redis 从0到1 linux下的安装使用 数据类型 以及操作指令 一
安装 redis 到 /usr/目录下 我这里安装的是redis-3.2.9.tar.gz
tar zxvf redis-3.2.9.tar.gz -C /usr
然后进行 执行编译命令 make 执行安装 make install
进入redis目录 ll查看所有文件
将 redis.conf文件 移动到usr/local/redis/etc目录下
再进入redis/src 目录 将以下文件移动到 usr/local/redis/bin目录下 方便以后管理
此时进入 usr/local/redis/bin目录下 执行------- 如果需要带参数配置文件启动,则在redis启动命令 后面加上 配置文件的路径
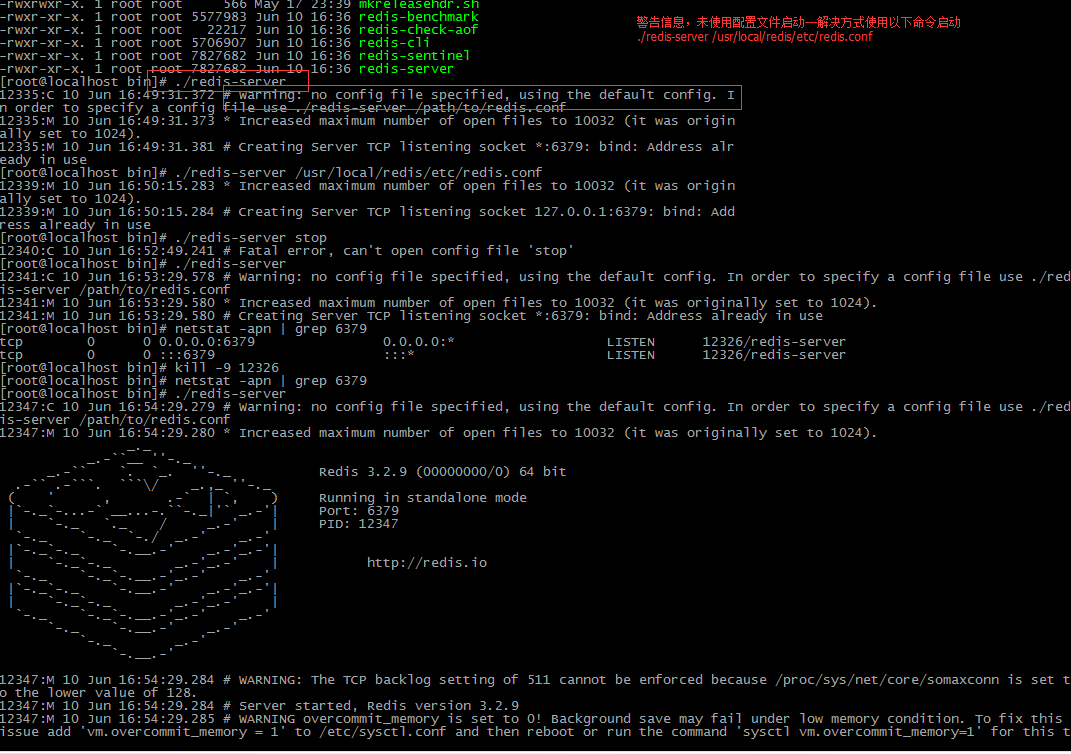
说明启动成 默认端口为6379 如果启动失败
12339:M 10 Jun 16:50:15.283 * Increased maximum number of open files to 10032 (it was originally set to 1024).
12339:M 10 Jun 16:50:15.284 # Creating Server TCP listening socket 127.0.0.1:6379: bind: Address already in use
说明 6379端口被占用 使用netstat -apn | grep 6379 然后kill -9 进程ID 再此启动
# 守护进程模式
# 默认情况下 redis 不是作为守护进程运行的,如果你想让它在后台运行,你就把它改成 yes
# 当redis作为守护进程运行的时候,它会写一个 pid 到 /var/run/redis.pid 文件里面
daemonize yes # 当redis作为守护进程运行的时候,它会把 pid 默认写到 /var/run/redis.pid 文件里面,但是你可以在这里自己制定它的文件位置
pidfile /var/run/redis.pid # 监听端口号,默认为 6379,如果你设为 0 ,redis 将不在 socket 上监听任何客户端连接。
port 6379 # TCP接收队列长度,受/proc/sys/net/core/somaxconn和tcp_max_syn_backlog这两个内核参数的影响
# 在高并发的环境下,你需要把这个值调高以避免客户端连接缓慢的问题。
tcp-backlog 511 # 一个客户端空闲多少秒后关闭连接(0代表禁用,永不关闭)
timeout 0 # 如果非零,则设置SO_KEEPALIVE选项来向空闲连接的客户端发送ACK
# 推荐一个合理的值就是60秒
tcp-keepalive 60 # 指定服务器调试等级
# 可能值:
# debug (大量信息,对开发/测试有用)
# verbose (很多精简的有用信息,但是不像debug等级那么多)
# notice (适量的信息,基本上是你生产环境中需要的)
# warning (只有很重要/严重的信息会记录下来)
loglevel notice # 指定日志文件名和保存位置
logfile "./redis.log" # 设置数据库个数
# 默认数据库是 DB 0,你可以在每个连接上使用 select <dbid> 命令选择一个不同的数据库,但是 dbid 必须是一个介于 0 到 databasees - 1 之间的值
databases 16 #根据给定的时间间隔和写入次数将数据保存到磁盘
