Python多线程爬虫爬取电影天堂资源
最近花些时间学习了一下Python,并写了一个多线程的爬虫程序来获取电影天堂上资源的迅雷下载地址,代码已经上传到GitHub上了,需要的同学可以自行下载。刚开始学习python希望可以获得宝贵的意见。
先来简单介绍一下,网络爬虫的基本实现原理吧。一个爬虫首先要给它一个起点,所以需要精心选取一些URL作为起点,然后我们的爬虫从这些起点出发,抓取并解析所抓取到的页面,将所需要的信息提取出来,同时获得的新的URL插入到队列中作为下一次爬取的起点。这样不断地循环,一直到获得你想得到的所有的信息爬虫的任务就算结束了。我们通过一张图片来看一下。
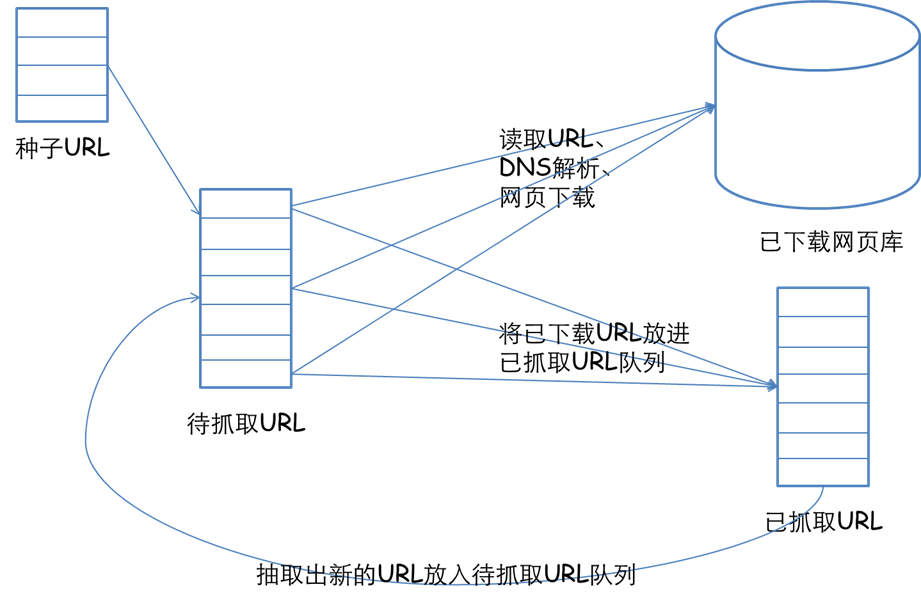
好的 下面进入正题,来讲解下程序的实现。
首先要分析一下电影天堂网站的首页结构。

从上面的菜单栏中我们可以看到整个网站资源的总体分类情况。刚刚好我们可以利用到它的这个分类,将每一个分类地址作为爬虫的起点。
①解析首页地址 提取分类信息
#解析首页
def CrawIndexPage(starturl):
print "正在爬取首页"
page = __getpage(starturl)
if page=="error":
return
page = page.decode('gbk', 'ignore')
tree = etree.HTML(page)
Nodes = tree.xpath("//div[@id='menu']//a")
print "首页解析出地址",len(Nodes),"条"
for node in Nodes:
CrawledURLs = []
CrawledURLs.append(starturl)
url=node.xpath("@href")[0]
if re.match(r'/html/[A-Za-z0-9_/]+/index.html', url):
if __isexit(host + url,CrawledURLs):
pass
else:
try:
catalog = node.xpath("text()")[0].encode("utf-8")
newdir = "E:/电影资源/" + catalog
os.makedirs(newdir.decode("utf-8"))
print "创建分类目录成功------"+newdir
thread = myThread(host + url, newdir,CrawledURLs)
thread.start()
except:
pass
在这个函数中,首先将网页的源码下载下来,通过XPath解析出其中的菜单分类信息。并创建相应的文件目录。有一个需要注意的地方就是编码问题,但是也是被这个编码纠缠了好久,通过查看网页的源代码,我们可以发现,网页的编码采用的是GB2312,这里通过XPath构造Tree对象是需要对文本信息进行解码操作,将gb2312变成Unicode编码,这样DOM树结构才是正确的,要不然在后面解析的时候就会出现问题。
②解析每个分类的主页
# 解析分类文件
def CrawListPage(indexurl,filedir,CrawledURLs):
print "正在解析分类主页资源"
print indexurl
page = __getpage(indexurl)
if page=="error":
return
CrawledURLs.append(indexurl)
page = page.decode('gbk', 'ignore')
