[.net 面向对象程序设计进阶] (3) 正则表达式 (二) 高级应用
[.net 面向对象程序设计进阶] (2) 正则表达式 (二) 高级应用
上一节我们说到了C#使用正则表达式的几种方法(Replace,Match,Matches,IsMatch,Split等),还有正则表达式的几种元字符及其应用实例,这些都是学习正则表达式的基础。本节,我们继续深入学习表达式的几种复杂的用法。
1.分组
用小括号来指定子表达式(也叫做分组)
我们通过前一节的学习,知道了重复单个字符,只需要在字符后面加上限定符就可以了,
比如 a{5},如果要重复多个字符,就要使用小括号分组,然后在后面加上限定符,下面我们看一个示例。
示例一:重复单字符 和 重复分组字符
//示例:重复单字符 和 重复分组字符
//重复 单个字符
Console.WriteLine("请输入一个任意字符串,测试分组:");
string inputStr = Console.ReadLine();
string strGroup1 = @"a{2}";
Console.WriteLine("单字符重复2两次替换为22,结果为:"+Regex.Replace(inputStr, strGroup1,""));
//重复 多个字符 使用(abcd){n}进行分组限定
string strGroup2 = @"(ab\w{2}){2}";
Console.WriteLine("分组字符重复2两次替换为5555,结果为:" + Regex.Replace(inputStr, strGroup2, ""));
运行结果如下:

示例二:校验IP4地址(如:192.168.1.4,为四段,每段最多三位,每段最大数字为255,并且第一位不能为0)
//示例:校验IP4地址(如:192.168.1.4,为四段,每段最多三位,每段最大数字为255,并且第一位不能为0)
string regexStrIp4 = @"^(((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?))$";
Console.WriteLine("请输入一个IP4地址:");
string inputStrIp4 = Console.ReadLine();
Console.WriteLine(inputStrIp4 + " 是否为合法的IP4地址:" + Regex.IsMatch(inputStrIp4, regexStrIp4));
Console.WriteLine("请输入一个IP4地址:");
string inputStrIp4Second = Console.ReadLine();
Console.WriteLine(inputStrIp4 + " 是否为合法的IP4地址:" + Regex.IsMatch(inputStrIp4Second, regexStrIp4));
运行结果如下:

在这个正则表达式中,我们需要理解 2[0-4]\d|25[0-5]|[01]?\d\d?
这部分表示一个三位数的三种形式
2[0-4]\d 表示:2开头+0~4的一位数字+任意数
25[0-5] 表示:25开头+0~5的一位数字
[01]?\d\d? 表示:0或1或空 + 一位任意数字 + 一位任意数或空
这三种形式使用|分开,表示择一种匹配
理解了这段,整体就理解了,前半部分为 重复三次带.号,后面一个不带.号
^ 和 $ 表示匹配整体的开始和结束
2. 后向引用
在这节之前,还是比较好理解的,这段有点难以理解了,但是我们还得拍拍脑袋继续学习。
先不说后向引用是啥,我们先说,后向引用能干啥?
前面我们说了分组的概念,就是在正则表达式中使用小括号()完成分组,后向引用就是针对分组的。
如果前面分组以后,后面还要检索前面分组内同样的内容,就用到了后向引用,意思就是后面引用前面的分组之意。
…………………………………………………………………容我喘口气…………………………………………………………………………………………
那么要如何在后面引用前面分组呢?
这里就需要有一个组名,即定义一个组名,在后面引用。
在定义组名前,说一下
正则对于分组的工作原理:
A.分组后,正则会自动为每个分组编一个组号
B.分配组号时,从左往右扫描两遍,第一遍给未命名分组分配组号,第二遍自然是给命名组分配组号。因此,命名组的组号是大于未命名组的组号。(说这些工作原理,对我们使用后向引用没有什么作用,就是理解一下,内部工作原理而已)
C.也不是所有的组都会分配组号,我们可以使用(:?exp)来禁止分配组号。
不知道小伙伴们是否看明白了,至少我看了网上关于这块儿的介绍,都不是很清晰。
下面先看一下后向引用 捕获 的定义
|
分类 |
代码/语法 |
说明 |
|
捕获 |
(exp) |
匹配exp,并捕获文本到自动命名的组里 |
|
(?<name>exp) |
匹配exp,并捕获文本到名称为name的组里,也可以写成(?'name'exp) |
|
|
(?:exp) |
匹配exp,不捕获匹配的文本,也不给此分组分配组号 |
先来对上面的三个语法理解一下:
(exp) 就是分组,使用() ,exp就是分组内的子表达式 ,这个在上面分组中已经说明了
(?<name>exp)或 (?’name’exp) 就是组分组命名,只是有两种写法而已
(?:exp)exp表达式不会被捕获到某个组里,也不会分配组号,但不会改变正则处理方式,肯定很多小盆友要问,为啥要有这个东西,要他何用?
