kubernets集群的安全防护(下)
一 集群角色以及集群角色绑定
1.1 前面我们提到过角色以及角色绑定,那么现在为什么会出现集群级别的角色以及角色绑定,作用有如下所示
- 我们如果需要在所有的命名的空间创建某个角色或者角色绑定的时候,按照目前已经学习的方法只能将现有的命名空间里一个一个的去创建,并且这种办法只能创建已经存在的命名空间,对于那些即将创建的命名空间也还需要等待创建完成之后在去创建角色以及角色绑定
- API服务器存储的有2类URL,第一类是资源类型的URL,另一种是非资源性的URL
- 利用角色,以及角色绑定需要明确指出需要访问的集群资源的名称service等是无法访问到非资源形URL
- 再有一点,如果命名空间想要访问集群级别的资源,也只能通过绑定集群角色来访问
1.2 让某个命名空间的pod访问集群级别的资源
k create clusterrole pv-reader --verb=get,list --resource=persistentvolumes
1.3 它的yaml形式如下所示
[root@node01 Chapter12]# k get clusterrole pv-reader -o yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: pv-reader
rules:
- apiGroups:
- ""
resources:
- persistentvolumes
verbs:
- list
- get
1.4 此时来通过wdm的pod来访问集群级别的资源persistentvolumes,结果如下所示
/ # curl localhost:8001/api/v1/persistentvolumes
{
"kind": "Status",
"apiVersion": "v1",
"metadata": { },
"status": "Failure",
"message": "persistentvolumes is forbidden: User \"system:serviceaccount:wdm:default\" cannot list resource \"persistentvolumes\" in API group \"\" at the cluster scope",
"reason": "Forbidden",
"details": {
"kind": "persistentvolumes"
},
"code": 403
1.5 现在我们将这个集群资源绑定到wdm这个命名空间的SA上面去,执行的命令如下所示
k create rolebinding pv-test --cluster-role=pv-reader --serviceaccount=wdm:default
1.6 之后继续进入wdm命名空间所在的pod来访问集群资源persistentvolumes
/ # curl localhost:8001/api/v1/persistentvolumes
{
"kind": "Status",
"apiVersion": "v1",
"metadata": { },
"status": "Failure",
"message": "persistentvolumes is forbidden: User \"system:serviceaccount:wdm:default\" cannot list resource \"persistentvolumes\" in API group \"\" at the cluster scope",
"reason": "Forbidden",
"details": {
"kind": "persistentvolumes"
},
"code": 403
- 很是奇怪,明明创建了rolebinding并将其具有访问集群资源persistentvolumes的clusterrole,但是还是访问失败
- 说明虽然rolebinding能够将clusterrole绑定到命名空间role上面,但是却无法对集群资源进行访问
1.7 创建一个clusterrolebinding来与clusterrole进行相关绑定
k create clusterrolebinding pv-test --clusterrole=pv-reader --serviceaccount=wdm:default
1.8 之后在wdm的命名空间里面pod访问集群资源
/ # curl localhost:8001/api/v1/persistentvolumes
{
"kind": "PersistentVolumeList",
"apiVersion": "v1",
"metadata": {
"selfLink": "/api/v1/persistentvolumes",
"resourceVersion": "3570872"
},
"items": [
{
"metadata": {
"name": "pv-a",
"selfLink": "/api/v1/persistentvolumes/pv-a",
"uid": "17346ca6-53e0-11eb-ae9a-5254002a5691",
"resourceVersion": "3033946",
"creationTimestamp": "2021-01-11T07:39:09Z",
"labels": {
"type": "local"
},
......