tree = etree.HTML(page)
Nodes = tree.xpath("//div[@class='co_content8']//a")
for node in Nodes:
url=node.xpath("@href")[0]
if re.match(r'/', url):
# 非分页地址 可以从中解析出视频资源地址
if __isexit(host + url,CrawledURLs):
pass
else:
#文件命名是不能出现以下特殊符号
filename=node.xpath("text()")[0].encode("utf-8").replace("/"," ")\
.replace("\\"," ")\
.replace(":"," ")\
.replace("*"," ")\
.replace("?"," ")\
.replace("\""," ")\
.replace("<", " ") \
.replace(">", " ")\
.replace("|", " ")
CrawlSourcePage(host + url,filedir,filename,CrawledURLs)
pass
else:
# 分页地址 从中嵌套再次解析
print "分页地址 从中嵌套再次解析",url
index = indexurl.rfind("/")
baseurl = indexurl[0:index + 1]
pageurl = baseurl + url
if __isexit(pageurl,CrawledURLs):
pass
else:
print "分页地址 从中嵌套再次解析", pageurl
CrawListPage(pageurl,filedir,CrawledURLs)
pass
pass
打开每一个分类的首页会发现都有一个相同的结构(点击打开示例)首先解析出包含资源URL的节点,然后将名称和URL提取出来。这一部分有两个需要注意的地方。一是因为最终想要把资源保存到一个txt文件中,但是在命名时不能出现一些特殊符号,所以需要处理掉。二是一定要对分页进行处理,网站中的数据都是通过分页这种形式展示的,所以如何识别并抓取分页也是很重要的。通过观察发现,分页的地址前面没有“/”,所以只需要通过正则表达式找出分页地址链接,然后嵌套调用即可解决分页问题。
③解析资源地址保存到文件中
#处理资源页面 爬取资源地址
def CrawlSourcePage(url,filedir,filename,CrawledURLs):
print url
page = __getpage(url)
if page=="error":
return
CrawledURLs.append(url)
page = page.decode('gbk', 'ignore')
tree = etree.HTML(page)
Nodes = tree.xpath("//div[@align='left']//table//a")
try:
source = filedir + "/" + filename + ".txt"
f = open(source.decode("utf-8"), 'w')
for node in Nodes:
sourceurl = node.xpath("text()")[0]
f.write(sourceurl.encode("utf-8")+"\n")
f.close()
except:
print "!!!!!!!!!!!!!!!!!"
