充分利用CPU高速缓存,提高程序效率(原理篇)
提高程序效率应该充分利用CPU的高速缓存。要想编写出对CPU缓存友好的程序就得先明白CPU高速缓存的运行机制。
i5-2400S:
1、有三级缓存分别为 32k(数据、指令缓存分开,分为32k),256K,6144K(四个CPU之间共享);
2、主频为2.5G,则一个时钟周期为1/2.5x10^9=0.4ns(主频=1/时钟周期)。
CPI:
CPU中每条指令执行所需的机器周期不同CPI:平均每条指令的平均时钟周期个数,注:一个机器周期等于若干个时钟周期,如一个机器周期等于5个时钟周期
MIPS:
MIPS = 每秒执行百万条指令数 = 1/(CPI×时钟周期)= 主频/CPI,通过 cat /proc/cpuinfo | grep bogomips 命令可以查看linux系统的mips,对于i5-2400s CPU 其mips=4988.85
从而我们可以算出平均执行一个指令所需时间 T = 1/(4988.85x10^6)=0.2ns,注意:每个CPU时钟内可并行处理多条指令。
内存体系:

核心到主存的延迟变化范围很大,大约在10-100纳秒。在100ns内,一个2.5GH的CPU可以处理多达100/T=500条指令,所以CPU使用缓存子系统避免了处理核心访问主存的时延,从而使CPU更加高效的处理指令。所以在程序设计中提供程序高速缓存的命中率对于程序性能的提高帮助很大。尤其是要着重考虑主要数据结构的设计。
Cache概述,一下转自博文:http://www.cnblogs.com/liloke/archive/2011/11/20/2255737.html
1. cache概述
cache,中译名高速缓冲存储器,其作用是为了更好的利用局部性原理,减少CPU访问主存的次数。简单地说,CPU正在访问的指令和数据,其可能会被以后多次访问到,或者是该指令和数据附近的内存区域,也可能会被多次访问。因此,第一次访问这一块区域时,将其复制到cache中,以后访问该区域的指令或者数据时,就不用再从主存中取出。
2. cache结构
假设内存容量为M,内存地址为m位:那么寻址范围为000…00~FFF…F(m位)
倘若把内存地址分为以下三个区间:
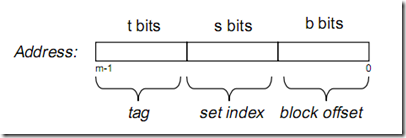 《深入理解计算机系统》p305 英文版 beta draft
《深入理解计算机系统》p305 英文版 beta draft
tag, set index, block offset三个区间有什么用呢?再来看看Cache的逻辑结构吧:
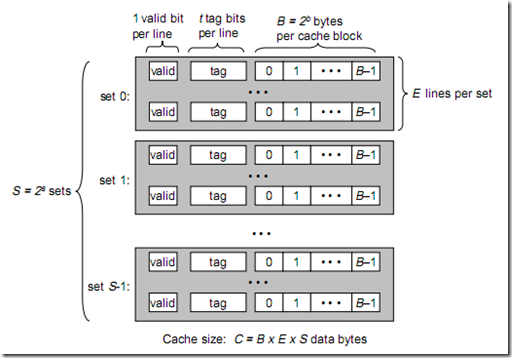
将此图与上图做对比,可以得出各参数如下:
B = 2^b
S = 2^s
现在来解释一下各个参数的意义:
一个cache被分为S个组,每个组有E个cacheline,而一个cacheline中,有B个存储单元,现代处理器中,这个存储单元一般是以字节(通常8个位)为单位的,也是最小的寻址单元。因此,在一个内存地址中,中间的s位决定了该单元被映射到哪一组,而最低的b位决定了该单元在cacheline中的偏移量。valid通常是一位,代表该cacheline是否是有效的(当该cacheline不存在内存映射时,当然是无效的)。tag就是内存地址的高t位,因为可能会有多个内存地址映射到同一个cacheline中,所以该位是用来校验该cacheline是否是CPU要访问的内存单元。
当tag和valid校验成功是,我们称为cache命中,这时只要将cache中的单元取出,放入CPU寄存器中即可。
当tag或valid校验失败的时候,就说明要访问的内存单元(也可能是连续的一些单元,如int占4个字节,double占8个字节)并不在cache中,这时就需要去内存中取了,这就是cache不命中的情况(cache miss)。当不命中的情况发生时,系统就会从内存中取得该单元,将其装入cache中,与此同时也放入CPU寄存器中,等待下一步处理。注意,以下这一点对理解linux cache机制非常重要:
当从内存中取单元到cache中时,会一次取一个cacheline大小的内存区域到cache中,然后存进相应的cacheline中。
例如:我们要取地址 (t, s, b) 内存单元,发生了cache miss,那么系统会取 (t, s, 00…000) 到 (t, s, FF…FFF)的内存单元,将其放入相应的cacheline中。
下面看看cache的映射机制:
当E=1时, 每组只有一个cacheline。那么相隔2^(s+b)个单元的2个内存单元,会被映射到同一个cacheline中。(好好想想为什么?)
