HBase面试考点
- HBase
- 架构图
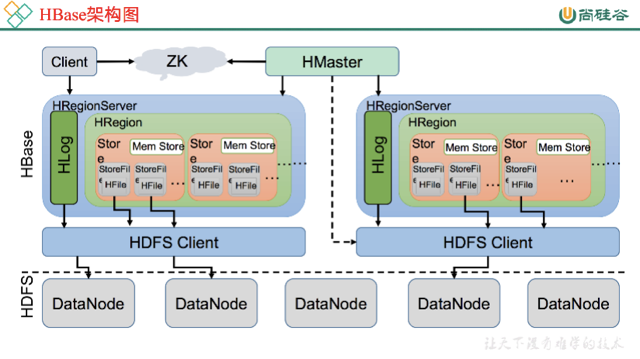
- 组成部分及作用
- Zookeeper在HBase中作用
- Master的高可用
- RegionServer的监控
- 元数据的入口
- HMaster
- 不仅有维护集群元数据信息的功能,还能
- 通过Zookeeper发布自己的位置给客户端
- 为RegionServer分配Region
- 维护整个集群的负载均衡
- 发现失效的Region,并将失效的Region分配到正常的RegionServer上
- 当RegioServer失效的时候,协调对应Hlog的拆分
- HRegionServer
- 作用
- 干活的结点:处理用户读写请求
- 管理Hmaster为其分配的region
- 与底层HDFS交互,存储数据到HDFS
- 负责Region的拆分与Storefile的合并工作
- 组成
- HLog
- 日志文件,记录了操作,数据写入时先写入这里再写入内存,防止内存中丢失。系统故障时可以通过这个日志文件重建。内存存入磁盘后hlog也对应删除
- Region
- 表的分片,一个总体表的一部分
- Store
- 不同的列族分在不同的Store存放,Store在Region中,也就对应了列族的一部分数据
- MemStore
- 每个列族持有,写入时先写入这里
- 数据flush过程指MemStore达到阈值,将数据刷新到硬盘,同时删除Hlog中历史数据
- HFile
- 实际物理文件,以这种形式存储在HDFS上。
- 是强一致性数据库,其牺牲了可用性来换取强一致性
- hbase之所以是CP系统,实际和底层HDFS无关,它是CP系统,是因为对每一个region同时只有一台region server为它服务,对一个region所有的操作请求,都由这一台region server来响应,自然是强一致性的.在这台region server fail的时候,它管理的region failover到其他region server时,需要根据WAL log来redo,这时候进行redo的region应该是unavailable的,所以hbase降低了可用性,提高了一致性.设想一下,如果redo的region能够响应请求,那么可用性提高了,则必然返回不一致的数据(因为redo可能还没完成),那么hbase就降低一致性来提高可用性了.
- HBase数据结构
- Rowkey
- 用来检索记录的主键,访问HBase table中的行
- 可以使任意字符串,最大64KB,
- 存储时,按照RowKey的字典排序存储,设计Rowkey时要充分存储这个特性,将经常一起读取的行存放到一起(位置相关性),也要注意热点问题
- RowKey设计
- 目的:就是让所有数据均匀的分布与所有的Region中,在一定程度上防止数据倾斜
- 原则
- 唯一性
- 长度原则
- 散列原则
- 热点问题
- 数据热点:HBase 中的行是按照 rowkey 的字典顺序排序的,这种设计优化了 scan 操作,可以将相 关的行以及会被一起读取的行存取在临近位置,便于 scan。然而糟糕的 rowkey 设计是热点 的源头。 热点发生在大量的 client 直接访问集群的一个或极少数个节点(访问可能是读, 写或者其他操作)。大量访问会使热点 region 所在的单个机器超出自身承受能力,引起性能 下降甚至 region 不可用,这也会影响同一个 RegionServer 上的其他 region,由于主机无法服 务其他 region 的请求。 设计良好的数据访问模式以使集群被充分,均衡的利用。 为了避免写热点,设计 rowkey 使得不同行在同一个 region,但是在更多数据情况下,数据 应该被写入集群的多个 region,而不是一个。(解决方法就是rowkey设计原则中的散列原则)
- 列族Colum Family
- HBase中每个列都属于某个列族,列族必须在使用表前定义
- 列族设计原则
