HDFS架构与原理
HDFS
HDFS 全称hadoop分布式文件系统,其最主要的作用是作为 Hadoop 生态中各系统的存储服务
特点
优点
• 高容错、高可用、高扩展 -数据冗余多副本,副本丢失后自动恢复 -NameNode HA、安全模式 -10K节点规模
• 海量数据存储 -典型文件大小GB~TB,百万以上文件数量 PB以上数据规模
• 构建成本低、安全可靠 -构建在廉价的商用服务器上 -提供了容错和恢复机制
• 适合大规模离线批处理 -流式数据访问 -数据位置暴露给计算框架
缺点
• 不适合低延迟数据访问
• 不适合大量小文件存储 -元数据占用NameNode大量内存空间 -磁盘寻道时间超过读取时间
• 不支持并发写入 -一个文件同时只能有一个写入者
• 不支持文件随机修改 -仅支持追加写入
架构图
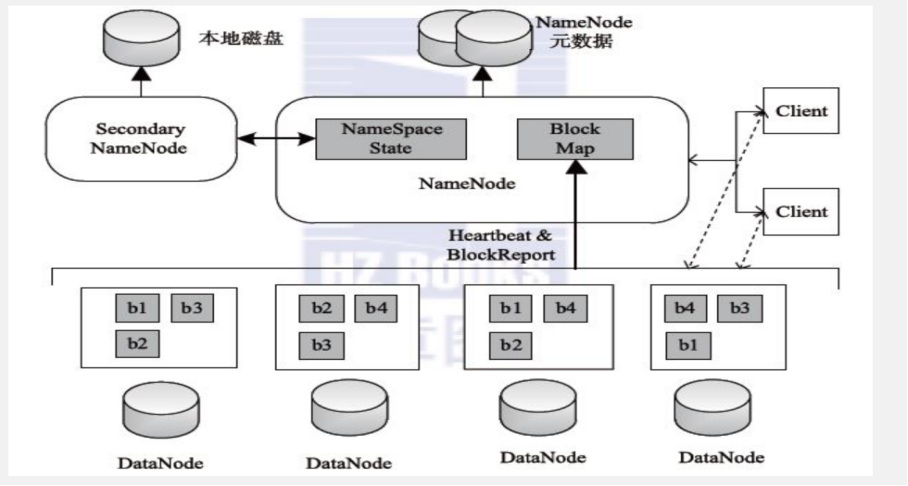
Namenode 主节点
管理HDFS文件系统的命名空间、维护元数据信息
处理客户端读写请求
Datanode 从节点
存储数据(Block)
集群启动时, DataNode向NameNode汇报Block列表信息集群运行期间, 通过心跳机制定期(默认3秒) 与NameNode保持通信
Secondary node
主要存在于HDFS1.x架构当中, 并不是NameNode的热备,只是在namende发生故障的时候快速切换
辅助NameNode完成元数据文件fsimage、 edits的定期合并
HDFS存储机制:元数据
元数据(Metadata)
信息存放在NameNode内存当中 包含:HDFS中文件及目录的基本属性信息(如拥有者、权限信息创建时间等)、文件有哪些block构成、 以及block的位置存放信息。
元数据信息持久化
fsimage(元数据镜像检查点文件)
edits(编辑日志文件,记录写操作)
注:block的位置信息并不会做持久化,仅仅只是在DataNode启动汇报给NameNode,存放在NameNode内存空间内
HDFS存储机制:block
Block
• Block是HDFS的最小存储单元 • Block的大小 -默认大小:128M(HDFS 1.x中,默认64M)
-若文件大小不足128M,则会单独成为一个block -实质上就是Linux相应目录下的普通文件
-名称格式:blk_xxxxxxx
• Block和元数据分开存储,Block存储于DataNode,元数据存储于NameNode
• Block多副本 -默认副本数:3
-机架感知:将副本存储到不同的机架上,实现数据的高容错
-副本均匀分布:提高访问带宽和读取性能,实现负载均衡,避免出现数据倾斜
HDFS存储机制:读写流程

写流程
• 客户端发送创建文件指令给分布式文件系统
• 文件系统告知namenode • 检查权限,查看文件是否存在
• EditLog增加记录 • 返回输出流对象
• 客户端往输出流中写入数据,分成一个个数据包
• 根据namenode分配,输出流往datanode写数据
• 多个datanode构成一个管道pipeline,输出流写第一个,后面的转发
• 每个datanode写完一个块后,返回确认信息
• 写完数据,关闭输出流
• 发送完成信号给namenode
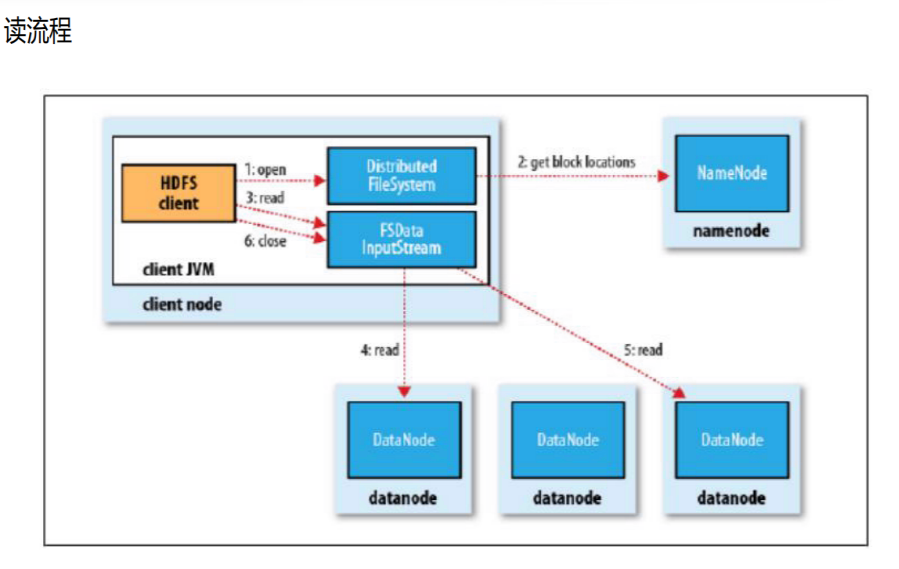
读流程
• 客户端发送打开文件指令给分布式文件系统
• 文件系统访问namenode,获得这个文件的数据块位置列表,返回输入流对象
• 客户端从输入流中读取数据
• 输入流从各个datanode读取数据
• 关闭输入流
HDFS架构与原理的更多相关文章
- HDFS架构及原理
原文链接:HDFS架构及原理 引言 进入大数据时代,数据集的大小已经超过一台独立物理计算机的存储能力,我们需要对数据进行分区(partition)并存储到若干台单独的计算机上,也就出现了管理网络中跨多 ...