这段就比较简单了,将提取出来的内容写到一个文件中就行了
为了能够提高程序的运行效率,使用了多线程进行抓取,在这里我是为每一个分类的主页都开辟了一个线程,这样极大地加快了爬虫的效率。想当初,只是用单线程去跑,结果等了一下午最后因为一个异常没处理到结果一下午都白跑了!!!!心累
class myThread (threading.Thread): #继承父类threading.Thread
def __init__(self, url, newdir,CrawledURLs):
threading.Thread.__init__(self)
self.url = url
self.newdir = newdir
self.CrawledURLs=CrawledURLs
def run(self): #把要执行的代码写到run函数里面 线程在创建后会直接运行run函数
CrawListPage(self.url, self.newdir,self.CrawledURLs)
以上只是部分代码,全部代码可以到GitHub上面去下载(点我跳转)
最后爬取的结果如下。
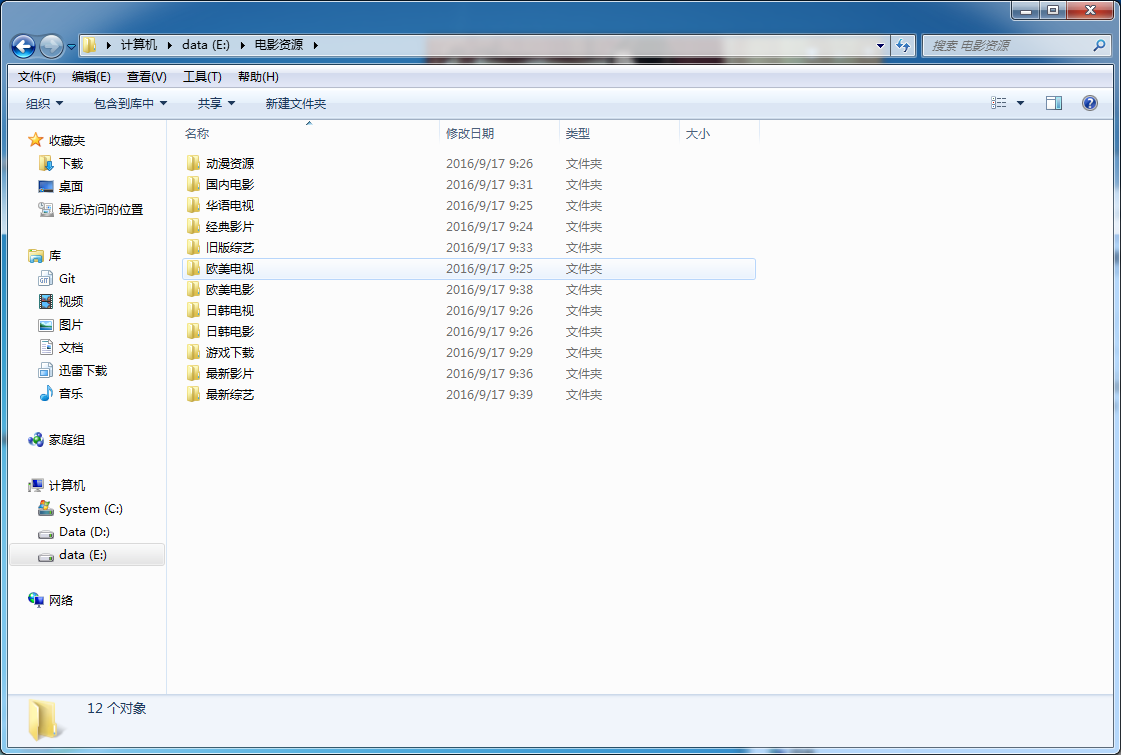
