Elasticsearch 为了搜索
前言
Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene 基础之上。 Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库——无论是开源还是私有。
下面将从索引、相关性、TF−IDF与BM25相关性算法、查全率跟查准率来分析Elasticsearch的搜索。
倒排索引
说到倒排索引,就不得不说正排索引。
正排索引,由key查询实体的过程,使用正排索引,比如我们常用的MySQL索引到数据行的过程。
倒排索引由词查询文档的过程,使用倒排索引。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。将单词或记录作为索引,将文档ID作为记录,这样便可以方便地通过单词或记录查找到其所在的文档。
两者的区别就比如一本书中,书本目录是正排索引,书本附录中的术语中关联的页数是倒排索引。
相关性(relevance)
对于MySQL中的数据,默认返回的索引数据存储的数据,那Elasticsearch返回的文档的排序顺序呢?
默认情况下,返回结果是按相关性倒序排列的。但是什么是相关性?相关性如何计算?
每个文档都有相关性评分,用一个正浮点数字段 _score 来表示。_score 的评分越高,相关性越高。
查询语句会为每个文档生成一个 _score 字段。评分的计算方式取决于查询类型 不同的查询语句用于不同的目的: fuzzy 查询会计算与关键词的拼写相似程度,terms 查询会计算找到的内容与关键词组成部分匹配的百分比,但是通常我们说的 relevance 是我们用来计算全文本字段的值相对于全文本检索词相似程度的算法。
相关性的算法有TF-IDF跟BM25,Elasticsearch5.0之后默认相关性算法是BM25。
一些术语
索引词(term)
在Elasticsearch中索引词(term)是一个能够被索引的精确值。
如果是英文,忽略大小写,保存为小写格式,忽略一些无效词(比如the);
如果是中文,忽略一些无效词(比如“的”)
文本(text)
文本是一段普通的非结构化文字。通常,文本会被分析成一个个的索引词,存储在Elasticsearch的索引库中。
比如文本“I love China”可能会被分析成索引词“I”,“love”,“China”。具体还得看分词器。
分析(analysis)
分析是将文本转换为索引词的过程,分析的结果依赖于分词器。
文档(document)
文档是存储在Elasticsearch中的一个JSON格式的字符串。它就像在关系数据库中表的一行。
TF-IDF 算法
TF(Term Frequence):代表词频。公式为 text中某一索引词w出现的次数 / text所有的term的个数
IDF(Invert Document Frequence):代表逆向文档频率。公式为 lg(总文档数 / (有索引词w的文档数+1))
TF−IDF的值为TF∗IDF。
例子:一篇文档总的词语数是100个,而词语“中华”出现了3次,词频就是3/100=0.03,如果“中华”出现在1000份文件中,而所有文件总数是10000000份,逆向文件频率就是 lg(10,000,000 / 1,000)=4,最后的TF-IDF的分数为0.03 * 4 = 0.12。
BM25 算法
BM25 源自 概率相关模型,而不是向量空间模型,BM25 同样使用词频、逆向文档频率以及字段长归一化,但是每个因子的定义都有细微区别。
公式
IDF * ((k + 1) * tf) / (k * (1.0 - b + b * (|d|/avgDl)) + tf)
IDF是根据概率信息检索获得
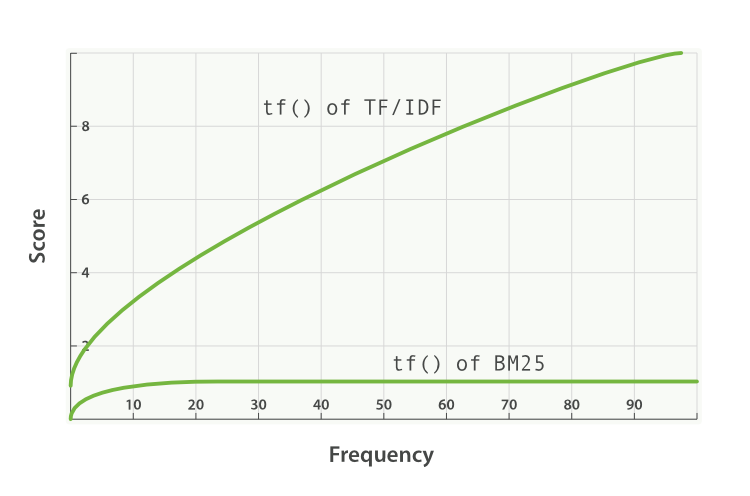
相比传统的TF*IDF相关性算法,在BM25中词频的影响降低。词频的影响一直在增加,但渐渐地逼近一个值。
BM25 有一个上限,文档里出现 5 到 10 次的词会比那些只出现一两次的对相关度有着显著影响。但是如图 TF/IDF 与 BM25 的词频饱和度 所见,文档中出现 20 次的词几乎与那些出现上千次的词有着相同的影响。
搜索的效率
如何衡量搜索的效率呢?用查全率跟查准率。
查全率=(搜索出的相关文档/系统中的相关文档总量)*100%。代表所有相关文档被检索的比例。
查准率=(搜索出的相关文档/检索出的文档总量)*100%。代表搜索出来的文档中相关文档的比例。
查全率是衡量搜索系统和搜索者搜出相关文档的能力,查准率是衡量搜索系统和搜索者拒绝非相关相关文档的能力。两者合起来,即表示搜索效率。

比如上图中,期望结果是搜索出所有的实心圆,结果是搜索出了部分实心圆跟不想要的空心圆。
分词器
分词器 接受一个字符串作为输入,将这个字符串拆分成独立的词或 语汇单元(token) (可能会丢弃一些标点符号等字符),然后输出一个 语汇单元流(token stream) 。
有趣的是用于词汇 识别 的算法。 whitespace (空白字符)分词器按空白字符 —— 空格、tabs、换行符等等进行简单拆分 —— 然后假定连续的非空格字符组成了一个语汇单元。例如:
GET /_analyze?tokenizer=whitespace
You're the 1st runner home!