大家看一下下面这个示例:
^([1-9][0-9]*|0)$ 表示匹配0-9的整数
再看下面这个
^(?:[1-9][0-9]*|0)$ 也是匹配0-9的整数,但是使用了非捕获组
作用呢?两个字:效率
因为我们定义了组,但是我们只是为了使用组来限定范围开始和结束,并不是为了后向引用,因此使用非捕获组来禁上分配组号和保存到组里,极大的提高了检索效率。
有了上面的理解,我才好写点示例,先理论后实践。
在进行示例前,我们先复习以下上节学到的元字符
* 匹配前面的子表达式任意次。例如,zo* 能匹配“z”,“zo”以及“zoo”。*等价于{ 0,}。
+ 匹配前面的子表达式一次或多次(大于等于1次)。例如,“zo +”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{ 1,}。
? 匹配前面的子表达式零次或一次。例如,“do (es) ?”可以匹配“do”或“does”中的“do”。?等价于{ 0,1}。
\w 匹配包括下划线的任何单词字符。类似但不等价于“[A-Za-z0-9_]”,这里的"单词"字符使用Unicode字符集。
\b 匹配一个单词边界,也就是指单词和空格间的位置(即正则表达式的“匹配”有两种概念,一种是匹配字符,一种是匹配位置,这里的\b就是匹配位置的)。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”。
\s 匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。
//后向引用 //在后向引用前,我们先熟悉一下单词的查找
//复习一下前面学的几个元字符
// * 匹配前面的子表达式任意次。例如,zo* 能匹配“z”,“zo”以及“zoo”。*等价于{ 0,}。
// + 匹配前面的子表达式一次或多次(大于等于1次)。例如,“zo +”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{ 1,}。
// ? 匹配前面的子表达式零次或一次。例如,“do (es) ?”可以匹配“do”或“does”中的“do”。?等价于{ 0,1}。
// \w 匹配包括下划线的任何单词字符。类似但不等价于“[A-Za-z0-9_]”,这里的"单词"字符使用Unicode字符集。
// \b 匹配一个单词边界,也就是指单词和空格间的位置(即正则表达式的“匹配”有两种概念,一种是匹配字符,一种是匹配位置,这里的\b就是匹配位置的)。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”。
// \s 匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。
string str1 = "zoo zoo hello how you mess ok ok home house miss miss yellow"; //示例一:查找单词中以e结尾的,并将单词替换为了*
string regexStr1 = @"\w+e\b";
Console.WriteLine("示例一:" + Regex.Replace(str1, regexStr1,"*")); //示例二:查询单词中以h开头的,并将单词替换为#
string regexStr2 = @"\bh\w+";
Console.WriteLine("示例二:" + Regex.Replace(str1, regexStr2, "#")); //示例三:查找单词中有重叠ll的单词,将单词替换为@
string regexStr3 = @"\b\w+l+\w+\b";
Console.WriteLine("示例三:" + Regex.Replace(str1, regexStr3, "@"));
此外,我们说到了分组及编号,那么如何取到某个分组的匹配文本呢?
使用 \1 表示取第一个分组的匹配文本
//使用 \1 代表第一个分组 组号为1的匹配文本
//示例四:查询单词中有两个重复的单词,替换为%
string regexStr4 = @"(\b\w+\b)\s+\1";
Console.WriteLine("示例四:" + Regex.Replace(str1, regexStr4, "%"));
//上面示例中,第一个分组匹配任意一个单词 \s+ 表示任意空字符 \1 表示匹配和第一个分组相同
别名定义 (?<name>exp) ,别名后向引用 \k<name>
//使用别名 代替 组号 ,别名定义 (?<name>exp) ,别名后向引用 \k<name>
//示例五:使用别名后向引用 查询 查询单词中有两个重复的单词,替换为%%
string regexStr5 = @"(?<myRegWord>\b\w+\b)\s+\k<myRegWord>";
Console.WriteLine("示例五:"+Regex.Replace(str1, regexStr5, "%%"));
运行结果如下:

3. 零宽断言
什么!?什么!?对你没看错,这段题目叫“零宽断言”(顿时1W头艹尼马奔腾而过!!!!)
本来正则表达式学到本节,小伙伴们渐渐感觉看着有点吃力了,还来这么一个名字。
不过,不要忘记,我们这一系列的文章叫“.NET 进阶”既然是进阶,自然就有很多有难度的问题要解决,我们还是先看一下这个概念的意思吧!
什么是零宽断言?