# 900秒(15分钟)之后,且至少1次变更
# 300秒(5分钟)之后,且至少10次变更
# 60秒之后,且至少10000次变更
save 900 1
save 300 10
save 60 10000 # 默认如果开启RDB快照(至少一条save指令)并且最新的后台保存失败,Redis将会停止接受写操作
# 这将使用户知道数据没有正确的持久化到硬盘,否则可能没人注意到并且造成一些灾难
# 如果后台保存进程重新启动工作了,redis 也将自动的允许写操作
stop-writes-on-bgsave-error yes # 当导出到 .rdb 数据库时是否用LZF压缩字符串对象,默认都设为 yes
rdbcompression yes # 是否校验rdb文件,版本5的RDB有一个CRC64算法的校验和放在了文件的最后。这将使文件格式更加可靠。
rdbchecksum yes # 持久化数据库的文件名
dbfilename dump.rdb # 工作目录
# 例如上面的 dbfilename 只指定了文件名,但是它会写入到这个目录下。这个配置项一定是个目录,而不能是文件名
dir ./ # 当master服务设置了密码保护时,slav服务连接master的密码
masterauth !@#$%^&* # 当一个slave失去和master的连接,或者同步正在进行中,slave的行为可以有两种表现:
#
# 1) 如果 slave-serve-stale-data 设置为 "yes" (默认值),slave会继续响应客户端请求,
# 可能是正常数据,或者是过时了的数据,也可能是还没获得值的空数据。
# 2) 如果 slave-serve-stale-data 设置为 "no",slave会回复"正在从master同步
# (SYNC with master in progress)"来处理各种请求,除了 INFO 和 SLAVEOF 命令。
slave-serve-stale-data yes # 你可以配置salve实例是否接受写操作。可写的slave实例可能对存储临时数据比较有用(因为写入salve的数据在同master同步之后将很容易被删除)
slave-read-only yes # 是否在slave套接字发送SYNC之后禁用 TCP_NODELAY?
# 如果你选择“yes”Redis将使用更少的TCP包和带宽来向slaves发送数据。但是这将使数据传输到slave上有延迟,Linux内核的默认配置会达到40毫秒
# 如果你选择了 "no" 数据传输到salve的延迟将会减少但要使用更多的带宽
repl-disable-tcp-nodelay no # slave的优先级是一个整数展示在Redis的Info输出中。如果master不再正常工作了,哨兵将用它来选择一个slave提升为master
# 优先级数字小的salve会优先考虑提升为master,所以例如有三个slave优先级分别为10,100,25,哨兵将挑选优先级最小数字为10的slave。
# 0作为一个特殊的优先级,标识这个slave不能作为master,所以一个优先级为0的slave永远不会被哨兵挑选提升为master
slave-priority 100 # 密码验证
# 警告:因为Redis太快了,所以外面的人可以尝试每秒150k的密码来试图破解密码。这意味着你需要一个高强度的密码,否则破解太容易了
requirepass !@#$%^&* # redis实例最大占用内存,不要用比设置的上限更多的内存。一旦内存使用达到上限,Redis会根据选定的回收策略(参见:maxmemmory-policy)删除key
maxmemory 3gb # 最大内存策略:如果达到内存限制了,Redis如何选择删除key。你可以在下面五个行为里选:
# volatile-lru -> 根据LRU算法删除带有过期时间的key。
# allkeys-lru -> 根据LRU算法删除任何key。
# volatile-random -> 根据过期设置来随机删除key, 具备过期时间的key。
# allkeys->random -> 无差别随机删, 任何一个key。
# volatile-ttl -> 根据最近过期时间来删除(辅以TTL), 这是对于有过期时间的key
# noeviction -> 谁也不删,直接在写操作时返回错误。
maxmemory-policy volatile-lru # 默认情况下,Redis是异步的把数据导出到磁盘上。这种模式在很多应用里已经足够好,但Redis进程
# 出问题或断电时可能造成一段时间的写操作丢失(这取决于配置的save指令)。
#
# AOF是一种提供了更可靠的替代持久化模式,例如使用默认的数据写入文件策略(参见后面的配置)
# 在遇到像服务器断电或单写情况下Redis自身进程出问题但操作系统仍正常运行等突发事件时,Redis
# 能只丢失1秒的写操作。
#
# AOF和RDB持久化能同时启动并且不会有问题。
# 如果AOF开启,那么在启动时Redis将加载AOF文件,它更能保证数据的可靠性。
appendonly no # aof文件名
appendfilename "appendonly.aof" # fsync() 系统调用告诉操作系统把数据写到磁盘上,而不是等更多的数据进入输出缓冲区。
# 有些操作系统会真的把数据马上刷到磁盘上;有些则会尽快去尝试这么做。
#
# Redis支持三种不同的模式:
#
# no:不要立刻刷,只有在操作系统需要刷的时候再刷。比较快。
# always:每次写操作都立刻写入到aof文件。慢,但是最安全。
# everysec:每秒写一次。折中方案。
appendfsync everysec # 如果AOF的同步策略设置成 "always" 或者 "everysec",并且后台的存储进程(后台存储或写入AOF
# 日志)会产生很多磁盘I/O开销。某些Linux的配置下会使Redis因为 fsync()系统调用而阻塞很久。
# 注意,目前对这个情况还没有完美修正,甚至不同线程的 fsync() 会阻塞我们同步的write(2)调用。
#
# 为了缓解这个问题,可以用下面这个选项。它可以在 BGSAVE 或 BGREWRITEAOF 处理时阻止主进程进行fsync()。
#
# 这就意味着如果有子进程在进行保存操作,那么Redis就处于"不可同步"的状态。
# 这实际上是说,在最差的情况下可能会丢掉30秒钟的日志数据。(默认Linux设定)
#
# 如果你有延时问题把这个设置成"yes",否则就保持"no",这是保存持久数据的最安全的方式。
no-appendfsync-on-rewrite yes # 自动重写AOF文件
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb # AOF文件可能在尾部是不完整的(这跟system关闭有问题,尤其是mount ext4文件系统时
# 没有加上data=ordered选项。只会发生在os死时,redis自己死不会不完整)。
# 那redis重启时load进内存的时候就有问题了。
# 发生的时候,可以选择redis启动报错,并且通知用户和写日志,或者load尽量多正常的数据。
# 如果aof-load-truncated是yes,会自动发布一个log给客户端然后load(默认)。
# 如果是no,用户必须手动redis-check-aof修复AOF文件才可以。
# 注意,如果在读取的过程中,发现这个aof是损坏的,服务器也是会退出的,
# 这个选项仅仅用于当服务器尝试读取更多的数据但又找不到相应的数据时。
aof-load-truncated yes # Lua 脚本的最大执行时间,毫秒为单位