这个请求会返回如下词项(terms): You're 、 the 、 1st 、 runner 、 home!
icu_分词器 和 标准分词器 使用同样的 Unicode 文本分段算法, 只是为了更好的支持亚洲语,添加了泰语、老挝语、中文、日文、和韩文基于词典的词汇识别方法,并且可以使用自定义规则将缅甸语和柬埔寨语文本拆分成音节。
中文分词还可以使用“IK”分词器。
中文分词难点,需要根据上下文语义进行分词。比如“这个苹果不大好吃”,可以有两种分词,“这个苹果,不大好吃”,“这个苹果,不大,好吃”,不一样的分词,不一样的结果。
参考资料
- https://www.elastic.co/guide/cn/elasticsearch/guide/current/controlling-relevance.html
- https://www.elastic.co/guide/cn/elasticsearch/guide/current/relevance-intro.html
- https://lucene.apache.org/core/
Elasticsearch 为了搜索的更多相关文章
- ElasticSearch位置搜索
ElasticSearch位置搜索 学习了:https://blog.csdn.net/bingduanlbd/article/details/52253542 学习了:https://blog.cs ...
- ElasticSearch入门-搜索(java api)
ElasticSearch入门-搜索(java api) package com.qlyd.searchhelper; import java.util.Map; import net.sf.json ...
- PHP使用ElasticSearch做搜索
PHP 使用 ElasticSearch 做搜索 https://blog.csdn.net/zhanghao143lina/article/details/80280321 https://www. ...
- 十九种Elasticsearch字符串搜索方式终极介绍
前言 刚开始接触Elasticsearch的时候被Elasticsearch的搜索功能搞得晕头转向,每次想在Kibana里面查询某个字段的时候,查出来的结果经常不是自己想要的,然而又不知道问题出在了哪 ...
- Elasticsearch实现搜索推荐词
本篇介绍的是基于Elasticsearch实现搜索推荐词,其中需要用到Elasticsearch的pinyin插件以及ik分词插件,代码的实现这里提供了java跟C#的版本方便大家参考. 1.实现的结 ...
- Elasticsearch分布式搜索和数据分析引擎-ElasticStack(上)v7.14.0
Elasticsearch概述 **本人博客网站 **IT小神 www.itxiaoshen.com Elasticsearch官网地址 https://www.elastic.co/cn/elast ...
- Elasticsearch 教程--搜索
搜索 – 基本工具 到目前为止,我们已经学习了Elasticsearch的分布式NOSQL文档存储,我们可以直接把JSON文档扔到Elasticsearch中,然后直接通过ID来进行调取.但是Elas ...
- Elasticsearch 数据搜索篇·【入门级干货】
ES即简单又复杂,你可以快速的实现全文检索,又需要了解复杂的REST API.本篇就通过一些简单的搜索命令,帮助你理解ES的相关应用.虽然不能让你理解ES的原理设计,但是可以帮助你理解ES,探寻更多的 ...
- Elasticsearch分布式搜索集群配置
配置文件位于%ES_HOME%/config/elasticsearch.yml文件中,用Editplus打开它,你便可以进行配置. 所有的配置都可以使用环境变量,例如:node.rack: ${ ...
随机推荐
- Codeforces Round #575 (Div. 3) D2. RGB Substring (hard version)
传送门 题意: 给你一个长为n的仅由'R','G','B'构成的字符串s,你需要在其中找出来一个子串.使得这个子串在"RGBRGBRGBRGB........(以RGB为循环节,我们称这个串 ...
- 牛客编程巅峰赛S1第5场 - 黄金&钻石&王者 B.牛牛的字符串 (DP)
题意:有一个字符串\(s\),我们可以选择\(s_{i}\),如果\(s_{i+k}>s_{i}\),那么就可以交换\(s_{i}\)和\(s_{i+k}\),问最多能够交换多少次. 题解:因为 ...
- Codeforces Round #656 (Div. 3) A. Three Pairwise Maximums (数学)
题意:给你三个正整数\(x\),\(y\),\(z\),问能够找到三个正整数\(a\),\(b\),\(c\),使得\(x=max(a,b)\),\(y=max(a,c)\),\(z=max(b,c) ...
- Pdf和Office相关归集
Spire 支持Pdf.Office等的诸多操作,使用方便,需收费,免费版本仅支持10页以内的操作,在 这里 可以下载库. 优点 测试过打印效果佳,操作简便. 缺点 PDF打印慢,免费版本仅支持10页 ...
- 一篇文章搞懂G1收集器
一.何为G1收集器 The Garbage-First (G1) garbage collector is a server-style garbage collector, targeted for ...
- codeforces 2C(非原创)
C. Commentator problem time limit per test 1 second memory limit per test 64 megabytes input standar ...
- 读js DOM编程艺术总结
第一章主要介绍一些历史性问题,javascript是Netcape和sun公司合作开发的. 第二章JavaScript语法: 1,数据类型:(弱类型)字符串,数值,布尔值(只有true和false,不 ...
- Google reCAPTCHA 2 : Protect your site from spam and abuse & Google reCAPTCHA 2官方教程
1
- Prettier All In One
Prettier All In One .prettierrc.js / .prettierrc / .prettierrc.json module.exports = { singleQuote: ...
- js & bitwise-operators
js & bitwise-operators 不用加减乘除运算符, 求整数的7倍 "use strict"; /** * * @author xgqfrms * @lice ...