我们有经常要查询某些文本某个位置前面或后面的东西,就像 ^ $ \b一样,指定一个位置,这个位置需要满足一定的条件(断言),我们把这个称做 零宽断言
|
分类 |
代码/语法 |
说明 |
|
零宽断言 |
(?=exp) |
匹配exp前面的位置 |
|
(?<=exp) |
匹配exp后面的位置 |
|
|
(?!exp) |
匹配后面跟的不是exp的位置 |
|
|
(?<!exp) |
匹配前面不是exp的位置 |
看上面的表,零宽断言一共有四个类型的位置判断写法
我们先举几个示例来看看,TMD零宽断言到底解决了什么问题?
//零宽断言
//示例一:将下面字符串每三位使用逗号分开
string stringFist = "dfalrewqrqwerl43242342342243434abccc";
string regexStringFist = @"((?=\w)\w{3})";
string newStrFist = String.Empty;
Regex.Matches(stringFist, regexStringFist).Cast<Match>().Select(m=>m.Value).ToList<string>().ForEach(m => newStrFist += (m+","));
Console.WriteLine("示例一:" + newStrFist.TrimEnd(',')); //示例二:查询字符串中,两个空格之间的所有数字
string FindNumberSecond = "asdfas 3 dfasfas3434324 9 8888888 7 dsafasd342";
string regexFindNumberSecond = @"((?<=\s)\d(?=\s))";
string newFindNumberSecond = String.Empty;
Regex.Matches(FindNumberSecond, regexFindNumberSecond).Cast<Match>().Select(m => m.Value).ToList<string>().ForEach(m => newFindNumberSecond += (m + " "));
Console.WriteLine("示例二:" + newFindNumberSecond);
运行结果如下:

?=exp)也叫零宽度正预测先行断言,它断言自身出现的位置的后面能匹配表达式exp。
(?<=exp)也叫零宽度正回顾后发断言,它断言自身出现的位置的前面能匹配表达式exp。
4. 负向零宽断言
实在无语了,零宽断言刚理解完,又来了一个负向零宽断言,真是非常的坑爹。
解释这个概念已经非常无力了,除非你不是地球人。但这个东东本身并不难使用,我们直接解决一个问题。
//负向零宽断言
//示例:查找单词中包含x并且x前面不是o的所有单词
string strThird = "hot example how box house ox xerox his fox six my";
string regexStrThird = @"\b\w*[^o]x\w*\b";
string newStrThird = String.Empty;
Regex.Matches(strThird, regexStrThird).Cast<Match>().Select(m => m.Value).ToList<string>().ForEach(m => newStrThird += (m + " "));
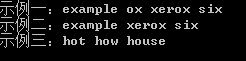
Console.WriteLine("示例一:" + newStrThird);
//我们发现以上写法,如果以x开头的单词,就会出错,原因是[^o]必须要匹配一个非o的字符
//为了解决以上问题,我们需要使用负向零宽断言 (?<!o])负向零宽断言能解决这样的问题,因为它只匹配一个位置,并不消费任何字符
//改进以后如下
string regexStrThird2 = @"\b\w*(?<!o)x\w*\b";
string newStrThird2 = String.Empty;
Regex.Matches(strThird, regexStrThird2).Cast<Match>().Select(m => m.Value).ToList<string>().ForEach(m => newStrThird2 += (m + " "));
Console.WriteLine("示例二:" + newStrThird2); //示例三:如查询上面示例,但是要求区配必须含o但 后面不能有x 则要使用 (?!x)
string regexStrThird3 = @"\b\w*o(?!x)\w*\b";
string newStrThird3 = String.Empty;
Regex.Matches(strThird, regexStrThird3).Cast<Match>().Select(m => m.Value).ToList<string>().ForEach(m => newStrThird3 += (m + " "));
Console.WriteLine("示例三:" + newStrThird3);
运行结果如下:
再举一个示例:
//实例一:取到<div name='Fist'></div>以内的内容 使用零宽断言 正负断言就可以解决了
