TensorFlow+实战Google深度学习框架学习笔记(10)-----神经网络几种优化方法
神经网络的优化方法:
4、批标准化(解决网络层数加深而产生的问题---如梯度弥散,爆炸等)
一、学习率的设置----指数衰减方法
通过指数衰减的方法设置GD的学习率。该方法可让模型在训练的前期快速接近较优解,又可保证模型在训练后期不会有太大的波动,从而更加接近局部最优。
学习率不能过大,可能让参数在极值两侧波动,不能过小,训练时间会过长。
TensorFlow提供的方法:tf.train.exponential_decay函数实现了指数衰减学习率。通过这个函数,可以先使用较大的学习率来快速得到一个比较优的解,然后随着迭代的继续逐步减小学习率,使得模型在训练后期更加稳定。exponential_decay函数会指数级地减少学习率:

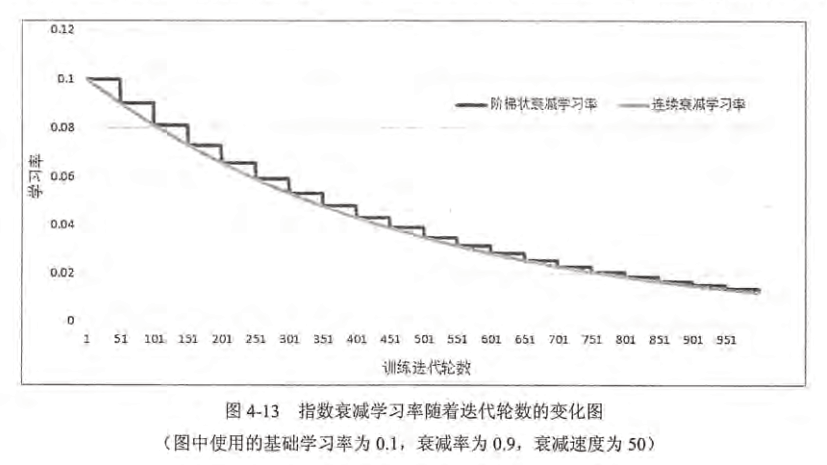
应用:

二、过拟合问题:
过拟合:一个模型过于复杂时,只记得去学习训练数据中随机噪声而忘了去学习训练数据中通用的趋势。
避免过拟合的方法:正则化、数据增强(增加训练数据)、提早终止训练、参数共享、批标准化、集成方法、辅助分类节点
正则化:在损失函数中加入刻画模型复杂程度的指标。通过限制权重的大小,得到模型不能拟合训练数据中的随机噪音。
TensorFlow中的L2正则化的损失函数定义:

提高代码可读性:可以运用集合collection的思想,即将均方误差损失函数和正则化损失函数分开计算,然后放入loss【自己取名】的集合中,最终再从集合中取出求和。

