RabbitMq之消息确认
最近阅读了rabbitmq的官方文档,然后结合之前面试时被问到关于消息队列的问题来探索一下关于消息队列的消息确认机制。
其实消息确认就是消费者确认消息被消费了, 生产者确认消息已经发送到了消息队列中了。
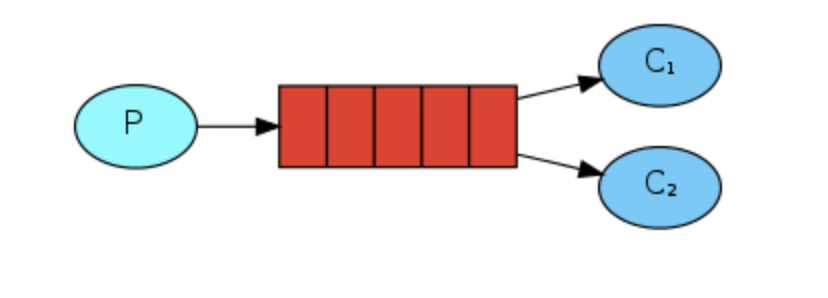
我们知道rabbitmq有四种消息机制,下图是为了我们对消息确认的理解从官网盗了一张工作队列的图如下:
一、 关于消费者确认方面问题
在我们的mq推送了消息给消费者后,我们怎么知道消息被消费者消费了呢?万一消费者没有消费该消息,或者消费者挂了,这消息是不是就永久丢失了,所以根据此有下列几个关于消费者确认的相关问题。同时在这我们也纠正一个常见的误区,mq是推消息到消费者处的而不是消费者去mq中取消息的,然后在mq中消息充足的情况下,mq推消息给消费者不是等消费者消费完一个再推一个,而是根据 prefetch_count参数来决定可以推多个消息到消费者的缓存里面。
问题1: 如果其中一个消费者开始一项漫长的任务,而仅部分完成而死掉,会发生什么情况。使用我们当前的代码,RabbitMQ一旦将消息传递给消费者,便立即将其标记为删除。在这种情况下,如果您杀死一个work,我们将丢失正在处理的消息。我们还将丢失所有发送给该特定工作人员但尚未处理的消息。
答:为了确保消息永不丢失,RabbitMQ支持 消息确认。消费者发送回一个确认(acknowledgement)以告知RabbitMQ已经接收,处理了特定的消息,然后RabbitMQ会去删除这条消息,如果消费者在不发送确认的情况下死亡(其通道已关闭,连接已关闭或TCP连接丢失),RabbitMQ将了解消息未得到充分处理,并将重新排队。如果同时有其他消费者在线,它将很快将其重新分发给另一个消费者。这样,您可以确保即使工人偶尔死亡也不会丢失任何消息
问题2:开启了消息持久化,消息就一定不会丢失吗?
答: 将消息标记为持久性并不能完全保证不会丢失消息。尽管它告诉RabbitMQ将消息保存到磁盘,但是仍有很短的时间RabbitMQ接受了消息但尚未将其保存。另外,RabbitMQ不会对每条消息都执行fsync(2)-它可能只是保存到缓存中,而没有真正写入磁盘。持久性保证并不强,但是对于我们的简单任务队列而言,这已经绰绰有余了。如果您需要更强有力的保证,则可以使用 发布者确认。
在这里补充一个知识:如果mq开启了持久化以后, 生产者把消息推给消息队列, 消息队列会复制一份消息到持久化队列,然后有新线程从持久化队列中把消息持久化到磁盘中。
问题3: 两个消费者同时消费一个队列,是队列分发消息还是消费者去取消息?
答:您可能已经注意到,调度仍然无法完全按照我们的要求进行。例如,在有两名工人的情况下,当有的消息都很重,有的消息消息很轻时,一位工人将一直忙碌而另一位工人将几乎不做任何工作。好吧,RabbitMQ对此一无所知,并且仍将平均分配消息。
问题4: 关于队列大小的注意事项,如果队列满了怎么处理?
答:如果队列满了以后,我们一方面可以增加消费者的数量,很浅显消费者越多消费消息就越快,还有一个是设置消息的过期时间来控制。
这里补充个知识: 当消息过期或者被消费者拒绝并且设置不返回队列中,这消息将加入死信队列。
二、关于生产者确认方面问题
同样的,我们的生产者给mq push消息的时候,我们怎么知道这消息放进了mq里面了呢?所以这引发了mq确认消息的相关问题。
问题1: 发布者确认消息机制是怎样的?
答:首先消息的传递机制是这样,发布者将消息发送到消息队列的exchange中,然后根据exchange的分发规则,分发到制定具体队列,如果开启了持久化,消息会复制一份持久化队列中, 持久化队列在收到消息后会给队列返回ack确认信息, 然后队列给exchange返回确认信息, exchange根据回调函数给发布者返回确认信息,这样发布者确认就算完成了。
当时你知道发布者的确认规则,你是不是立马想到确认要经过这么多个中间人,省略中间的环节行不行勒,哈哈答案是可以的,不过得自己去改造啦,这是性能优化的一项。
问题2:发布者确认的方式有哪几种?
