redis_ 5 集群
[转自 ]https://www.cnblogs.com/hjwublog/p/5681700.html#_label0
Redis集群简介
Redis 集群是3.0之后才引入的,在3.0之前,使用哨兵(sentinel)机制(本文将不做介绍,大家可另行查阅)来监控各个节点之间的状态。Redis 集群可谓是让很多人久等了。
Redis 集群是一组能进行数据共享的Redis 实例(服务或者节点)的设施,集群可以使用的功能是普通单机 Redis 所能使用的功能的一个子集;Redis 集群通常具有高可用、可扩展性、分布式、容错等特性。了解redis的集群后,这些晦涩的概念可结合redis的主从、集群分区和集群运维等角度理解体会。
Redis集群搭建
创建集群文件夹
在/usr/local/下新建redis-cluster目录并在redis-cluster下新建7031~7036共6个文件夹,这6个文件夹代表创建redis集群的6个节点。如下
[root@localhost local]# mkdir -p /usr/local/redis-cluster
[root@localhost redis-cluster]# mkdir 7031 7032 7033 7034 7035 7036
拷贝修改配置文件
将已有的/usr/local/redis/etc/下的redis.conf拷贝到新创建的7031目录中
[root@localhost etc]# cp redis.conf /usr/local/redis-cluster/7031
[root@localhost 7031]# vi redis.conf
修改项如下:
(1)绑定端口,port 7031
(2)绑定IP,bind 192.168.2.128
(3)指定数据存放路径,dir /usr/local/redis-cluster/7031
(4)启动集群模式,cluster-enabled yes
(5)指定集群节点配置文件,cluster-config-file nodes-7031.conf
(6)后台启动,daemonize yes
(7)指定集群节点超时时间,cluster-node-timeout 5000
(8)指定持久化方式,appendonly yes
上面红色项目最好全部设置,不然会出意想不到的错误,703x最好与节点文件夹保持一致。
将7031的redis.conf改完后再拷贝到剩下的5个目录中,然后只要全局替换redis.conf中的7031为相应的节点即可。
安装ruby
由于Redis 集群客户端实现很少,redis集群的启动需要用到ruby实现的redis-trib.rb,所以我们需要先安装ruby。
[root@localhost redis-cluster]# yum install ruby
[root@localhost redis-cluster]# yum install rubygems
[root@localhost redis-cluster]# gem install redis
启动redis实例
[root@localhost redis-cluster]#
/usr/local/redis/bin/redis-server /usr/local/redis-cluster/7031/redis.conf
分别启动6个redis实例。也可以用脚本循环启动,这样更方便省时
[root@localhost redis-cluster]#
for((i=1;i<=6;i++)); do /usr/local/redis/bin/redis-server /usr/local/redis-cluster/703$i/redis.conf; done
或者新建shell脚本继续批处理
vim run.sh
内容为:
cd redis01
./redis-server redis.conf
cd ../redis02
./redis-server redis.conf
cd ../redis03
./redis-server redis.conf
cd ../redis04
./redis-server redis.conf
cd ../redis05
./redis-server redis.conf
cd ../redis06
./redis-server redis.conf
查看redis实例是否启动成功
[root@localhost redis-cluster]# netstat -tunpl | grep redis-server
#或者
[root@localhost redis-cluster]# ps -ef | grep redis-server

创建并启动集群
进入redis安装目录的bin目录下
[root@localhost ~]# cd /usr/local/redis/bin/
[root@localhost bin]#./redis-trib.rb create --replicas 1 192.168.2.128:7031 192.168.2.128:7032 192.168.2.128:7033 192.168.2.128:7034 192.168.2.128:7035 192.168.2.128:7036
在配置redis集群的时候 ip不能写为127.0.0.1 或者0.0.0.0。要写为网络连接的ip(如:192.168.2.13)。否则会连接不到集群
命令的意义如下:
给定 redis-trib.rb 程序的命令是 create,表示创建一个新的集群。选项 --replicas 1 表示为集群中的每个主节点创建一个从节点。之后跟着的其他参数则是实例的地址列表, 指定使用这些地址所指示的实例来创建新集群。
>>> Creating cluster
>>> Performing hash slots allocation on 6 nodes...
