python爬虫 学习1
1 import requests
2 from bs4 import BeautifulSoup
3 import bs4
4 def gethtmltext(url): #获取html内容,利用try和except框架可以抛出异常
5 try:
6 r = requests.get(url,timeout=30) #获取url,时间限制为30秒
7 r.raise_for_status() #检查连接状态是否为200,即正常连接,如果为否则抛出except异常
8 r.encoding=r.apparent_encoding #确定编码
9 return r.text #返回为html的内容
10 except:
11 return ''
12
13
14 def fillunivlist(ulist,html): #解析html内容,提取所需数据 ulist是一个空列表,用来存取解析出来的所需数据
15 soup = BeautifulSoup(html,'html.parser') #利用beautifulsoup的html.parser来解析r.text
16 for tr in soup.find('tbody').children: #通过分析发现所需排序,学校名称,总分存在于tbody标签类的tr标签中的td标签 .children是查找tbody的子类
17 if isinstance(tr,bs4.element.Tag): #因为tr标签包含其他string,而我们所需要的只是bs4.element.Tag标签类型,所以用isinstance(obj,class)作一个判断
18 tds = tr('td') #若判断为真则 执行查找tr标签中的td标签,并赋值给tds
19 ulist.append([tds[0].string,tds[1].string,tds[2].string]) #将tds的数据追加给ulist
20
21 def printunivlist(ulist,num): #格式化输出内容
22 print('{:^10}\t{:^6}\t{:^10}'.format('排名','学校名称','总分'))
23 for i in range(num):
24 u=ulist[i]
25 print('{:^10}\t{:^6}\t{:^10}'.format(u[0],u[1],u[2]))
26
27
28 def main(): #定义一个主函数,实现具体抓取并输出
29 uinfo = []
30 url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html'
31 html = gethtmltext(url)
32 fillunivlist(uinfo,html)
33 printunivlist(uinfo,20)
34
35 main()
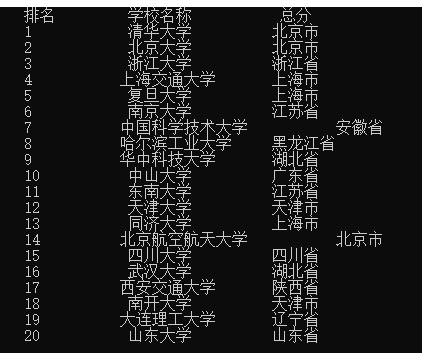
效果图如下:
python爬虫 学习1的更多相关文章
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- python爬虫学习 —— 总目录
开篇 作为一个C党,接触python之后学习了爬虫. 和AC算法题的快感类似,从网络上爬取各种数据也很有意思. 准备写一系列文章,整理一下学习历程,也给后来者提供一点便利. 我是目录 听说你叫爬虫 - ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫学习:四、headers和data的获取
之前在学习爬虫时,偶尔会遇到一些问题是有些网站需要登录后才能爬取内容,有的网站会识别是否是由浏览器发出的请求. 一.headers的获取 就以博客园的首页为例:http://www.cnblogs.c ...
- Python爬虫学习:二、爬虫的初步尝试
我使用的编辑器是IDLE,版本为Python2.7.11,Windows平台. 本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:二.爬虫的初步尝试 1.尝试抓取指定网页 ...
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
- python爬虫学习视频资料免费送,用起来非常666
当我们浏览网页的时候,经常会看到像下面这些好看的图片,你是否想把这些图片保存下载下来. 我们最常规的做法就是通过鼠标右键,选择另存为.但有些图片点击鼠标右键的时候并没有另存为选项,或者你可以通过截图工 ...
- python爬虫学习笔记(一)——环境配置(windows系统)
在进行python爬虫学习前,需要进行如下准备工作: python3+pip官方配置 1.Anaconda(推荐,包括python和相关库) [推荐地址:清华镜像] https://mirrors ...
- [转]《Python爬虫学习系列教程》
<Python爬虫学习系列教程>学习笔记 http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多. ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
随机推荐
- Linux的MySQL安装方法
第一种: APT方式安装 在ubuntu系统的apt软件仓库中,默认存在MySQL数据库 在用户模式下使用命令: apt/apt-get install mysql-server mysql-cli ...
- Burp Suite的安装
安装均在虚拟机环境下进行. 1.首先在浏览器找到java进行最新版本的安装. 2.然后找到burp suite 的安装包下载 不知道这一次 怎么直接跳过安装打开了.
- scala 传值调用,传名调用
Scala的解释器在解析函数参数(function arguments)时有两种方式: 传值调用(call-by-value):先计算参数表达式的值,再应用到函数内部: 传名调用(call-by-na ...
- PHPExcel集成对数据导入和导出
<?php /** * Created by PhpStorm. * User: admin * Date: 2017/8/15 * Time: 9:07 */ class User exten ...
- hystrix ,feign,ribbon的超时时间配置,以及原理分析
背景,网上看到很多关于hystrix的配置都是没生效的,如: 一.先看测试环境搭建: order 服务通过feign 的方式调用了product 服务的getProductInfo 接口 //---- ...
- This is Riv3r1and.
总是要弄个博客来搞的嘛.
- 022 01 Android 零基础入门 01 Java基础语法 03 Java运算符 02 算术运算符
022 01 Android 零基础入门 01 Java基础语法 03 Java运算符 02 算术运算符 本文知识点:Java中的算术运算符 算术运算符介绍 算术运算符代码示例 注意字符串连接问题和整 ...
- C++读写ini配置文件GetPrivateProfileString()&WritePrivateProfileString()
转载: 1.https://blog.csdn.net/fengbingchun/article/details/6075716 2. 转自:http://hi.baidu.com/andywangc ...
- ASP。NET MVC警告横幅使用Bootstrap和AngularUI Bootstrap
Watch this script in action - demo 下载Source Code from GitHub 下载Source Code from CodeProject (1.1 MB) ...
- Code Forces 1030E
题目大意: 给你n个数,你可以交换一个数的任意二进制位,问你可以选出多少区间经过操作后异或和是0. 思路分析: 根据题目,很容易知道,对于每个数,我们可以无视它的1在那些位置,只要关注它有几个1即可, ...