三、滑动平均模型【参数的更新】
作用:
使用滑动平均模型在很多应用中都可以在一定程度提高模型在测试数据上的鲁棒性。
其实滑动平均模型,主要是通过控制衰减率来控制参数更新前后之间的差距,从而达到减缓参数的变化值(如,参数更新前是5,更新后的值是4,通过滑动平均模型之后,参数的值会在4到5之间)
如:本次结果=(1-a)本次采样值+a上次结果
目的:平滑、滤波,即使数据平滑变化,通过调整参数来调整变化的稳定性。
为何在测试阶段使用:
对神经网络边的权重 weights 使用滑动平均,得到对应的影子变量 shadow_weights。在训练过程仍然使用原来不带滑动平均的权重 weights,不然无法得到 weights 下一步更新的值,又怎么求下一步 weights 的影子变量 shadow_weights。之后在测试过程中使用 shadow_weights 来代替 weights 作为神经网络边的权重,这样在测试数据上效果更好。因为 shadow_weights 的更新更加平滑,对于随机梯度下降而言,更平滑的更新说明不会偏离最优点很远;对于梯度下降 batch gradient decent,我感觉影子变量作用不大,因为梯度下降的方向已经是最优的了,loss 一定减小;对于 mini-batch gradient decent,可以尝试滑动平均,毕竟 mini-batch gradient decent 对参数的更新也存在抖动。
比如:在最后的1000次训练过程中,模型早已经训练完成,正处于抖动阶段,而滑动平均相当于将最后的1000次抖动进行了平均,这样得到的权重会更加robust。
应用:
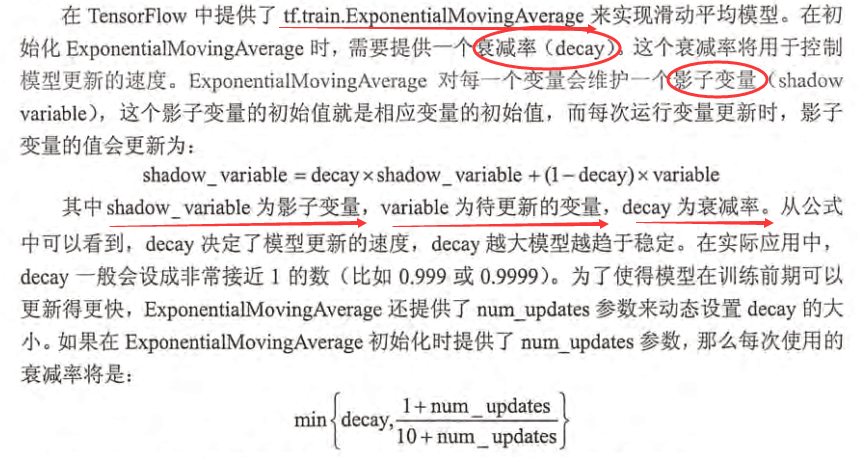
tensorflow提供了tf.train.ExponentialMovingAverage(decay, num_updates=None, name='ExponentialMovingAverage')这个接口。
- decay:一般设置为非常接近1的数,比如0.9999,
- num_updates:为了在初期快速的更新,可以设置num_updates,如果num_updates = None ,那么decay将为一个固定的值。设置num_updates=global_step,那么dacay将会根据如下公式选择decay值:
min(decay, (1 + num_updates) / (10 + num_updates))
使用MovingAverage的三个要素。
- 指定decay参数创建实例:
- ema = tf.train.ExponentialMovingAverage(decay=0.9999)
- 对模型变量使用apply方法:
- maintain_averages_op = ema.apply([var0, var1])
- 在优化方法使用梯度更新模型参数后执行MovingAverage:
- with tf.control_dependencies([opt_op]):
training_op = tf.group(maintain_averages_op)其中,tf.group将传入的操作捆绑成一个操作。
以下的代码有以下几点要注意:
原理:
apply方法会为每个变量(也可以指定特定变量)创建各自的shadow variable, 即影子变量。之所以叫影子变量,是因为它会全程跟随训练中的模型变量。影子变量会被初始化为模型变量的值,然后,每训练一个step,就更新一次。更新的方式为:
应用例子:
import tensorflow as tf v1 = tf.Variable(0, dtype=tf.float32) #初始化v1变量
step = tf.Variable(0, trainable=False) #初始化step为0
ema = tf.train.ExponentialMovingAverage(0.99, step) #定义平滑类,设置参数以及step
maintain_averages_op = ema.apply([v1]) #定义更新变量平均操作 with tf.Session() as sess: # 初始化
init_op = tf.global_variables_initializer()
sess.run(init_op)
print sess.run([v1, ema.average(v1)]) # 更新变量v1的取值
sess.run(tf.assign(v1, 5))
sess.run(maintain_averages_op)
print sess.run([v1, ema.average(v1)]) # 更新step和v1的取值
sess.run(tf.assign(step, 10000))
sess.run(tf.assign(v1, 10))
sess.run(maintain_averages_op)
print sess.run([v1, ema.average(v1)]) # 更新一次v1的滑动平均值
sess.run(maintain_averages_op)
print sess.run([v1, ema.average(v1)])
书中详细解释


