day03深浅拷贝、文件操作和函数初识
一、赋值、浅拷贝与深拷贝
直接赋值:其实就是对象的引用(别名)。
浅拷贝(copy):拷贝父对象,不会拷贝对象的内部的子对象。
深拷贝(deepcopy): copy 模块的 deepcopy 方法,完全拷贝了父对象及其子对象。
赋值实例:
# 赋值运算 变量指向同一个内存地址
l1 = [1,2,3]
l2 = l1
l3 = l2
l1.append(666)
print(l1,l2,l3)
print(id(l1),id(l2),id(l3))
# 运行结果:
# [1, 2, 3, 666] [1, 2, 3, 666] [1, 2, 3, 666]
# 1543171498568 1543171498568 1543171498568 赋值运算 变量指向同一个内存地址
赋值实例: 赋值运算 变量指向同一个内存地址
浅拷贝实例:
# copy一个新列表(dict),列表在内存中是新的,但是列表里面的元素,完全沿用之前的元素。
l1 = [1, 2,{'alex':23},4,[22,33]]
l2 = l1.copy()
l1[-1].append(44)
l1[2]['taibai'] = 18
l2[-1].append(55)
l2[2]['egon'] = 36
print(id(l1),id(l2)) #1583337071240 1583337553800
print(id(l1[-1]),id(l2[-1])) #1583337071176 1583337071176
print(l1,l2)#[1, 2, {'alex': 23, 'taibai': 18, 'egon': 36}, 4, [22, 33, 44, 55]] [1, 2, {'alex': 23, 'taibai': 18, 'egon': 36}, 4, [22, 33, 44, 55]] l1[0] = 2
l1[-1].append(88)
l2[-1].append(99)
l1.append(666)
l2.append(999)
print(l1,l2)#[2, 2, {'alex': 23, 'taibai': 18, 'egon': 36}, 4, [22, 33, 44, 55, 88, 99], 666] [1, 2, {'alex': 23, 'taibai': 18, 'egon': 36}, 4, [22, 33, 44, 55, 88, 99], 999]
print(id(l1[0]),id(l2[0])) #140721386935360 140721386935328
print(id(l1),id(l2))#1866099286664 1866099769224
实例一
l1 = [1, 2, 3, [22, 33]]
l2 = l1[:] # 切片 是 浅copy
l1[-1].append(666)
print(id(l1),id(l2)) #不是赋值关系 2304312369800 2304312852040
print(l1,l2) #[1, 2, 3, [22, 33, 666]] [1, 2, 3, [22, 33, 666]]
列表切片属于浅拷贝
x = ['lily', '', 'hr',['a']]
y = x
x[0] = 'lucy'
z = list(x) #列表实例化对象也是前拷贝
x[0] = 'lilei'
x[-1].append('b')
z[-1].append('c')
print(x,y,z)#['lilei', '20', 'hr', ['a', 'b', 'c']] ['lilei', '20', 'hr', ['a', 'b', 'c']] ['lucy', '20', 'hr', ['a', 'b', 'c']]
print(id(x),id(y),id(z))#1744470303368 1744470303368 1744502045704
列表实例化对象也是前拷贝
图片解析赋值、浅拷贝和深拷贝原理
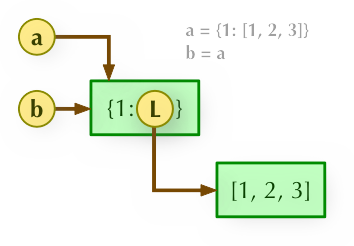
1、b = a: 赋值引用,a 和 b 都指向同一个对象。
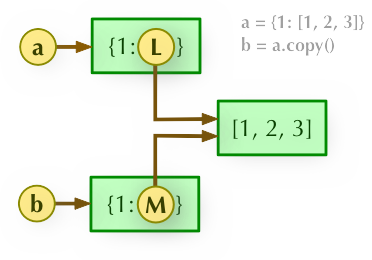
2、b = a.copy(): 浅拷贝, a 和 b 是一个独立的对象,但他们的子对象还是指向统一对象(是引用)。
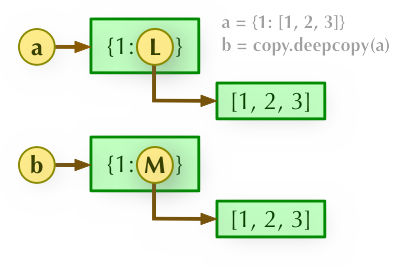
3、b = copy.deepcopy(a): 深度拷贝, a 和 b 完全拷贝了父对象及其子对象,两者是完全独立的。
深拷贝实例:深度拷贝需要引入 copy 模块
import copy
# 总结:深copy则会在内存中开辟新空间,将原列表以及列表里面的可变的数据类型重新创建一份,
# 不可变的数据类型则沿用之前的。
l1 = [1, 2, 3, [22, 33]]
l2 = copy.deepcopy(l1)
print(id(l1), id(l2))
