ElasticSearch 交互使用
Curl 命令
# 建立索引
[root@dbtest01 ~]# curl -XPUT 'http://10.0.0.121:9200/test'
# 插入数据
[root@dbtest01 ~]# curl -XPUT 'localhost:9200/student/user/1?pretty' -H 'Content-Type: application/json' -d '{"name": "wqh","gender":"male","age":"18","about":"I will carry you","interests":["cs","it"]}'
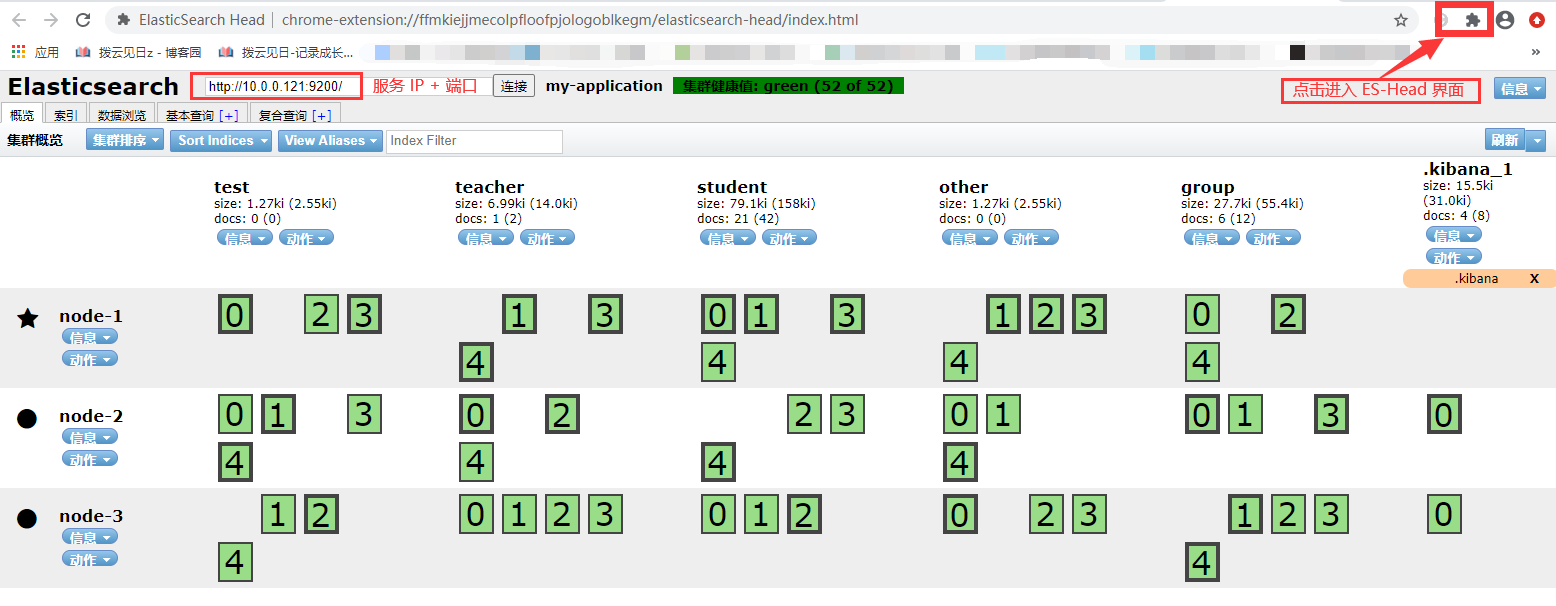
ES-Head 插件
谷歌浏览器安装 ES-Head 插件,点击下载
将解压后的文件夹拖入谷歌浏览器扩展程序界面即可
部署 Kibana
安装 Kibana
# 上传代码包
[root@dbtest01 ~]# rz kibana-6.6.0-x86_64.rpm
# 安装
[root@dbtest01 ~]# rpm -ivh kibana-6.6.0-x86_64.rpm
配置 Kibana
[root@dbtest01 ~]# vim /etc/kibana/kibana.yml
[root@dbtest01 ~]# grep "^[a-Z]" /etc/kibana/kibana.yml
# 进程的端口
server.port: 5601
# 监听地址
server.host: "10.0.0.121"
# 指定 ES 地址
elasticsearch.hosts: ["http://127.0.0.1:9200"]
# Kibana 也会创建索引
kibana.index: ".kibana"
启动 Kibana
# 启动 Kibana
[root@dbtest01 ~]# systemctl start kibana.service
# 验证
[root@dbtest01 ~]# netstat -lntp
tcp 0 0 10.0.0.121:5601 0.0.0.0:* LISTEN 88636/node
浏览器访问页面
# 访问 http://10.0.0.121:5601 , Kibana 启动速度较慢
ElasticSearch 数据操作
创建索引
# 语法:
PUT /<index>
# 示例:
PUT /laowang
PUT xiaowang
创建数据
ES 存储数据三个必要构成条件,每一条数据必须有以下的数据结构,
| 构成条件 | 说明 |
|---|---|
| _index | 索引(数据存储的地方) |
| _type | 类型(数据对应的类) |
| _id | 数据唯一标识符 |
# 语法
PUT /<index>/_doc/<_id>
POST /<index>/_doc/
PUT /<index>/_create/<_id>
POST /<index>/_create/<_id>
index:索引名称,如果索引不存在,会自动创建
_doc:类型
<_id>:唯一识别符,创建一个数据时,可以自定义ID,也可以让他自动生成
