使用Python实现搜索任意电影资源的磁力链接
对于喜欢电影的人来说各种电影资源必不可少,但每次自己搜索都比较麻烦,索性用python自己写一个自动搜索的脚本。
这里我只分享我的思路,具体如何实现参考代码,要想实现搜索功能先要抓包分析如何发送数据,这里我用的是burp,
这是电影网站搜索框,

输入电影名抓取数据报:
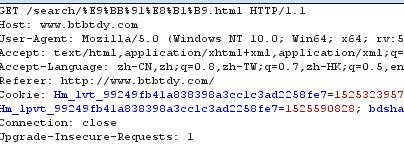
数据一get方式提交,并且进行了url编码,%E9%BB%91%E8%B1%B9进行url解码后正是“黑豹”两个字
python中用于处理url编码的是urllib中的quote模块
name=黑豹
uname=quote(name)
所以我们提交数据的地址为:url='http://www.btbtdy.com/search/'+uname+'.html'
之后就得到这个界面:
我们只需要拿到最顶端的那个连接就行,直接用beautifulsoup进行匹配也可以用re正则匹配,找到“黑豹"两个字的herf属性即可
最后得到的数据为”/btdy/dy7706.html",与原网址进行拼接记得到我们要找电影资源的主页面为:
http://www.btbtdy.com/btdy/dy7706.html
到达主页面后,如果你直接用以前的办法直接用正则或其他的办法去匹配磁力链接的话是不行的,因为这是一个动态的页面,
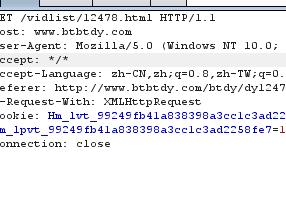
思路依旧是抓包分析,可以看出主页面提交后有提交多个其他的请求,其中有也个请求是这样的:
在网页上访问后是这样的:
这才是我们要找的网页,只有在这个网页上才能找到真正的资源


上代码:(代码还没有进行异常处理)
1 import requests
2 from bs4 import BeautifulSoup
3
4 from urllib.parse import quote
5 import time
6 import re
7 import threading
8
9 head = {
10 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
11 'Referer':'http://www.btbtdy.com/'
12 }
13
14 print('-----------------------------')
15 name=input('请输入需要查找的电影:')
16 print('-----------------------------')
17 uname=quote(name)
18
19 def pyhead():
20
21 url='http://www.btbtdy.com/search/'+uname+'.html'
22
23 return url
24
25 def gethtml(url):
26
27 link=url
28 html=requests.get(link,head)
29 time.sleep(5)
30 soup = BeautifulSoup(html.text, "lxml")
31 html = html.content.decode('utf-8')
32 sorry="对不起,没有找到任何记录,"
33 sodiv=soup.find('div',class_="list_so")
34 if sorry in str(sodiv):
35 print("网站没有资源")
36 else:
37 title=soup.find_all('a',class_="so_pic")
38 r=r'href="(.+?)" '
39 title=re.findall(r,str(title[0]))
40 print("网址为:http://www.btbtdy.com"+title[0])
41 return title
42
43 def gethtml2(title):
44 dr=r'btdy/dy(.+?).html'
45 dtit=re.findall(dr,title[0])
46 url2='http://www.btbtdy.com/vidlist/'+dtit[0]+'.html'
47 dhtml=requests.get(url2,head)
48 time.sleep(5)
49 dsoup=BeautifulSoup(dhtml.text,'lxml')
50 return dsoup
51
52 def getdhtml(dsoup):
53 ddiv=dsoup.find_all('div',class_="p_list")
54 for model in ddiv:
55 h="<h2>720p下载地址</h2>"
56 h2="<h2>1080p下载地址</h2>"
57 h3="<h2>下载地址一</h2>"
58 if h in str(model):
59 print("720p:"'\n')
60 r='<a class="d1" href="(.+?)">磁力</a>'
61 dlink=re.findall(r,str(model))
62 for pdlink in dlink:
63 print(str(pdlink)+'\n')
64 if h2 in str(model):
65 print("1080p:"'\n')
66 r='<a class="d1" href="(.+?)">磁力</a>'
67 dlink=re.findall(r,str(model))
68 for pdlink in dlink:
69 print(str(pdlink))
70 if h3 in str(model):
71 print("磁力连接:"'\n')
72 r='<a class="d1" href="(.+?)">磁力</a>'
73 dlink=re.findall(r,str(model))
74 for pdlink in dlink:
75 print(str(pdlink)+'\n')
76
77
78 def start():
79 url=pyhead()
80 title=gethtml(url)
81 dsoup=gethtml2(title)
82 getdhtml(dsoup)
83 if __name__ == '__main__':
84 go=threading.Thread(start())
85 go.start()
使用Python实现搜索任意电影资源的磁力链接的更多相关文章
- 第11.5节 Python正则表达式搜索任意字符匹配及元字符“.”(点)功能介绍
在re模块中,任意字符匹配使用"."(点)来表示, 在默认模式下,点匹配除了换行的任意字符.如果指定了搜索标记re.DOTALL ,它将匹配包括换行符的任意字符.关于搜索标记的含义 ...