print(id(l1[0]),id(l2[0]))
print(id(l1[-1]),id(l2[-1]))
l1[0] = 2
l1[-1].append(666)
print(l1,l2)
# 运行结果:
# 2522273468936 2522273389832
# 140732471497760 140732471497760
# 2522273604680 2522273605000
# [2, 2, 3, [22, 33, 666]] [1, 2, 3, [22, 33]]
#
# 小知识点:
# id 测试对象的内存地址
# == 比较 比较两边的数值是否相等
# print(2 == 2)
# is 判断 判断的两边对象的内存地址是否是同一个
深拷贝实例 内存地址比较 id
二、文件操作
之前对文件进行的任何操作,都必须依赖一个文件编辑器,word wps等等
假设一个场景:现在世界上没有任何个文件编辑器的产生。
设计这个软件必要的三要素:
path:文件的路径。
encoding:文件以什么编码方式存储,就以什么编码方式读取。
mode:读,写,写读,读写,追加,改等等。不写mode默认是r 不同模式打开文件的完全列表:

例子:以下这种读取方法只适合读取小文件
f1 = open(r'C:\Users\Administrator\Desktop\python_excel\log\rsyncd.log', encoding='utf-8', mode='r')
content = f1.read()
print(content)
f1.close()
文件句柄赋值给一个变量 ,例如 上面例子变量f1。open 内置函数 底层调用的操作系统的操作文件功能的接口。windows: 默认编码gbk,linux utf-8, ios: utf-8。带b的模式操作对象都是非文字类的文件:视频,音频,图片。
操作文件总共3步:1,打开文件,产生文件句柄。2,对文件句柄进行操作。3,关闭文件句柄。
常见错误
1,UnicodeDecodeError: 'gbk' codec can't decode... 编解码错误。
2,路径错误。路径分隔符 与后面的字符产生特殊的意义。 解决方式 r 或者 \ # 绝对路径:从根目录开始。和 # 相对路径:同一个工作目录(文件夹)下。
三个大方向:
1、读:r(只读) rb(bytes类型只读) r+(读写) rb+(bytes类型读写) 默认就是r模式
# 1.1 read()
f1 = open(r'C:\Users\Administrator\Desktop\python_excel\log\rsyncd.log', encoding='utf-8',)
content = f1.read()
print(content,type(content))
f1.close()
结果:
D:\python\python37\python.exe C:/Users/Administrator/Desktop/python_excel/ZY.py
haha
caltta
xixi <class 'str'> Process finished with exit code 0
# 1.2 read(n) r模式下,n代表字符。
f1 = open(r'C:\Users\Administrator\Desktop\python_excel\log\rsyncd.log', encoding='utf-8',)
content = f1.read(6) #eg: haha\nc 6个字符
print(content)
print('haha\nc')
f1.close()
D:\python\python37\python.exe C:/Users/Administrator/Desktop/python_excel/ZY.py
haha
c
haha
c Process finished with exit code 0
# 1.3 readline() 按行读取
f1 = open(r'C:\Users\Administrator\Desktop\python_excel\log\rsyncd.log', encoding='utf-8', mode='r')
print(f1.readline().strip())
print(f1.readline().strip())
f1.close()
D:\python\python37\python.exe C:/Users/Administrator/Desktop/python_excel/ZY.py
haha
caltta Process finished with exit code 0
# 1.4 readlines() 返回一个列表,列表里面的元素是原文件每一行
f1 = open(r'C:\Users\Administrator\Desktop\python_excel\log\rsyncd.log', encoding='utf-8', mode='r')
content = f1.readlines()