指定 ID 插入数据(PUT)
PUT /student/user/3
{
"name": "zzz",
"gender": "male",
"age": "23",
"about": "abcdefg",
"interests": [
"sturdy",
"dddddd"
]
}
# 一般不用此方式插入数据
# —— 需要修改 ID 值
# —— 当指定 ID 时,插入数据时会查询数据对比 ID 值,若 ID 相同,则会覆盖更新原来的数据
随机 ID 插入数据(POST)
# ES 会随机生成一个较长字符串作为此条数据的唯一 ID 标识
POST /student/user/
{
"name":"xiaoliu",
"gender":"female"
}
添加指定字段
# 推荐使用方法
POST /student/user/
{
"id":"1",
"name":"xiaoliu",
"gender":"female"
}
查询数据
简单查询
# 查看所有索引信息
GET /_all
GET _all
# 查看所有索引的数据
GET /_all/_search
# 查看指定索引信息
GET /student
# 查看指定索引的数据
GET /student/_search
# 查看指定数据
GET /student/user/1
条件查询(Term,Match)
①. — term 代表完全匹配,也就是精确查询,搜索前不会再对搜索词进行分词,例如,我们要搜索标题(title)为 "北京烤鸭" 的所有文档:
# 方法一:
GET /news/_search
{
"query": {
"term": {
"title": {
"value": "北京烤鸭"
}
}
}
}
# 可以省略 value 行,与 Key 合并到一行
GET /news/_search
{
"query": {
"term": { <-------- 使用 term 匹配,适用于精确查找
"title":"北京烤鸭" <------- 简写,并为一行
}
}
}
②. — match 代表模糊匹配,先对搜索词进行分词,例如,我们要搜索标题(title)为 "北京烤鸭" 的文档时,会先将 "北京烤鸭" 分词为 "北京" 和 "烤鸭",符合两者其一的,都会取到结果:
# 方法二:
GET /news/_search
{
"query": {
"match": { <-------- 使用 match 匹配,适用于模糊查找
"title": "北京烤鸭"
}
}
}
多条件查询(Bool)
Bool 查询现在包括四种子句:must,filter,should,must_not
①. — must 查询:查询条件必须全部满足,类似 SELECT 语句中 的 AND:
# 查询条件必须全部满足
GET /student/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"age": {
"value": "23"
}
}
},
{
"term": {
"name": {
"value": "wqh"
}
}
}
]
}
}
}