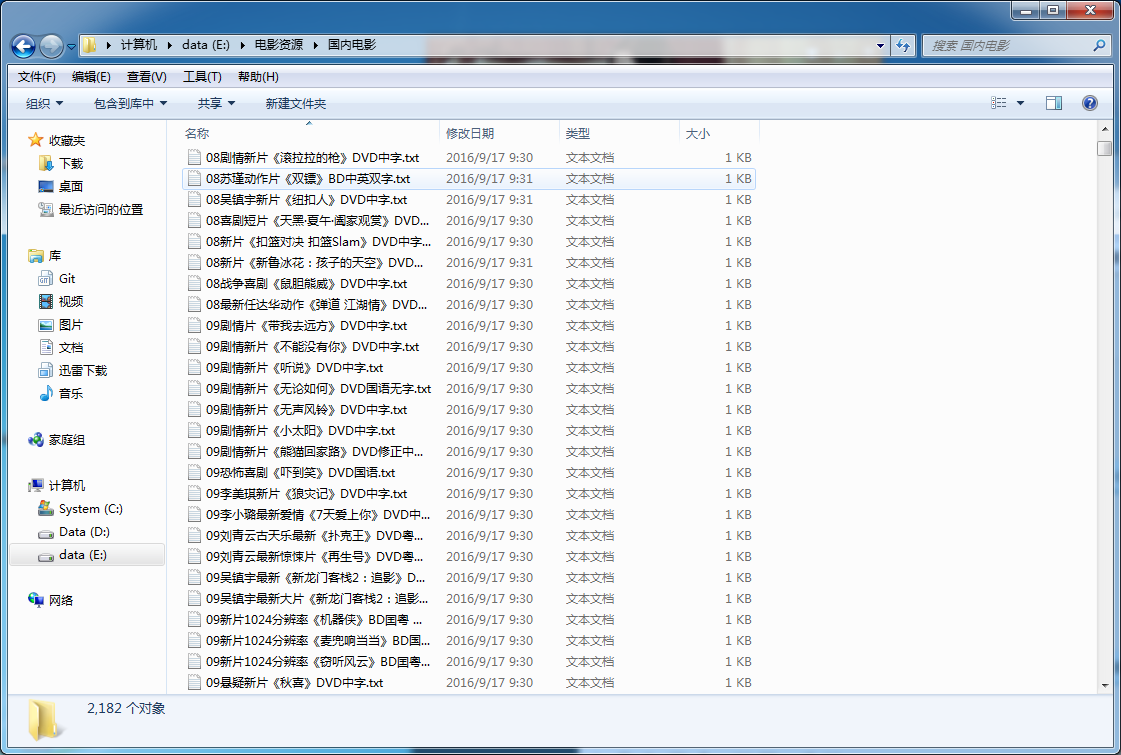
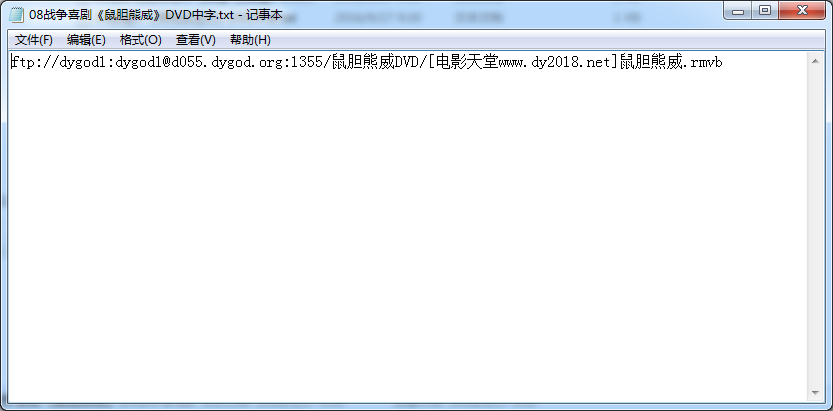
Python多线程爬虫爬取电影天堂资源的更多相关文章
- 14.python案例:爬取电影天堂中所有电视剧信息
1.python案例:爬取电影天堂中所有电视剧信息 #!/usr/bin/env python3 # -*- coding: UTF-8 -*- '''======================== ...
- Python多线程爬虫爬取网页图片
临近期末考试,但是根本不想复习!啊啊啊啊啊啊啊!!!! 于是做了一个爬虫,网址为 https://yande.re,网页图片为动漫美图(图片带点颜色........宅男福利 github项目地址为:h ...
- python3----练习题(爬取电影天堂资源,大学排名,淘宝商品比价)
import requests import re url = 'http://www.ygdy8.net/html/gndy/dyzz/list_23_{}.html' for n in range ...