lua-time-limit 5000 # Redis慢查询日志可以记录超过指定时间的查询
slowlog-log-slower-than 10000 # 这个长度没有限制。只是要主要会消耗内存。你可以通过 SLOWLOG RESET 来回收内存。
slowlog-max-len 128 # redis延时监控系统在运行时会采样一些操作,以便收集可能导致延时的数据根源。
# 通过 LATENCY命令 可以打印一些图样和获取一些报告,方便监控
# 这个系统仅仅记录那个执行时间大于或等于预定时间(毫秒)的操作,
# 这个预定时间是通过latency-monitor-threshold配置来指定的,
# 当设置为0时,这个监控系统处于停止状态
latency-monitor-threshold 0 # Redis能通知 Pub/Sub 客户端关于键空间发生的事件,默认关闭
notify-keyspace-events "" # 当hash只有少量的entry时,并且最大的entry所占空间没有超过指定的限制时,会用一种节省内存的
# 数据结构来编码。可以通过下面的指令来设定限制
hash-max-ziplist-entries 512
hash-max-ziplist-value 64 # 与hash似,数据元素较少的list,可以用另一种方式来编码从而节省大量空间。
# 这种特殊的方式只有在符合下面限制时才可以用
list-max-ziplist-entries 512
list-max-ziplist-value 64 # set有一种特殊编码的情况:当set数据全是十进制64位有符号整型数字构成的字符串时。
# 下面这个配置项就是用来设置set使用这种编码来节省内存的最大长度。
set-max-intset-entries 512 # 与hash和list相似,有序集合也可以用一种特别的编码方式来节省大量空间。
# 这种编码只适合长度和元素都小于下面限制的有序集合
zset-max-ziplist-entries 128
zset-max-ziplist-value 64 # HyperLogLog稀疏结构表示字节的限制。该限制包括
# 16个字节的头。当HyperLogLog使用稀疏结构表示
# 这些限制,它会被转换成密度表示。
# 值大于16000是完全没用的,因为在该点
# 密集的表示是更多的内存效率。
# 建议值是3000左右,以便具有的内存好处, 减少内存的消耗
hll-sparse-max-bytes 3000 # 启用哈希刷新,每100个CPU毫秒会拿出1个毫秒来刷新Redis的主哈希表(顶级键值映射表)
activerehashing yes # 客户端的输出缓冲区的限制,可用于强制断开那些因为某种原因从服务器读取数据的速度不够快的客户端
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60 # 默认情况下,“hz”的被设定为10。提高该值将在Redis空闲时使用更多的CPU时,但同时当有多个key
# 同时到期会使Redis的反应更灵敏,以及超时可以更精确地处理
hz 10
# 当一个子进程重写AOF文件时,如果启用下面的选项,则文件每生成32M数据会被同步
aof-rewrite-incremental-fsync yes
内容摘至http://www.cnblogs.com/kreo/p/4423362.html
进入redis 客户端