- 一篇文章教会你利用Python网络爬虫获取电影天堂视频下载链接
[一.项目背景] 相信大家都有一种头疼的体验,要下载电影特别费劲,对吧?要一部一部的下载,而且不能直观的知道最近电影更新的状态. 今天小编以电影天堂为例,带大家更直观的去看自己喜欢的电影,并且下载下来 ...
- nodejs 实现 磁力链接资源搜索 BT磁力链接爬虫
项目简介 前端站点 项目效果预览 http://findcl.com 使用 nodejs 实现磁力链接爬虫 磁力链接解析成 torrent种子信息,保存到数据库,利用 Elasticsearch 实现 ...
- Python爬虫爬取BT之家找电影资源
一.写在前面 最近看新闻说圣城家园(SCG)倒了,之前BT天堂倒了,暴风影音也不行了,可以说看个电影越来越费力,国内大厂如企鹅和爱奇艺最近也出现一些幺蛾子,虽然目前版权意识虽然越来越强,但是很多资源在 ...
- Python爬虫 -- 抓取电影天堂8分以上电影
看了几天的python语法,还是应该写个东西练练手.刚好假期里面看电影,找不到很好的影片,于是有个想法,何不搞个爬虫把电影天堂里面8分以上的电影爬出来.做完花了两三个小时,撸了这么一个程序.反正蛮简单 ...
- 学习Python编程的11个资源
用 Python 写代码并不难,事实上,它一直以来都是被声称为最容易学习的编程语言.如果你正打算学习 web 开发,Python 是一个不错的选择,甚至你想学游戏开发也可 以从 Python 开始,因 ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- 找电影资源最强攻略,知道这些你就牛B了!
找电影资源最强攻略,知道这些你就牛B了! 电影工厂 2015-07-01 · 分享 点击题目下方环球电影,关注中国顶尖电影微杂志 我们也许没有机会去走遍千山万水,却可以通过电影进入各种各样的角色来 ...
- 学习 Python 编程的 19 个资源 (转)
学习 Python 编程的 19 个资源 2018-01-07 数据与算法之美 编译:wzhvictor,英文:codecondo segmentfault.com/a/119000000418731 ...
随机推荐
- spring bean注册和实例化
1.左边3个接口定义了基本的Ioc容器的2.HierarchicalBeanFactory增加了getParentBeanFactory()具备了双亲Ioc的管理能力3.ConfigurableBea ...
- dubbo 远程调用
记得服务暴露的时候createServer()里 server = Exchangers.bind(url, requestHandler); requestHandler在DubboProtocol ...
- 【mq学习笔记】mq查找路由信息与故障延迟
路由发现:缓存中的路由信息什么时候更新呢? 由QueueData转topicPublishInfo的List<QueueMessage>: 选择消息队列: sendLatencyFault ...
- php项目使用git的webhooks实现自动部署
前言 在项目开发中使用git进行代码的管理,每次完成更改上传代码后,还需要登录服务器将代码拉取下来.现在git服务器(gitee/gitlab/github)都会有Webhooks功能,以实现在向gi ...
- ubuntu配置网络和静态路由(界面配置形式)
目录 网卡配置 静态ip配置 静态路由 外网ip配置(动态获取DHCP) 内网ip和静态路由配置 本文主要针对ubuntu18.0系统进行界面形式配置网络.并配置静态路由. 网卡配置 静态ip配置 打 ...
- vue获取浏览器地址栏参数(?及/)路由+非路由实现方式
1.? 参数 浏览器参数形式:http://javam4.com/m4detail?id=1322914793170014208 1.1.路由取参方式 this.$route.query.id 前端跳 ...
- Spring Cloud 学习 (八) Spring Boot Admin
Spring Boot Admin 用于管理和监控一个或者多个 Spring Boot 程序 新建 spring-boot-admin-server pom <parent> <ar ...
- Codeforces Educational Round 94 (Rated for Div. 2)
昨晚算是不幸中的万幸了 A题问的是给2n-1个01串,让你构造出来一个n串使得从1开始每个长度为n的串都至少存在有一个相似的地方 这道题我一开始没什么想法,但是手动观察发现每次可以留出来的空挡间隔为1 ...
- RabbitMQ,想说爱你不容易(附详细安装教程)
前言 本文讲述的只是主要是 RabbitMQ 的入门知识,学习本文主要可以掌握以下知识点: MQ 的发展史 AMQP 协议 Rabbit MQ 的安装 Rabbit MQ 在 Java API 中的使 ...
- 第2.3节 Python运算符大全
一. Python的算术运算 Python的算术运算符与C语言类似,略有不同.包括加(+).减(-).乘(*).除(/).取余(%).按位或(|).按位与(&).按位求补(~).左移位(< ...