答:有三种确认方式
1)同步确认,消息发出后一直处于阻塞状态等待确认消息,可以设置超时时间,如果超过超时时间则认为消息丢失, 如果超时或者消息确认失败则会抛出异常,我们捕获异常然后选择是重发还是等其他处理方式。
2)批量确认,一次性发出一批消息然后阻塞等待,形式和同步确认相似,有点则是一批确认所以性能上会有很大的提升,缺点是我们不能确认具体发生了什么错误,并且我们得在内存中存储这批消息以确认发送成功的消息和重发失败的消息。
3)异步确认,发送消息后注册一个回调函数,不阻塞线程,在消息确认后会调用回调函数
如果想更详细地了解其机制可以阅读其官方文档,文档中有关于消息确认的具体代码展示,可以更方便地理解其机制。
RabbitMq之消息确认的更多相关文章
- Java使用RabbitMQ之消息确认(confirm模板)
RabbitMQ生产者消息确认Confirm模式,分为普通模式.批量模式和异步模式,本次举例为普通模式. 源码: package org.study.confirm4; import com.rabb ...
- RabbitMQ的消息确认机制
一:确认种类 RabbitMQ的消息确认有两种. 一种是消息发送确认.这种是用来确认生产者将消息发送给交换器,交换器传递给队列的过程中,消息是否成功投递.发送确认分为两步,一是确认是否到达交换器,二是 ...
- RabbitMq初探——消息确认
消息确认机制 前言 消息队列的下游,业务逻辑可能复杂,处理任务可能花费很长时间.若在一条消息到达它的下游,任务刚处理了一半,由于不确定因素,下游的任务处理进程 被kill掉啦,导致任务无法执行完成.而 ...
- RabbitMQ学习笔记六:RabbitMQ之消息确认
使用消息队列,必须要考虑的问题就是生产者消息发送失败和消费者消息处理失败,这两种情况怎么处理. 生产者发送消息,成功,则确认消息发送成功;失败,则返回消息发送失败信息,再做处理. 消费者处理消息,成功 ...
- RabbitMQ 之消息确认机制(事务+Confirm)
概述 在 Rabbitmq 中我们可以通过持久化来解决因为服务器异常而导致丢失的问题,除此之外我们还会遇到一个问题:生产者将消息发送出去之后,消息到底有没有正确到达 Rabbit 服务器呢?如果不错得 ...
- RabbitMQ (十一) 消息确认机制 - 消费者确认
由于生产者和消费者不直接通信,生产者只负责把消息发送到队列,消费者只负责从队列获取消息(不管是push还是pull). 消息被"消费"后,是需要从队列中删除的.那怎么确认消息被&q ...
- springboot整合rabbitmq,支持消息确认机制
安装 推荐一篇博客https://blog.csdn.net/zhuzhezhuzhe1/article/details/80464291 项目结构 POM.XML <?xml version= ...
- 快速掌握RabbitMQ(三)——消息确认、持久化、优先级的C#实现
1 消息确认 在一些场合,如转账.付费时每一条消息都必须保证成功的被处理.AMQP是金融级的消息队列协议,有很高的可靠性,这里介绍在使用RabbitMQ时怎么保证消息被成功处理的.消息确认可以分为两种 ...
- RabbitMQ的消息确认ACK机制
1.什么是消息确认ACK. 答:如果在处理消息的过程中,消费者的服务器在处理消息的时候出现异常,那么可能这条正在处理的消息就没有完成消息消费,数据就会丢失.为了确保数据不会丢失,RabbitMQ支持消 ...
随机推荐
- celery 错误相关:Monkey-patching not on the main thread; threading.main_thread().join() will hang from a greenlet
/Users/wangpingyang/.pyenv/versions/3.7.2/lib/python3.7/site-packages/httprunner/__init__.py:5: Monk ...
- Mysql and ORM
本节内容 数据库介绍 mysql 数据库安装使用 mysql管理 mysql 数据类型 常用mysql命令 创建数据库 外键 增删改查表 权限 事务 索引 python 操作mysql ORM sql ...
- Mysql----左连接、右连接、内连接、全连接的区别
最近,突然想起来数据库有好些时间没用到,所以,想把数据库有关的知识回顾一下,所以接下来这个月,基本上会以数据库的帖子来写为主,首先,很多同学都会有个错觉,觉得学习数据库会sql语句的增删改查就够了,其 ...
- vscode切换虚拟环境报错无法加载文件 E:\Python_project\shop_env\Scripts\Activate.ps1,因为在此系统上禁止运行 脚本。
在使用vscode切换python的虚拟环境时报错 解决方法如下: Windows+x打开面板,选择以管理员身份运行PowerShell,输入: set-executionpolicy remotes ...
- 在Java中使用AES加密
本文转载https://blog.csdn.net/z69183787/article/details/82746686
- 【Maven】总结
导言:生产环境下开发不再是一个项目一个工程,而是每一个模块创建一个工程,而多个模块整合在一起就需要 使用到像 Maven 这样的构建工具. 1 Why? 1.1 真的需要吗? Maven 是干什么用的 ...
- HDFS+ClickHouse+Spark:从0到1实现一款轻量级大数据分析系统
在产品精细化运营时代,经常会遇到产品增长问题:比如指标涨跌原因分析.版本迭代效果分析.运营活动效果分析等.这一类分析问题高频且具有较高时效性要求,然而在人力资源紧张情况,传统的数据分析模式难以满足.本 ...
- 什么是控制反转(IoC)?什么是依赖注入(DI)?以及实现原理
IoC不是一种技术,只是一种思想,一个重要的面向对象编程的法则,它能指导我们如何设计出松耦合.更优良的程序.传统应用程序都是由我们在类内部主动创建依赖对象,从而导致类与类之间高耦合,难于测试:有了 ...
- Ethical Hacking - Overview
Hacking is gaining unauthorized access to anything. Preparation Setting up a lab and installing need ...
- assemble、compile、make、build和rebuild的关系
assemble:打包(之前已经编译了源文件)compile.make.build和rebuild都是编译过程:将源代码转换为可执行代码的过程,Java的编译会将java编译为class文件,将非ja ...