Using 3 masters:
192.168.2.128:7031
192.168.2.128:7032
192.168.2.128:7033
Adding replica 192.168.2.128:7034 to 192.168.2.128:7031
Adding replica 192.168.2.128:7035 to 192.168.2.128:7032
Adding replica 192.168.2.128:7036 to 192.168.2.128:7033
......
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
“All 16384 slots covered.”表示集群中的 16384 个槽都有至少一个主节点在处理, 集群运作正常。从打印出来的信息也可以看出,7031,7032,7033是主节点,其它三个是从节点。
客户端连接集群
集群启动成功后,我们就可以用任意一个客户端连接集群了,如下
[root@localhost bin]# /usr/local/redis/bin/redis-cli -c -h 192.168.2.128 -p 7031
192.168.2.128:7031> info
# Server
redis_version:3.2.0
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:f8fcffd133fe3364
redis_mode:cluster
os:Linux 2.6.32-504.el6.x86_64 x86_64
arch_bits:64
可以使用 cluster info命令查看集群信息,cluster nodes命令查看集群节点信息。
集群关闭
关闭集群需要逐个关闭
[root@localhost redis-cluster]#
for((i=1;i<=6;i++)); do /usr/local/redis/bin/redis-cli -c -h 192.168.2.128 -p 703$i shutdown; done
如果重新启动集群报以下错误
[ERR] Node 192.168.2.128:7031 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0.
需要清除杀掉redis实例,然后删除每个节点下的临时数据文件appendonly.aof,dump.rdb,nodes-703x.conf,然后再重新启动redis实例即可启动集群。
[root@localhost redis-cluster]#for((i=1;i<=6;i++)); do cd 703$i; rm -rf appendonly.aof; rm -rf dump.rdb; rm -rf nodes-703$i.conf; cd ..; done
集群测试
下面我们先来体验一下集群的set,get简单操作,后面我们会进一步学习集群的更多操作。
192.168.2.128:7031> set name "zhangsan"
-> Redirected to slot [5798] located at 192.168.2.128:7032
OK
192.168.2.128:7032> set age 20
-> Redirected to slot [741] located at 192.168.2.128:7031
OK
192.168.2.128:7031> set sex "man"
OK
192.168.2.128:7031>
如果在连接客户端的时候不加-c选项set key时则会报MOVED 的错误:
[root@localhost bin]# /usr/local/redis/bin/redis-cli -h 192.168.2.128 -p 7031
192.168.2.128:7031> set name "zhangsan"
(error) MOVED 5798 192.168.2.128:7032
192.168.2.128:7031> set age 20
OK
192.168.2.128:7031> set sex "man"
OK
192.168.2.128:7031>
来看看取值又是怎么样
192.168.2.128:7031> get name
-> Redirected to slot [5798] located at 192.168.2.128:7032
"zhangsan"
192.168.2.128:7032> get age
-> Redirected to slot [741] located at 192.168.2.128:7031
"20"
192.168.2.128:7031> get sex
"man"
192.168.2.128:7031>
可以看到,客户端连接加-c选项的时候,存储和提取key的时候不断在7031和7032之间跳转,这个称为客户端重定向。之所以发生客户端重定向,是因为Redis Cluster中的每个Master节点都会负责一部分的槽(slot),存取的时候都会进行键值空间计算定位key映射在哪个槽(slot)上,如果映射的槽(slot)正好是当前Master节点负责则直接存取,否则就跳转到其他Master节点负的槽(slot)中存取,这个过程对客户端是透明的。继续看下文的集群分区原理。
Redis集群分区原理
槽(slot)的基本概念
从上面集群的简单操作中,我们已经知道redis存取key的时候,都要定位相应的槽(slot)。
Redis 集群键分布算法使用数据分片(sharding)而非一致性哈希(consistency hashing)来实现: 一个 Redis 集群包含 16384 个哈希槽(hash slot), 它们的编号为0、1、2、3……16382、16383,这个槽是一个逻辑意义上的槽,实际上并不存在。redis中的每个key都属于这 16384 个哈希槽的其中一个,存取key时都要进行key->slot的映射计算。
下面我们来看看启动集群时候打印的信息:
>>> Creating cluster
>>> Performing hash slots allocation on 6 nodes...
