13.solr学习速成之IK分词器
IKAnalyzer简介

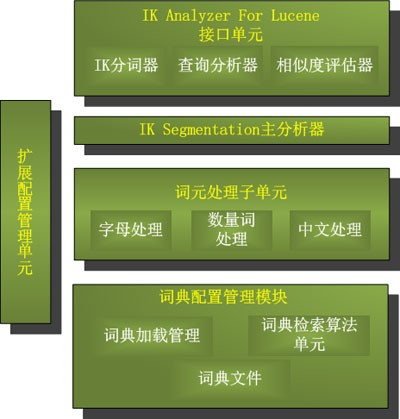
IKAnalyzer特性
IK分词算法理解
其它分词器
IK与solr的集成
1.添加jar
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true"/>
</analyzer>
</fieldType>
有了这个fieldType,我们顺便改一个text_ik的field
<!--
<field name="title" type="text_general" indexed="true" stored="true" multiValued="true"/>
-->
<field name="title" type="text_ik" indexed="true" stored="true" multiValued="true"/>
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic;</entry> <!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry> </properties>
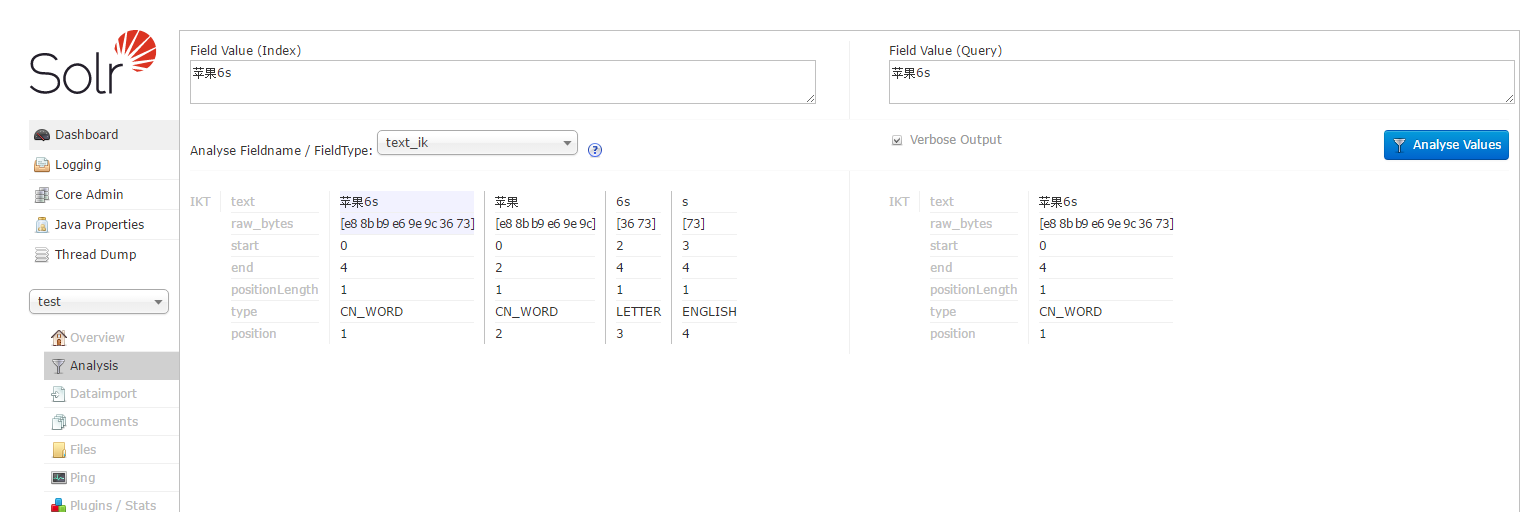
