Spark SQL使用时需要有若干“表”的存在,这些“表”可以来自于Hive,也可以来自“临时表”。如果“表”来自于Hive,它的模式(列名、列类型等)在创建时已经确定,一般情况下我们直接通过Spark SQL分析表中的数据即可;如果“表”来自“临时表”,我们就需要考虑两个问题:
(1)“临时表”的数据是哪来的?
(2)“临时表”的模式是什么?
通过Spark的官方文档可以了解到,生成一张“临时表”需要两个要素:
(1)关联着数据的RDD;
(2)数据模式;
也就是说,我们需要将数据模式应用于关联着数据的RDD,然后就可以将该RDD注册为一张“临时表”。在这个过程中,最为重要的就是数据(模式)的数据类型,它直接影响着Spark SQL计算过程以及计算结果的正确性。
目前pyspark.sql.types支持的数据类型:NullType、StringType、BinaryType、BooleanType、DateType、TimestampType、DecimalType、DoubleType、FloatType、ByteType、IntegerType、LongType、ShortType、ArrayType、MapType、StructType(StructField),其中ArrayType、MapType、StructType我们称之为“复合类型”,其余称之为“基本类型”,“复合类型”在是“基本类型”的基础上构建而来的。
这些“基本类型”与Python数据类型的对应关系如下:
| NullType |
None |
| StringType |
basestring |
| BinaryType |
bytearray |
| BooleanType |
bool |
| DateType |
datetime.date |
| TimestampType |
datetime.datetime |
| DecimalType |
decimal.Decimal |
| DoubleType |
float(double precision floats) |
| FloatType |
float(single precision floats) |
| ByteType |
int(a signed integer) |
| IntegerType |
int(a signed 32-bit integer) |
| LongType |
long(a signed 64-bit integer) |
| ShortType |
int(a signed 16-bit integer) |
下面我们分别介绍这几种数据类型在Spark SQL中的使用。
1. 数字类型(ByteType、ShortType、IntegerType、LongType、FloatType、DoubleType、DecimalType)
数字类型可分为两类,整数类型:ByteType、ShortType、IntegerType、LongType,使用时需要注意各自的整数表示范围;浮点类型:FloatType、DoubleType、DecimalType,使用时不但需要注意各自的浮点数表示范围,还需要注意各自的精度范围。
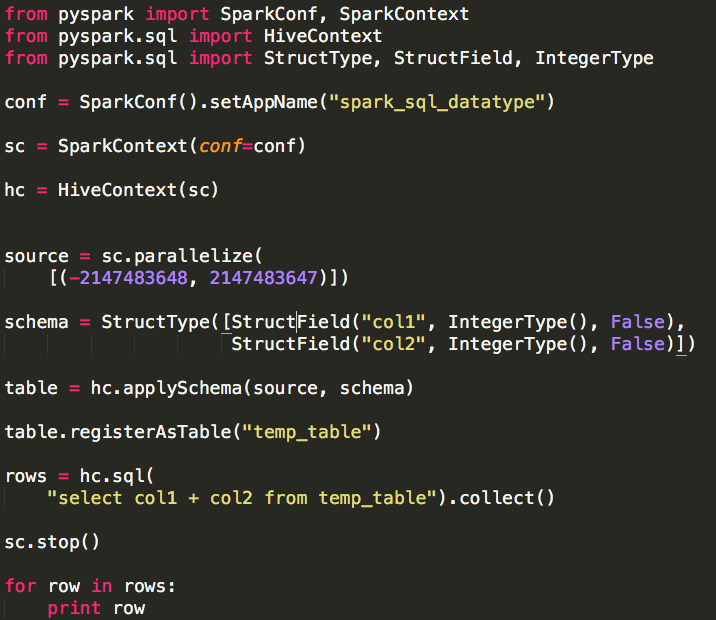