Using 3 masters:
192.168.2.128:7031
192.168.2.128:7032
192.168.2.128:7033
Adding replica 192.168.2.128:7034 to 192.168.2.128:7031
Adding replica 192.168.2.128:7035 to 192.168.2.128:7032
Adding replica 192.168.2.128:7036 to 192.168.2.128:7033
M: bee706db5ae182c5be9b9bdf94c2d6f3f8c8ec5c 192.168.2.128:7031
slots:0-5460 (5461 slots) master
M: 72826f06dbf3be163f2f456ca24caed76a15bdf4 192.168.2.128:7032
slots:5461-10922 (5462 slots) master
M: ab6e9d1dfc471225eef01e57be563157f81d26b3 192.168.2.128:7033
slots:10923-16383 (5461 slots) master
......
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
从上面信息可以看出,创建集群的时候,哈希槽被分配到了三个主节点上,从节点是没有哈希槽的。7031负责编号为0-5460 共5461个 slots,7032负责编号为 5461-10922共5462 个 slots,7033负责编号为10923-16383 共5461个 slots。
键-槽映射算法
和memcached一样,redis也采用一定的算法进行键-槽(key->slot)之间的映射。memcached采用一致性哈希(consistency hashing)算法进行键-节点(key-node)之间的映射,而redis集群使用集群公式来计算键 key 属于哪个槽:
HASH_SLOT(key)= CRC16(key) % 16384
其中 CRC16(key) 语句用于计算键 key 的 CRC16 校验和 。key经过公式计算后得到所对应的哈希槽,而哈希槽被某个主节点管理,从而确定key在哪个主节点上存取,这也是redis将数据均匀分布到各个节点上的基础。
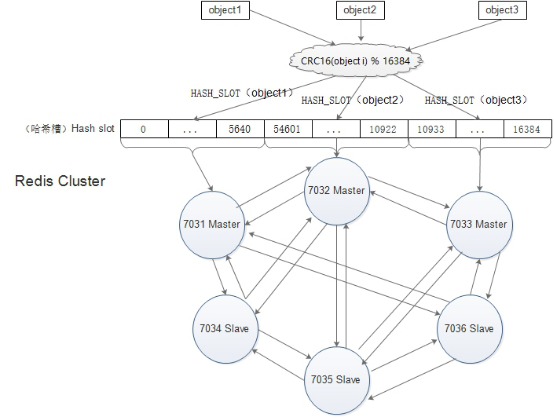
键-槽-节点(key->slot->node)映射示意图
集群分区好处
无论是memcached的一致性哈希算法,还是redis的集群分区,最主要的目的都是在移除、添加一个节点时对已经存在的缓存数据的定位影响尽可能的降到最小。redis将哈希槽分布到不同节点的做法使得用户可以很容易地向集群中添加或者删除节点, 比如说:
l 如果用户将新节点 D 添加到集群中, 那么集群只需要将节点 A 、B 、 C 中的某些槽移动到节点 D 就可以了。
l 与此类似, 如果用户要从集群中移除节点 A , 那么集群只需要将节点 A 中的所有哈希槽移动到节点 B 和节点 C , 然后再移除空白(不包含任何哈希槽)的节点 A 就可以了。
因为将一个哈希槽从一个节点移动到另一个节点不会造成节点阻塞, 所以无论是添加新节点还是移除已存在节点, 又或者改变某个节点包含的哈希槽数量, 都不会造成集群下线,从而保证集群的可用性。下面我们就来学习下集群中节点的增加和删除。
集群操作
集群操作包括查看集群信息,查看集群节点信息,向集群中增加节点、删除节点,重新分配槽等操作。
查看集群信息
cluster info 查看集群状态,槽分配,集群大小等,cluster nodes也可查看主从节点。
192.168.2.128:7031> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_sent:119
cluster_stats_messages_received:119
192.168.2.128:7031>
新增节点
(1)新增节点配置文件
执行下面的脚本创建脚本配置文件
[root@localhost redis-cluster]# mkdir /usr/local/redis-cluster/7037 && cp /usr/local/redis-cluster/7031/redis.conf /usr/local/redis-cluster/7037/redis.conf && sed -i "s/7031/7037/g" /usr/local/redis-cluster/7037/redis.conf
(2)启动新增节点
