爬虫框架Scrapy之详解
Scrapy 框架
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 使用了 Twisted
['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
Scrapy架构图(绿线是数据流向):
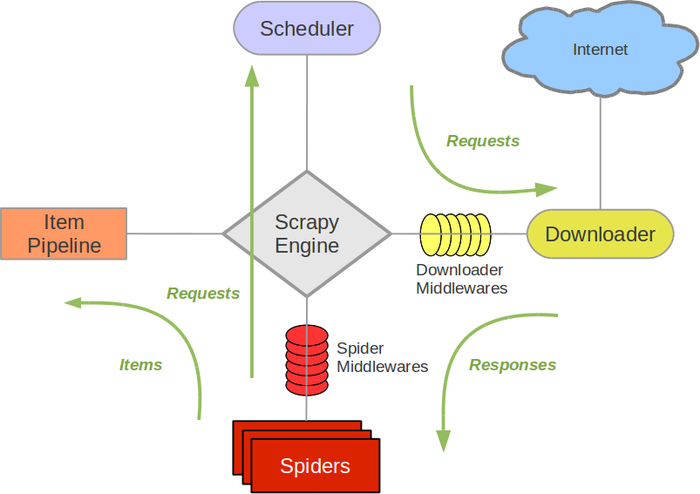

Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
Scrapy的运作流程
代码写好,程序开始运行...
引擎:Hi!Spider, 你要处理哪一个网站?Spider:老大要我处理xxxx.com。引擎:你把第一个需要处理的URL给我吧。Spider:给你,第一个URL是xxxxxxx.com。引擎:Hi!调度器,我这有request请求你帮我排序入队一下。调度器:好的,正在处理你等一下。引擎:Hi!调度器,把你处理好的request请求给我。调度器:给你,这是我处理好的request引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。引擎:Hi !管道我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。管道``调度器:好的,现在就做!
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy也会重新下载。)
制作 Scrapy 爬虫 一共需要4步:
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
爬虫框架Scrapy之详解的更多相关文章
- python爬虫框架scrapy实例详解
生成项目scrapy提供一个工具来生成项目,生成的项目中预置了一些文件,用户需要在这些文件中添加自己的代码.打开命令行,执行:scrapy st... 生成项目 scrapy提供一个工具来生成项目,生 ...
- Scrapy 爬虫框架入门案例详解
欢迎大家关注腾讯云技术社区-博客园官方主页,我们将持续在博客园为大家推荐技术精品文章哦~ 作者:崔庆才 Scrapy入门 本篇会通过介绍一个简单的项目,走一遍Scrapy抓取流程,通过这个过程,可以对 ...
- 第三百五十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy信号详解
第三百五十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy信号详解 信号一般使用信号分发器dispatcher.connect(),来设置信号,和信号触发函数,当捕获到信号时执行 ...
- 教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http://www.xiaohuar.com/,让你体验爬取校花的成就感. Scr ...
- java的集合框架最全详解
java的集合框架最全详解(图) 前言:数据结构对程序设计有着深远的影响,在面向过程的C语言中,数据库结构用struct来描述,而在面向对象的编程中,数据结构是用类来描述的,并且包含有对该数据结构操作 ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- 爬虫框架Scrapy
前面十章爬虫笔记陆陆续续记录了一些简单的Python爬虫知识, 用来解决简单的贴吧下载,绩点运算自然不在话下. 不过要想批量下载大量的内容,比如知乎的所有的问答,那便显得游刃不有余了点. 于是乎,爬虫 ...
- 第三篇:爬虫框架 - Scrapy
前言 Python提供了一个比较实用的爬虫框架 - Scrapy.在这个框架下只要定制好指定的几个模块,就能实现一个爬虫. 本文将讲解Scrapy框架的基本体系结构,以及使用这个框架定制爬虫的具体步骤 ...
- 网络爬虫框架Scrapy简介
作者: 黄进(QQ:7149101) 一. 网络爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本:它是一个自动提取网页的程序,它为搜索引擎从万维 ...
随机推荐
- NSUserDefault 保存自定义对象
由于NSUserDefaults 不支持保存自定类,保存的对象需要实现NSCoding协议,不过自定的类型就算实现了NSCoding也不可以保存,可以通过以下方法实现: //h文件 #import & ...
- Golang开发支持平滑升级(优雅重启)的HTTP服务
Golang开发支持平滑升级(优雅重启)的HTTP服务 - tabalt的博客 http://tabalt.net/blog/graceful-http-server-for-golang/ http ...
- glibc-2.23_large_bin链接方式_浅析
上面两个图应该合并为一个图,但是指针太多了,合并在一起看不清了,所以分成两张图 所有的块都通过fd和bk两个指针链接,但是为了加快查询速度,不同大小的chunk通过fd_nextsize和bk_nex ...
- sublime text 3 配置方法
一.安装sublime text 3 1>.执行sublime text 3的安装包(.exe)文件安装成功后,进入sublime的安装目录(例如:D:\Program Files\Sublim ...
- 监控之snmpd 服务
监控离不开数据采集,经常使用的Mrtg ,Cacti,Zabbix,等等监控软件都是通过snmp 协议进行数据采集的! 1 什么是snmp 协议? 简单网络管理协议(SNMP,Simple Netwo ...
- Flask路由系统与模板系统
路由系统 @app.route('/user/<username>') @app.route('/post/<int:post_id>') @app.route('/post/ ...
- H5开发APP入门
一.MUI MUI是一个最接近原生APP体验的高性能前端框架.我们用它来排版布局. 官方网站:http://dev.dcloud.net.cn/mui/ 二.HTML5PLUS html5+是HBul ...
- Java-多线程基本
Java-多线程基本 一 相关的概念 进程:是一个正在执行中的程序 每个进程都有一个执行的顺序,该顺序是一个执行路径,或者叫一个控制单元 线程:就是进程中的一个独立的控制单元,线程在控制着进程的执行 ...
- ASP.NET的优点
ASP.NET 是一个统一的 Web 开发平台,它提供开发人员创建企业级 Web 应用程序所需的服务.尽管 ASP.NET 的语法基本上与 ASP 兼容,但是它还提供了一个新的编程模型和基础结构以提高 ...
- 机器学习第7周-炼数成金-支持向量机SVM
支持向量机SVM 原创性(非组合)的具有明显直观几何意义的分类算法,具有较高的准确率源于Vapnik和Chervonenkis关于统计学习的早期工作(1971年),第一篇有关论文由Boser.Guyo ...