他锁,成功。
- B更新earth表,请求earth的排他锁,成功。
- 5秒过后
- A更新earth,请求earth的排它锁,由于B占用着earth的排它锁,等待。
- B更新lives,请求lives的排它锁,由于A占用着lives的排它锁,等待。
这样相互等待对方释放资源,造成资源读写拥挤堵塞的情况,就被称为死锁现象,也叫做阻塞。而为什么会产生,上例就列举出来啦。
然而数据库并没有出现无限等待的情况,是因为数据库搜索引擎会定期检测这种状况,一旦发现有情况,立马选择一个事务作为牺牲品。牺牲的事务,将会回滚数据。有点像两个人在过独木桥,两个无脑的人都走在啦独木桥中间,如果不落水,必定要有一个人给退回来。这种相互等待的过程,是一种耗时耗资源的现象,所以能避则避。
哪个人会被退回来,作为牺牲品,这个我们是可以控制的。控制语法:
set deadlock_priority <级别>
死锁处理的优先级别为 low<normal<high,不指定的情况下默认为normal,牺牲品为随机。如果指定,牺牲品为级别低的。
还可以使用数字来处理标识级别:-10到-5为low,-5为normal,-5到10为high。
在大型数据库中,高并发带来的死锁是不可避免的,所以我们只能让其变的更少。
- 按照同一顺序访问数据库资源,上述例子就不会发生死锁啦
- 保持是事务的简短,尽量不要让一个事务处理过于复杂的读写操作。事务过于复杂,占用资源会增多,处理时间增长,容易与其它事务冲突,提升死锁概率。
- 尽量不要在事务中要求用户响应,比如修改新增数据之后在完成整个事务的提交,这样延长事务占用资源的时间,也会提升死锁概率。
- 尽量减少数据库的并发量。
- 尽可能使用分区表,分区视图,把数据放置在不同的磁盘和文件组中,分散访问保存在不同分区的数据,减少因为表中放置锁而造成的其它事务长时间等待。
- 避免占用时间很长并且关系表复杂的数据操作。
- 使用较低的隔离级别,使用较低的隔离级别比使用较高的隔离级别持有共享锁的时间更短。这样就减少了锁争用。
查看锁活动情况:
--查看锁活动情况
select * from sys.dm_tran_locks
--查看事务活动情况
dbcc opentran
为事务设置隔离级别
所谓事物隔离级别,就是并发事务对同一资源的读取深度层次。分为5种。
- read uncommitted:这个隔离级别最低啦,可以读取到一个事务正在处理的数据,但事务还未提交,这种级别的读取叫做脏读。
- read committed:这个级别是默认选项,不能脏读,不能读取事务正在处理没有提交的数据,但能修改。
- repeatable read:不能读取事务正在处理的数据,也不能修改事务处理数据前的数据。
- snapshot:指定事务在开始的时候,就获得了已经提交数据的快照,因此当前事务只能看到事务开始之前对数据所做的修改。
- serializable:最高事务隔离级别,只能看到事务处理之前的数据。
--语法
set tran isolation level <级别>
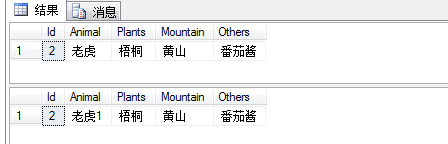
read uncommitted隔离级别的例子:
begin tran
set deadlock_priority low
update Earth set Animal='老虎'
waitfor delay '0:0:5' --等待5秒执行下面的语句
rollback tran
开另外一个查询窗口执行下面语句
set tran isolation level read uncommitted
select * from Earth --读取的数据为正在修改的数据 ,脏读
waitfor delay '0:0:5' --5秒之后数据已经回滚
select * from Earth --回滚之后的数据
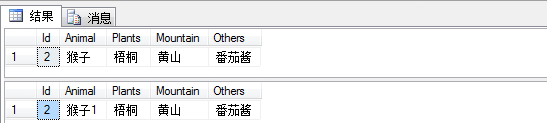
read committed隔离级别的例子:
begin tran
update Earth set Animal='老虎'
waitfor delay '0:0:10' --等待5秒执行下面的语句
rollback tran
开另外一个查询窗口执行下面语句
set tran isolation level read committed
select * from Earth ---获取不到老虎,不能脏读
update Earth set Animal='猴子1' --可以修改
waitfor delay '0:0:10' --10秒之后上一个事务已经回滚
select * from Earth --修改之后的数据,而不是猴子
设置锁超时时间
发生死锁的时候,数据库引擎会自动检测死锁,解决问题,然而这样子是很被动,只能在发生死锁后,等待处理。
然而我们也可以主动出击,设置锁超时时间,一旦资源被锁定阻塞,超过设置的锁定时间,阻塞语句自动取消,释放资源,报1222错误。
好东西一般都具有两面性,调优的同时,也有他的不足之处,那就是一旦超过时间,语句取消,释放资源,但是当前报错事务,不会回滚,会造成数据错误,你需要在程序中捕获1222错误,用程序处理当前事务的逻辑,使数据正确。
--查看超时时间,默认为-
select @@lock_timeout
--设置超时时间
set lock_timeout --为0时,即为一旦发现资源锁定,立即报错,不在等待,当前事务不回滚,设置时间需谨慎处理后事啊,你hold不住的。
SQLServer中的事务与锁的更多相关文章
- 【SqlServer】解析SqlServer中的事务
目录结构: contents structure [+] 事务是什么 控制事务 数据并发访问产生的影响 事务的隔离级别 锁 NOLOCK.HOLDLOCK.UPDLOCK 死锁分析 在这篇Blog中, ...
