javase(8)_集合框架_List、Set、Map
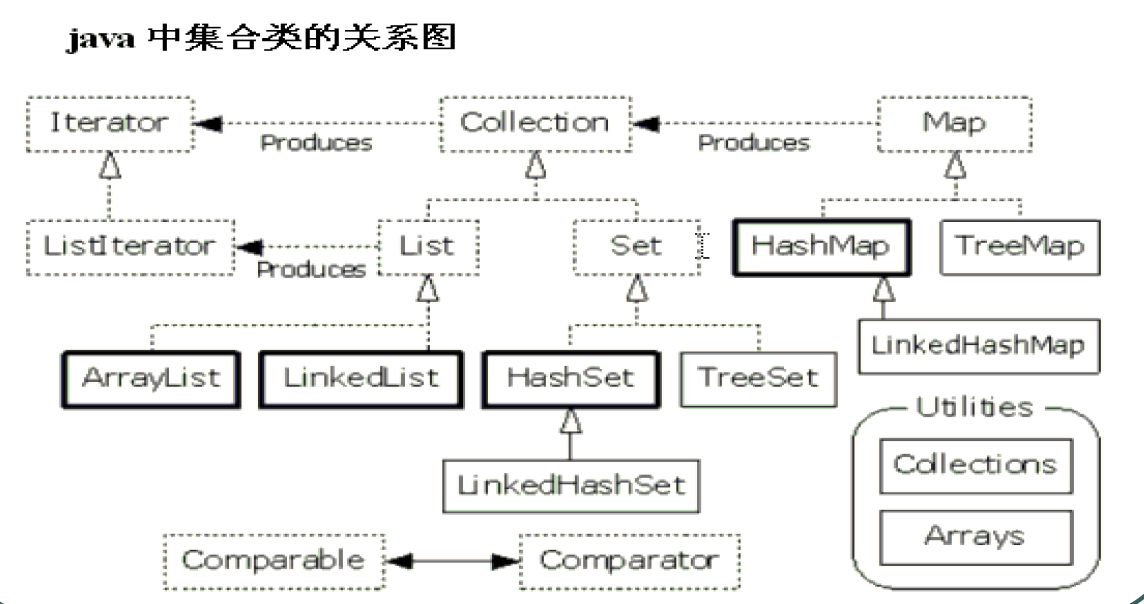
一、集合体系(不包括Queue体系)
二、ArrayList
ArrayList的属性
private transient Object[] elementData; //存储元素
private int size; //数组的长度
ArrayList三个构造方法
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);
}
}
public ArrayList() { //可变容
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
public ArrayList(Collection<? extends E> c) { //大多数集合类都有该构造方法,实现集合间的相互转换
elementData = c.toArray();
if ((size = elementData.length) != 0) {
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
this.elementData = EMPTY_ELEMENTDATA;
}
}
ArrayList常用方法
public int size() {
return size;
}
public boolean isEmpty() {
return size == 0;
}
public boolean contains(Object o) { //根据是否能查找到下标来判断有无
return indexOf(o) >= 0;
}
public int indexOf(Object o) { //可以存null,null.equals会抛异常,所有分开写
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
public int lastIndexOf(Object o) { //逆序查找数组
if (o == null) {
for (int i = size-1; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
for (int i = size-1; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
public Object[] toArray() {
return Arrays.copyOf(elementData, size);
}
public E get(int index) {
rangeCheck(index); //首先检查下标是否合法
return elementData(index);
}
public E set(int index, E element) {
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue; //返回了老的数据
}
public boolean add(E e) {
ensureCapacityInternal(size + 1); //自动扩容
elementData[size++] = e; //在尾部添加
return true;
}
public void add(int index, E element) {
rangeCheckForAdd(index); //检查下标
ensureCapacityInternal(size + );
//从指定源数组中复制一个数组,复制从指定的位置开始,到目标数组的指定位置结束
System.arraycopy(elementData, index, elementData, index + ,size - index);
elementData[index] = element;
size++;
}
public E remove(int index) {
rangeCheck(index);
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
public void clear() {
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}
Arraylist底层是使用数组作为数据结构来存储元素,元素的添加和删除时,都是通过System.arrayCopy()来实现,速度较慢;set,get直接通过下标定位,速度快;indexOf,lastIndexOf,contain查找或者remove移除一个元素时,都是通过逐个读取元素然后通过equals来实现.