print(content)
f1.close()
结果:
D:\python\python37\python.exe C:/Users/Administrator/Desktop/python_excel/ZY.py
['haha\n', 'caltta\n', 'xixi'] Process finished with exit code 0
# 1.5 for循环
f1 = open(r'C:\Users\Administrator\Desktop\python_excel\log\rsyncd.log', encoding='utf-8', mode='r')
for line in f1:
print(line.strip())
f1.close()
D:\python\python37\python.exe C:/Users/Administrator/Desktop/python_excel/ZY.py
haha
caltta
xixi Process finished with exit code 0
rb模式
#f1 = open(r'log\rsyncd.log', encoding='utf-8', mode='rb') #b的方式不能指定编码
#文件不管以什么编码保存到磁盘上 都是以二进制方式存储,所以在读取rb和写入wb时直接用二进制来操作
#关于换行,Windows以\r\n来换行 Linux以\n来换行 f1 = open(r'log\rsyncd.log', mode='rb')
content = f1.read()
print(content)
print(content.decode('utf-8'))
f1.close()
结果:
D:\python\python37\python.exe C:/Users/Administrator/Desktop/python_excel/ZY.py
b'haha\r\ncaltta\r\nxixi'
haha
caltta
xixi Process finished with exit code 0
r+ 读写模式
先读后写
f = open(r'log\rsyncd.log',encoding='utf-8',mode='r+')
print(f.read()) #先读完 光标会移到文本末尾
'''
haha
caltta
xixi
'''
f.write('') #然后再写 写完后当前光标也在末尾
'''
haha
caltta
xixi666
'''
print(f.read()) #再读就都不用来了
f.close()
先写后读会出问题(会从光标开始替换原来的内容)
# -*-coding:utf8 -*- #要指定代码编码格式 以防止中文报错
f = open(r'log\rsyncd.log',encoding='utf-8',mode='r+')
f.write('秦小芳和徐志文')
print(f.read())#覆盖原来的内容 光标移动到 ‘文’ 字后面
f.close()
原文件内容:
haha
caltta
xixi
xiaoming 覆盖后的文件内容:
秦小芳和徐志文iaoming
结果
2、第二写模式 写 w wb w+ wb+
# w模式 没有文件创建文件写入内容,有文件先清空内容后写入。
f = open(r'log\rsyncd.log',encoding='utf-8',mode='w')
f.write('hi')
f.write('caltta ~~~')
f.write('深圳 ~~~')
f.write('北京 ~~~')
f.write('上海 ~~~')
f.write('南京 ~~~')
f.close()
结果:
hicaltta ~~~深圳 ~~~北京 ~~~上海 ~~~南京 ~~~
小栗子
# wb模式
f1 = open('timg.jpeg', mode='rb')
content = f1.read()
print(content)
f2 = open('timg2.jpeg',mode='wb')
f2.write(content)
f2.close()
小栗子
# w+ 写读
f = open('log1',encoding='utf-8',mode='w+')
f.write('深圳市民中心...')
f.seek(0)
print(f.read())
f.close()
小栗子
3、追加(a ab a+ a+b)模式 a 追加 没有文件创建文件追加内容,有文件,在文件最后追加内容。
f = open('log3',encoding='utf-8',mode='a')
f.write('深圳')
f.close()
文件操作的其他方法
# seek 调整光标位置 按照字节移动 对英文数字字母没问题 对中文会有问题 。 因为除了acsll码都是多个字节一个字符
#seek(0) 将光标移动到开始, seek(0,2) 将光标移动到最后。 # tell 获取光标位置 ,按照字节。# readable() writable() 是否可以读?可以写?