------------------------------redis的数据类型 ,以及操作

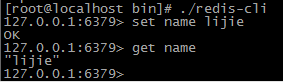
启动redis-cli 客户端 set name lijie 设置key(name)的value(lijie) 获取name的值 get name key重复 会覆盖原来的内容
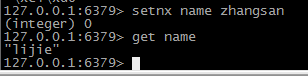
----命令 setnx key value 此命令 为判断操作 如果key存在 则返回0 不更新 如果key不存在 则进行插入 “nx”代表 no exist 不存在
---命令 setex key time value 设置一个key-value键值对 并指定过期时间 time单位为秒 到达指定时间后 这个键值对会失效

---命令 setrange key [index] value 替换命令 将 key的值 从指定的下标开始 替换成指定的value 返回替换后字符串的长度?

---命令 mset msetnx 格式 :命令 key vlaue ...key vlaue

--命令getset 获取旧值 并设置新值

--getrange  获取指定位置的 key值
获取指定位置的 key值
 获取多个值 不存在返回nil
获取多个值 不存在返回nil
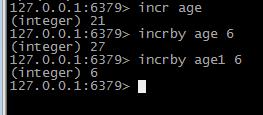
------------命令 incr自增 返回自增后的结果 incrby 加法运算 加上指定的值 若key 不存在 则默认key为0 并进行加法运算 若数据类型非integer 则报错
(error) ERR value is not an integer or out of range
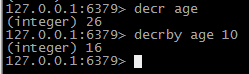
-----------自减 减去指定值 返回计算后的新值 “decr key value “ ” decrby key value“ 示例
--------append 字符串 追加vlaue 返回增加后的字符串长度

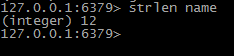
0----------------获取字符串长度 strlen key
del 删除某个string数据 del key
--------------------------------hashes数据类型 -----------------------------------------------------------

操作与String类型 类似 hset设置 hget获取 hmset批量设置 hmget批量获取 hsetnx如果存在则返回0 如果不存在 则创建这个hash

-hmset hmget

判断hashes的某个字段是否存在 hexists user name 存在返回1 不存在 返回0
hashes的所有字段 hlen user 返回3 如果user 不存在 则返回0
hdel 删除 字段 hdel user age ; 如果字段不存在 返回0 如果将一个hashes的所有字段删除 那么这个hashes也就没删除了
hkeys 获取所有字段
hvals获取所有的value 值
hgetall 获取一个hashes类型的所有字段 和value值

-------------------lists类型----------

特点 先进后出
--lpush user nage age; 向lists头部插入2个数据 如果这个lists不存在则创建 存在则插入,如果插入多个值 如示例 则age为头部元素,name为尾部元素
如果数据库存在其他类型的同名key值 则报错 (error) WRONGTYPE Operation against a key holding the wrong kind of value
lpop user 将user中尾部元素 弹出 若最后一个元素被弹出 则删除这个 lists链表
rpop 弹出头部第一个元素的值 如果这个lists只有一个值 则删除这个lists
 获取这个链表所有元素 ,star 开始位置 stop 结束位置 stop位置如果超标 只返回lists中存在的值
获取这个链表所有元素 ,star 开始位置 stop 结束位置 stop位置如果超标 只返回lists中存在的值
rpush 在链表的尾部添加数据
 示例
示例

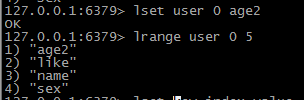
修改指定位置的值  lset user 0 age2
lset user 0 age2
删除重复的值  从头部开始 删除指定数量count 重复的值 value 当count为负数则从尾部开始删除 若count数大于lists中存在value的个数 则只删除lists中存在的值
从头部开始 删除指定数量count 重复的值 value 当count为负数则从尾部开始删除 若count数大于lists中存在value的个数 则只删除lists中存在的值
保留指定位置的值,删除其他值 格式

