hadoop开发环境部署——通过eclipse远程连接hadoop2.7.3进行开发
一、前言
环境:
- 系统:centos6.5
- hadoop版本:Apache hadoop2.7.3(Windows和centos都是同一个)
- eclipse版本:4.2.0(juno版本,windows)
- ant版本:ant 1.7.1(windows)
- java版本:1.8.0_05(windows)
我是在虚拟机中安装的系统,具体的安装和配置参考:Hadoop单机伪分布部署。
二、制作插件
1. 下载hadoop2x-eclipse-plugin-master.zip
在github下载:https://github.com/winghc/hadoop2x-eclipse-plugin。
2. 修改配置
原来的配置是编译2.4.1的,为了编译成2.7.3版本,首先需要改2个文件。
1) 修改hadoop2x-eclipse-plugin-master/src/contrib/eclipse-plugin/build.xml
在第82行 找到 <target name="jar" depends="compile" unless="skip.contrib">标签,找到下面的子标签(在127行):
<copy file="${hadoop.home}/share/hadoop/common/lib/htrace-core-${htrace.version}.jar" todir="${build.dir}/lib" verbose="true"/>
删掉这行,然后在下面增加多三行信息:
<copy file="${hadoop.home}/share/hadoop/common/lib/htrace-core-${htrace.version}-incubating.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/servlet-api-${servlet-api.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/commons-io-${commons-io.version}.jar" todir="${build.dir}/lib" verbose="true"/>
然后找到标签<attribute name="Bundle-ClassPath",在下面的标签中,删除lib/htrace-core-${htrace.version}.jar这行,同样加多三行:
lib/servlet-api-${servlet-api.version}.jar,
lib/commons-io-${commons-io.version}.jar,
lib/htrace-core-${htrace.version}-incubating.jar"
修改完的文件:
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
--> <project default="jar" name="eclipse-plugin"> <import file="../build-contrib.xml"/> <path id="eclipse-sdk-jars">
<fileset dir="${eclipse.home}/plugins/">
<include name="org.eclipse.ui*.jar"/>
<include name="org.eclipse.jdt*.jar"/>
<include name="org.eclipse.core*.jar"/>
<include name="org.eclipse.equinox*.jar"/>
<include name="org.eclipse.debug*.jar"/>
<include name="org.eclipse.osgi*.jar"/>
<include name="org.eclipse.swt*.jar"/>
<include name="org.eclipse.jface*.jar"/> <include name="org.eclipse.team.cvs.ssh2*.jar"/>
<include name="com.jcraft.jsch*.jar"/>
</fileset>
</path> <path id="hadoop-sdk-jars">
<fileset dir="${hadoop.home}/share/hadoop/mapreduce">
<include name="hadoop*.jar"/>
</fileset>
<fileset dir="${hadoop.home}/share/hadoop/hdfs">
<include name="hadoop*.jar"/>
</fileset>
<fileset dir="${hadoop.home}/share/hadoop/common">
<include name="hadoop*.jar"/>
</fileset>
</path> <!-- Override classpath to include Eclipse SDK jars -->
<path id="classpath">
<pathelement location="${build.classes}"/>
<!--pathelement location="${hadoop.root}/build/classes"/-->
<path refid="eclipse-sdk-jars"/>
<path refid="hadoop-sdk-jars"/>
</path> <!-- Skip building if eclipse.home is unset. -->
<target name="check-contrib" unless="eclipse.home">
<property name="skip.contrib" value="yes"/>
<echo message="eclipse.home unset: skipping eclipse plugin"/>
</target> <target name="compile" depends="init, ivy-retrieve-common" unless="skip.contrib">
<echo message="contrib: ${name}"/>
<javac
encoding="${build.encoding}"
srcdir="${src.dir}"
includes="**/*.java"
destdir="${build.classes}"
debug="${javac.debug}"
deprecation="${javac.deprecation}">
<classpath refid="classpath"/>
</javac>
</target> <!-- Override jar target to specify manifest -->
<target name="jar" depends="compile" unless="skip.contrib">
<mkdir dir="${build.dir}/lib"/>
<copy todir="${build.dir}/lib/" verbose="true">
<fileset dir="${hadoop.home}/share/hadoop/mapreduce">
<include name="hadoop*.jar"/>
</fileset>
</copy>
<copy todir="${build.dir}/lib/" verbose="true">
<fileset dir="${hadoop.home}/share/hadoop/common">
<include name="hadoop*.jar"/>
</fileset>
</copy>