f = open(r'log\rsyncd.log',encoding='utf-8') #hi caltta ~~~深圳 ~~~北京 ~~~上海 ~~~南京 ~~~
f.seek(10)
print(f.read()) #~~~深圳 ~~~北京 ~~~上海 ~~~南京 ~~~
print(f.tell()) #当前关闭位置 已经到了最后 53
f.seek(0) # 将光标移动到开始
print(f.tell()) #
f.seek(0,2) # 将光标移动到最后。
print(f.tell()) #
print(f.read()) # 打印为空
print(f.writable()) #False
if f.writable():
f.write('')
f.close()
# flush 刷新 保存
f = open('log3',encoding='utf-8',mode='w')
f.write('fjdsklafjdfjksa')
f.flush()
f.close()
小栗子
# truncate 截断截取
f = open(r'log\rsyncd.log',encoding='utf-8',mode='r+')
f.truncate(3) #将文件截断只留下三个字节
f.close()
import os
import time
import shutil root_dir = r'C:\Users\Administrator\Desktop\python_excel\log'
os.chdir(root_dir)
oldname = 'rsyncd.log'
newname = time.strftime('%Y-%m-%d', time.localtime()) + oldname if os.path.exists(oldname): #每天创建新的rsyncd.log的日志文件,
if os.path.exists(newname):
pass
else:
shutil.copy(oldname,newname)
with open(oldname, 'r+') as f:
f.seek(0)
f.truncate() else:
f = open(oldname, 'w',encoding='gbk')
f.close() dirname= os.listdir(root_dir)
# print(dirname)
ntime = int(time.time()) - 3600 * 24 * 15 #保留15天以内的日志文件
for item in dirname:
if item == oldname:
pass
else:
ft = os.stat(item)
ltime = int(ft.st_mtime)
# print('ft:',ft)
# print('ltime:',ltime,item)
if ltime <= ntime:
os.remove(item)
else:
pass
只保留15天的日志
文件的改
1,以读的模式打开原文件。
2,以写的模式打开新文件。
3,读取原文件对源文件内容进行修改形成新内容写入新文件。
4,将原文件删除。
5,将新文件重命名成原文件。
# 方法一 小文件可以。
import os # 1,以读的模式打开原文件。
# 2,以写的模式打开新文件。
with open('xxx个人简历',encoding='gbk') as f1,\
open('xxx个人简历.bak',encoding='utf-8',mode='w') as f2: #f1的文件编码格式是什么就用什么格式
# 3,读取原文件对源文件内容进行修改形成新内容写入新文件。
old_content = f1.read()
# print(old_content)
new_content = old_content.replace('xxx','hi')
f2.write(new_content) # 4,将原文件删除。
os.remove('xxx个人简历')
# 5,将新文件重命名成原文件。
os.rename('xxx个人简历.bak','xxx个人简历') # 方法二:
import os # 1,以读的模式打开原文件。
# 2,以写的模式打开新文件。
with open('xxx个人简历',encoding='utf-8') as f1,\
open('xxx个人简历.bak',encoding='utf-8',mode='w') as f2:
# 3,读取原文件对源文件内容进行修改形成新内容写入新文件。
for old_line in f1:
new_line = old_line.replace('hi','xiaohei')
f2.write(new_line) # 4,将原文件删除。
os.remove('xxx个人简历')
# 5,将新文件重命名成原文件。
os.rename('xxx个人简历.bak','xxx个人简历')
大栗子一 文件修改
# -*-coding:utf8 -*- '''
修改svn配置文件
将svn配置文件中的 工号 替换为 姓名+工号 eg: xiaoming xiaoming00001008
提供了一个名单文件格式:
xiaoyang00001007
xiaoming00001008
...