三、LinkedList
LinkedList的属性
transient int size = ;
transient Node<E> first; //存储首节点和尾节点
transient Node<E> last;
Node定义
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
获取模一位置的元素(需要遍历)
Node<E> node(int index) {
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
给节点首部添加元素
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
List 接口的列表实现,允许所有元素(包括 null).LinkedList实现了Deque接口,可以将链列表用作堆栈、队列或双端队列.元素的添加和删除时,都是通过查找到要添加的位置,改变前后两个指针即可,相对于ArrayList的数组Copy效率高;set,get查找元素时,需要遍历到指定位置,比起ArrayList的直接定位效率较慢;indexOf,lastIndexOf,contain查找或者remove移除一个元素时,也是通过逐个读取元素然后通过equals来实现.
四、Set、Map
1.哈希表
哈希表是种数据结构,它可以提供快速的插入操作和查找操作,不论哈希表中有多少数据,插入和删除,只需要接近常量的时间即0(1)的时间级.哈希表运算得非常快,在计算机程序中,如果需要在一秒种内查找上千条记录通常使用哈希表(例如拼写检查器)哈希表的速度明显比树快,树的操作通常需要O(N)的时间级.哈希表不仅速度快,编程实现也相对容易.但是没有一种简便的方法可以以任何一种顺序〔例如从小到大〕遍历表中数据项.如果需要这种能力,就只能选择其他数据结构.如果不需要有序遍历数据,那么哈希表在速度和易用性方面是无与伦比的.
一般的线新表,树中,查找记录时需进行一系列和关键字的比较.这一类查找方法建立在“比较“的基础上,查找的效率依赖于查找过程中所进行的比较次数.理想的情况是能直接找到需要的记录,因此必须在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使每个关键字和结构中一个唯一的存储位置相对应.注意这里的存储位置只是表中的存储位置,并不是实际的物理地址,称作为Hash地址.
哈希表最常见的例子是以学生学号为关键字的成绩表,1号学生的记录位置在第一条,10号学生的记录位置在第10条...
如果我们以学生姓名为关键字,如何建立查找表,使得根据姓名可以直接找到相应记录呢?

用上述得到的数值作为对应记录在表中的位置,得到下表:

上面这张表即哈希表.
如果将来要查李秋梅的成绩,可以用上述方法求出该记录所在位置:
李秋梅:lqm 12+17+13=42 取表中第42条记录即可.
Hash算法
计算Hash地址的方法,就是Hash算法,也就是上例中计算学号的过程,对应到java中就是hashCode方法的实现就是hash算法,有很多种.
例1:字符串采用的hash算法
public int hashCode() {
int h = hash; //String中属性hash默认是0
if (h == 0 && value.length > 0) { //value是char[],String底层是char[]实现
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
例2:List集合中采用的hash算法
public int hashCode() {
int hashCode = 1;
for (E e : this) //this是当前集合
hashCode = 31*hashCode + (e==null ? 0 : e.hashCode());
return hashCode;
}
上例中:如果两个同学分别叫 刘丽 刘兰 该如何处理这两条记录?
这个问题是哈希表不可避免的,即冲突现象:对不同的关键字可能得到同一哈希地址,处理的方式有很多种.
HashMap中采用的是链地址法:将所有hash值相同的记录存储在同一线性链表中.
详细如下:
http://www.cnblogs.com/jiewei915/archive/2010/08/09/1796042.html
2、hashCode
Java中的hashCode方法就是根据一定的规则将与对象相关的信息(比如对象的存储地址,对象的字段等)映射成一个数值,这个数值称作为散列值.
在Java的Object类中有一个方法:public native int hashCode();根据这个方法的声明可知,该方法返回一个int类型的数值,并且是本地方法,因此在Object类中并没有给出具体的实现.