[root@localhost bin]# /usr/local/redis/bin/redis-server /usr/local/redis-cluster/7037/redis.conf
(3)添加节点到集群
现在已经添加了新增一个节点所需的配置文件,但是这个这点还没有添加到集群中,现在让它成为集群中的一个主节点
[root@localhost redis-cluster]# cd /usr/local/redis/bin/
[root@localhost bin]# ./redis-trib.rb add-node 192.168.2.128:7037 192.168.2.128:7036
>>> Adding node 192.168.2.128:7037 to cluster 192.168.2.128:7036
>>> Performing Cluster Check (using node 192.168.2.128:7036)
S: 2c8d72f1914f9d6052065f7e9910cc675c3c717b 192.168.2.128:7036
slots: (0 slots) slave
replicates 6dbb4aa323864265c9507cf336ef7d3b95ea8d1b
M: 6dbb4aa323864265c9507cf336ef7d3b95ea8d1b 192.168.2.128:7033
slots:10923-16383 (5461 slots) master
1 additional replica(s)
S: 791a7924709bfd7ef5c36d9b9c838925e41e3c2e 192.168.2.128:7034
slots: (0 slots) slave
replicates d9e3c78a7c49689c29ab67a8a17be9d95cb08452
M: d9e3c78a7c49689c29ab67a8a17be9d95cb08452 192.168.2.128:7031
slots:0-5460 (5461 slots) master
1 additional replica(s)
M: 69b63d8db629fa8a689dd1ed25ed941c076d4111 192.168.2.128:7032
slots:5461-10922 (5462 slots) master
1 additional replica(s)
S: e669a91866225279aafcac29bf07b826eb5be91c 192.168.2.128:7035
slots: (0 slots) slave
replicates 69b63d8db629fa8a689dd1ed25ed941c076d4111
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 192.168.2.128:7037 to make it join the cluster.
[OK] New node added correctly.
[root@localhost bin]#
./redis-trib.rb add-node 命令中,7037 是新增的主节点,7036 是集群中已有的从节点。再来看看集群信息
192.168.2.128:7031> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:7
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_sent:11256
cluster_stats_messages_received:11256

(4)分配槽
从添加主节点输出信息和查看集群信息中可以看出,我们已经成功的向集群中添加了一个主节点,但是这个主节还没有成为真正的主节点,因为还没有分配槽(slot),也没有从节点,现在要给它分配槽(slot)
[root@localhost bin]# ./redis-trib.rb reshard 192.168.2.128:7031
>>> Performing Cluster Check (using node 192.168.2.128:7031)
M: 1a544a9884e0b3b9a73db80633621bd90ceff64a 192.168.2.128:7031
......
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 1024
What is the receiving node ID?
系统提示要移动多少个配槽(slot),并且配槽(slot)要移动到哪个节点,任意输入一个数,如1024,再输入新增节点的ID cf48228259def4e51e7e74448e05b7a6c8f5713f.