'''
import os dic = {}
with open(file='svnuser.txt',encoding='gbk',mode='r') as f: #Windows文件默认是gbk 编码的
for line in f:
# print(line.strip())
tempstr = line.strip()[-10:]
dic[tempstr] = line.strip()
# print(tempstr,type(tempstr))
with open('gota_4g.conf',encoding='utf-8') as f1,\
open('gota_4g.conf.bak',encoding='utf-8',mode='w') as f2:
for old_line in f1:
for key in dic.keys():
old_line = old_line.replace(key,dic[key]) f2.write(old_line)
# 将原文件删除。
os.remove('gota_4g.conf')
# 将新文件重命名成原文件。
os.rename('gota_4g.conf.bak','gota_4g.conf')
大栗子二 文件修改
三、函数的初识
函数基础:什么是函数、函数的结构、函数的返回值、函数的参数
函数进阶:1. 名称空间、作用域、加载顺序、取值顺序 2. 内置函数 locals() globals() 3. 函数名 4. 高阶函数(函数的嵌套) 4. nonlocal global
1、函数(结构、作用、返回值)
# 面向过程编程
# 但是有缺点:
# ,代码重复太多。
# ,代码的可读性差。---> 诞生函数式编程
s1 = 'fjksdfjsdklf'
count =
for i in s1:
count +=
print(count) l1 = [, , , , ]
count =
for i in l1:
count +=
print(count)
# 函数是什么?
# 功能体,一个函数封装的一个功能,
# 结构:
'''
def 函数名():
函数体
'''
# 面向函数式编程:函数什么时候执行?调用:函数名()
def my_lf_len(s):
count =
for i in s:
count +=
print(count) my_lf_len('fdskfjskdlf')
# 函数的返回值
def Tantan():
print('左滑动一下')
print('右滑动一下')
# return
print('发现美女,打招呼')
# return '美女一枚'
# return ['恐龙一堆','肯德基']
return '小萝莉', '肯德基', '御姐' # 调用一次执行一次
Tantan() '''
return:
,终止函数。
,给函数的调用者(执行者)返回值。
return ---> 函数名() None
return 单个值 ---> 函数名() 直接返回该值 ['恐龙一堆','肯德基']
return 多个值 ---> 函数名() 返回多个值组成的元组 ('小萝莉', '肯德基', '御姐')
'''
ret = Tantan()
print('值:',ret, '\t类型:',type(ret))
2、函数(参数)
# 练习:
# # n = if 你看到卖西瓜 :n =
def max_(a,b): return a if a > b else b
# # if a > b:
# # return a
# # else:
# # return b
# # return a if a > b else b
print(max_(,))
# 三元运算符
# a = '饼'
# b = '西瓜'
# ret = a if > else b
# print(ret)
三元运算符
def Tantan(sex): #函数的定义:sex形式参数,形参
print('左滑动一下')
print('右滑动一下')
print('发现美女,打招呼')
return '小萝莉', '肯德基', '御姐'
Tantan('女') # 函数的执行:'女' 实际的数据, 实参。 #.位置参数。 从左至右,一一对应
def Tantan(sex,age):
print('筛选性别%s,年龄%s左右' %(sex,age))
print('左滑动一下')
print('右滑动一下')
print('发现美女,打招呼')
Tantan('女',,) # 关键字参数。 一一对应。 函数参数较多 记形参顺序较麻烦时,需要关键字参数。
def Tantan(sex,age,area):
print('筛选性别%s,%s 附近,年龄%s左右的美女' %(sex,area,age))
print('左滑动一下')
print('右滑动一下')
print('发现美女,打招呼')
Tantan(sex='女',area='南山区',age='') #. 混合参数 : 一一对应,关键字参数必须要在位置参数后面。
def Tantan(sex,age,area):
print('筛选性别%s,%s 附近,年龄%s左右的美女' %(sex,area,age))
print('搜索')
print('左滑动一下')
print('右滑动一下')
print('发现美女,打招呼')
Tantan('女',,area='南山区') #. 默认参数 : 使用最多的一般不更改的参数,默认参数一定放在位置参数后面
def Tantan(area,age,sex='girl'):
print('筛选性别%s, %s 附近,年龄%s左右的美女' %(sex,area,age))
print('左滑动一下')
print('右滑动一下')
print('发现美女,打招呼')
Tantan('南山区',,'laddboy')
#. 万能参数 *args, **kwargs
def Tantan(*args,**kwargs):
# 函数的定义: * 代表聚合。
# * 将实参角度所有的位置参数放到一个元祖中,并将元组给了args
# ** 将实参角度所有的关键字参数放到一个字典中中,并将字典给了kwargs
print(args) # ('南山区', '')