<copy todir="${build.dir}/lib/" verbose="true">
<fileset dir="${hadoop.home}/share/hadoop/hdfs">
<include name="hadoop*.jar"/>
</fileset>
</copy>
<copy todir="${build.dir}/lib/" verbose="true">
<fileset dir="${hadoop.home}/share/hadoop/yarn">
<include name="hadoop*.jar"/>
</fileset>
</copy> <copy todir="${build.dir}/classes" verbose="true">
<fileset dir="${root}/src/java">
<include name="*.xml"/>
</fileset>
</copy> <copy file="${hadoop.home}/share/hadoop/common/lib/protobuf-java-${protobuf.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/log4j-${log4j.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/commons-cli-${commons-cli.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/commons-configuration-${commons-configuration.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/commons-lang-${commons-lang.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/commons-collections-${commons-collections.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/jackson-core-asl-${jackson.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/jackson-mapper-asl-${jackson.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/slf4j-log4j12-${slf4j-log4j12.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/slf4j-api-${slf4j-api.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/guava-${guava.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/hadoop-auth-${hadoop.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/commons-cli-${commons-cli.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/netty-${netty.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/htrace-core-${htrace.version}-incubating.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/servlet-api-${servlet-api.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/commons-io-${commons-io.version}.jar" todir="${build.dir}/lib" verbose="true"/> <jar
jarfile="${build.dir}/hadoop-${name}-${hadoop.version}.jar"
manifest="${root}/META-INF/MANIFEST.MF">
<manifest>
<attribute name="Bundle-ClassPath"
value="classes/,
lib/hadoop-mapreduce-client-core-${hadoop.version}.jar,
lib/hadoop-mapreduce-client-common-${hadoop.version}.jar,
lib/hadoop-mapreduce-client-jobclient-${hadoop.version}.jar,
lib/hadoop-auth-${hadoop.version}.jar,
lib/hadoop-common-${hadoop.version}.jar,
lib/hadoop-hdfs-${hadoop.version}.jar,
lib/protobuf-java-${protobuf.version}.jar,
lib/log4j-${log4j.version}.jar,
lib/commons-cli-${commons-cli.version}.jar,
lib/commons-configuration-${commons-configuration.version}.jar,
lib/commons-httpclient-${commons-httpclient.version}.jar,
lib/commons-lang-${commons-lang.version}.jar,
lib/commons-collections-${commons-collections.version}.jar,
lib/jackson-core-asl-${jackson.version}.jar,
lib/jackson-mapper-asl-${jackson.version}.jar,
lib/slf4j-log4j12-${slf4j-log4j12.version}.jar,
lib/slf4j-api-${slf4j-api.version}.jar,
lib/guava-${guava.version}.jar,
lib/netty-${netty.version}.jar,
lib/servlet-api-${servlet-api.version}.jar,
lib/commons-io-${commons-io.version}.jar,
lib/htrace-core-${htrace.version}-incubating.jar"/>
</manifest>
<fileset dir="${build.dir}" includes="classes/ lib/"/>
<!--fileset dir="${build.dir}" includes="*.xml"/-->
<fileset dir="${root}" includes="resources/ plugin.xml"/>
</jar>
</target> </project>
2) 修改hadoop2x-eclipse-plugin-master/ivy/libraries.properties
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License. #This properties file lists the versions of the various artifacts used by hadoop and components.