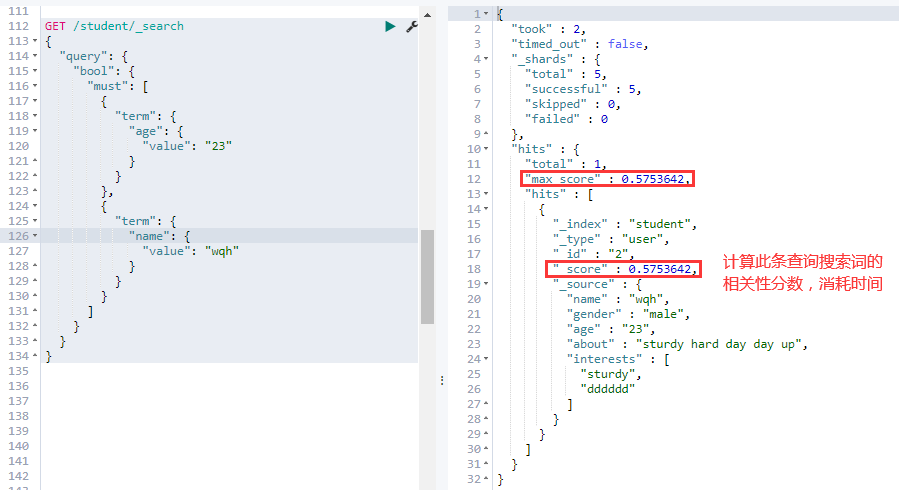
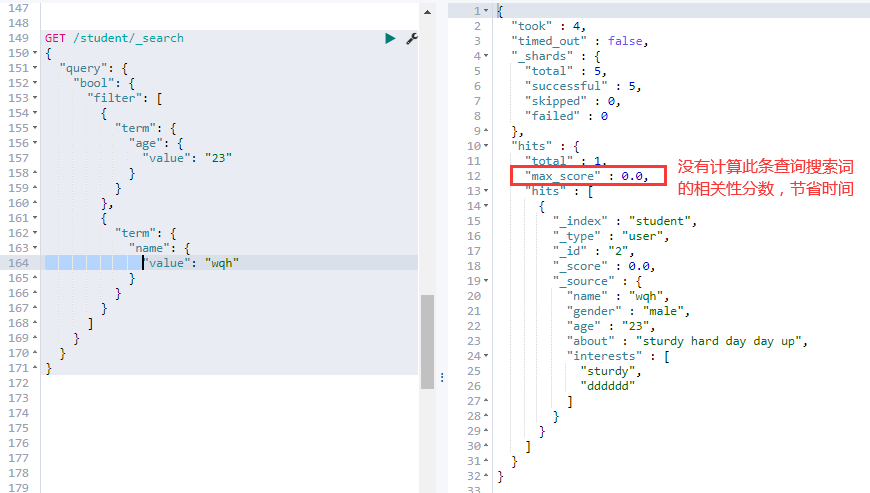
②. — filter 查询:查询条件必须全部满足,类似 SELECT 语句中的 AND,与 must 不同的是,不会计算相关性分数:
# 跟 must 一样,在数据量很大时,比 must 查询快一点,因为不用计算相关分
GET /student/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"age": {
"value": "23"
}
}
},
{
"term": {
"name": {
"value": "wqh"
}
}
}
]
}
}
}
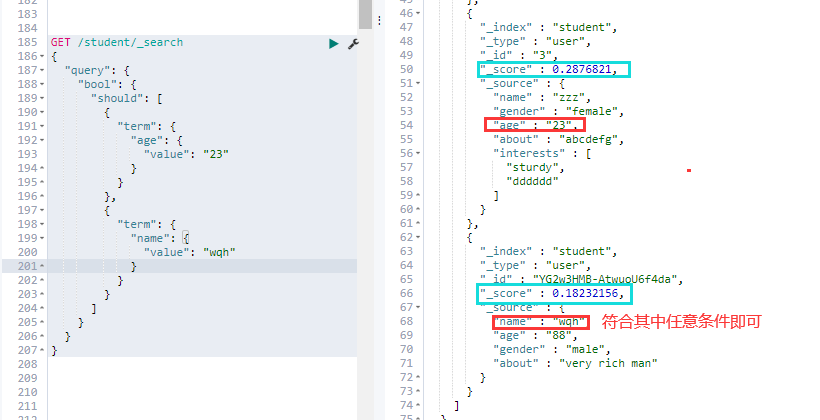
③. — should 查询:查询条件满足其一即可,类似 SELECT 语句中的 OR,会计算相关性分数:
# 多条件查询时,查询条件只要有一个满足就可以
GET /student/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"age": {
"value": "23"
}
}
},
{
"term": {
"name": {
"value": "wqh"
}
}
}
]
}
}
}
④. — must_not 查询:查询条件必须不满足,类似 SELECT 语句中的 NOT,会计算相关性分数 :
# must_not 中的条件,必须全部不满足
GET /student/_search
{
"query": {
"bool": {
"must_not": [
{
"term": {
"age": {
"value": "23"
}
}
},
{
"term": {
"name": {
"value": "wqh"
}
}
}
]
}
}
}
⑤. — must + should 查询:
# 查询年龄是 23岁 或者年龄是 18岁 并且名字是 wqh 的数据
GET /student/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"age": {
"value": "23"
}
}
},
{
"bool": {
"must": [
{
"term": {
"age": {
"value": "18"
}
}
},
{
"term": {
"name": {
"value": "xiaozi"
}
}
}
]
}
}
]
}
}
}
⑥. — 范围查询:
GET /student/_search
{
"query": {
"bool": {
"must": [
{
"range": {
"age": {
"gte": 20,
"lte": 25
}
}
}
]
}
}
}
修改数据
# 修改数据时指定 ID 修改
PUT /student/user/1
{
"name":"雾山火行",
"gender":"male",
"age":"18"
}
# 注意,修改数据时,除了要修改的值,其他字段的值也要带上,否则原有的其他字段会丢失
PUT /student/user/2
{