当1<E<C/B时,每组有E个cacheline,不同的地址,只要中间s位相同,那么就会被映射到同一组中,同一组中被映射到哪个cacheline中是依赖于替换算法的。
当E=C/B,此时S=1,每个内存单元都能映射到任意的cacheline。带有这样cache的处理器几乎没有,因为这种映射机制需要昂贵复杂的硬件来支持。
不管哪种映射,只要发生了cache miss,那么必定会有一个cacheline大小的内存区域,被取到cache中相应的cacheline。
现代处理器,一般将cache分为2~3级,L1, L2, L3。L1一般为CPU专有,不在多个CPU中共享。L2 cache一般是多个CPU共享的,也可能装在主板上。L1 cache还可能分为instruction cache, data cache. 这样CPU能同时取指令和数据。
下面来看看现实中cache的参数,以Intel Pentium处理器为例:
| E | B | S | C | |
| L1 i-cache | 4 | 32B | 128 | 16KB |
| L1 d-cache | 4 | 32B | 128 | 16KB |
| L2 | 4 | 32B | 1024~16384 | 128KB~2MB |
3. cache miss的代价
cache可能被分为L1, L2, L3, 越往外,访问时间也就越长,但同时也就越便宜。
L1 cache命中时,访问时间为1~2个CPU周期。
L1 cache不命中,L2 cache命中,访问时间为5~10个CPU周期
当要去内存中取单元时,访问时间可能就到25~100个CPU周期了。
所以,我们总是希望cache的命中率尽可能的高。
4. False Sharing(伪共享)问题
到现在为止,我们似乎还没有提到cache如何和内存保持一致的问题。
其实在cacheline中,还有其他的标志位,其中一个用于标记cacheline是否被写过。我们称为modified位。当modified=1时,表明cacheline被CPU写过。这说明,该cacheline中的内容可能已经被CPU修改过了,这样就与内存中相应的那些存储单元不一致了。因此,如果cacheline被写过,那么我们就应该将该cacheline中的内容写回到内存中,以保持数据的一致性。
现在问题来了,我们什么时候写回到内存中呢?当然不会是每当modified位被置1就写,这样会极大降低cache的性能,因为每次都要进行内存读写操作。事实上,大多数系统都会在这样的情况下将cacheline中的内容写回到内存:
当该cacheline被置换出去时,且modified位为1。
现在大多数系统正从单处理器环境慢慢过渡到多处理器环境。一个机器中集成2个,4个,甚至是16个CPU。那么新的问题来了。
以Intel处理器为典型代表,L1级cache是CPU专有的。
先看以下例子:
系统是双核的,即为有2个CPU,CPU(例如Intel Pentium处理器)L1 cache是专有的,对于其他CPU不可见,每个cacheline有8个储存单元。
我们的程序中,有一个 char arr[8] 的数组,这个数组当然会被映射到CPU L1 cache中相同的cacheline,因为映射机制是硬件实现的,相同的内存都会被映射到同一个cacheline。
2个线程分别对这个数组进行写操作。当0号线程和1号线程分别运行于0号CPU和1号CPU时,假设运行序列如下:
开始CPU 0对arr[0]写;
随后CPU 1对arr[1]写;
随后CPU 0对arr[2]写;
……
CPU 1对arr[7]写;
根据多处理器中cache一致性的协议:
当CPU 0对arr[0]写时,8个char单元的数组被加载到CPU 0的某一个cacheline中,该cacheline的modified位已经被置1了;
当CPU 1对arr[1]写时,该数组应该也被加载到CPU 1的某个cacheline中,但是该数组在cpu0的cache中已经被改变,所以cpu0首先将cacheline中的内容写回到内存,然后再从内存中加载该数组到CPU 1中的cacheline中。CPU 1的写操作会让CPU 0对应的cacheline变为invalid状态注意,由于相同的映射机制,cpu1 中的 cacheline 和cpu0 中的cacheline在逻辑上是同一行(直接映射机制中是同一行,组相联映射中则是同一组)
当CPU 0对arr[2]写时,该cacheline是invalid状态,故CPU 1需要将cacheline中的数组数据传送给CPU 0,CPU 0在对其cacheline写时,又会将CPU 1中相应的cacheline置为invalid状态
……
如此往复,cache的性能遭到了极大的损伤!此程序在多核处理器下的性能还不如在单核处理器下的性能高。
对于伪共享问题,有2种比较好的方法:
1. 增大数组元素的间隔使得由不同线程存取的元素位于不同的cache line上。典型的空间换时间
2. 在每个线程中创建全局数组各个元素的本地拷贝,然后结束后再写回全局数组
而我们要说的linux cache机制,就与第1种方法有关。
充分利用CPU高速缓存,提高程序效率(原理篇)的更多相关文章
- 程序员如何巧用Excel提高工作效率 第二篇
之前写了一篇博客程序员如何巧用Excel提高工作效率,讲解了程序员在日常工作中如何利用Excel来提高工作效率,没想到收到很好的反馈,点赞量,评论量以及阅读量一度飙升为我的博客中Top 1,看来大家平 ...