print(kwargs) #{'body': '身材好', 'voice': '萝莉音', 'money': '白富美'}
print('筛选地域:%s,年龄%s' % args) #筛选地域:南山区,年龄28
print('左滑动一下')
print('右滑动一下')
print('发现美女,打招呼')
Tantan('南山区','',body='身材好',voice='萝莉音',money='白富美') # 形参的最终顺序
# 位置参数 -- *args -- 默认参数 -- **kwargs
def func(a,b,*args,sex='女',):
print(a,b,sex,args)
func(,,,,,sex='男') # 男 (, , )
def func(a,b,*args,sex='女',**kwargs):
print(a,b,sex,args,kwargs)
func(,,,,,name='alex',age=) # 女 (, , ) {'name': 'alex', 'age': }
def Tantan(*args,**kwargs):
print(args)
print(kwargs) l1 = [,,]
l2 = (,,)
Tantan(*l1,*l2) # 函数的执行:*iterable 打散 **dic 将所有的键值对添加到kwargs。
#(, , , , , )
#{}
Tantan(, , , , , )
# (, , , , , )
# {}
dic1 = {'name':"alex"}
dic2 = {'age':}
Tantan(**dic1,**dic2)
# ()
# {'name': 'alex', 'age': }
*iterable 打散 **dic 将所有的键值对添加到kwargs。
3、函数进阶
python的空间三种:全局名称空间、局部名称空间、内置名称空间
python中的作用域:
1. 全局作用域:内置名称空间 全局名称空间
2. 局部作用域:局部名称空间
取值顺序: 就近原则 (局部名称空间 ——————> 全局名称空间 ——————> 内置名称空间)
加载顺序:内置名称空间 -------> 全局名称空间 -------> 局部名称空间
###例子1
input = 'barry'
def func():
input = 'alex' #局部变量 只在函数体 局部名称空间有效
print(input)
func() #alex
print(input) #barry ###例子2
def func1():
print(111) def func2(): #函数加载时 只加载函数名 不执行函数
print(222)
func1() def func3(): #函数加载时 只加载函数名 不执行函数
print(333)
func2() print(444)
func1()
print(555)
# 结果:444 111 555 ###例子3
def func1():
print(111) def func2():
print(222)
func1() def func3():
print(333)
func2() print(444)
func3()
print(555)
# 结果:444 333 222 111 555 ###例子4
def wraaper():
print(222)
def inner():
print(111)
print(444)
inner()
print(333)
wraaper()
# 结果:222 444 111 333
示例
内置函数 locals() globals()
name = 'alex'
age = 46
def func():
sex = '男'
hobby = '女'
print(globals()) # 返回一个字典:全局作用域的所有内容 print(locals()) # 当前位置的内容
func()
print(globals()) # 返回一个字典:全局作用域的所有内容
print(locals()) # 当前位置的内容
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x000001E308500DD8>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'C:/Users/Administrator/Desktop/CMDB/95/autoclient/test.py', '__cached__': None, 'name': 'alex', 'age': 46, 'func': <function func at 0x000001E3084BC1E0>}
{'sex': '男', 'hobby': '女'}
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x000001E308500DD8>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'C:/Users/Administrator/Desktop/CMDB/95/autoclient/test.py', '__cached__': None, 'name': 'alex', 'age': 46, 'func': <function func at 0x000001E3084BC1E0>}
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x000001E308500DD8>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'C:/Users/Administrator/Desktop/CMDB/95/autoclient/test.py', '__cached__': None, 'name': 'alex', 'age': 46, 'func': <function func at 0x000001E3084BC1E0>}