What is the receiving node ID? cf48228259def4e51e7e74448e05b7a6c8f5713f
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:
然后提示要从哪几个节点中移除1024个槽(slot),这里输入‘all’表示从所有的主节点中随机转移,凑够1024个哈希槽,然后就开始从新分配槽(slot)了。从新分配完后再次查看集群节点信息

可见,0-340 5461-5802 10923-11263的槽(slot)被分配给了新增加的节点。三个加起来刚好1024个槽(slot)。
(5)指定从节点
现在从节点7036的主节点是7033,现在我们要把他变为新增加节点(7037)的从节点,需要登录7036的客户端
[root@localhost bin]# /usr/local/redis/bin/redis-cli -c -h 192.168.2.128 -p 7036
192.168.2.128:7036> cluster replicate cf48228259def4e51e7e74448e05b7a6c8f5713f
OK
再来查看集群节点信息

可见,7036成为了新增节点7037的从节点。
删除节点
指定删除节点的ID即可,如下
[root@localhost bin]#
./redis-trib.rb del-node 192.168.2.128:7037 'a56461a171334560f16652408c2a45e629d268f6'
>>> Removing node a56461a171334560f16652408c2a45e629d268f6 from cluster 192.168.2.128:7037
>>> Sending CLUSTER FORGET messages to the cluster...
>>> SHUTDOWN the node.
[root@localhost bin]#
集群操作小结
从上面过程可以看出,添加节点、分配槽、删除节点的过程,不用停止集群,不阻塞集群的其他操作。命令小结
#向集群中添加节点,7037是新增节点,7036是集群中已有的节点
./redis-trib.rb add-node 192.168.2.128:7037 192.168.2.128:7036
#重新分配槽
./redis-trib.rb reshard 192.168.2.128:7031
#指定当前节点的主节点
cluster replicate cf48228259def4e51e7e74448e05b7a6c8f5713f
#删除节点
./redis-trib.rb del-node 192.168.2.128:7037 'a56461a171334560f16652408c2a45e629d268f6'
到此,redis的集群搭建、分区原理、集群增加节点以及删除节点的主要内容已经简要介绍完毕。
java操作集群 :在配置redis集群的时候 ip不能写为127.0.0.1 或者0.0.0.0。要写为网络连接的ip(如:192.168.2.13)。否则会连接不到集群
@Test
public void jedisCluster() {
//创建节点
Set<HostAndPort> nodes = new HashSet<>();
nodes.add(new HostAndPort("192.168.213.178", 6700));
nodes.add(new HostAndPort("192.168.213.178", 6701));
nodes.add(new HostAndPort("192.168.213.178", 6702));
nodes.add(new HostAndPort("192.168.213.178", 6703));
nodes.add(new HostAndPort("192.168.213.178", 6704));
nodes.add(new HostAndPort("192.168.213.178", 6705));
//通过节点创建集群
JedisCluster jedisCluster = new JedisCluster(nodes);
//通过集群操作redis
jedisCluster.set("aa", "123");
String string = jedisCluster.get("aa");
System.out.println(string);
// jedisCluster.close();
}
参考文档
redis_ 5 集群的更多相关文章
- Net分布式系统之五:C#使用Redis集群缓存
本文介绍系统缓存组件,采用NOSQL之Redis作为系统缓存层. 一.背景 系统考虑到高并发的使用场景.对于并发提交场景,通过上一章节介绍的RabbitMQ组件解决.对于系统高并发查询,为了提供性能减 ...
- Redis-cluster集群【第一篇】:redis安装及redis数据类型
Redis介绍: 一.介绍 redis 是一个开源的.使用C语言编写的.支持网络交互的.可以基于内存也可以持久化的Key-Value数据库. redis的源码非常简单,只要有时间看看谭浩强的C语言,在 ...
- 分布式架构高可用架构篇_03-redis3集群的安装高可用测试
参考文档 Redis 官方集群指南:http://redis.io/topics/cluster-tutorial Redis 官方集群规范:http://redis.io/topics/cluste ...