对于包含容器类型的程序设计语言来说,基本上都会涉及到hashCode.在Java中也一样,hashCode方法的主要作用是为了配合基于散列的集合一起正常运行,这样的散列集合包括HashSet、HashMap以及HashTable.
为什么这么说呢?考虑一种情况,当向集合中插入对象时,如何判别在集合中是否已经存在该对象了?(这些集合中不允许重复的元素存在)
也许大多数人都会想到调用equals方法来逐个进行比较,这个方法确实可行.但是如果集合中已经存在一万条数据或者更多的数据,如果采用equals方法去逐一比较,效率必然是一个问题.此时hashCode方法的作用就体现出来了,当集合要添加新的对象时,先调用这个对象的hashCode方法,得到对应的hashcode值,实际上在HashMap的具体实现中会用一个table保存已经存进去的对象的hashcode值,如果table中没有该hashcode值,它就可以直接存进去,不用再进行任何比较了;如果存在该hashcode值, 就调用它的equals方法与新元素进行比较,相同的话就不存了,不相同就散列其它的地址,所以这里存在一个冲突解决的问题,这样一来实际调用equals方法的次数就大大降低了.
可以根据hashcode值判断两个对象是否相等吗?肯定是不可以的,因为不同的对象可能会生成相同的hashcode值.虽然不能根据hashcode值判断两个对象是否相等,但是可以直接根据hashcode值判断两个对象不等,如果两个对象的hashcode值不等,则必定是两个不同的对象.如果要判断两个对象是否真正相等,必须通过equals方法.
3、HashMap、HashSet
实际上,HashSet 和 HashMap 之间有很多相似之处,对于 HashSet 而言,系统采用 Hash 算法决定集合元素的存储位置,这样可以保证能快速存、取集合元素;对于 HashMap 而言,系统 key-value 当成一个整体进行处理,系统总是根据 Hash 算法来计算 key-value 的存储位置,这样可以保证能快速存、取 Map 的 key-value 对.
在介绍集合存储之前需要指出一点:虽然集合号称存储的是 Java 对象,但实际上并不会真正将 Java 对象放入 Set 集合中,只是在 Set 集合中保留这些对象的引用而言.也就是说:Java 集合实际上是多个引用变量所组成的集合,这些引用变量指向实际的 Java 对象.
HashMap 的存储实现
当程序试图将多个 key-value 放入 HashMap 中时,以如下代码片段为例:
HashMap<String , Double> map = new HashMap<String , Double>();
map.put("语文" , 80.0);
map.put("数学" , 89.0);
map.put("英语" , 78.2);
HashMap 采用一种所谓的“Hash 算法”来决定每个元素的存储位置.
当程序执行 map.put("语文" , 80.0); 时,系统将调用"语文"的 hashCode() 方法得到其 hashCode 值——每个 Java 对象都有 hashCode() 方法,都可通过该方法获得它的 hashCode 值.得到这个对象的 hashCode 值之后,系统会根据该 hashCode 值来决定该元素的存储位置.
hashMap源代码中的节点定义:
transient Entry<K,V>[] table; //哈希表,Entry类型的数组来存储元素
transient Node<K,V>[] table; //jdk8.0中明确的指出是一个链表类型的数组
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return (key==null ? 0 : key.hashCode()) ^
(value==null ? 0 : value.hashCode());
}
public final String toString() {
return getKey() + "=" + getValue();
}
}
我们可以看 HashMap 类的 put(K key , V value) 方法的源代码:
public V put(K key, V value) {
// 如果 key 为 null,调用 putForNullKey 方法进行处理
if (key == null)
return putForNullKey(value);
// 根据 key 的 keyCode 计算 Hash 值
int hash = hash(key.hashCode());
// 搜索指定 hash 值在对应 table 中的索引
int i = indexFor(hash, table.length);
// 如果 i 索引处的 Entry 不为 null,通过循环不断遍历 e 元素的下一个元素
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 如果此链表下已有元素的key与要新添加元素的key,二者equals,则替换旧元素的值为新值
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 如果 i 索引处的 Entry 为 null,表明此处还没有 Entry
modCount++;
// 将 key、value 添加到 i 索引处
addEntry(hash, key, value, i);
return null;
}
上面程序中用到了一个重要的接口:Map.Entry,每个 Map.Entry 其实就是一个 key-value 对.从上面程序中可以看出:当系统决定存储 HashMap 中的 key-value 对时,完全没有考虑 Entry 中的 value,仅仅只是根据 key 来计算并决定每个 Entry 的存储位置.这也说明了前面的结论:我们完全可以把 Map 集合中的 value 当成 key 的附属,当系统决定了 key 的存储位置之后,value 随之保存在那里即可.
