基于HDP3.0的基础测试
1,TestDFSIO write和read的性能测试, 测试hadoop读写的速度。该测试为Hadoop自带的测试工具,位于$HADOOP_HOME/share/hadoop/mapreduce目录中,主要用于测试DFS的IO性能。
写入:
hadoop jar hadoop-mapreduce-client-jobclient-3.1.0.3.0.0.0-1634-tests.jar TestDFSIO -write -nrFiles -size 10MB -resFile /tmp/TestDFSIOresults.txt
读取:
hadoop jar hadoop-mapreduce-client-jobclient-3.1.0.3.0.0.--tests.jar TestDFSIO -read -nrFiles -size -resFile /tmp/TestDFSIOresults.txt
清空数据:
hadoop jar /usr/hdp/3.0.0.0-/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-tests.jar TestDFSIO -clean
2,TeraSort是由微软的数据库专家Jim Gray创建的标准benchmark,输入数据由Hadoop TeraGen产生。
生成数据:
hadoop jar /usr/hdp/3.0.0.0-/hadoop-mapreduce/hadoop-mapreduce-examples.jar teragen 数据量 数据位置
使用teragen方法进行排序:
hadoop jar /usr/hdp/3.0.0.0-/hadoop-mapreduce/hadoop-mapreduce-examples.jar terasort 输入文件位置/par* 输出文件位置
3,HiBench是一个大数据基准测试工具,它包含hadoopbench、sparkbench、flinkbench、stormbench、gearpumpbench等多个模块。我们可以从github上下载源码:
https://codeload.github.com/intel-hadoop/HiBench/zip/6.0
到Maven官网或其他镜像站点下载Maven:
[root@n2 ~]# wget \ http://mirror.bit.edu.cn/apache/maven/maven-3/3.5.3/binaries/apache-maven-3.5.3-bin.tar.gz
解压tarball,并配置Maven环境变量:
tar -xzvf apache-maven-3.5.-bin.tar.gz -C /opt/
添加如下两行到配置文件/etc/profile:
export MAVEN_HOME=/opt/apache-maven-3.5.
export PATH=$MAVEN_HOME/bin:$PATH
查看maven版本:
mvn -v
要在HiBench中简单构建所有模块,请使用以下命令:
mvn -Dspark=2.1 -Dscala=2.11 clean package
但这样会编译所有模板,耗费大量时间,因为hadoopbench依赖于Mahout和Nutch等第三方工具,编译过程会自动下载这些工具。如果我们运行这些模块,也可以只构建特定的框架来加速编译过程。
这里,我们只编译编译HadoopBench:
mvn -Phadoopbench -Dspark=2.1 -Dscala=2.11 clean package

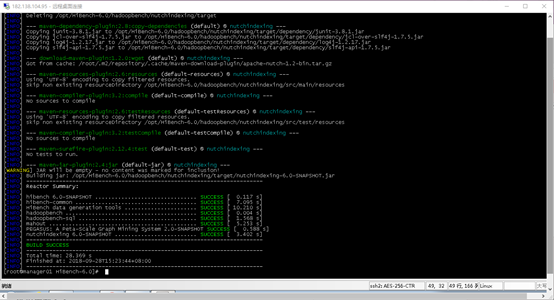
详细说明请参见官方文档:
https://github.com/intel-hadoop/HiBench/blob/master/docs/build-hibench.md
3.1,指定hadoop配置
在配置文件conf/hadoop.conf中,定义hadoop相关信息:
|
属性 |
值 |
备注 |
|
hibench.hadoop.home |
/usr/hdp/3.0.0.0-1634/hadoop-mapreduce |
Hadoop安装目录 |
|
hibench.hadoop.executable |
${hibench.hadoop.home}/../hadoop/bin/hadoop |
Hadoop可执行文件路径 |
|
hibench.hadoop.configure.dir |
${hibench.hadoop.home}/etc/hadoop |
Hadoop配置文件目录 |
|
hibench.hdfs.master |
nas:///hibench |
HiBench测试数据存放路径 |
|
hibench.hadoop.release |
hdp |
Hadoop版本:apache/cdh5/hdp |

3.2,定义数据量级
在配置文件conf/hibench.conf中,定义数据量级别,如:
hibench.scale.profile = large
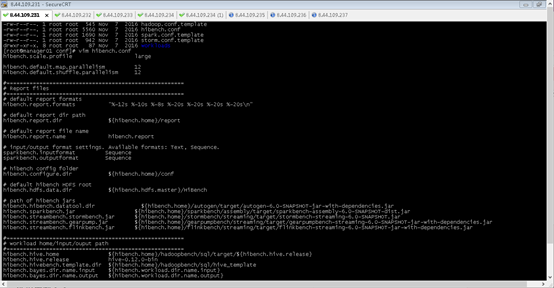
不同级别的实际数据量,定义在配置文件conf/workloads/micro/wordcount.conf:
|
参数 |
属性 |
值 (byte) |
|
tiny |
hibench.wordcount.tiny.datasize |
32000 |
|
small |
hibench.wordcount.small.datasize |
320000000 |
|
large |
hibench.wordcount.large.datasize |
3200000000 |
|
huge |
hibench.wordcount.huge.datasize |
32000000000 |
|
gigantic |
hibench.wordcount.gigantic.datasize |
320000000000 |
|
bigdata |
hibench.wordcount.bigdata.datasize |
1600000000000 |
3.3,其他运行参数
还可以在配置文件conf/hibench.conf中,定义其他一些运行参数,如mapper数量、report文件路径等参数,如:
|
属性 |
默认值 |
备注 |
|
hibench.default.map.parallelism |
8 |
Mapper数量 |
|
hibench.default.shuffle.parallelism |
8 |
Reducer数量 |
|
hibench.report.dir |
${hibench.home}/report |
Report文件路径 |
|
hibench.report.name |
hibench.report |
Report文件名 |
3.4,运行程序
运行测试数据
./bin/workloads/micro/wordcount/prepare/prepare.sh