- 可以看到已经成功的查询到了集群级别的信息PV
- 综上所叙,即使给role绑定了集群级别的资源,也无法去访问集群级别的资源
- 集群级别的资源只能通过clusterrolebinding来关联到某个命名空间的pod才能进行访问
1.9 对于非资源类型的URL,集群给其system:discovery的clusterrole,并且将其绑定到了未被认证和已经被认证的组了,即集群内部的任何pod都可以对其进行访问
1.10 集群中也有些clusterrolebinding不仅仅可以与clusterrole进行绑定,同时也可以与role进行绑定,其中有一个名字为view的clusterrole,里面包含了集群内部所有的命名空间的资源相关信息,所有它会具有以下2个特点
- 当它与集群角色绑定进行绑定的时候,那么集群绑定下面的账户就拥有访问这个集群的权限
- 当它与某个命名空间里面的角色绑定的时候进行绑定,那么角色绑定下面的用户或组或serviceaccount则可以访问这个命名空间的资源
总结角色,角色绑定,集群角色,集群角色绑定的一些规律如下图所示:
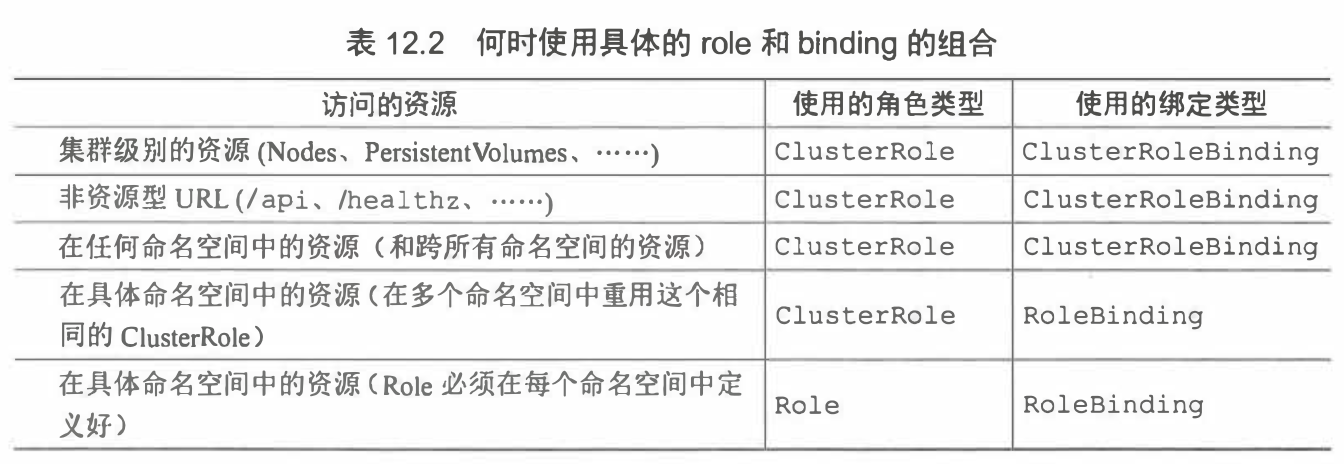
1.11 介绍集群默认的clusterrolebinding
- admin的clusterrole允许访问某个命名空间的所有资源(除了role,以及rolebinding)
- cluster-admin允许访问整个集群的所有资源
kubernets集群的安全防护(下)的更多相关文章
- kubernets集群的安全防护(上)
一 了解认证机制 1.1 API的服务器在接收来自客户端的请求的时候会对发起的用户进行几个步骤 认证插件进行认证,确认发起的用户是外部用户,还是集群中的某个命名空间里面的pod 确认用户属于哪个 ...
- 利用Redis实现集群或开发环境下SnowFlake自动配置机器号
前言: SnowFlake 雪花ID 算法是推特公司推出的著名分布式ID生成算法.利用预先分配好的机器ID,工作区ID,机器时间可以生成全局唯一的随时间趋势递增的Long类型ID.长度在17-19位. ...