//以下为模拟一个HTML表格数据
StringBuilder strHeroes =new StringBuilder();
strHeroes.Append("<table>");
strHeroes.Append("<tr><td>武林高手</td></tr>");
strHeroes.Append("<tr><td>");
strHeroes.Append("<div name='Fist'>");
strHeroes.Append("<div>欧阳锋</div>");
strHeroes.Append("<div>白驼山</div>");
strHeroes.Append("<div>蛤蟆功</div>");
strHeroes.Append("</div>"); strHeroes.Append("<div>");
strHeroes.Append("<div>黄药师</div>");
strHeroes.Append("<div>桃花岛</div>");
strHeroes.Append("<div>弹指神通</div>");
strHeroes.Append("</div>"); strHeroes.Append("</td></tr>");
strHeroes.Append("</table>"); Console.WriteLine("原字符串:"+strHeroes.ToString()); string newTr = String.Empty;
string regexTr = @"(?<=<div name='Fist'>).+(?=</div>)";
Regex.Matches(strHeroes.ToString(),regexTr).Cast<Match>().Select(m => m.Value).ToList<string>().ForEach(m => newTr += (m + "\n"));
Console.WriteLine(Regex.IsMatch(strHeroes.ToString(), regexTr));
Console.WriteLine("实例一:"+newTr);
运行结果如下:

5. 注释
正则表达式很长的时候,很难读懂,因些他有专门的注释方法,主要有两种写法
A.通过语法(?#comment)
例如:\b\w*o(?!x)(?#o后面不包含x)\w*\b 红色部分是注释,他不对表达式产生任何影响
B.启用“忽略模式里的空白符”选项的多行注释法
例如:
//正则表达式注释
//重写上面的例子,采用多行注释法
string regexStrThird4 = @"\b #限定单词开头
\w* #任意长度字母数字及下划线
o(?!x) #含o字母并且后面的一个字母不是x
\w* #任意长度字母数字及下划线
\b #限定单词结尾
";
string newStrThird4 = String.Empty;
Regex.Matches(strThird, regexStrThird4,RegexOptions.IgnorePatternWhitespace).Cast<Match>().Select(m => m.Value).ToList<string>().ForEach(m => newStrThird4 += (m + " "));
Console.WriteLine("示例四:" + newStrThird4);
运行结果同上。
6. 注释贪婪与懒惰
这个比较好理解,首先,懒惰是针对重复匹配模式来说的,我们先看一下下面的表 懒惰的限定符如下:
|
懒惰限定符 |
|
|
代码/语法 |
说明 |
|
*? |
重复任意次,但尽可能少重复 |
|
+? |
重复1次或更多次,但尽可能少重复 |
|
?? |
重复0次或1次,但尽可能少重复 |
|
{n,m}? |
重复n到m次,但尽可能少重复 |
|
{n,}? |
重复n次以上,但尽可能少重复 |
通过示例来看
//懒惰限定符
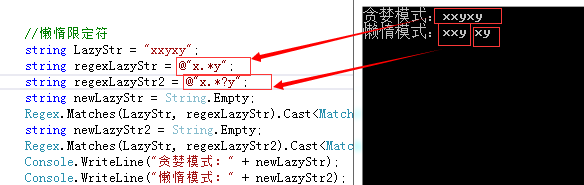
string LazyStr = "xxyxy";
string regexLazyStr = @"x.*y";
string regexLazyStr2 = @"x.*?y";
string newLazyStr = String.Empty;
Regex.Matches(LazyStr, regexLazyStr).Cast<Match>().Select(m => m.Value).ToList<string>().ForEach(m => newLazyStr += (m + " "));
string newLazyStr2 = String.Empty;
Regex.Matches(LazyStr, regexLazyStr2).Cast<Match>().Select(m => m.Value).ToList<string>().ForEach(m => newLazyStr2 += (m + " "));
Console.WriteLine("贪婪模式:" + newLazyStr);
Console.WriteLine("懒惰模式:" + newLazyStr2);
运行结果如下:
我们可以看出:
懒惰匹配,也就是匹配尽可能少的字符。
相反,贪婪模式则尽可能多的匹配字符
贪婪模式都可以被转化为懒惰匹配模式,只要在它后面加上一个问号?