#It drives ivy and the generation of a maven POM # This is the version of hadoop we are generating
#hadoop.version=2.6.0 modify
hadoop.version=2.7.3
hadoop-gpl-compression.version=0.1.0 #These are the versions of our dependencies (in alphabetical order)
apacheant.version=1.7.1
ant-task.version=2.0.10 asm.version=3.2
aspectj.version=1.6.5
aspectj.version=1.6.11 checkstyle.version=4.2 commons-cli.version=1.2
commons-codec.version=1.4
#commons-collections.version=3.2.1 modify
commons-collections.version=3.2.2
commons-configuration.version=1.6
commons-daemon.version=1.0.13
#commons-httpclient.version=3.0.1 modify
commons-httpclient.version=3.1
commons-lang.version=2.6
#commons-logging.version=1.0.4 modify
commons-logging.version=1.1.3
#commons-logging-api.version=1.0.4 modify
commons-logging-api.version=1.1.3
#commons-math.version=2.1 modify
commons-math.version=3.1.1
commons-el.version=1.0
commons-fileupload.version=1.2
#commons-io.version=2.1 modify
commons-io.version=2.4
commons-net.version=3.1
core.version=3.1.1
coreplugin.version=1.3.2 #hsqldb.version=1.8.0.10 modify
hsqldb.version=2.0.0
#htrace.version=3.0.4 modify
htrace.version=3.1.0 ivy.version=2.1.0 jasper.version=5.5.12
jackson.version=1.9.13
#not able to figureout the version of jsp & jsp-api version to get it resolved throught ivy
# but still declared here as we are going to have a local copy from the lib folder
jsp.version=2.1
jsp-api.version=5.5.12
jsp-api-2.1.version=6.1.14
jsp-2.1.version=6.1.14
#jets3t.version=0.6.1 modify
jets3t.version=0.9.0
jetty.version=6.1.26
jetty-util.version=6.1.26
#jersey-core.version=1.8 modify
#jersey-json.version=1.8 modify
#jersey-server.version=1.8 modify
jersey-core.version=1.9
jersey-json.version=1.9
jersey-server.version=1.9
#junit.version=4.5 modify
junit.version=4.11
jdeb.version=0.8
jdiff.version=1.0.9
json.version=1.0 kfs.version=0.1 log4j.version=1.2.17
lucene-core.version=2.3.1 mockito-all.version=1.8.5
jsch.version=0.1.42 oro.version=2.0.8 rats-lib.version=0.5.1 servlet.version=4.0.6
servlet-api.version=2.5
#slf4j-api.version=1.7.5 modify
#slf4j-log4j12.version=1.7.5 modify
slf4j-api.version=1.7.10
slf4j-log4j12.version=1.7.10 wagon-http.version=1.0-beta-2
xmlenc.version=0.52
#xerces.version=1.4.4 modify
xerces.version=2.9.1 protobuf.version=2.5.0
guava.version=11.0.2
netty.version=3.6.2.Final
3. 用ant进行构建
这个时候在centos系统上,hadoop已经能够正常运行了,为了后面方便eclipse访问,关掉集群的权限校验(注意不要在生产环境这么做)。在mapred-site.xml增加一条配置:
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
重启集群。
将已经能在centos运行的hadoop2.7.3安装目录复制到windows,另外确保ant和eclipse已经配置好了,在ant命令中需要用到三个目录信息,以我本地为例:
- eclipse:C:\eclipse
- hadoop:E:\5-Hadoop\hadoop-2.7.3
- hadoop2x-eclipse-plugin-master:E:\5-Hadoop\hadoop2x-eclipse-plugin-master
进入目录E:\5-Hadoop\hadoop2x-eclipse-plugin-master\src\contrib\eclipse-plugin\
输入命令进行构建:
ant jar -Dhadoop.version=2.7.3 -Declipse.home=C:\eclipse -Dhadoop.home=E:\5-Hadoop\hadoop-2.7.3
如果路径有空格的话,记得用双引号括起来,不过建议把软件都安装没有空格的路径上。等待几分钟,显示构建成功,最后的生成的hadoop-eclipse-plugin-2.7.3.jar存放在目录E:\5-Hadoop\hadoop2x-eclipse-plugin-master\build\contrib\eclipse-plugin下。
三、配置插件
1. 安装插件
将hadoop-eclipse-plugin-2.7.3.jar放在eclipse的plugin目录中:C:\eclipse\plugins,重启eclipse。
如果顺利,打开eclipse,通过Windows->Preferences->Hadoop Map/Reduce设置安装路径:
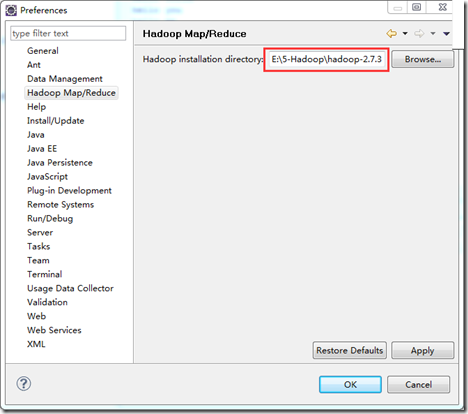
2. 设置location
通过Windows–> Show View –> Others –> Map/Redure Location ,通过图标新建一个location:

设置参数:
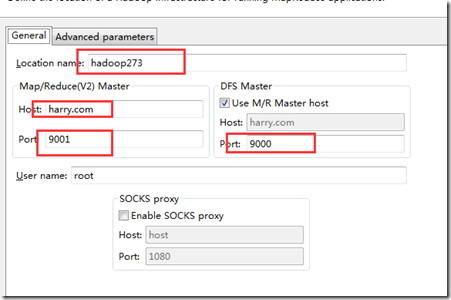
location name随便起一个,user name实际上也是默认就行,我之前以为需要填root,实际上什么名字都可以,重点是host跟两个port,在这里卡了一段时间。
实际上在centos端,我的主机名字是harry.com:

所以在windows端增加hosts配置:
192.168.0.210 harry.com
DFS Master的端口,根据hadoop的配置文件core-site.xml配置的端口去填:
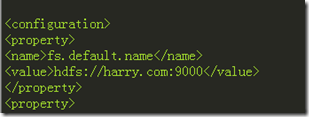
至于Map/Reduce(V2) Master据说是job tracker的端口号(可是hadoop2已经用yarn了),在mapred-site.xml配置,我没有配这个,所以直接用9001的就行了。
完成之后,在左侧应该就可以看到hdfs里面的内容了:
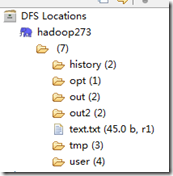
如果host和port没配对,在连接hdfs的时候可能会报错:
An internal error occurred during: "Map/Reduce location status updater". java.lang.NullPointerExcept
如何还有其他报错,请先确保集群能正常运行,关闭centos的防火墙,如果能顺利走到这步,整个部署过程就已经完成了一半了。
四、运行MapReduce作业
1. 新建测试项目
新建hadoop里的hello world程序word count,并从源码中拷贝WordCount.java过来,如下:
把包名改成Test,源码如下:
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package Test; import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
} public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
实际上,刚开始构建的时候,会报错:
The type java.util.Map$Entry cannot be resolved. It is indirectly referenced from required .class files WordCount.java /WordCount/src/Test line 1 Java Problem
查了一下,原来我的eclipse版本是Helios,而java版本是1.8,不支持。于是有两个选择:降到java1.8以下或者换更高的eclipse版本,我的选择是升eclipse版本到juno版本,问题解决。
2. 设置运行参数并运行
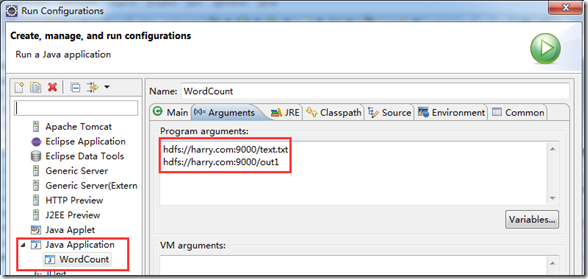
点击WordCount类,右键Run As –> Run Configurations ,点击Arguments,填写输入目录,输出目录参数:
运行,报错:
Exception in thread "main" java.io.IOException: (null) entry in command string: null chmod 0700 C:\tmp\hadoop-Administrator\mapred\staging\Administrator134847124\.staging
...