从源list弹出第一个元素 并追加到第二个list上(如果目标list不存在则自动创建),返回被弹出的元素值 ,如果源list不存在则返回nil 若源list为只有一个元素 弹出后删除

lindex user 0 获取list指定位置上的内容 如果list 或者指定位置上的元素不存在 返回nil 
llen 获取list的长度 list不存在返回0
--------------------------set集合---------------------------

sadd添加元素 老规矩 不存在 就先创建再添加 可以一次添加多个元素 重复元素会被剔除
smembers key 查看set集合中所有的元素
srem key value 从set集合中移除指定元素 移除成功返回受影响元素的个数 元素不存在返回0
spop key 随机删除一个元素
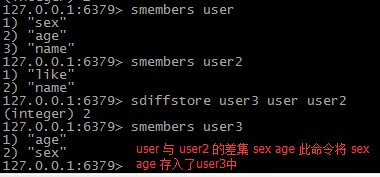
sdiff key key1 key2获取 key 与key1 key2没有交集的元素 也就是说key1 key2中不存在的元素 如果key中的元素 在key1 key2中都存在 则提示 
sdiffstore 返回所有给定 key 与第一个 key 的差集,并将结果存为另一个 key 
sinter 获取交集 获取多个set中都存在的元素 没有交集则提示
sinterstore 获取交集 存入 另外一个key中 destination 为交集存放的位置 其余key则是取交集的所有集合 
sunion 取并集 sunionstore 取并集并存入指定的key中
smove  移动 元素 到指定key
移动 元素 到指定key
scard key 返回key中元素的个数 不存在则返回0
sismember 测试元素是否存在key中
srandmember 随机返回一个key中的元素
-------------zset---------------简单理解成 java中的map集合 但此map的k 为 integer类型 v为redis中的string类型

zadd user 1 name 添加元素 到key中 不存在就创建
zrem key member 移除指定key中的元素
zincrby user 3 address  将 指位置 的 元素 插入到 key中 若元素存在 则元素的位置加上 指令的位置值
将 指位置 的 元素 插入到 key中 若元素存在 则元素的位置加上 指令的位置值

zrank 将zset集合的core进行从小到大的排序 然后返回指定元素 存在的位置
zrevrank 将zset集合的core进行从大到小的排序 然后返回指定元素 存在的位置

zrevrange key star stop 将zset集合的core进行从大到小的排序,然后返回指定位置的元素
zrangebyscore key min max 获取score为指定值的元素 若 指定 1-3 而score为2的元素 不存在 则返回 score 1和3的元素
zcount key min max 返回score 位置为指定位置元素的个数
zcared key 返回key中 vlaue元素的个数
zscore key member 返回元素在key中score位置
zremrangebyrank key star stop 以score进行从小到大的排序 删除位于指定位置的元素