- C与C++中的常用提高程序效率的方法
1.用a++和++a及a+=1代替a=a+1,用a--和--a及a-=1代替a=a-1 通常使用若把一个函数定义为内联函数,则在程序编译阶段,编译器就会把每次调用该函数的地方都直接替换为该函数体中的代 ...
- android图片的缓存--节约内存提高程序效率
如今android应用占内存一个比一个大,android程序的质量亟待提高. 这里简单说说网络图片的缓存,我这边就简单的说说思路 1:网络图片,无疑须要去下载图片,我们不须要每次都去下载. 维护一张表 ...
- php提高程序效率的24个小技巧
本文转自<php必须知道的300个问题>一书,在此记录方便以后查看 (1)用单引号代替双引号来包含字符串,这样做会更快些.因为php会在双引号包围的字符串中搜寻变量,单引号则不会.注意:只 ...
- 程序员提高工作效率的15个技巧【Facebook】
程序员提高工作效率的15个技巧[Facebook] 作者: habadog 日期: 2015 年 02 月 13 日发表评论 (0)查看评论 程序员提高工作效率的15个技巧[Facebook] 1,D ...
- 每个程序员都应该了解的 CPU 高速缓存
每个程序员都应该了解的 CPU 高速缓存 英文原文:Memory part 2: CPU caches 来源:oschina [编者按:这是Ulrich Drepper写“程序员都该知道存储器”的第二 ...
- NIO[读]、[写]在同一线程(单线程)中执行,让CPU使用率最大化,提高处理效率
前几天写过一篇文章,讨论重写服务后,用ab进行压力测试,发现使用NIO后没提高什么性能,只是CPU使用率提高了,内存占用降低了. 之前的NIO实现模式,主要参考(基于事件的NIO多线程服务器)http ...
- freecplus框架,Linux平台下C/C++程序员提高开发效率的利器
目录 一.freecplus框架简介 二.freecplus开源许可协议 三.freecplus框架内容 字符串操作 2.xml解析 3.日期时间 4.目录操作 5.文件操作 6.日志文件 7.参数文 ...
- Hadoop 使用Combiner提高Map/Reduce程序效率
众所周知,Hadoop框架使用Mapper将数据处理成一个<key,value>键值对,再网络节点间对其进行整理(shuffle),然后使用Reducer处理数据并进行最终输出. 在上述过 ...
随机推荐
- syscomments 可以用来查找所有关于库中用到的某个关键词的所有相关脚本
syscomments SELECT * FROM syscomments
- Path Sum 解答
Question Given a binary tree and a sum, determine if the tree has a root-to-leaf path such that addi ...
- Pattern | CLiPS
Pattern | CLiPS Pattern Pattern is a web mining module for the Python programming language. It has t ...
- No enclosing instance of type Outer is accessible. Must qualify the allocation with an enclosing instance of type Outer (e.g. x.new A() where x is an instance of Outer)
之前看内部类的时候没发现这个问题,今天写代码的时候遇到,写个最简单的例子: 下面这一段代码 红色的部分就是编译报错: No enclosing instance of type Outer is ac ...
- 异常:ERROR [org.hibernate.proxy.BasicLazyInitializer] - CGLIB Enhancement failed...
ERROR [org.hibernate.proxy.BasicLazyInitializer] - CGLIB Enhancement failed: com.movie.类 放到lib 包下 \W ...
- SVN trunk、branch、tag的用法
Subversion有一个很标准的目录结构,是这样的.比如项目是proj,svn地址为svn://proj/,那么标准的svn布局是svn://proj/|+-trunk+-branches+-tag ...
- Oracle数据库使用存储过程实现分页
注:本示例来源于韩顺平[10天玩转oracle数据库]视频教程 1.创建包同时创建游标 create or replace package pagingPackage is type paging_c ...
- LR实战之Discuz开源论坛——网页细分图结果分析(Web Page Diagnostics)
续LR实战之Discuz开源论坛项目,之前一直是创建虚拟用户脚本(Virtual User Generator)和场景(Controller),现在,终于到了LoadRunner性能测试结果分析(An ...
- 未找到具有固定名称“System.Data.SQLite”的 ADO.NET 提供程序的实体框架提供程序
用户代码未处理 System.InvalidOperationException HResult=-2146233079 Message=未找到具有固定名称"System.Data. ...
- 查看DB文件的空间使用情况
可以使用如下语句获得DB文件的空间使用 use dbName SELECT DB_NAME() AS DbName, name AS FileName, size/128.0 AS CurrentSi ...