- python利用requests和threading模块,实现多线程爬取电影天堂最新电影信息。
利用爬到的数据,基于Django搭建的一个最新电影信息网站: n1celll.xyz (用的花生壳动态域名解析,服务器在自己的电脑上,纯属自娱自乐哈.) 今天想利用所学知识来爬取电影天堂所有最新电影 ...
- Python爬取电影天堂指定电视剧或者电影
1.分析搜索请求 一位高人曾经说过,想爬取数据,要先分析网站 今天我们爬取电影天堂,有好看的美剧我在上面都能找到,算是很全了. 这个网站的广告出奇的多,用过都知道,点一下搜索就会弹出个窗口,伴随着滑稽 ...
- scrapy框架用CrawlSpider类爬取电影天堂.
本文使用CrawlSpider方法爬取电影天堂网站内国内电影分类下的所有电影的名称和下载地址 CrawlSpider其实就是Spider的一个子类. CrawlSpider功能更加强大(链接提取器,规 ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- Node.js 爬虫爬取电影信息
Node.js 爬虫爬取电影信息 我的CSDN地址:https://blog.csdn.net/weixin_45580251/article/details/107669713 爬取的是1905电影 ...
随机推荐
- Unity3d学习 相机的跟随
最近在写关于相机跟随的逻辑,其实最早接触相机跟随是在Unity官网的一个叫Roll-a-ball tutorial上,其中简单的涉及了关于相机如何跟随物体的移动而移动,如下代码: using Unit ...
- 【.net 深呼吸】设置序列化中的最大数据量
欢迎收看本期的<老周吹牛>节目,由于剧组严重缺钱,故本节目无视频无声音.好,先看下面一个类声明. [DataContract] public class DemoObject { [Dat ...
- 多线程爬坑之路-学习多线程需要来了解哪些东西?(concurrent并发包的数据结构和线程池,Locks锁,Atomic原子类)
前言:刚学习了一段机器学习,最近需要重构一个java项目,又赶过来看java.大多是线程代码,没办法,那时候总觉得多线程是个很难的部分很少用到,所以一直没下决定去啃,那些年留下的坑,总是得自己跳进去填 ...
- [Spring]IoC容器之进击的注解
先啰嗦两句: 第一次在博客园使用markdown编辑,感觉渲染样式差强人意,还是github的样式比较顺眼. 概述 Spring2.5 引入了注解. 于是,一个问题产生了:使用注解方式注入 JavaB ...
- ajax异步请求
做前端开发的朋友对于ajax异步更新一定印象深刻,作为刚入坑的小白,今天就和大家一起聊聊关于ajax异步请求的那点事.既然是ajax就少不了jQuery的知识,推荐大家访问www.w3school.c ...
- PowerDesigner-VBSrcipt-自动设置主键,外键名等(SQL Server)
在PowerDesigner中的设计SQL Server 数据表时,要求通过vbScript脚本实现下面的功能: 主键:pk_TableName 外键:fk_TableName_ForeignKeyC ...
- ASP.NET SignaiR 实现消息的即时推送,并使用Push.js实现通知
一.使用背景 1. SignalR是什么? ASP.NET SignalR 是为 ASP.NET 开发人员提供的一个库,可以简化开发人员将实时 Web 功能添加到应用程序的过程.实时 Web 功能是指 ...
- BlockingCollection使用
BlockingCollection是一个线程安全的生产者-消费者集合. 代码 public class BlockingTest { BlockingCollection<int> bc ...
- TemplateMethod(模块方法模式)
/** * 模块模式 * @author TMAC-J * 将一个完整的算法分离,分成不同的模块 * 用于有很多步骤的时候,可能以后这些步骤还会增加,把这些步骤分离 * 将有共性的部分放在抽象类中 * ...
- FineReport如何用JDBC连接阿里云ADS数据库
在使用FineReport连接阿里云的ADS(AnalyticDB)数据库,很多时候在测试连接时就失败了.此时,该如何连接ADS数据库呢? 我们只需要手动将连接ads数据库需要使用到的jar放置到%F ...