7.处理与选项
|
常用的处理选项 |
|
|
名称 |
说明 |
|
IgnoreCase(忽略大小写) |
匹配时不区分大小写。 |
|
Multiline(多行模式) |
更改^和$的含义,使它们分别在任意一行的行首和行尾匹配,而不仅仅在整个字符串的开头和结尾匹配。(在此模式下,$的精确含意是:匹配\n之前的位置以及字符串结束前的位置.) |
|
Singleline(单行模式) |
更改.的含义,使它与每一个字符匹配(包括换行符\n)。 |
|
IgnorePatternWhitespace(忽略空白) |
忽略表达式中的非转义空白并启用由#标记的注释。 |
|
ExplicitCapture(显式捕获) |
仅捕获已被显式命名的组。 |
这个我们在前面已经很多次用到了,比如 注释的示例。
在.NET 正则表达式中,我们使用RegexOptions 枚举来完成。
上一节在说到.NET常用正规表达式方法时简单作了说明,下面我们把.NET RegexOptions 枚举的各个值列举说明一下
提供用于设置正则表达式选项的枚举值。此枚举有一个 FlagsAttribute 属性,允许其成员值按位组合
Compiled:指定将正则表达式编译为程序集。这会产生更快的执行速度,但会增加启动时间。
CultureInvariant:指定忽略语言中的区域性差异。有关更多信息,请参见 在 RegularExpressions 命名空间中执行不区分区域性的操作。
ECMAScript:为表达式启用符合 ECMAScript 的行为。该值只能与 IgnoreCase、Multiline 和 Compiled 值一起使用。该值与其他任何值一起使用均将导致异常。
ExplicitCapture:指定有效的捕获仅为形式为 (?<name>...) 的显式命名或编号的组。这使未命名的圆括号可以充当非捕获组,并且不会使表达式的语法 (?:...) 显得笨拙。
IgnoreCase:指定不区分大小写的匹配。
IgnorePatternWhitespace:消除模式中的非转义空白并启用由 # 标记的注释。但是,IgnorePatternWhitespace 值不会影响或消除字符类中的空白。
Multiline:多行模式。更改 ^ 和 $ 的含义,使它们分别在任意一行的行首和行尾匹配,而不仅仅在整个字符串的开头和结尾匹配。
None:指定不设置选项。
RightToLeft:指定搜索从右向左而不是从左向右进行。
Singleline:指定单行模式。更改点 (.) 的含义,使它与每一个字符匹配(而不是与除 /n 之外的每个字符匹配)。
示例:
//处理选项
//Compiled表示编译为程序集,使效率提高
//IgnoreCase表示匹配不分大小写
Regex rx = new Regex(@"\b(?<word>\w+)\s+(\k<word>)\b",RegexOptions.Compiled | RegexOptions.IgnoreCase);
string myWords = "hello hello How Hi hi are you you apple o o ";
string newMyWords = String.Empty;
rx.Matches(myWords).Cast<Match>().Select(m => m.Value).ToList<string>().ForEach(m => newMyWords += (m + ","));
Console.WriteLine("相同的单词有:" + newMyWords.Trim(','));
运行结果如下:

8. 判断表达式
这里需要用到以下的语法构造:
- (?'group') 把捕获的内容命名为group,并压入堆栈(Stack)
- (?'-group') 从堆栈上弹出最后压入堆栈的名为group的捕获内容,如果堆栈本来为空,则本分组的匹配失败
- (?(group)yes|no) 如果堆栈上存在以名为group的捕获内容的话,继续匹配yes部分的表达式,否则继续匹配no部分
- (?!) 零宽负向先行断言,由于没有后缀表达式,试图匹配总是失败
可以看到,实际上就是一个除|择一之后的,另一种判断表达,这里算是个总结 ,下面几种写法带有判断性质语法:
(1)、A|B,这个是最基本的,A或者B,其实这个不能算判断
(2)、(?(expression)yes-expression|no-expression),其中no-expression为可选项,意为,如果expression成立,则要求匹配yes-expression,否则要求匹配no-expression
(3)、(?(group-name)yes-expressioin|no-expression),其中no-expression为可选项,意为,如果名为group-name的组匹配成功,则要求匹配yes-expression,否则要求匹配no-expression
判断表达式还是很好理解的,唯有一点要注意:@"(?(A)A|B)"不能匹配"AA",我们应该这样写Regex: @”(?(A)AA|B)”,请注意,判断式中的内容并不会做为yes-expression或no-expression表达式的一部分。
(?'group') 和(?'group') 通常用作平衡组匹配,比如我们匹配html等对称标签时,对于不对称的标签,则匹配失败
本节所有源代码贴上来
//示例:重复单字符 和 重复分组字符
//重复 单个字符
Console.WriteLine("请输入一个任意字符串,测试分组:");
string inputStr = Console.ReadLine();
string strGroup1 = @"a{2}";
Console.WriteLine("单字符重复2两次替换为22,结果为:"+Regex.Replace(inputStr, strGroup1,""));
//重复 多个字符 使用(abcd){n}进行分组限定
string strGroup2 = @"(ab\w{2}){2}";
Console.WriteLine("分组字符重复2两次替换为5555,结果为:" + Regex.Replace(inputStr, strGroup2, "")); Console.WriteLine("\n"); //示例:校验IP4地址(如:192.168.1.4,为四段,每段最多三位,每段最大数字为255,并且第一位不能为0)
string regexStrIp4 = @"^(((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?))$";
Console.WriteLine("请输入一个IP4地址:");
string inputStrIp4 = Console.ReadLine();
Console.WriteLine(inputStrIp4 + " 是否为合法的IP4地址:" + Regex.IsMatch(inputStrIp4, regexStrIp4));
Console.WriteLine("请输入一个IP4地址:");
string inputStrIp4Second = Console.ReadLine();