- 和mysql一样的原理,能少列族就少列族,比如用户基本信息一个列族,额外信息一个列族。(因为列族过大,对一部分的改动有时会影响其他的列族,比如flush,都是针对region的,表的分裂1000列族10行,分裂会产生基数问题,分不开。)
- Cell
- 由rowkey、列族、列唯一确定的单元,没有类型,全部以字节码存储
- Time stamp
- 版本号,每个cell都保存着同一份数据的多个版本。版本通过时间戳来索引,最新的数据排在前面。操作只要加一个版本而不用删去之前的版本,这大大提高了速度。删去和合并版本最后数据的操作什么时候做都可以。
- 工作流程
- 数据合并、拆分过程
- HDFS不适合存储小文件,当数据达到3块,Hmaster出发合并操作,Region将数据进行合并。但是当合并的Region太大之后,还要进行拆分,分给不同的Regionserver
- 读数据流程(写流程相似)
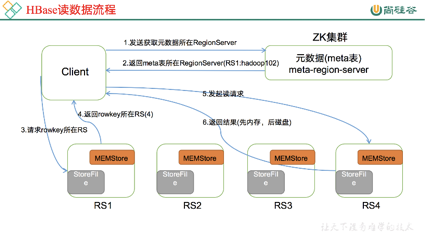
- 具体从每一个server读数据的时候要先从memStore读,然后没找到,再到BlockCache里读(应该是一个cache一样的东西,利用时间局部性原理),最后没有到StroeFile里读,读完之后先缓存到BlockCache,再返回给客户端。
- 布隆过滤器:比哈希表高效一些,但是不适用于零错误的应用场合。
- 因为哈希表的存储效率比较低,布隆过滤器解决了这个问题。用很少的错误率换取极大地存储空间节省。原理是通过对一个数进行多次哈希值,对应的位置标记,如果对一个数多次哈希之后的结果都被标记,则这个数在表里。但存在一定误识率,即一个数刚好对应的是其他的已经标记了的几个点里。优化:可以建立一个白名单,标注出这些可能被识别为错误的数字。
- Hbase应用
- Hbase应用布隆:我们可以知道,当我们随机读get数据时,如果采用hbase的块索引机制,hbase会加载很多块文件。如果采用布隆过滤器后,它能够准确判断该HFile的所有数据块中,是否含有我们查询的数据,从而大大减少不必要的块加载,从而增加hbase集群的吞吐率。
- Hbase快的关键
- 时间戳
- 基于内存
- 列式存储
- 行存储写快读慢,列存储写慢读快,适合大数据。hbase列存储。
- 优化
- 布隆过滤器
- 有些不需要的情况,版本设置为1
- 压缩方式:snappy
- 预分区
- 可以自己事先定义分区策略让每个Region维护哪些数据(startRow 与endRowKey来界定)
- 防止因自动切分策略造成的数据倾斜问题
- 内存优化:HBase操作需要大量内存开销,一般给70%内存给Hbase的Java堆,但是不能给太多,因为GC持续太长也会使RegionServer处于长期不可用状态。而且太多的话其他应该用内存不足也会造成系统的不稳定。
HBase面试考点的更多相关文章
- C#面试考点集锦
C#面试考点集锦 ©智客坊 岁末年初往往是程序猿准备跳槽的高峰,当然互联网行业跳槽几乎是每个月都在发生,没有太过明显的淡季~那么,如何提高面试的通过率,最终顺利的拿到自己心仪的offer呢? ...
- React16源码解读:开篇带你搞懂几个面试考点
引言 如今,主流的前端框架React,Vue和Angular在前端领域已成三足鼎立之势,基于前端技术栈的发展现状,大大小小的公司或多或少也会使用其中某一项或者多项技术栈,那么掌握并熟练使用其中至少一种 ...
- HBase面试问题
一.HBase的特点是什么 1.HBase一个分布式的基于列式存储的数据库,基于hadoop的hdfs存储,zookeeper进行管理. 2.HBase适合存储半结构化或非结构化数据,对于数据结构字段 ...
- 【面试】Spring事务面试考点吐血整理(建议珍藏)
Spring和事务的关系 关系型数据库.某些消息队列等产品或中间件称为事务性资源,因为它们本身支持事务,也能够处理事务. Spring很显然不是事务性资源,但是它可以管理事务性资源,所以Spring和 ...