- ASP.NET Core 数据保护(Data Protection 集群场景)【下】
前言 接[中篇],在有一些场景下,我们需要对 ASP.NET Core 的加密方法进行扩展,来适应我们的需求,这个时候就需要使用到了一些 Core 提供的高级的功能. 本文还列举了在集群场景下,有时候 ...
- Kafka集群在空载情况下Cpu消耗比较高的问题
线上kafka与storm的空载情况下负载都比较高, kafka达到122%, storm平均负载达到, 20%, 当前是通过Ambari下管理kafka的, a. 先停止s5的kafka进程.b. ...
- 使用kubeadm创建kubernets集群
参考: http://docs.kubernetes.org.cn/459.html https://blog.csdn.net/gui951753/article/details/833169 ...
- Redis 集群方案什么情况下会导致整个集群不可用?
有 A,B,C 三个节点的集群,在没有复制模型的情况下,如果节点 B 失败了, 那么整个集群就会以为缺少 5501-11000 这个范围的槽而不可用.
- rancher部署kubernets集群
docker的安装 先添加docker源 sudo apt update sudo apt install docker.io docker更换国内镜像 1.配置脚本如下: #!/bin/bashca ...
- 集群/分布式环境下5种session处理策略
转载自:http://blog.csdn.net/u010028869/article/details/50773174?ref=myread 前言 在搭建完集群环境后,不得不考虑的一个问题就是用户访 ...
- Centos7下部署ceph 12.2.1 (luminous)集群及RBD使用
前言 本文搭建了一个由三节点(master.slave1.slave2)构成的ceph分布式集群,并通过示例使用ceph块存储. 本文集群三个节点基于三台虚拟机进行搭建,节点安装的操作系统为Cento ...
随机推荐
- 20201203-5 批量发送 email【】
1-1 批量发送 email 1 from openpyxl import load_workbook 2 import smtplib 3 from email.mime.text import M ...
- Linux下keepalived配置
1.背景 节点1:192.168.12.35 节点2:192.168.12.36 2.keepalived安装 使用yum仓库安装keepalived [root@node01 ~]# yum ins ...
- Spark Connector Reader 原理与实践
本文主要讲述如何利用 Spark Connector 进行 Nebula Graph 数据的读取. Spark Connector 简介 Spark Connector 是一个 Spark 的数据连接 ...
- css 11-CSS3属性详解(一)
11-CSS3属性详解(一) #前言 我们在上一篇文章中学习了CSS3的选择器,本文来学一下CSS3的一些属性. 本文主要内容: 文本 盒模型中的 box-sizing 属性 处理兼容性问题:私有前缀 ...
- css 10-CSS3选择器详解
10-CSS3选择器详解 #CSS3介绍 CSS3在CSS2基础上,增强或新增了许多特性, 弥补了CSS2的众多不足之处,使得Web开发变得更为高效和便捷. #CSS3的现状 浏览器支持程度不够好,有 ...
- [日常摸鱼]bzoj1502[NOI2005]月下柠檬树-简单几何+Simpson法
关于自适应Simpson法的介绍可以去看我的另一篇blog http://www.lydsy.com/JudgeOnline/problem.php?id=1502 题意:空间里圆心在同一直线上且底面 ...
- svn 忘记了用户名和密码
[SVN]如果windows用户忘记了svn的用户名和密码怎么办? 如果windows用户忘记了svn的用户名和密码怎么办? 1>你得进入默认地址 C:\Users\Administrato ...
- Python爬虫:爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一 ...
- sql 查询条件为拼接字符串 不能使用IN 使用patindex查询结果集
题目: 求组织机构ID在('5dc8de20-9f2f-465e-afcc-f69abecaee50','63549b63-1e0d-4269-98f4-013869d7f211','f7316bf3 ...
- 在 ASP.NET Core和Worker Service中使用Quartz.Net
现在有了一个官方包Quartz.Extensions.Hosting实现使用Quartz.Net运行后台任务,所以把Quartz.Net添加到ASP.NET Core或Worker Service要简 ...