上面方法提供了一个根据 hashCode() 返回值来计算 Hash 码的方法:hash(),这个方法是一个纯粹的数学计算,其方法如下:
static int hash(int h)
{
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
对于任意给定的对象,只要它的 hashCode() 返回值相同,那么程序调用 hash(int h) 方法所计算得到的 Hash 码值总是相同的.接下来程序会调用 indexFor(int h, int length) 方法来计算该对象应该保存在 table 数组的哪个索引处.indexFor(int h, int length) 方法的代码如下:
static int indexFor(int h, int length)
{
return h & (length-1);
}
这个方法非常巧妙,它总是通过 h &(table.length -1) 来得到该对象的保存位置——而 HashMap 底层数组的长度总是 2 的 n 次方,这一点可参看后面关于 HashMap 构造器的介绍.
当 length 总是 2 的倍数时,h & (length-1)将是一个非常巧妙的设计:假设 h=5,length=16, 那么 h & length - 1 将得到 5;如果 h=6,length=16, 那么 h & length - 1 将得到 6 ……如果 h=15,length=16, 那么 h & length - 1 将得到 15;但是当 h=16 时 , length=16 时,那么 h & length - 1 将得到 0 了;当 h=17 时 , length=16 时,那么 h & length - 1 将得到 1 了……这样保证计算得到的索引值总是位于 table 数组的索引之内.
根据上面 put 方法的源代码可以看出,当程序试图将一个 key-value 对放入 HashMap 中时,程序首先根据该 key 的 hashCode() 返回值决定该 Entry 的存储位置:如果两个 Entry 的 key 的 hashCode() 返回值相同,那它们的存储位置相同.如果这两个 Entry 的 key 通过 equals 比较返回 true,新添加 Entry 的 value 将覆盖集合中原有 Entry 的 value,但 key 不会覆盖.如果这两个 Entry 的 key 通过 equals 比较返回 false,新添加的 Entry 将与集合中原有 Entry 形成 Entry 链,而且新添加的 Entry 位于 Entry 链的头部——具体说明继续看 addEntry() 方法的说明.
当向 HashMap 中添加 key-value 对,由其 key 的 hashCode() 返回值决定该 key-value 对(就是 Entry 对象)的存储位置.当两个 Entry 对象的 key 的 hashCode() 返回值相同时,将由 key 通过 eqauls() 比较值决定是采用覆盖行为(返回 true),还是产生 Entry 链(返回 false).
上面程序中还调用了 addEntry(hash, key, value, i); 代码,其中 addEntry 是 HashMap 提供的一个包访问权限的方法,该方法仅用于添加一个 key-value 对.下面是该方法的代码:
void addEntry(int hash, K key, V value, int bucketIndex) {
// 获取指定 bucketIndex 索引处的 Entry
Entry<K,V> e = table[bucketIndex]; // ①
// 将新创建的 Entry 放入 bucketIndex 索引处,并让新的 Entry 指向原来的 Entry
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
// 如果 Map 中的 key-value 对的数量超过了极限
if (size++ >= threshold)
// 把 table 对象的长度扩充到 2 倍.
resize(2 * table.length); // ②
}
上面方法的代码很简单,但其中包含了一个非常优雅的设计:系统总是将新添加的 Entry 对象放入 table 数组的 bucketIndex 索引处——如果 bucketIndex 索引处已经有了一个 Entry 对象,那新添加的 Entry 对象指向原有的 Entry 对象(产生一个 Entry 链),如果 bucketIndex 索引处没有 Entry 对象,也就是上面程序①号代码的 e 变量是 null,也就是新放入的 Entry 对象指向 null,也就是没有产生 Entry 链.