"name":"wqh",
"gender":"male",
"age":"19"
}
删除数据
# 删除指定 ID 数据
DELETE /student/user/4
# 删除索引(别瞎删,可以用 ES-head 关闭索引)
DELETE /student
Query Context(不带 Filter) 与 Filter Context
①. — Query Context 即指所有不使用 Bool 查询中的 Filter(过滤器)的上下文查询
②. — Filter Context 指 Bool 查询中,使用 Filter(过滤器)的上下文查询
查询在 Query 查询上下文和 Filter 过滤器上下文中,执行的操作是不一样的:
①. — 查询上下文:是在使用 query 进行查询时的执行环境,比如使用 search 的时候。
在查询上下文中,查询会回答这个问题——“这个文档是否匹配,它的相关度高么?”
ES中索引的数据都会存储一个 _score 分值,分值越高就代表越匹配。即使 lucene 使用倒排索引,对于某个搜索的分值计算还是需要一定的时间消耗 。
②. — 过滤器上下文:在使用 filter 参数时候的执行环境,比如在 bool 查询中使用 Must_not 或者 filter
在过滤器上下文中,查询会回答这个问题——“这个文档是否匹配?”
它不会去计算任何分值,也不会关心返回的排序问题,因此效率会高一点。
另外,经常使用过滤器,ES会自动的缓存过滤器的内容,这对于查询来说,会提高很多性能。
总而言之:
①. — 查询上下文:查询操作不仅仅会进行查询,还会计算分值,用于确定相关度;
②. — 过滤器上下文:查询操作仅判断是否满足查询条件,不会计算得分,查询的结果可以被缓存,所以速度快
所以,根据实际的需求是否需要获取得分,考虑性能因素,选择不同的查询子句;如果不需要获得查询词条的相关性分数,尽量使用 Filter 。
参考:
ElasticSearch 交互使用的更多相关文章
- 使用spark与ElasticSearch交互
使用 elasticsearch-hadoop 包,可在 github 中搜索到该项目 项目地址 example import org.elasticsearch.spark._ import org ...
- PHP如何与搜索引擎Elasticsearch交互?
一:参考官方文档 1. Elasticsearch 5.4.0英文手册:https://www.elastic.co/guide/en/elasticsearch/reference/5.4/sear ...
- 与Elasticsearch交互的客户端
1.访问ES的方式 访问es的方式有两种,一种是http方式,还有一种是java客户端方式. 其中Java客户端又分为:1.1.Node client: 节点客户端实际上是一个集群中的节点(但不保存数 ...
- Elasticsearch安装和使用
Elasticsearch安装和使用 Elasticsearch 是开源搜索平台的新成员,实时数据分析的神器,发展迅猛,基于 Lucene.RESTful.分布式.面向云计算设计.实时搜索.全文搜索. ...