Console.WriteLine(inputStrIp4 + " 是否为合法的IP4地址:" + Regex.IsMatch(inputStrIp4Second, regexStrIp4)); //后向引用 //在后向引用前,我们先熟悉一下单词的查找
//复习一下前面学的几个元字符
// * 匹配前面的子表达式任意次。例如,zo* 能匹配“z”,“zo”以及“zoo”。*等价于{ 0,}。
// + 匹配前面的子表达式一次或多次(大于等于1次)。例如,“zo +”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{ 1,}。
// ? 匹配前面的子表达式零次或一次。例如,“do (es) ?”可以匹配“do”或“does”中的“do”。?等价于{ 0,1}。
// \w 匹配包括下划线的任何单词字符。类似但不等价于“[A-Za-z0-9_]”,这里的"单词"字符使用Unicode字符集。
// \b 匹配一个单词边界,也就是指单词和空格间的位置(即正则表达式的“匹配”有两种概念,一种是匹配字符,一种是匹配位置,这里的\b就是匹配位置的)。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”。
// \s 匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。
string str1 = "zoo zoo hello how you mess ok ok home house miss miss yellow"; //示例一:查找单词中以e结尾的,并将单词替换为了*
string regexStr1 = @"\w+e\b";
Console.WriteLine("示例一:" + Regex.Replace(str1, regexStr1,"*")); //示例二:查询单词中以h开头的,并将单词替换为#
string regexStr2 = @"\bh\w+";
Console.WriteLine("示例二:" + Regex.Replace(str1, regexStr2, "#")); //示例三:查找单词中有重叠ll的单词,将单词替换为@
string regexStr3 = @"\b\w+l+\w+\b";
Console.WriteLine("示例三:" + Regex.Replace(str1, regexStr3, "@")); //使用 \1 代表第一个分组 组号为1的匹配文本
//示例四:查询单词中有两个重复的单词,替换为%
string regexStr4 = @"(\b\w+\b)\s+\1";
Console.WriteLine("示例四:" + Regex.Replace(str1, regexStr4, "%"));
//上面示例中,第一个分组匹配任意一个单词 \s+ 表示任意空字符 \1 表示匹配和第一个分组相同 //使用别名 代替 组号 ,别名定义 (?<name>exp) ,别名后向引用 \w<name>
//示例五:使用别名后向引用 查询 查询单词中有两个重复的单词,替换为%%
string regexStr5 = @"(?<myRegWord>\b\w+\b)\s+\k<myRegWord>";
Console.WriteLine("示例五:"+Regex.Replace(str1, regexStr5, "%%")); //零宽断言
//示例一:将下面字符串每三位使用逗号分开
string stringFist = "dfalrewqrqwerl43242342342243434abccc";
string regexStringFist = @"((?=\w)\w{3})";
string newStrFist = String.Empty;
Regex.Matches(stringFist, regexStringFist).Cast<Match>().Select(m=>m.Value).ToList<string>().ForEach(m => newStrFist += (m+","));
Console.WriteLine("示例一:" + newStrFist.TrimEnd(',')); //示例二:查询字符串中,两个空格之间的所有数字
string FindNumberSecond = "asdfas 3 dfasfas3434324 9 8888888 7 dsafasd342";
string regexFindNumberSecond = @"((?<=\s)\d(?=\s))";
string newFindNumberSecond = String.Empty;
Regex.Matches(FindNumberSecond, regexFindNumberSecond).Cast<Match>().Select(m => m.Value).ToList<string>().ForEach(m => newFindNumberSecond += (m + " "));
Console.WriteLine("示例二:" + newFindNumberSecond); //负向零宽断言
//示例:查找单词中包含x并且x前面不是o的所有单词
string strThird = "hot example how box house ox xerox his fox six my";
string regexStrThird = @"\b\w*[^o]x\w*\b";
string newStrThird = String.Empty;
Regex.Matches(strThird, regexStrThird).Cast<Match>().Select(m => m.Value).ToList<string>().ForEach(m => newStrThird += (m + " "));
Console.WriteLine("示例一:" + newStrThird);
//我们发现以上写法,如果以x开头的单词,就会出错,原因是[^o]必须要匹配一个非o的字符
//为了解决以上问题,我们需要使用负向零宽断言 (?<!o])负向零宽断言能解决这样的问题,因为它只匹配一个位置,并不消费任何字符
//改进以后如下
string regexStrThird2 = @"\b\w*(?<!o)x\w*\b";
string newStrThird2 = String.Empty;
Regex.Matches(strThird, regexStrThird2).Cast<Match>().Select(m => m.Value).ToList<string>().ForEach(m => newStrThird2 += (m + " "));
Console.WriteLine("示例二:" + newStrThird2); //示例三:如查询上面示例,但是要求区配必须含o但 后面不能有x 则要使用 (?!x)
string regexStrThird3 = @"\b\w*o(?!x)\w*\b";
string newStrThird3 = String.Empty;