我们以常见的数据类型IntegerType来说明数字类型的使用方法:
a. 模拟“一行两列”的数据,并通过parallelize方法将其转换为一个RDD source,这个RDD就是关联着数据的RDD;
b. 创建数据模式,需要分别为这两列指定列名、列类型、可否包含空(Null)值;其中模式需要使用StructType表示,每一列的各个属性(列名称、列类型、可否包含空(Null)值)需要使用StructField表示;第一列的列名为col1,列类型为IntegerType,不可包含空(Null)值(False);第二列的列名为col2,列类型为IntegerType,不可包含空(Null)值(False);(注意:实际使用中每列的数据类型并不一定相同)
c. 通过applySchema方法将数据模式schema应用于RDD source,这会产生一个SchemaRDD(具有模式的RDD) table;
d. 将SchemaRDD table注册为一张表:temp_table;
到此我们就完成了创建RDD、创建Schema、注册Table的整个过程,接下来就可以使用这张表(temp_table)通过Spark(Hive) SQL完成分析。其它数字类型的使用方式类似。
实际上本例中“一行两列”的数据实际就是IntergerType的表示范围:[-2147483648, 2147483647],其它数字类型的表示范围如下:
| ByteType |
[-128, 127] |
| ShortType |
[-32768, 32767] |
| IntegerType |
[-2147483648, 2147483647] |
| LongType |
[-9223372036854775808, 9223372036854775807] |
| FloatType |
[1.4E-45, 3.4028235E38] |
| DoubleType |
[4.9E-324, 1.7976931348623157E308] |
可以看出,虽然我们使用Python编写程序,这些数据类型的表示范围与Java中的Byte、Short、Integer、Long、Float、Double是一致的,因为Spark是Scala实现的,而Scala运行于Java虚拟机之上,因此Spark SQL中的数据类型ByteType、ShortType、IntegerType、LongType、FloatType、DoubleType、DecimalType在运行过程中对应的数据实际上是由Java中的Byte、Short、Integer、Long、Float、Double表示的。
在使用Python编写Spark Application时需要牢记:为分析的数据选择合适的数据类型,避免因为数据溢出导致输入数据异常,但这仅仅能够解决数据输入的溢出问题,还不能解决数据在计算过程中可能出现的溢出问题。
我们将上述例子中的示例数据修改为(9223372036854775807, 9223372036854775807),数据类型修改为LongType,现在的示例数据实际是LongType所能表示的最大值,如果我们将这两例值相加,是否会出现溢出的情况呢?
输出结果:
可以看出,实际计算结果与我们预想的完全一样,这是因为col1与col2的类型为LongType,那么col1 + col2的类型也应为LongType(原因见后),然而col1 + col2的结果值18446744073709551614已经超过LongType所能表示的范围([-9223372036854775808, 9223372036854775807]),必然导致溢出。
因为我们使用的是HiveContext(SQLContext目前不被推荐使用),很多时候我们会想到使用“bigint”,
输出结果依然是:
要解释这个原因,需要了解一下Hive中数字类型各自的表示范围:
通过比对可以发现Hive BIGINT的表示范围与LongType是一致的,毕竟Hive是Java实现的,因此我们可以猜想Hive tinyint、smallint、int、bigint、float、double与Java Byte、Short、Integer、Long、Float、Double是一一对应的(仅仅是猜想,并没有实际查看源码验证),所以我们将LongType的数据类型转换为BIGINT的方式是行不通的,它们的数值范围是一样的。
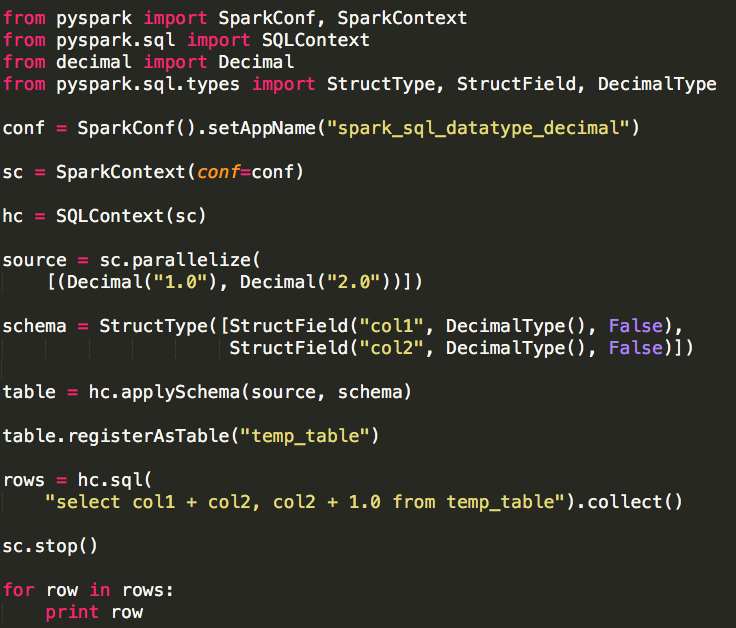
那么我们应该如何解决溢出问题呢?注意到Hive Numeric Types中的最后一个数字类型:DECIMAL,从Hive 0.11.0引入,Hive 0.13.0开始支持用户可以自定义“precision”和“scale”。Decimal基于Java BigDecimal实现,可以表示不可变的任务精度的十进制数字,支持常规的数学运算(+,-,*,/)和UDF(floor、ceil、round等),也可以与其它数字类型相互转换(cast)。使用示例如下:
使用Decimal时需要注意“precision”和“scale”值的选取,Java BigDecimal(BigInteger,后续会提到)取值范围理论上取决于(虚拟)内存的大小,可见它们是比较消耗内存资源的,因此我们需要根据我们的实际需要为它们选取合适的值,并且需要满足下述条件:
整数部分位数(precision - scale) + 小数部分位数(scale) = precision
LongType所能表示的最大位数:19,因为在我们的示例中会导致溢出问题,因此我们将数值转换为Decimal,并指定precision为38,scale为0,这样我们便可以得到正确的结果:
需要注意的是计算结果类型也变成decimal.Decimal(Python),使用Python编写Spark Application时,pyspark也提供了DecimalType,它是一种比较特殊的数据类型,它不是Python内建的数据类型,使用时需要导入模块decimal,使用方式如下:
使用数据类型DecimalType时有两个地方需要注意:
(1)创建RDD时需要使用模块decimal中的Decimal生成数据;
(2)DecimalType在Spark 1.2.0环境下使用时会出现异常:java.lang.ClassCastException: java.math.BigDecimal cannot be cast to org.apache.spark.sql.catalyst.types.decimal.Decimal,在Spark 1.5.0环境下可以正常使用,但需要将模块名称由“pyspark.sql”修改为“pyspark.sql.types”。