- elasticsearch集群搭建实例
elasticsearch集群搭建实例 下个月又开始搞搜索了,几个月没动这块还好没有落下. 晚上在自己虚拟机上搭建了一个简易搜索集群,分享一下. 操作系统环境: Red Hat 4.8.2-16 el ...
- Elasticsearch教程-从入门到精通(转载)
转载,原文地址:http://mageedu.blog.51cto.com/4265610/1714522?utm_source=tuicool&utm_medium=referral 各位运 ...
- Elasticsearch简介与实战
什么是Elasticsearch? Elasticsearch是一个开源的分布式.RESTful 风格的搜索和数据分析引擎,它的底层是开源库Apache Lucene. Lucene 可以说是 ...
- Elasticsearch入门教程之安装与基本使用
ubuntu16.04+elasticsearch6.5为例,参考官网文档https://www.elastic.co/guide/en/elasticsearch/reference/current ...
- Elasticsearch通关教程(一): 基础入门
简介 Elasticsearch是一个高度可扩展的.开源的.基于 Lucene 的全文搜索和分析引擎.它允许您快速,近实时地存储,搜索和分析大量数据,并支持多租户. Elasticsearch也使用J ...
随机推荐
- oracle 12C单实例打PSU
前提: oracle不管打什么样的补丁,readme都是很好的参考资料. Oracle每季度都会更新一个最新的PSU,现在12.1.0.2.0的最新的PSU是Patch 26925311. 由于今天白 ...
- SAP轻松访问会话管理器等设置
对于SAP的登陆后初始界面,是有一个配置表,可以进行设置的,例如隐藏SAP的标准菜单,设置轻松访问页面右边的图片内容等等这一切的设置都可以通过维护SSM_CUST表来实现可以通过SM30来维护内容,该 ...
- 跨平台导PDF,结合wkhtmltopdf很顺手
前言 好东西要分享,之前一直在使用wkhtmltopdf进行pdf文件的生成,常用的方式就是先安装wkhtmltopdf,然后在程序中用命令的方式将对应的html生成pdf文件,简单而且方便:但重复的 ...
- CMU数据库(15-445)Lab1-BufferPoolManager
0. 关于环境搭建请看 https://www.cnblogs.com/JayL-zxl/p/14307260.html 1. Task1 LRU REPLACEMENT POLICY 0. 任务描述 ...
- [Usaco2008 Mar]Cow Travelling游荡的奶牛
题目描述 奶牛们在被划分成N行M列(2 <= N <= 100; 2 <= M <= 100)的草地上游走,试图找到整块草地中最美味的牧草.Farmer John在某个时刻看见 ...
- 【Azure Redis 缓存】Windows和Linux系统本地安装Redis, 加载dump.rdb中数据以及通过AOF日志文件追加数据
任务描述 本次集中介绍使用Windows和Linux()搭建本地Redis服务器的步骤,从备份的RDB文件中加载数据,以及如何生成AOF文件和通过AOF文件想已经运行的Redis追加数据. 操作步骤 ...
- Linq.Expressions扩展ExpressionExtension
手上有一个以前项目用到的.NET工具类封装的DLL. 正好又想试一下动态LAMBDA表达式,用.NET Reflector看一下源码. public static class ExpressionEx ...
- 白日梦的Elasticsearch实战笔记,32个查询案例、15个聚合案例、7个查询优化技巧。
目录 一.导读 三._search api 搜索api 3.1.什么是query string search? 3.2.什么是query dsl? 3.3.干货!32个查询案例! 四.聚合分析 4.1 ...
- 使用pushplus+python实现亚马逊到货消息推送微信
xbox series和ps5发售以来,国内黄牛价格一直居高不下.虽然海外amazon上ps5补货很少而且基本撑不过一分钟,但是xbox series系列明显要好抢很多. 日亚.德亚的xbox ser ...
- (Oracle)常用的数据库函数
Trim: Trim() 函数的功能是去掉首尾空格. Eg: trim(to_char(level, '00')) Trunc: 1.TRUNC函数为指定元素而截去的日期值. trun ...