Regex.Matches(strThird, regexStrThird3).Cast<Match>().Select(m => m.Value).ToList<string>().ForEach(m => newStrThird3 += (m + " "));
Console.WriteLine("示例三:" + newStrThird3); //正则表达式注释
//重写上面的例子,采用多行注释法
string regexStrThird4 = @" \b #限定单词开头
\w* #任意长度字母数字及下划线
o(?!x) #含o字母并且后面的一个字母不是x
\w* #任意长度字母数字及下划线
\b #限定单词结尾
";
string newStrThird4 = String.Empty;
Regex.Matches(strThird, regexStrThird4,RegexOptions.IgnorePatternWhitespace).Cast<Match>().Select(m => m.Value).ToList<string>().ForEach(m => newStrThird4 += (m + " "));
Console.WriteLine("示例四:" + newStrThird4); //懒惰限定符
string LazyStr = "xxyxy";
string regexLazyStr = @"x.*y";
string regexLazyStr2 = @"x.*?y";
string newLazyStr = String.Empty;
Regex.Matches(LazyStr, regexLazyStr).Cast<Match>().Select(m => m.Value).ToList<string>().ForEach(m => newLazyStr += (m + " "));
string newLazyStr2 = String.Empty;
Regex.Matches(LazyStr, regexLazyStr2).Cast<Match>().Select(m => m.Value).ToList<string>().ForEach(m => newLazyStr2 += (m + " "));
Console.WriteLine("贪婪模式:" + newLazyStr);
Console.WriteLine("懒惰模式:" + newLazyStr2); //处理选项
//Compiled表示编译为程序集,使效率提高
//IgnoreCase表示匹配不分大小写
Regex rx = new Regex(@"\b(?<word>\w+)\s+(\k<word>)\b",RegexOptions.Compiled | RegexOptions.IgnoreCase);
string myWords = "hello hello How Hi hi are you you apple o o ";
string newMyWords = String.Empty;
rx.Matches(myWords).Cast<Match>().Select(m => m.Value).ToList<string>().ForEach(m => newMyWords += (m + ","));
Console.WriteLine("相同的单词有:" + newMyWords.Trim(',')); //实例一:取到<div name='Fist'></div>以内的内容 使用零宽断言 正负断言就可以解决了
//以下为模拟一个HTML表格数据
StringBuilder strHeroes =new StringBuilder();
strHeroes.Append("<table>");
strHeroes.Append("<tr><td>武林高手</td></tr>");
strHeroes.Append("<tr><td>");
strHeroes.Append("<div name='Fist'>");
strHeroes.Append("<div>欧阳锋</div>");
strHeroes.Append("<div>白驼山</div>");
strHeroes.Append("<div>蛤蟆功</div>");
strHeroes.Append("</div>"); strHeroes.Append("<div>");
strHeroes.Append("<div>黄药师</div>");
strHeroes.Append("<div>桃花岛</div>");
strHeroes.Append("<div>弹指神通</div>");
strHeroes.Append("</div>"); strHeroes.Append("</td></tr>");
strHeroes.Append("</table>"); Console.WriteLine("原字符串:"+strHeroes.ToString()); string newTr = String.Empty;
string regexTr = @"(?<=<div name='Fist'>).+(?=</div>)";
Regex.Matches(strHeroes.ToString(),regexTr).Cast<Match>().Select(m => m.Value).ToList<string>().ForEach(m => newTr += (m + "\n"));
Console.WriteLine(Regex.IsMatch(strHeroes.ToString(), regexTr));
Console.WriteLine("实例一:"+newTr);
==============================================================================================
<如果对你有帮助,记得点一下推荐哦,如有
有不明白或错误之处,请多交流>
<对本系列文章阅读有困难的朋友,请先看《.net 面向对象编程基础》>
<转载声明:技术需要共享精神,欢迎转载本博客中的文章,但请注明版权及URL>
.NET 技术交流群:467189533 
==============================================================================================
[.net 面向对象程序设计进阶] (3) 正则表达式 (二) 高级应用的更多相关文章
- [.net 面向对象程序设计进阶] (2) 正则表达式 (一) 快速入门
[.net 面向对象程序设计进阶] (2) 正则表达式 (一) 快速入门 1. 什么是正则表达式? 1.1 正则表达式概念 正则表达式,又称正则表示法,英文名:Regular Expression(简 ...
- [.net 面向对象程序设计进阶] (4) 正则表达式 (三) 表达式助手
[.net 面向对象程序设计进阶] (2) 正则表达式(三) 表达式助手 上面两节对正则表达式的使用及.NET下使用正则表达式作了详细说明,本节主要搜集整理了常用的正则表达式提供参考. 此外为了使用方 ...