设置环境变量HADOOP_HOME为E:\5-Hadoop\hadoop-2.7.3,在 https://github.com/SweetInk/hadoop-common-2.7.1-bin 中下载winutils.exe,libwinutils.lib拷贝到%HADOOP_HOME%\bin目录,重新运行,嗯,重新报错:
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
...
在https://github.com/SweetInk/hadoop-common-2.7.1-bin中下载hadoop.dll,并拷贝到c:\windows\system32目录中。重新执行,报WARN:
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
在项目的src下面新建file名为log4j.properties的文件,内容为:
# Configure logging for testing: optionally with log file
#log4j.rootLogger=debug,appender
log4j.rootLogger=info,appender
#log4j.rootLogger=error,appender
#\u8F93\u51FA\u5230\u63A7\u5236\u53F0
log4j.appender.appender=org.apache.log4j.ConsoleAppender
#\u6837\u5F0F\u4E3ATTCCLayout
log4j.appender.appender.layout=org.apache.log4j.TTCCLayout
因为刚才其实已经运行成功了,所以这次需要先删掉hdfs中的out1目录,然后运行,然后在console中会打印出这次任务的运行数据,最后在hdfs中查看运行结果:
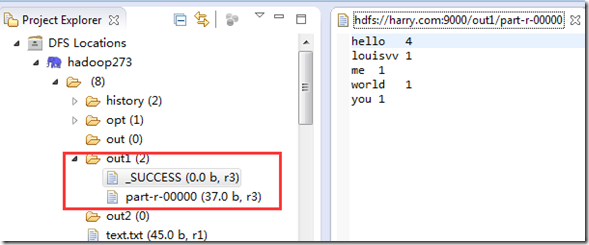
至此,终于成功利用在eclipse通过hadoop-eclipse-plugin-2.7.3.jar插件,成功连接centos下运行中的hadoop,开发环境搭建完成!!!
五、参考
1. hadoop 2.7.3 (hadoop2.x)使用ant制作eclipse插件hadoop-eclipse-plugin-2.7.3.jar
2. An internal error occurred during: "Map/Reduce location status updater". java.lang.NullPointerExcept
4. Hadoop学习笔记2:eclipse运行Mapreduce程序问题总结
5. Eclipse搭建hadoop开发环境[hadoop-eclipse-plugin-2.5.2]
7. JDK8之The type java.util.Map$Entry cannot be resolved
(完)
hadoop开发环境部署——通过eclipse远程连接hadoop2.7.3进行开发的更多相关文章
- eclipse+hbase开发环境部署
一.前言 1. 前提 因为hbase的运行模式是伪分布式,需要用到hdfs,所以在此之前,我已经完成了hadoop-eclipse的开发环境搭建,详细看另一篇文章:hadoop开发环境部署——通过ec ...
- Eclipse for C/C++ 开发环境部署保姆级教程
Eclipse for C/C++ 开发环境部署保姆级教程 工欲善其事,必先利其器. 对开发人员来说,顺手的开发工具必定事半功倍.自学编程的小白不知道该选择那个开发工具,Eclipse作为一个功能强大 ...
- windows下eclipse远程连接hadoop集群开发mapreduce
转载请注明出处,谢谢 2017-10-22 17:14:09 之前都是用python开发maprduce程序的,今天试了在windows下通过eclipse java开发,在开发前先搭建开发环境.在 ...
- Hadoop学习5--配置本地开发环境(Windows+Eclipse)
一.导入hadoop插件到eclipse 插件名称:hadoop-eclipse-plugin-2.7.0.jar 我是从网上下载的,还可以自己编译. 放到eclipse安装目录下的plugins文件 ...