zremrangebyscore key min max 删除 指定score位于指定位置的 元素
-------------最后疑点,,zset为什么允许 相同score 不同元素的值存在??
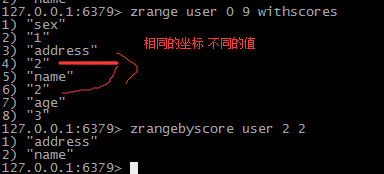
感谢红丸出品的redis实战 .pdf
redis 从0到1 linux下的安装使用 数据类型 以及操作指令 一的更多相关文章
- Linux下php安装Redis扩展
说明: 操作系统:CentOS php安装目录:/usr/local/php php.ini配置文件路径:/usr/local/php7/etc/php.ini Nginx安装目录:/usr/loca ...
- linux下php7安装memcached、redis扩展
linux下php7安装memcached.redis扩展 1.php7安装Memcached扩展 比如说我现在使用了最新的 Ubuntu 16.04,虽然内置了 PHP 7 源,但 memcache ...
- linux下如何安装mysql和redis
linux下如何安装mysql(mariadb) linux下如何安装软件? 1. yum安装软件也得注意,一个是配置yum源 1.我们当前的是阿里云的yum源(下载速度特别快) 通过 yum ins ...
- redis 在Linux下的安装与配置
redis在Linux下的安装与配置 by:授客 QQ:1033553122 测试环境 redis-3.0.7.tar.gz 下载地址: http://redis.io/download http: ...
- 使用redis客户端连接windows和linux下的redis并解决无法连接redis的问题
搭建环境:linux是centos7.4(请注意centos7以下版本的防火墙跟centos7以上的不同,使用redis客户端连接redis时会有区别,建议使用centos7以上版本) 一.下载red ...
- Redis总结(九)Linux环境如何安装redis
以前总结Redis 的一些基本的安装和使用,由于是测试方便,直接用的window 版的reids,并没有讲redis在linux下的安装.今天就补一下Linux环境如何安装redis. 大家可以这这里 ...
- Linux下yum安装MySQL
写这篇文章的原因是:在刚开始使用Linux操作系统时想要搭建LAMP环境,于是开始在Google和百度上各种寻找资料,碰到了不是很多的问题后,我决定写这篇文章总结一下在Linux下yum安装MySQL ...
- LINUX下编译安装PHP各种报错大集合
本文为大家整理汇总了一些linux下编译安装php各种报错大集合 ,感兴趣的同学参考下. nginx1.6.2-mysql5.5.32二进制,php安装报错解决: 123456 [root@clien ...
- Linux学习心得之 Linux下ant安装与使用
作者:枫雪庭 出处:http://www.cnblogs.com/FengXueTing-px/ 欢迎转载 Linux学习心得之 Linux下ant安装与使用 1. 前言2. ant安装3. 简单的a ...
随机推荐
- mysql去除字段内容的空格和换行回车
MySQL 去除字段中的换行和回车符 解决方法: UPDATE tablename SET field = REPLACE(REPLACE(field, CHAR(10), ''), ...
- [React] Modify file structure
In React app, you might create lots of components. We can use index.js to do both 'import' & 'ex ...
- Android系统编译环境初始化时Product产品的import-nodes过程
从运行make -f config,mk文件開始,config,mk作为当前的makefile文件.将会被make解析,一般make解析Makefile文件流程首先是载入当中include的各种其它m ...
- tky项目第②个半月总结
在上一篇半月总结中,介绍了tky项目的整体架构.项目的进展情况.项目的优势与开发中存在的问题等.今天来聊聊这半个月中,项目中发生的事情. 在这半个月中,项目中有了较大的突破:成功通过了国家评測中心的測 ...
- android 滚动栏下拉反弹的效果(相似微信朋友圈)
微信朋友圈上面的图片封面,QQ空间说说上面的图片封面都有下拉反弹的效果,这些都是使用滚动栏实现的.下拉,当松开时候.反弹至原来的位置.下拉时候能看到背景图片.那么这里简介一下这样的效果的实现. 本文源 ...
- 【u239】整数分解
Time Limit: 1 second Memory Limit: 128 MB [问题描述] 某些数能表示成为一些互不相同的整数的阶乘之和.如9=l!+2! +3!. 现在给定一个非负整数n,要求 ...
- 第二十一篇:基于WDM模型的AVStream驱动架构研究
基于WDM模型的AVStream驱动架构研 这篇论文2006年早就发表, 与当时开发这个驱动正好几乎相同的时间. 近期实际项目须要, 又回过头来将AVStre ...
- Python 第三方库的安装
1. pip 进入命令行,使用 pip install pip install numpy 2. 含有 setup.py 文件的第三方库 切换到 setup.py 所在的目录: python setu ...
- 使用 jquery 的 上传文件插件 uploadify 3.1 配合 java 来做一个简单的文件上次功能。并且在界面上有radio 的选择内容也要上传
使用 jquery 的 上传文件插件 uploadify 3.1 配合 java 来做一个简单的文件上次功能.并且在界面上有radio 的选择内容也要上传 uploadify 插件的 下载和文档地址 ...
- Hamcrest 总结
Junit JUnit框架用一组assert方法封装了一些常用的断言.这些assert方法可以帮我们简化单元测试的编写.这样的话,Junit就可以根据这些断言是否抛出 AssertionFailedE ...