- 2本Hadoop技术内幕电子书百度网盘下载:深入理解MapReduce架构设计与实现原理、深入解析Hadoop Common和HDFS架构设计与实现原理
这是我收集的两本关于Hadoop的书,高清PDF版,在此和大家分享: 1.<Hadoop技术内幕:深入理解MapReduce架构设计与实现原理>董西成 著 机械工业出版社2013年5月出 ...
- 2、Hdfs架构设计与原理分析
文章目录 1.Hadoop架构 2.HDFS体系架构 2.1NameNode 2.1.1元数据信息 2.1.2NameNode文件操作 2.1.3NameNode副本 2.1.4NameNode心跳机 ...
- HBase的基本架构及其原理介绍
1.概述:最近,有一些工程师问我有关HBase的基本架构的问题,其实这个问题仅仅说架构是非常简单,但是需要理解.在这里,我觉得可以用HDFS的架构作为借鉴.(其实像Hadoop生态系统中的大部分组建的 ...
- 大数据技术hadoop入门理论系列之二—HDFS架构简介
HDFS简单介绍 HDFS全称是Hadoop Distribute File System,是一个能运行在普通商用硬件上的分布式文件系统. 与其他分布式文件系统显著不同的特点是: HDFS是一个高容错 ...
- HDFS 架构简述
HDFS 架构简述 Hadoop分布式文件系统(HDFS)是一个分布式的文件系统,运行在廉价的硬件上.它与现有的分布式文件系统有很多相似之处.然而与其他的分布式文件系统的差异也是显着的.HDFS是高容 ...
- Hbase架构与原理
Hbase架构与原理 HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang所撰写的Google论文"Bigtable:一个结构化数据的分布式存储系统".就 ...
- Spark基本架构及原理
Hadoop 和 Spark 的关系 Spark 运算比 Hadoop 的 MapReduce 框架快的原因是因为 Hadoop 在一次 MapReduce 运算之后,会将数据的运算结果从内存写入到磁 ...
- storm架构及原理
storm 架构与原理 1 storm简介 1.1 storm是什么 如果只用一句话来描述 storm 是什么的话:分布式 && 实时 计算系统.按照作者 Nathan Marz 的说 ...
随机推荐
- Git的初始化设置
Git安装成功之后,新建一个初始化的仓库以及配置GitHub仓库 Git配置GitHub账户 安装完成之后要进行git的配置,这里配置的是GitHub账户 MisSa@DESKTOP-PIQ06QO ...
- NTP同步底层实现
RFC http://www.ietf.org/rfc/rfc5905.txt https://www.eecis.udel.edu/~mills/ntp/html/select.html https ...
- ES6之用let,const和用var来声明变量的区别
var(掌握) 不区分变量和常量 用var声明的变量都是变量,都是可变的,我们可以随便对它进行运算操作.这样当多个人进行同一个项目时,区分变量和常量会越来越难,一不小心就会把设计为常量的数据更改了 ...
- NOIP2018提高组金牌训练营——搜索专题
NOIP2018提高组金牌训练营——搜索专题 1416 两点 福克斯在玩一款手机解迷游戏,这个游戏叫做”两点”.基础级别的时候是在一个n×m单元上玩的.像这样: 每一个单元有包含一个有色点.我们将用不 ...
- reac实现控制输入框字符长度
reac实现控制输入框字符长度 代码思路:
- jvm 虚拟机参数_栈内存分配
1.参数 -Xss 指定线程最大的栈空间,整个参数也直接决定了函数可调用的最大深度 2.测试代码 private static int count; public static void addCou ...
- 2015 Multi-University Training Contest 4 hdu 5338 ZZX and Permutations
ZZX and Permutations Time Limit: 6000/3000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/O ...
- javascript-js中技巧集合
1.值的转换 在JavaScript中,一共有两种类型的值:原始值(primitives)和对象值(objects).原始值有:undefined, null, 布尔值(booleans), 数字(n ...
- angular-模块Module
模块定义了一个应用程序. 模块是应用程序中不同部分的容器. 模块是应用控制器的容器. 控制器通常属于一个模块. <div ng-app="myApp" runoob-dire ...
- 前端防止button被多次点击
前端的部分逻辑有时候控制前端的显示.比方记录收藏数目等等.有时候多次反复点击会造成前端显示的bug.所以须要有部分逻辑推断去筛除掉反复多次的点击. 实现部分代码例如以下,主要是通过setTimeout ...