HashMap 的读取实现
当 HashMap 的每个 bucket 里存储的 Entry 只是单个 Entry ——也就是没有通过指针产生 Entry 链时,此时的 HashMap 具有最好的性能:当程序通过 key 取出对应 value 时,系统只要先计算出该 key 的 hashCode() 返回值,在根据该 hashCode 返回值找出该 key 在 table 数组中的索引,然后取出该索引处的 Entry,最后返回该 key 对应的 value 即可.看 HashMap 类的 get(K key) 方法代码:
public V get(Object key) {
// 如果 key 是 null,调用 getForNullKey 取出对应的 value
if (key == null)
return getForNullKey();
// 根据该 key 的 hashCode 值计算它的 hash 码
int hash = hash(key.hashCode());
// 直接取出 table 数组中指定索引处的值,
for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null;e = e.next){ // ①
Object k;
// 如果该 Entry 的 key 与被搜索 key 相同
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
从上面代码中可以看出,如果 HashMap 的每个 bucket 里只有一个 Entry 时,HashMap 可以根据索引、快速地取出该 bucket 里的 Entry;在发生“Hash 冲突”的情况下,单个 bucket 里存储的不是一个 Entry,而是一个 Entry 链,系统只能必须按顺序遍历每个 Entry,直到找到想搜索的 Entry 为止——如果恰好要搜索的 Entry 位于该 Entry 链的最末端(该 Entry 是最早放入该 bucket 中),那系统必须循环到最后才能找到该元素.
归纳起来简单地说,HashMap 在底层将 key-value 当成一个整体进行处理,这个整体就是一个 Entry 对象.HashMap 底层采用一个 Entry[] 数组来保存所有的 key-value 对,当需要存储一个 Entry 对象时,会根据 Hash 算法来决定其存储位置;当需要取出一个 Entry 时,也会根据 Hash 算法找到其存储位置,直接取出该 Entry.由此可见:HashMap 之所以能快速存、取它所包含的 Entry,完全类似于现实生活中母亲从小教我们的:不同的东西要放在不同的位置,需要时才能快速找到它.
当创建 HashMap 时,有一个默认的负载因子(load factor),其默认值为 0.75,这是时间和空间成本上一种折衷:增大负载因子可以减少 Hash 表(就是那个 Entry 数组)所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的的操作(HashMap 的 get() 与 put() 方法都要用到查询);减小负载因子会提高数据查询的性能,但会增加 Hash 表所占用的内存空间.掌握了上面知识之后,我们可以在创建 HashMap 时根据实际需要适当地调整 load factor 的值;如果程序比较关心空间开销、内存比较紧张,可以适当地增加负载因子;如果程序比较关心时间开销,内存比较宽裕则可以适当的减少负载因子.通常情况下,程序员无需改变负载因子的值.
HashSet
HashSet 的实现其实非常简单,它只是封装了一个 HashMap 对象来存储所有的集合元素,所有放入 HashSet 中的集合元素实际上由 HashMap 的 key 来保存,而 HashMap 的 value 则存储了一个 PRESENT,它是一个静态的 Object 对象.
HashSet 的绝大部分方法都是通过调用 HashMap 的方法来实现的,因此 HashSet 和 HashMap 两个集合在实现本质上是相同的.
http://www.ibm.com/developerworks/cn/java/j-lo-hash/ ***经典
四、TreeMap和TreeSet
http://www.ibm.com/developerworks/cn/java/j-lo-tree/ ***经典
ps:集合使用案例
http://www.cnblogs.com/littlehann/p/3690187.html
javase(8)_集合框架_List、Set、Map的更多相关文章
- javase(12)_集合框架_Queue
一.Queue Queye接口体系图 体系分析: Deque实现类:ArrayDeque, LinkedList(数组和链表实现双向队列) BlockingDeque实现类:LinkedBlockin ...
- JavaSE中Collection集合框架学习笔记(2)——拒绝重复内容的Set和支持队列操作的Queue
前言:俗话说“金三银四铜五”,不知道我要在这段时间找工作会不会很艰难.不管了,工作三年之后就当给自己放个暑假. 面试当中Collection(集合)是基础重点.我在网上看了几篇讲Collection的 ...