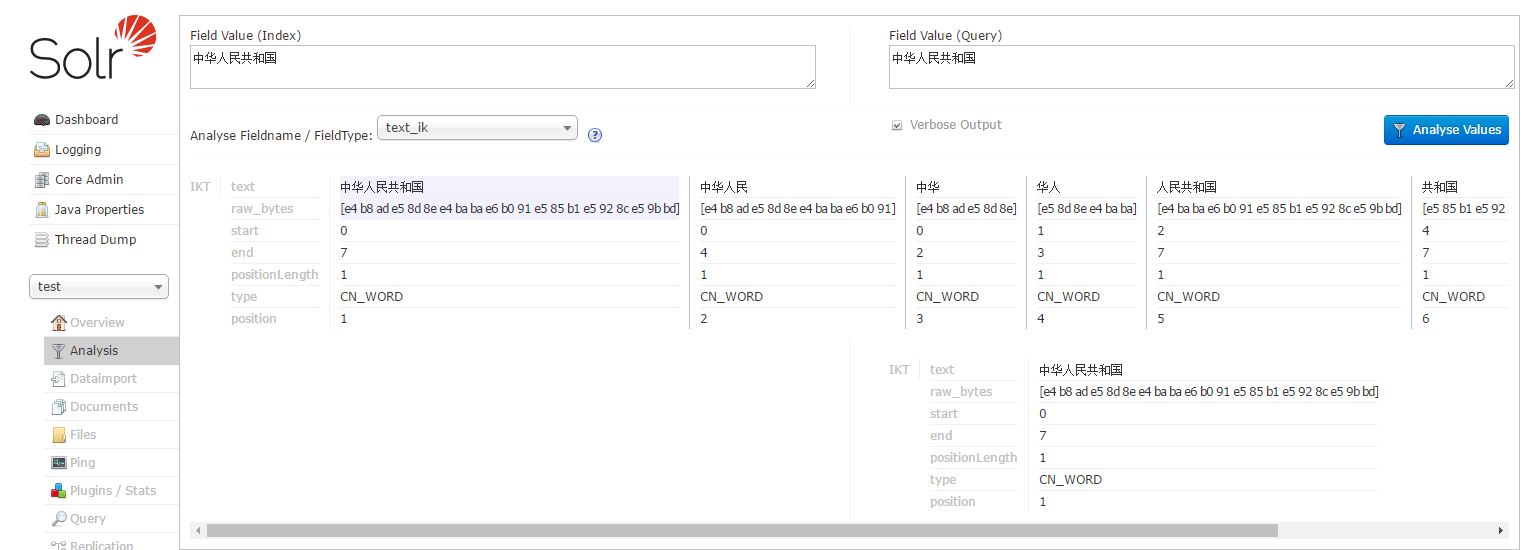
13.solr学习速成之IK分词器的更多相关文章
- Solr 06 - Solr中配置使用IK分词器 (配置schema.xml)
目录 1 配置中文分词器 1.1 准备IK中文分词器 1.2 配置schema.xml文件 1.3 重启Tomcat并测试 2 配置业务域 2.1 准备商品数据 2.2 配置商品业务域 2.3 配置s ...
- Solr4.4入门,介绍Solr的安装、IK分词器的配置及高亮查询结果(转)
一.Windows下安装solr-4.4.0 1. 下载solr.4.4 2. 下载绿色版tomcat6.0.18 3. 解压下载的solr到d:\study\solr,将dist目录下的sol ...
- 原创:CentOS6.4配置solr 4.7.2+IK分词器
本文原创,转载请注明出处 相关资源下载:http://pan.baidu.com/s/1pJPpiqv 1.首先说明一下 solr是java语言开发的企业级应用服务器,所以你首先安装好jdk,配置好j ...
- Solr(四)Solr实现简单的类似百度搜索高亮功能-1.配置Ik分词器
配置Ik分词器 一 效果图 二 实现此功能需要添加分词器,在这里使用比较主流的IK分词器. 1 没有配置IK分词器,用solr自带的text分词它会把一句话分成单个的字. 2 配置IK分词器,的话它会 ...