四、批标准化:(batch normalization,BN)
https://www.cnblogs.com/zyly/p/8996070.html
(1)BN的来源:
批标准化(BN)是为了克服神经网络层数加深导致难以训练而产生的。
神经网络层数加深,收敛速度会很慢,常常导致梯度弥散或者梯度爆炸问题。
统计学中有一个ICS(Internal Covariate Shift)理论,这是一个经典假设:源域和目标域的数据分布是一致的。即训练数据和测试数据是满足相同分布的,这是通过训练数据获得的模型能够在测试集获得好效果的一个基本保障。
【Covariate Shift:指训练集的样本数据和目标样本集分布不一致时,训练得到的模型无法很好地泛化,它是分布不一致假设之下的一个分支问题,即源域和目标域的条件概率是一致的,但其边缘概率不同。的确,神经网络的各层输出,输出分布和对应的输入分布不同,且差异随着网络深度增大而加大,但每一层所指向的样本标记(label)是不变的。】
解决思路:根据训练样本和目标样本的比例对训练样本做一个矫正。通过BN来规范化某些层或所有层的输入,来固定每层输入的均值与方差。
(2)BN方法:
BN一般用在激活函数之前,对x=Wu+b做规范化,使结果的均值为0,方差为1.让每一层的输入有一个稳定的分布会有利于网络的训练。
BN层的前向传播公式为:

反向传播:

https://blog.csdn.net/pan5431333/article/details/78052867
(3)BN类型:
- Batch Norm:统计每个通道上所有其他维度的均值和方差。


(4)BN优点:
详细解释:https://blog.csdn.net/sunflower_sara/article/details/81159155
BN通过规范化让激活函数分布在线性区间,结果就是加大了梯度,优点如下:
- 加大探索的步长,加快收敛速度
- 容易跳出局部最小值
- 破坏原来的数据分布,一定程度上缓解过拟合
- 降低网络对初始化权重敏感
- 允许使用较大的学习率
(5)BN缺点:
https://cloud.tencent.com/developer/article/1351476
- 如果Batch Size太小,则BN效果明显下降。
- 局限2:对于有些像素级图片生成任务来说,BN效果不佳;
- 局限3:RNN等动态网络使用BN效果不佳且使用起来不方便
- 局限4:训练时和推理时统计量不一致
(6)BN训练 \ 验证 \ inference
训练:
BN层执行的操作为前向传播,eps的作用是保证分母不会除零,计算每个featuremap的minibatch集内的均值方差,归一化每个神经元xi,也就是CNN中featuremap的每个像素点,然后乘一个系数r,加上偏置b(初始化时一般r=1,b=0),得到输出yi,然后yi输入到激活函数,激活函数的输出再输入下一个卷积层,下一个卷积层的输出又重复以上操作。一般BN层都加在非线性层前面。参数r,b也是通过反向传播算法学习得到。所以在训练中,forward和backward都经过BN层。

按照:

迭代更新全局训练数据的统计值
TensorFlow+实战Google深度学习框架学习笔记(10)-----神经网络几种优化方法的更多相关文章
- [Tensorflow实战Google深度学习框架]笔记4
本系列为Tensorflow实战Google深度学习框架知识笔记,仅为博主看书过程中觉得较为重要的知识点,简单摘要下来,内容较为零散,请见谅. 2017-11-06 [第五章] MNIST数字识别问题 ...
- TensorFlow+实战Google深度学习框架学习笔记(5)----神经网络训练步骤
一.TensorFlow实战Google深度学习框架学习 1.步骤: 1.定义神经网络的结构和前向传播的输出结果. 2.定义损失函数以及选择反向传播优化的算法. 3.生成会话(session)并且在训 ...
- 1 如何使用pb文件保存和恢复模型进行迁移学习(学习Tensorflow 实战google深度学习框架)
学习过程是Tensorflow 实战google深度学习框架一书的第六章的迁移学习环节. 具体见我提出的问题:https://www.tensorflowers.cn/t/5314 参考https:/ ...
- 学习《TensorFlow实战Google深度学习框架 (第2版) 》中文PDF和代码
TensorFlow是谷歌2015年开源的主流深度学习框架,目前已得到广泛应用.<TensorFlow:实战Google深度学习框架(第2版)>为TensorFlow入门参考书,帮助快速. ...
- TensorFlow实战Google深度学习框架5-7章学习笔记
目录 第5章 MNIST数字识别问题 第6章 图像识别与卷积神经网络 第7章 图像数据处理 第5章 MNIST数字识别问题 MNIST是一个非常有名的手写体数字识别数据集,在很多资料中,这个数据集都会 ...
- TensorFlow实战Google深度学习框架1-4章学习笔记
目录 第1章 深度学习简介 第2章 TensorFlow环境搭建 第3章 TensorFlow入门 第4章 深层神经网络 第1章 深度学习简介 对于许多机器学习问题来说,特征提取不是一件简单的事情 ...
- TensorFlow实战Google深度学习框架-人工智能教程-自学人工智能的第二天-深度学习
自学人工智能的第一天 "TensorFlow 是谷歌 2015 年开源的主流深度学习框架,目前已得到广泛应用.本书为 TensorFlow 入门参考书,旨在帮助读者以快速.有效的方式上手 T ...
- 实现迁徙学习-《Tensorflow 实战Google深度学习框架》代码详解
为了实现迁徙学习,首先是数据集的下载 #利用curl下载数据集 curl -o flower_photos.tgz http://download.tensorflow.org/example_ima ...
- TensorFlow实战Google深度学习框架10-12章学习笔记
目录 第10章 TensorFlow高层封装 第11章 TensorBoard可视化 第12章 TensorFlow计算加速 第10章 TensorFlow高层封装 目前比较流行的TensorFlow ...
随机推荐
- 【ZOJ 4067】Books
[链接] 我是链接,点我呀:) [题意] [题解] 统计a中0的个数cnt0 然后m减去cnt0 因为这cnt0个0是一定会取到的. 如果m==0了 那么直接找到数组中的最小值mi 输出mi-1就好 ...
- 【ACM】nyoj_139_我排第几个_201308062046
我排第几个时间限制:1000 ms | 内存限制:65535 KB 难度:3描述 现在有"abcdefghijkl”12个字符,将其所有的排列中按字典序排列,给出任意一种排列,说出这个排 ...
- Linux文字分段裁剪命令cut(转)
Linux cut命令用于显示每行从开头算起num1到num2的文字. 语法 cut [-bn] [file] cut [-c] [file] cut [-df] [file] 使用说明: cut命令 ...
- PHP扩展开发--实验成功
原文:http://kimi.it/496.html http://blog.csdn.net/u011957758/article/details/72234075 ---------------- ...
- uva live 6827 Galaxy collision
就是给出非常多点,要求分成两个集合,在同一个集合里的点要求随意两个之间的距离都大于5. 求一个集合.它的点数目是全部可能答案中最少的. 直接从随意一个点爆搜,把它范围内的点都丢到跟它不一样的集合里.不 ...
- 输入url发生了什么--前端所有知识
面试经常会问到的一个问题,这个问题舒展开来,其实包含了前端(一些后端)几乎所有的知识.梳理一下,备忘.包含了一些面经中常问的问题. 有时间待续
- C++设计模式之状态模式(二)
2.智能空调的设计与实现 某软件公司将开发一套智能空调系统: 系统检測到温度处于20---30度之间,则切换到常温状态:温度处于30---45度,则切换到制冷状态: 温度小于20度,则切换到制热状态. ...
- 公司须要内部的地图服务,准备自己去开发可是成本太高,如今有没有专门为企业提供GIS地图开发的产品呀?大概价格多少?
公司须要内部的地图服务,准备自己去开发可是成本太高,如今有没有专门为企业提供GIS地图开发的产品呀?大概价格多少?
- oracel表的分区
1,创建表及分区 create table test ( ID VARCHAR2(32), MONTHS VARCHAR2(40), USERID VARCHAR2(20) ) partition b ...
- 《游戏脚本的设计与开发》-(RPG部分)3.8 通过脚本来自由控制游戏(一)
注意:本系列教程为长篇连载无底洞.半路杀进来的朋友,假设看不懂的话.请从第一章開始看起.文章文件夹请点击以下链接. http://blog.csdn.net/lufy_legend/article/d ...