结果
函数名的运用
def func():
print(666)
1. 函数名是一个特殊的变量 函数名() 执行此函数 # func()
2. 函数名可以当做变量进行赋值运算。
def func():
print(666)
age1 = 12
age2 = age1
age3 = age2
print(age3)
f = func
f()
# 下面不能执行
# age1 = 33
# age1()
print(globals()) 666
12
666 {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x00000224BA380DD8>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'C:/Users/Administrator/Desktop/CMDB/95/autoclient/test.py', '__cached__': None, 'func': <function func at 0x00000224BA672378>, 'age1': 12, 'age2': 12, 'age3': 12, 'f': <function func at 0x00000224BA672378>}
其中:func': <function func at 0x00000224BA672378> == 'f': <function func at 0x00000224BA672378>
'age1': 12, 'age2': 12, 'age3': 12,
3. 函数名可以作为容器型数据的元素。
def func():
print(666)
def func1():
print(777)
def func2():
print(888)
def func3():
print(999)
# a = 1
# b = 2
# c = 3
# d = 4
# l1 = [a, b, c, d]
l1 = [func, func1, func2, func3]
# for i in l1:
# i()
dic = {
1: func,
2: func1,
3: func2,
4: func3,
}
dic[1]()
dic[2]()
dic[3]()
# while 1:
# num = input('请输入序号:').strip()
# if num == '1':
# func()
# elif num == '2':
while 1:
num = input('请输入序号:').strip()
num = int(num)
dic[num]()
4.函数名可以作为函数的参数。
def func1():
print(111)
def func2(x):
x()
print(222)
5. 函数名可以作为函数的返回值。
def func1():
print(111)
def func2(x):
print(222)
return x
ret = func2(func1)
ret()
def func():
print(1111)
func()
f = func
func = 1
print(func)
print(f)
age1 = 12
age2 = age1
age3 = age2
age2 = 46
print(age1,age2,age3) # 12 46 12
age1 = [1,2,3]
age2 = age1
age1.append(666)
print(age1,age2) D:\python\python37\python.exe C:/Users/Administrator/Desktop/CMDB/95/autoclient/test.py
1111
1
<function func at 0x000001F1E63DC1E0>
12 46 12
[1, 2, 3, 666] [1, 2, 3, 666] Process finished with exit code 0
函数名作为变量问题
# global nonlocal
# global
#1,声明一个全局变量。
# def f():
# print(name)
# def func():
# global name
# name = 'alex'
# func()
# f()
# print(name)
# print(globals())
# 2,修改一个全局变量。
# 原因:局部作用域只能引用全局变量而不能改变全局变量。
count = 1
def func1():
global count
count += 1
print(count)
func1()
print(count)
# nonlocal: 子级函数可以通过nonlocal修改父级(更高级非全局变量)函数的变量。
# 现象:子级函数可以引用父级函数的变量但是不能修改。
def func():
count = 1
def func1():
def inner():
nonlocal count
count += 1
print(count) # 2
print(count) # 1
inner()
print(count) # 2
func1()
func()
count = 1
def func1():
def inner():
nonlocal count
count += 1
print(count)
inner() func1()
day03深浅拷贝、文件操作和函数初识的更多相关文章
- python笔记2小数据池,深浅copy,文件操作及函数初级
小数据池就是在内存中已经开辟了一些特定的数据,经一些变量名直接指向这个内存,多个变量间公用一个内存的数据. int: -5 ~ 256 范围之内 str: 满足一定得规则的字符串. 小数据池: 1,节 ...
- python学习day7 深浅拷贝&文件操作
4-4 day07 深浅拷贝&文件操作 .get()用法 返回指定键的值,如果值不在字典中返回默认值. info={'k1':'v1,'K2':'v2'}mes = info.get('k1' ...