- JavaSE中Collection集合框架学习笔记(3)——遍历对象的Iterator和收集对象后的排序
前言:暑期应该开始了,因为小区对面的小学这两天早上都没有像以往那样一到七八点钟就人声喧闹.车水马龙. 前两篇文章介绍了Collection框架的主要接口和常用类,例如List.Set.Queue,和A ...
- 理解java集合——集合框架 Collection、Map
1.概述: @white Java集合就像一种容器,可以把多个对象(实际上是对象的引用,但习惯上都称对象)"丢进"该容器中. 2.Java集合大致可以分4类: @white Set ...
- 牛客网Java刷题知识点之Java 集合框架的构成、集合框架中的迭代器Iterator、集合框架中的集合接口Collection(List和Set)、集合框架中的Map集合
不多说,直接上干货! 集合框架中包含了大量集合接口.这些接口的实现类和操作它们的算法. 集合容器因为内部的数据结构不同,有多种具体容器. 不断的向上抽取,就形成了集合框架. Map是一次添加一对元素. ...
- JavaSE学习总结第15天_集合框架1
15.01 对象数组的概述和使用 public class Student { // 成员变量 private String name; private int age; // 构造方法 publ ...
- JavaSE学习总结第18天_集合框架4
18.01 Map集合概述和特点 Map接口概述:将键映射到值的对象,一个映射不能包含重复的键,每个键最多只能映射到一个值 Map接口和Collection接口的不同 1.Map是双列的,Coll ...
- Java集合框架List,Map,Set等全面介绍
Java集合框架的基本接口/类层次结构: java.util.Collection [I]+--java.util.List [I] +--java.util.ArrayList [C] +- ...
- 【转】Java集合框架List,Map,Set等全面介绍
原文网址:http://android.blog.51cto.com/268543/400557 Java Collections Framework是Java提供的对集合进行定义,操作,和管理的包含 ...
随机推荐
- 51nod 1013【快速幂+逆元】
等比式子: Sn=(a1-an*q)/(1-q) n很大,搞一发快速幂,除法不适用于取膜,逆元一下(利用费马小定理) 假如p是质数,且gcd(a,p)=1,那么 a^(p-1)≡1(mod p).刚好 ...
- 关于 T[] 的反射问题
1. T[] 类型不适应以下代码 Dictionary<string, Test> d = new Dictionary<string, Test>(); // Get a T ...
- 部署spark 1.3.1 standalong模式
之前已经写过很多次部署spark 的博客,但是之前部署都是照瓢画葫芦,不得其中的细节,并且以前都是部署spark on yarn 部署环境 scala 2.10.2,jdk 1.6,spark 版本1 ...
- 00 | QPS
每秒查询率 QPS Query Per Second 某个查询服务器 在 规定时间内 处理了多少流量 对应的fetches/sec,即每秒响应请求数,就是最大吞吐量 原理:每天80%的访问集中在20% ...
- one jar(转)
http://blog.csdn.net/kabini/article/details/1598827
- 最近工作用到压缩,写一个zip压缩工具类
package test; import java.io.BufferedOutputStream;import java.io.File;import java.io.FileInputStream ...
- 条件运算符?:接受三个操作数,是C#中唯一的三元运算符(转)
int i = 10; int j = i == 10 ? 1 : 2; //转换成if选择结果如下 if (i == 10) { j = 1; } else { j = 2; } 需要根据还可以嵌套 ...
- Guard Duty (hard) Codeforces - 958E3 || uva 1411
https://codeforces.com/contest/958/problem/E3 当没有三点共线时,任意一个这样的点集都是保证可以找到答案的,(考虑任意一种有相交的连线方案,一定可以将其中两 ...
- oracle tps
http://blog.csdn.net/nilxin/article/details/5812480 sample 1: 定义 TPS:Transactions Per Second(每秒传输的事物 ...
- [译]Understanding ECMAScript 6 说明
说明 JavaScript核心语言功能定义在ECMA-262中,此标准定义的语言是ECMAScript,浏览器中的JavaScript和Node.js环境是它的超级.当浏览器与Node.js想要通过额 ...