- Elasticsearch学习系列一(部署和配置IK分词器)
Elasticsearch简介 Elasticsearch是什么? Elaticsearch简称为ES,是一个开源的可扩展的分布式的全文检索引擎,它可以近乎实时的存储.检索数据.本身扩展性很好,可扩展 ...
- [Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例一.
在这里一下讲解着三个的安装和配置, 是因为solr需要使用tomcat和IK分词器, 这里会通过图文教程的形式来详解它们的安装和使用.注: 本文属于原创文章, 如若转载,请注明出处, 谢谢.关于设置I ...
- [Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例二.
为了更好的排版, 所以将IK分词器的安装重启了一篇博文, 大家可以接上solr的安装一同查看.[Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例一: http://ww ...
- Solr和IK分词器的整合
IK分词器相对于mmseg4J来说词典内容更加丰富,但是没有mmseg4J灵活,后者可以自定义自己的词语库.IK分词器的配置过程和mmseg4J一样简单,其过程如下: 1.引入IKAnalyzer.j ...
- Solr——配置IK分词器
首先需要的准备好jdk1.8和tomcat8以及ik分词器(ik分词器是5.x的版本,和solr4.10搭配的版本不一样,虽然是5.x的版本但是也是能使用在solr7.2版本上的) 分享链接https ...
随机推荐
- EasyRTMP+EasyRTSPClient实现的多路(支持断线重连)RTSP转RTMP直播推流工具
本文转自EasyDarwin开源团队成员Kim的博客:http://blog.csdn.net/jinlong0603/article/details/73441405 介绍 EasyRTMP是Eas ...
- apache 支持.htaccess重写url
1. httpd.conf 添加: <Directory /> Options +Indexes +FollowSymLinks +Multiviews AllowOverride all ...
- 高德地图Demo运行报错 com.android.ide.common.process.ProcessException: Failed to execute aapt
最近由于有需求去做导航方面的Android开发,很是无奈,以前也的确是没有搞过,领导开大会当着所有人的面说这是给我分配的第一个工作,无论如何要做好,突然间感觉压力好大,自己已经多年没有敲过代码,而且A ...
- IOS在Document目录下创建文件夹、保存、读取、以及删除文件
// 在Documents目录下创建一个名为LaunchImage的文件夹 NSString *path = [[NSHomeDirectory() stringByAppendingPathComp ...
- Failed to read schema document
转自:http://eric-yan.iteye.com/blog/1908470 问题描述: web项目web.xml编译错误: schema_reference.4: Failed to read ...
- selenium-java,UI自动化截图方法
截图方法: import java.io.File; import java.io.IOException; import org.apache.commons.io.FileUtils; impor ...
- Hadoop_10_11虚拟机02_虚拟机桥接方式联网【自己的亲测笔记】
[桥接方式] 说明:自己搭建的时候用的是桥接,因为用的是2两个物理机搭建3台虚拟机所以采用桥接便于三个虚拟机在一个网段,但是不知道对后期有没有影响,目前搭建成功 (1)设置桥接方式 查看本地连接网 ...
- 【java基础】java中Object对象中的Hashcode方法的作用
以下是关于HashCode的官方文档定义: hashcode方法返回该对象的哈希码值.支持该方法是为哈希表提供一些优点,例如,java.util.Hashtable 提供的哈希表. hashCode ...
- 怎么安装Docker CE 17( Centos 7)
Docker CE for Centos 7 yum install -y yum-utils device-mapper-persistent-data lvm2 yum-config-manage ...
- Proteus 仿真运算放大器出现 GMIN 问题
Proteus 仿真运算放大器出现 GMIN 问题 为了仿真一个反相运算放大器,在仿真时出现 GMIN 问题,将 后面的 4.7UF 去掉就可以正常仿真. 初步检查是因为输入频率太低,输入时我用的是 ...