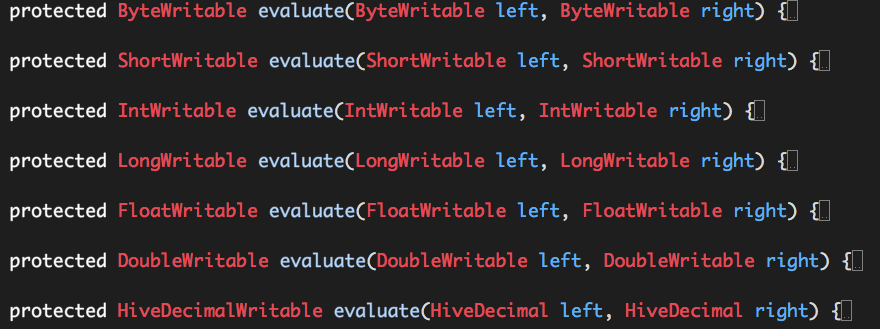
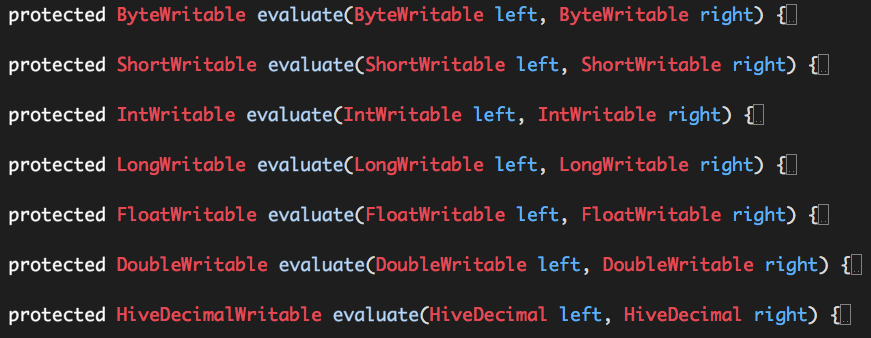
我们明确指定数据的类型是什么,那么什么决定我们常规数学运算(+,-,*,/)之后的结果类型呢?这些数学运行在Hive中实际都是由UDF实现的(org.apache.hadoop.hive.ql.exec.FunctionRegistry),
(1)+
(2)-
(3)*
(4)/
(5)%
可以看出,“+”,“-”,“*”,“%”通过重载支持的数据类型:byte、short、int、long、float、double、decimal,“/”通过重载仅仅支持数据类型:double、decimal,计算的结果类型与输入类型是相同的,这也意味着:
(1)数学运算“+”、“-”,“*”,“%”时可能会出现隐式转换(如int + long => long + long);
(2)数学运算“/”则统一将输入数据转换为数据类型double或decimal进行运算,这一点也意味着,计算结果相应地为数据类型double或decimal。
2. 时间类型(DateType,TimestampType)
DateType可以理解为年、月、日,TimestampType可以理解为年、月、日、时、分、秒,它们分别对着着Python datetime中的date,datetime,使用示例如下:
输出结果:
3. StringType、BooleanType、BinaryType、NoneType
这几种数据类型的使用方法大致相同,就不一一讲解了,注意BinaryType对应着使用了Python中的bytearray。
输出结果:
4. 复合数据类型(ArrayType、MapType、StructType)
复合数据类型共有三种:数组(ArrayType)、字典(MapType)、结构体(StructType),其中数组(ArrayType)要求数组元素类型一致;字典(MapType)要求所有“key”的类型一致,所有“value”的类型一致,但“key”、“value”的类型可以不一致;结构体(StructType)的元素类型可以不一致。
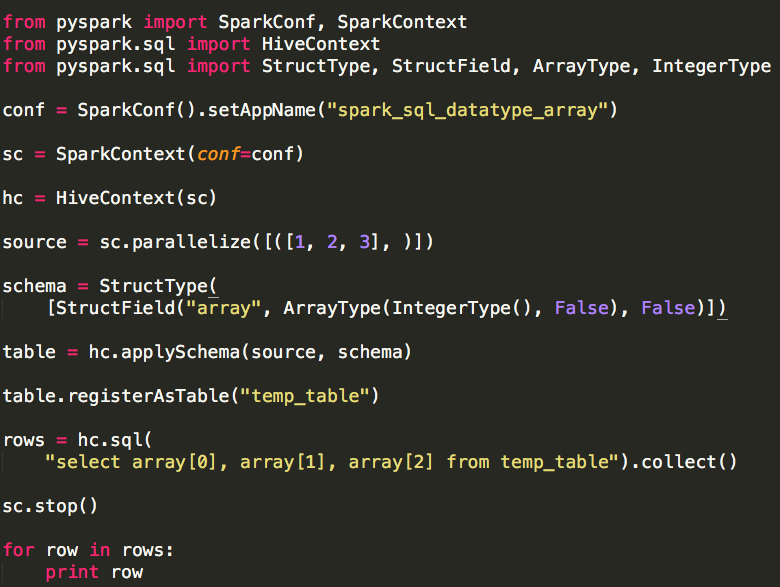
(1)ArrayType
ArrayType要求指定数组元素类型。
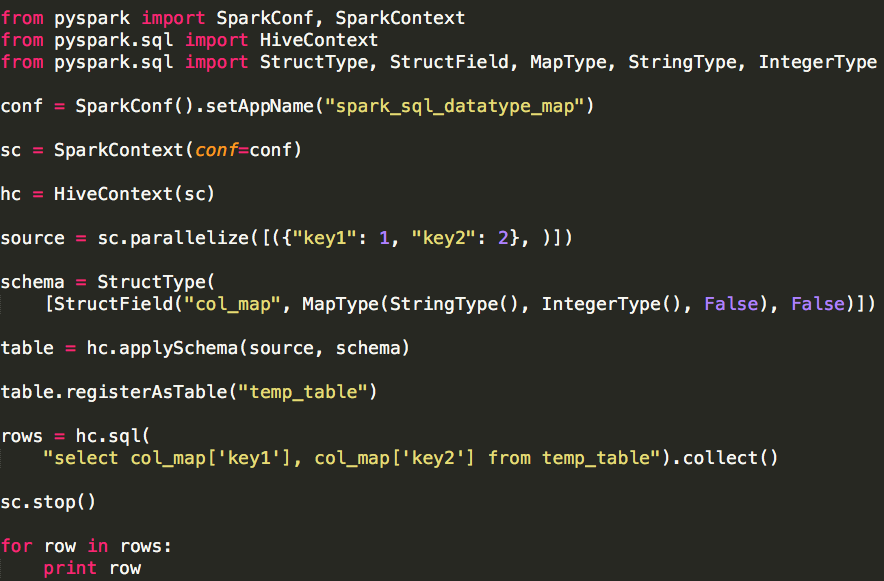
(2)MapType
MapType要求指定键(key)类型和值(value)类型。
(3)StructType
StructType包含的元素类型可不一致,需要根据元素的次序依次为其指定合适的名称与数据类型。
综上所述,Spark(Hive)SQL为我们提供了丰富的数据类型,我们需要根据分析数据的实际情况为其选取合适的数据类型(基本类型、复合类型)、尤其是数据类型各自的表示(精度)范围以及数据溢出的情况处理。
- Spark(Hive) SQL中UDF的使用(Python)
相对于使用MapReduce或者Spark Application的方式进行数据分析,使用Hive SQL或Spark SQL能为我们省去不少的代码工作量,而Hive SQL或Spark SQL本身内 ...