- [.net 面向对象程序设计进阶] (1) 开篇
[.net 面向对象程序设计进阶] (1) 开篇 上一系列文章<.net 面向对象编程基础>写完后,很多小伙伴们希望我有时间再写一点进阶的文章,于是有了这个系列文章.这一系列的文章中, 对 ...
- [.net 面向对象程序设计进阶] (23) 团队开发利器(二)优秀的版本控制工具SVN(上)
[.net 面向对象程序设计进阶] (23) 团队开发利器(二)优秀的版本控制工具SVN(上) 本篇导读: 上篇介绍了常用的代码管理工具VSS,看了一下评论,很多同学深恶痛绝,有的甚至因为公司使用VS ...
- [.net 面向对象程序设计进阶] (17) 多线程(Multithreading)(二) 利用多线程提高程序性能(中)
[.net 面向对象程序设计进阶] (17) 多线程(Multithreading)(二) 利用多线程提高程序性能(中) 本节要点: 上节介绍了多线程的基本使用方法和基本应用示例,本节深入介绍.NET ...
- [.net 面向对象程序设计进阶] (15) 缓存(Cache)(二) 利用缓存提升程序性能
[.net 面向对象程序设计进阶] (15) 缓存(Cache)(二) 利用缓存提升程序性能 本节导读: 上节说了缓存是以空间来换取时间的技术,介绍了客户端缓存和两种常用服务器缓布,本节主要介绍一种. ...
- [.net 面向对象程序设计进阶] (6) Lamda表达式(二) 表达式树快速入门
[.net 面向对象程序设计进阶] (6) Lamda表达式(二) 表达式树快速入门 本节导读: 认识表达式树(Expression Tree),学习使用Lambda创建表达式树,解析表达式树. 学习 ...
- [.net 面向对象程序设计进阶] (7) Lamda表达式(三) 表达式树高级应用
[.net 面向对象程序设计进阶] (7) Lamda表达式(三) 表达式树高级应用 本节导读:讨论了表达式树的定义和解析之后,我们知道了表达式树就是并非可执行代码,而是将表达式对象化后的数据结构.是 ...
- 【 .NET 面向对象程序设计进阶》】【 《.NET 面向对象编程基础》】【《正则表达式助手》】
<.NET 面向对象程序设计进阶> <.NET 面向对象程序设计进阶> <正则表达式助手>
随机推荐
- ADV数字的剪切
#include <iostream> using namespace std; #define SIZE 9 #define MAXLEN 6 int data[SIZE][MAXLEN ...
- Linq To Nhibernate 性能优化(入门级)
最近都是在用Nhibernate和数据库打交道,说实话的,我觉得Nhibernate比Ado.Net更好用,但是在对于一些复杂的查询Nhibernate还是比不上Ado.Net.废话不多说了,下面讲讲 ...
- ios页面弹出方式《笔记》
1.presentViewController 方式,动画效果是从底部弹出,主要用在除导航类页面的弹出 let anotherVC = UIStoryboard(name: "Main&qu ...
- .Net多文件同时上传(Jquery Uploadify)
前提:领导给了我一个文件夹,里面有4000千多张产品图片,每张图片已产品编号+产品名称命名,要求是让我把4000多张产品图片上传到服务器端,而且要以产品编码创建n个文件夹,每张图片放到对应的文件夹下. ...
- UIAlertController、UIAlertAction 警告框
NS_CLASS_AVAILABLE_IOS(8_0) @interface UIAlertAction : NSObject <NSCopying> //创建操作 + (instan ...
- 什么是F#
作者:Alexey Bykov@EastBancTech原文:http://bit.ly/1nGroOz翻译:kk1982.com转载请注明 简介 F#是由微软研究团队为.NET平台研发的一种现代函数 ...
- 数位DP
题意:(hdu 4734) 我们定义十进制数x的权值为f(x) = a(n)*2^(n-1)+a(n-1)*2(n-2)+...a(2)*2+a(1)*1,a(i)表示十进制数x中第i位的数字. 题目 ...
- n+1 < n , are you sure?
密码终于找回了,原来是我邮箱把改密链接的邮件当垃圾邮件了-- 回到正题,这是道面试题,原话大致是这样的: n+1<n成立吗?请说明. 当时我听到这个题后直觉是成立的,但是想不到怎么回事,后来别人 ...
- 机器学习利器——Scikit-learn的安装
由于笔者最近在进行毕业论文的准备,且毕业论文中需要用到Python版本的机器学习库——scikit-learn.所以最近三天一直在Windows上部署这个框架,终于部署成功了... 首先打开加州大学底 ...
- Sprint评审会议不是Sprint演示会议
最近,Innolution公司的执行总监.Essential Scrum的作者Ken Rubin在其公司博客上撰写了一篇题为It’s a Sprint Review Not a Sprint Demo ...