- redis集群部署之codis 维护脚本
搞了几天redis cluster codis 的部署安装,测试,架构优化,配合研发应用整合,这里记一些心得! 背景需求: 之前多个业务都在应用到redis库,各业务独立占用主从两台服务器,硬件资源利 ...
- C#使用Redis集群缓存
C#使用Redis集群缓存 本文介绍系统缓存组件,采用NOSQL之Redis作为系统缓存层. 一.背景 系统考虑到高并发的使用场景.对于并发提交场景,通过上一章节介绍的RabbitMQ组件解决.对于系 ...
- Redis 集群的安装
Redis 集群介绍.特性.规范等Redis 集群的安装(Redis3.0.3 + CentOS6.6_x64)要让 Redis3.0 集群正常工作至少需要 3 个 Master 节点,要想实现高可用 ...
- redis伪集群脚本
#安装redis伪集群脚本,先把redis-..gem及启动脚本放在/data1/redis-cluster目录下,然后执行该脚本即可 #!/bin/bash set -e #获取redis本机ip ...
- 搭建redis-sentinel(哨兵机制)集群
redis怎么才能做到高可用 对于redis主从架构,slave可以对应多个本身可以保障高可用,但是对于一个master节点,如果宕机,整个缓存系统就无法进行写的操作,显然整个系统会无法做到高可用 s ...
- Redis基本概念、基本使用与单机集群部署
1. Redis基础 1.1 Redis概述 Redis是一个开源.先进的key-value存储,并用于构建高性能.可扩展的应用程序的完美解决方案. Redis从它的许多竞争继承了三个主要特点: ...
随机推荐
- JAVA进阶-泛型
>泛型:泛型指代了參数的类型化类型,一般被用在接口.类.方法中 >作用:用来确定參数的范围,在书写代码的时候提前检查代码的错误性 >泛型的声明,下面给出类声明,依此类推: class ...
- usb键鼠驱动分析【钻】
本文转载自:http://blog.csdn.net/orz415678659/article/details/9197859 一.鼠标 Linux下的usb鼠标驱动在/drivers/hid/usb ...
- Java-杂项:Float 加减精度问题
ylbtech-Java-杂项:Float 加减精度问题 1.返回顶部 1. java float 加减精度问题在取这个字段的时候转换成BigDecimal就可以了同时,BigDecimal是可以设置 ...
- 前端总结·基础篇·CSS
前端总结·基础篇·CSS 1 常用重置+重置插件(Normalize.css,IE8+) * {box-sizing:border-box;} /* IE8+ */body {margin:0;} ...
- Oracle获取alter.log的方法
10g下:可以在 admin\{sid}\pfile文件下的init.ora文件中找到以下内容:audit_file_dest = C:\ORACLE\PRODUCT\10.2.0\ADMIN\ORC ...
- 更换WordPress编辑器为TinyMCE Advanced
WordPress自带的编辑器功能很少,连更换字体样式大小都不行,没关系WordPress的插件中心插件非常多 在插件中心搜索TinyMCE Advanced 安装启用 还没完 点击设置 里面有丰富的 ...
- javascript中构造函数知识总结
构造函数的说明 1.1 构造函数是一个模板 构造函数,是一种函数,主要用来在创建对象时对 对象 进行初始化(即为对象成员变量赋初始值),并且总是与new运算符一起使用. 1.2 new 运算符 new ...
- jq+mui 阻止事件冒泡
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <meta name ...
- css—各浏览器下的背景色渐变
.linear{ width:100%; height:600px; FILTER: progid:DXImageTransform.Microsoft.Gradient(gradientType=0 ...
- 系统A一定会按照自我的样子改造世界
A一定会按照自己的样子去构建系统A1,A1一定还会按照自己的样子去构建系统A1.1,A1.1一定还是会按照自我的样子去构建A1.1.1……我们编程,我们改造世界,我们的方向是被注定要朝着构建人造人的方 ...