- 【转】SQL Server中的事务与锁
SQL Server中的事务与锁 了解事务和锁 事务:保持逻辑数据一致性与可恢复性,必不可少的利器. 锁:多用户访问同一数据库资源时,对访问的先后次序权限管理的一种机制,没有他事务或许将会一塌糊涂 ...
- SQLServer中的事物与锁
了解事务和锁 事务:保持逻辑数据一致性与可恢复性,必不可少的利器. 锁:多用户访问同一数据库资源时,对访问的先后次序权限管理的一种机制,没有他事务或许将会一塌糊涂,不能保证数据的安全正确读写. 死锁: ...
- SQL Server中的事务与锁
了解事务和锁 事务:保持逻辑数据一致性与可恢复性,必不可少的利器. 锁:多用户访问同一数据库资源时,对访问的先后次序权限管理的一种机制,没有他事务或许将会一塌糊涂,不能保证数据的安全正确读写. 死锁: ...
- SqlServer中的事务使用
一.事务的概念和特点 事务(transaction)是恢复和并发控制的基本单位. 事务的特点 原子性:事务是一个工作单元,要都成功,要么的失败 例子:A付款给B,A余额-100,B余额+100,只能都 ...
- [转载]SQL Server中的事务与锁
了解事务和锁 事务:保持逻辑数据一致性与可恢复性,必不可少的利器. 锁:多用户访问同一数据库资源时,对访问的先后次序权限管理的一种机制,没有他事务或许将会一塌糊涂,不能保证数据的安全正确读写. 死锁: ...
- T-SQL查询进阶--SQL Server中的事务与锁
为什么需要锁 在任何多用户的数据库中,必须有一套用于数据修改的一致的规则,当两个不同的进程试图同时修改同一份数据时,数据库管理系统(DBMS)负责解决它们之间潜在的冲突.任何关系数据库必须支持事务的A ...
- 十五、SQL Server中的事务与锁
(转载别人的内容,值得Mark) 了解事务和锁 事务:保持逻辑数据一致性与可恢复性,必不可少的利器. 锁:多用户访问同一数据库资源时,对访问的先后次序权限管理的一种机制,没有他事务或许将会一塌糊涂,不 ...
- 知方可补不足~Sqlserver中的几把锁和.net中的事务级别
回到目录 当数据表被事务锁定后,我们再进行select查询时,需要为with(锁选项)来查询信息,如果不加,select将会被阻塞,直到锁被释放,下面介绍几种SQL的锁选项 SQL的几把锁 NOLOC ...
随机推荐
- NuGet及快速安装使用
关于NuGet园子里已经有不少介绍及使用经验,本文仅作为自己研究学习NuGet一个记录. 初次认识NuGet是在去年把项目升级为MVC3的时候,当时看到工具菜单多一项Library Package M ...
- Java基础语法总结1
一.标识符及字符集 Java语言规定标识符是以字母.下划线"_"或美元符号"$"开始,随后可跟数字.字母.下划线或美元符号的字符序列.Java标识符大小写敏感, ...
- Windows Azure Backup Agent安装注意事项
在Windows Server 2008 R2 SP1上安装Windows Azure Backup Agent时会出现错误: “Unable to execute the embedded appl ...
- html5 datalist自动完成
1.传统输入框 <label for="favorite_team">Favorite Team:</label> <input type=" ...
- Unity自学路线整理(参看微信公众号Unity墙外的世界的文章 )
目前还是个新手. 发现自己有时候还是会一脸蒙...的对着电脑屏幕不知所措,为了利用好在大学零散的时间所以整理一下学习unity的路线. 计划好才能更好的利用时间. 1. 先学好C#再去看引擎,我看的是 ...
- Use getopt() & getopt_long() to Parse Arguments
Today I came across a function [getopt] by accident. It is very useful to parse command-line argumen ...
- 【原创Android游戏】--猜数字游戏Version 0.1
想当年高中时经常和小伙伴在纸上或者黑板上或者学习机上玩猜数字的游戏,在当年那个手机等娱乐设备在我们那还不是很普遍的时候是很好的一个消遣的游戏,去年的时候便写了一个Android版的猜数字游戏,只是当时 ...
- switch结构的用法
已知学生的名字和百分制分数.要求根据学生的百分制分数,分别采用"满分","优秀","良好","及格"和"不及格 ...
- IIS7.5中神秘的ApplicationPoolIdentity
IIS7.5中(仅win7,win2008 SP2,win2008 R2支持),应用程序池的运行帐号,除了指定为LocalService,LocalSystem,NetWorkService这三种基本 ...
- sturct2类型转化
第三种struts2类型转换方式实例 1.convert.jsp <%@ page language="java" import="java.util.*" ...