- Spark(Hive) SQL中UDF的使用(Python)【转】
相对于使用MapReduce或者Spark Application的方式进行数据分析,使用Hive SQL或Spark SQL能为我们省去不少的代码工作量,而Hive SQL或Spark SQL本身内 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习笔记——Spark工作机制以及API详解
Spark工作机制以及API详解 本篇文章将会承接上篇关于如何部署Spark分布式集群的博客,会先对RDD编程中常见的API进行一个整理,接着再结合源代码以及注释详细地解读spark的作业提交流程,调 ...
- Java程序员从笨鸟到菜鸟之(一百零二)sql注入攻击详解(三)sql注入解决办法
sql注入攻击详解(二)sql注入过程详解 sql注入攻击详解(一)sql注入原理详解 我们了解了sql注入原理和sql注入过程,今天我们就来了解一下sql注入的解决办法.怎么来解决和防范sql注入, ...
- Spark Streaming性能调优详解
Spark Streaming性能调优详解 Spark 2015-04-28 7:43:05 7896℃ 0评论 分享到微博 下载为PDF 2014 Spark亚太峰会会议资料下载.< ...
- Hive 的collect_set使用详解
Hive 的collect_set使用详解 https://blog.csdn.net/liyantianmin/article/details/48262109 对于非group by字段,可以 ...
- 为什么说JAVA中要慎重使用继承 C# 语言历史版本特性(C# 1.0到C# 8.0汇总) SQL Server事务 事务日志 SQL Server 锁详解 软件架构之 23种设计模式 Oracle与Sqlserver:Order by NULL值介绍 asp.net MVC漏油配置总结
为什么说JAVA中要慎重使用继承 这篇文章的主题并非鼓励不使用继承,而是仅从使用继承带来的问题出发,讨论继承机制不太好的地方,从而在使用时慎重选择,避开可能遇到的坑. JAVA中使用到继承就会有两 ...
- 详解Python编程中基本的数学计算使用
详解Python编程中基本的数学计算使用 在Python中,对数的规定比较简单,基本在小学数学水平即可理解. 那么,做为零基础学习这,也就从计算小学数学题目开始吧.因为从这里开始,数学的基础知识列位肯 ...
随机推荐
- css3 盒模型
0,前言 在css2.1 之前,我们都熟知的两种盒模型,一种是w3c标准盒模型,另外一种是怪异模式下的盒模型.在css3之前我们一直使用的是标准盒模型,但是标准盒模型的宽度总是需要小心的去使用,稍有不 ...
- 多线程、Socket
多线程 线程.进程和应用程序域 进程:进程是一个操作系统上的概念,用来实现多任务并发执行,是资源分配的最小单元,各个进程是相互独立的,可以理解为执行当中的程序,在操作系统中一般用一个称为PCB的结 ...
- Tomcat - java.lang.UnsupportedClassVersionError:Unsupported major.minor version 51.0 (unable to load class com.microsoft.sqlserver.jdbc.SQLS
今天使用Tomcat连接sql Server 2008 enterprise的时候,报错: HTTP Status 500 - Servlet execution threw an exception ...
- mysql5.5提示Deprecated: mysql_query(): The mysql extension is deprecated
解决方法1:在php程序代码里面设置报警级别 <?php error_reporting = E_ALL & ~E_DEPRECATED 方法2:禁止php报错 display_erro ...
- ueditor之ruby on rails 版
最近公司的项目开始要使用ueditor了,但是ueditor却没有提供rails的版本,因此需要自己去定制化ueditor来满足项目的需求.不多说了,先简要说明下使用方法: ueditor目录下: 注 ...
- Bad owner or permissions on .ssh/config
Bad owner or permissions on $HOME/.ssh/config The ssh with RHEL 4 is a lot more anal about security ...
- js 之 json
/*JSON语法数据在名称/值对中数据由逗号分隔花括号保存对象方括号保存数组 JSON 数据的书写格式是:名称/值对名称/值对包括字段名称(在双引号中),后面写一个冒号,然后是值;如"myw ...
- Hibernate 使用说明
Eclipse中hibernate连接mySQL数据库练习(采用的是hibernate中XML配置方式连接数据库,以后在更新其他方式的连接) Hibernate就是Java后台数据库持久层的框架,也是 ...
- JavaScript学习心得(二)
一选择DOCTYPE DOCTYPE是一种标准通用标记语言的文档类型声明,目的是告诉标准通用标记语言解析器使用什么样的文档类型定义(DTD)来解析文档. 网页从DOCTYPE开始,即<!DOCT ...
- QFTP走了以后QNetworkAccessManager出现了
QNetworkAccessManager Class Header: #include <QNetworkAccessManager>qmake: QT += networ ...