- Eclipse远程连接Hadoop
Windows下面调试程序比在Linux下面调试方便一些,于是用Windows下的Eclipse远程连接Hadoop. 1. 下载相应版本的hadoop-eclipse-plugin插件,复制到ecl ...
- Hadoop项目开发环境搭建(Eclipse\MyEclipse + Maven)
写在前面的话 可详细参考,一定得去看 HBase 开发环境搭建(Eclipse\MyEclipse + Maven) Zookeeper项目开发环境搭建(Eclipse\MyEclipse + Mav ...
- Eclipse for Python开发环境部署
Eclipse for Python开发环境部署 工欲善其事,必先利其器. 对开发人员来说,顺手的开发工具必定事半功倍.自学编程的小白不知道该选择那个开发工具,Eclipse作为一个功能强大且开源免费 ...
- Eclipse For Java开发环境部署
Eclipse For Java开发环境部署 1.准备工作 jdk安装包 jdk官网下载 Eclipse安装包 Eclipse官网下载 Eclipse下载时选择图中所示的国内镜像地址下载 下载后的文件 ...
- Delphi 10.2 Linux 程序开发环境部署的基本步骤(网络连接方式要选择桥接或者是Host Only)
Delphi 10.2 Linux 程序开发环境部署的基本步骤 http://blog.qdac.cc/?p=4477 升級到 Delphi 10.2 Tokyo 笔记http://www.cnblo ...
随机推荐
- winform Textbox模糊搜索实现下拉显示+提示文字
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; usin ...
- SecureCRT导入已有会话
如果别人有完整的环境信息,我们想拿过来,怎么导入?或者别人想要我的会话配置信息,怎么导出?对SecureCRT这个工具来说很easy,根本不需要去找什么导入.导出按钮,直接文件操作. 假如我的Secu ...
- laravel Auth token创建于使用
token 的创建和使用, https://laravelacademy.org/post/3640.html 用户表密码字段验证修改,不只是password https://www.jianshu. ...
- Zookeeper--分布式锁和消息队列
在java并发包中提供了若干锁的实现,它们是用于单个java虚拟机进程中的:而分布式锁能够在一组进程之间提供互斥机制,保证在任何时刻只有一个进程可以持有锁. 分布式环境中多个进程的锁则可以使用Zook ...
- 以太坊客户端Geth命令用法
命令用法 geth [选项] 命令 [命令选项] [参数…] 命令: account 管理账户attach 启动交互式JavaScript环境(连接到节点)bug 上报bug Issuesconsol ...
- 杂项-Server:Serv-U
ylbtech-杂项-Server:Serv-U Serv-U FTP Server,是一种被广泛运用的FTP服务器端软件,支持3x/9x/ME/NT/2K等全Windows系列.可以设定多个FTP服 ...
- Apache common exec包的相应使用总结
最近在写一个Java工具,其中调用了各种SHELL命令,使用了Runtime.getRuntime().exec(command);这个方法.但是在我调用某个命令执行操作时,程序就卡在那了,但是其 ...
- GSON使用笔记
GSON简介 GSON是Google开发的Java API,用于转换Java对象和Json对象,我在这里将记录一下GSON的简单使用 下载GSON 我们可以在其github仓库中下载,也可以使用Mav ...
- MySql——事务控制语言(DTL)
什么是事务(控制台只能是内存的操作) 通常,在此之前,我们说,一条语句使用一个分号(;)来结束,并得到执行. 那么我们说,这个“一次性执行”的过程,可以称为“一个事务”. 简单来说,“一条sql语句, ...
- Cacti监控服务器配置教程(基于CentOS+Nginx+MySQL+PHP环境搭建)
Cacti监控服务器配置教程(基于CentOS+Nginx+MySQL+PHP环境搭建) 具体案例:局域网内有两台主机,一台Linux.一台Windows,现在需要配置一台Cacti监控服务器对这两台 ...