- php中文件操作常用函数有哪些
php中文件操作常用函数有哪些 一.总结 一句话总结:读写文件函数 判断文件或者目录是否存在函数 创建目录函数 file_exists() mkdir() file_get_content() fil ...
- python 文件操作: 文件操作的函数, 模式及常用操作.
1.文件操作的函数: open("文件名(路径)", mode = '模式', encoding = "字符集") 2.模式: r , w , a , r+ , ...
- python 文件操作的函数
1. 文件操作的函数 open(文件名(路径), mode="?", encoding="字符集") 2. 模式: r, w, a, r+, w+, a+, r ...
- PHP文件操作功能函数大全
PHP文件操作功能函数大全 <?php /* 转换字节大小 */ function transByte($size){ $arr=array("B","KB&quo ...
- python基础知识-7-内存、深浅、文件操作
python其他知识目录 1.一些对内存深入理解的案例 以下列举列表,列表/字典/集合这些可变类型都是一样的原理 变量是个地址,指向存储数据的内存空间的地址,它的实质就相当于c语言里的指针.变量和数据 ...
- Python基础-week03 集合 , 文件操作 和 函数详解
一.集合及其运算 1.集合的概念 集合是一个无序的,不重复的数据组合,它的主要作用如下 *去重,把一个列表变成集合,就自动去重了 *关系测试,测试两组数据之前的交集.并集.差集.子集.父级.对称差集, ...
- Python全栈开发之3、深浅拷贝、变量和函数、递归、函数式编程、内置函数
一.深浅拷贝 1.数字和字符串 对于 数字 和 字符串 而言,赋值.浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址. import copy # 定义变量 数字.字符串 # n1 = 123 n1 ...
随机推荐
- C# 实现串口发送数据(不用串口控件版)
参考:https://blog.csdn.net/mannix_lei/article/details/79979432 https://www.cnblogs.com/ElijahZeng/p/76 ...
- 部署项目到tomcat时 访问项目404的问题总结
使用tomcat服务器运行项目之前 需要把项目发布到(部署)tomcat上,然后启动服务器 运行项目 今天把以往正常运行的项目发布之后,运行时 竟然出现404 关键还不是我路径写错了 而 ...
- 洛谷 P1768 天路
P1768 天路 题目描述 “那是一条神奇的天路诶~,把第一个神犇送上天堂~”,XDM先生唱着这首“亲切”的歌曲,一道猥琐题目的灵感在脑中出现了. 和C_SUNSHINE大神商量后,这道猥琐的题目终于 ...
- ABCDE
ABCDE A-Artificial intelligence 人工智能 B-Block chain 区块链 C-Cloud 云 D-Big Data 大数据 E-Ecology 互联网生态是以互联网 ...
- KVO---视图间数据的传递:标签显示输入的内容【多个视图中】
RootViewController.m #import "ModalViewController.h" @interface RootViewController () @end ...
- Linux命令(七)——网络配置和网络通信
在使用网络前,需要对linux主机进行基本的网络配置,配置后可以使该主机能够同其他主机进行正常的通信. 一.网络配置 1.ifcfg-ethn网络配置文件 所有的网络接口配置文件均存放在/etc/sy ...
- SQL SEVER 元年是1900年
用SQL语句求 本月第一天,怎么写? 可以这样写: SELECT DATEADD(mm,DATEDIFF(mm,0,GETDATE()),0); 按照日期函数DATEDIFF的定义,第二个参数是开始日 ...
- 0x58B 四边形不等式
bzoj1563: [NOI2009]诗人小G 还有优化二维区间DP的,形如f[i][j]min{f[i][k]+f[k][j+1]+val(i,j)} 其中val满足四边形不等式,而且对于任意a&l ...
- Spring SSM 框架
IDEA 整合 SSM 框架学习 http://www.cnblogs.com/wmyskxz/p/8916365.html 认识 Spring 框架 更多详情请点击这里:这里 Spring 框架是 ...
- 【POJ 2286】 The Rotation Game
[题目链接] http://poj.org/problem?id=2286 [算法] IDA* [代码] #include <algorithm> #include <bitset& ...