使用测试数据进行测试
./bin/workloads/micro/wordcount/Hadoop/run.sh
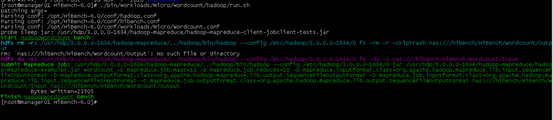
等等 后续补充
基于HDP3.0的基础测试的更多相关文章
- 基于JAVA语言的selenium测试基础总结
目录一.基本语句1.循环控制(break,continue)3.字符的替换(replace,repalceFirst,replaceAll,regex)4.字符串的连接("+",a ...
- 敏捷测试(6)--基于story的敏捷基础知识
基于story的敏捷基础知识----需求管理(三) (3)每日站会 站会的目的有三个: (1)周知进度 仅从用户故事和任务的层面周知进度,任务进度只有两种状态:完成或未完成(完成百分比). (2)周知 ...
- 敏捷测试(4)--基于story的敏捷基础知识
基于story的敏捷基础知识----需求管理(一) 基于story进行需求管理 (1)使用story模式来管理需求,将庞大的MRD划分为一个个合适粒度,且可独立交付的story(通常每个story能在 ...
- 敏捷测试(3)--基于story的敏捷基础知识
基于story的敏捷基础知识----story编写 为什么使用Story? 软件行业40年多来,需求分析技术已经很成熟了,但是MRD驱动的过程不堪重负.因为往往MRD编写会占去很多时间,MRD评审又会 ...
- 基于USB3.0的双目相机测试小结之CC1605配合CS5642 双目 500w摄像头
基于USB3.0的双目相机测试小结之CC1605配合CS5642 双目 500w摄像头 CC1605双目相机评估板可以配合使用柴草电子绝大多数摄像头应用 如:OV5640.OV5642.MT9P03 ...
- 敏捷测试(7)--基于story的敏捷基础知识
基于story的敏捷基础知识----迭代启动会.迭代回顾会 除需求讲解意外,需要所有团队成员参加的会议仅有两个,分别是"迭代启动会"和"迭代回顾会". (1)迭 ...
- 敏捷测试(5)--基于story的敏捷基础知识
基于story的敏捷基础知识----需求管理(二) (1)定期发布 定期发布上线,把整个项目划分为一个个迭代,每个迭代时间大小固定(基本固定),迭代结束时上线交付一次. (2)迭代规划 迭代规划相当于 ...
- mysql基础测试
mysql基础测试 测试原因 为什么需要做性能测试 模拟比当前系统更高的负载,找出性能瓶颈 重现线上异常 测试不同硬件软件配置 规划未来的业务增长 测试分类 性能测试的分类 设备层的测试 ...
- Exploratory Testing 3.0 - 探索式测试
最近看了James Bach新发的一篇文章,名为Exploratory Testing 3.0,文章链接:http://www.satisfice.com/blog/archives/1509 这篇文 ...
随机推荐
- [转]精选!15个必备的VSCode插件
Visual Studio Code 是由微软开发的一款免费.跨平台的文本编辑器.由于其卓越的性能和丰富的功能,它很快就受到了大家的喜爱. 就像大多数 IDE 一样,VSCode 也有一个扩展和主题市 ...
- python apply()函数
python apply函数的具体的含义: apply(func [, args [, kwargs ]]) 函数用于当函数参数已经存在于一个元组或字典中时,间接地调用函数.args是一个包含将要提供 ...
- UVALive - 6893 The Big Painting 字符串哈希
题目链接: http://acm.hust.edu.cn/vjudge/problem/129730 The Big Painting Time Limit: 5000MS 题意 给你一个模板串和待匹 ...
- HDU 5233 Gunner II 离散化
题目链接: hdu:http://acm.hdu.edu.cn/showproblem.php?pid=5233 bc(中文):http://bestcoder.hdu.edu.cn/contests ...
- 阅读笔记《我是一只IT小小鸟》
我是一只IT小小鸟 我们在尝试新的事物的时候,总是会遇到各种各样的困难,不同的人会在碰壁不同的次数之后退出.用程序员喜欢的话来说就是,我们都在for循环,区别在于你是什么情况下break;的.有的人退 ...
- Alpha事后诸葛亮(团队)
设想和目标 1.我们的软件要解决什么问题?是否定义得很清楚?是否对典型用户和典型场景有清晰的描述? 我们的软件要解决用手机使没有指纹验证硬件的电脑可以利用指纹进行文件的加密.定义的很清楚.我们针对的是 ...
- 解决zabbix使用中文是出现乱码的问题
解决zabbix使用中文是出现乱码的问题 ①:上传windows的simhei.ttf字体到zabbix服务器的/usr/share/zabbix/fonts/目录下 ②:编辑/usr/sh ...
- 使用JsonConfig中的setExcludes方法过滤不需要转换的属性
Hibernate的many-to-one双向关联中,查询many方时会将one方数据顺带着查询,同时one中会有List<Many>,然后又会去查Many中的数据... 周而复始,结果j ...
- c 用指针操作结构体数组
重点:指针自加,指向下一个结构体数组单元 #include <stdio.h> #include <stdlib.h> #include <string.h> #d ...
- Redis 备份数据的两种方式
既然是数据库,那就一定有数据备份方式了,而且 Redis 是内存形式的数据库,更需要数据备份了,要不然断电数据就全都丢失了. Redis 数据备份有两种方式: RDB(数据快照) AOF(记录操作日志 ...