- Java岗 面试考点精讲(基础篇02期)
1. 两个对象的hashCode相同,则equals也一定为true,对吗? 不对,答案见下面的代码: @Override public int hashCode() { return 1; } 两个 ...
- Java岗 面试考点精讲(基础篇01期)
即将到来金三银四人才招聘的高峰期,渴望跳槽的朋友肯定跟我一样四处找以往的面试题,但又感觉找的又不完整,在这里我将把我所见到的题目做一总结,并尽力将答案术语化.标准化.预祝大家面试顺利. 术语会让你的面 ...
- java和数据结构的面试考点
目标:不要有主要的逻辑错误.2遍以内bug free.注意代码风格 不要让面试官觉得不懂规矩 Java vs C++ Abstract class vs interface pass by refe ...
- java应届生面试考点收集
回 到 顶 部 这些知识点来自于之前去百度实习.阿里.蘑菇街校园招聘的电话面试 未完待续 JavaSE 面向对象 封装.继承.多态(包括重载.重写) 常见区别 String.StringBuffer. ...
- java面试考点-面试准备
面试前准备 了解应试公司相关信息及岗位信息 系统复习基础知识 对原公司负责项目进行梳理 阅读常规框架源码 学习典型架构案例 针对招聘文案准备加分项 相关技能 基础知识:进程/线程,TCP协议,HTTP ...
随机推荐
- 【转载】npx 真香
npx 主要提供了一些便捷操作: 调用项目安装的模块 避免全局安装模块 使用不同版本的 node 执行 GitHub 源码 原文地址:http://www.ruanyifeng.com/blog/20 ...
- JDK8--03:lambda表达式语法
对于lambda表达式的基础语法,一个是要了解lambda表达式的基础语法,另外一个是需要了解函数式接口 一.lambda表达式基础语法描述 java8中引入了新的操作符 -> ,可以称为l ...
- Egret游戏大厅制作思路
Egret游戏大厅制作思路 Egret中,写好的代码最终都被打包到main.js里面,只有库文件会单独生成出来,按需加载. 游戏中有需求,要将一些游戏(或者模块)进行外包,然后从主游戏大厅中进入,那么 ...
- Myeclipse启动WebLogic 总是报账号密码无效<Authentication denied: Boot identity not valid
在MyEclipse下配置了Weblogic 11后,每次启动从报错: Critical> 看了下描述,是用户名及密码什么的问题,我想起来,配置Weblogic 的域的时候将密码改成了12345 ...
- P2114 [NOI2014]起床困难综合症【二进制运算+优化】
起床困难综合症[二进制运算+优化] 题目描述 21世纪,许多人得了一种奇怪的病:起床困难综合症,其临床表现为:起床难,起床后精神不佳.作为一名青春阳光好少年,atm一直坚持与起床困难综合症作斗争.通过 ...
- 计算区间 1 到 n 的所有整数中,数字 x(0 ≤ x ≤ 9) 共出现了多少次?
#include<iostream> using namespace std; int main() { long long start, end , i, check, b, c, cn ...
- CSS选择器整理以及优先级介绍
一.基础选择器 选择器 名称 描述 兼容性 * 通配选择器 选择所有的元素 ie6+ E 元素选择器 选择指定的元素 ie6+ #idName id选择器 选择id属性等于idName的元素 ie6+ ...
- 自描述C++部分面试题集
1.谈谈啥叫对象成员以及对象成员的构造函数调用调用方式. 在类中定义的数据成员一般都是基本的数据类型.但是类中的成员也可以是对象,叫做对象成员. C++中对对象的初始化时非常重要的操作,当创建一个对象 ...
- WIN10有线网络反复断开解决方法
最近家里台式机碰到一个奇怪的问题,开机之后有线网络就时断时续,右下角网络图标不停在小地球与小电脑之间切换.网上大概搜索了一下,貌似碰到这种问题的朋友不在少数,但大部分朋友碰到的都是无线网络居多.这里把 ...
- 前端老司机常用的方法CSS如何清除浮动?清除浮动的几种方式
在前端开发过程中,我们经常会使用到浮动(float),这个我们即爱又恨的属性.爱,是因为通过浮动,我们能很方便地进行布局:恨,是因为浮动之后遗留下来太多的问题需要解决.下面本篇文章给大家介绍CSS清除 ...