tensorflow目标检测API之建立自己的数据集
1 收集数据
为了方便,我找了11张月儿的照片做数据集,如图1,当然这在实际应用过程中是远远不够的
2 labelImg软件的安装
使用labelImg软件(下载地址:https://github.com/tzutalin/labelImg)为图片做标签
下载下来之后解压缩,用Anaconda Prompt cd到解压缩后的labelImg文件目录下,例如 cd C:\Users\admin\Desktop\labelImg-master
然后安装pyqt,输入命令 conda install pyqt=5(注意:一定要使用管理员方式运行命令)
完成后输入命令 pyrcc5 -o resources.py resources.qrc,这个命令没有返回
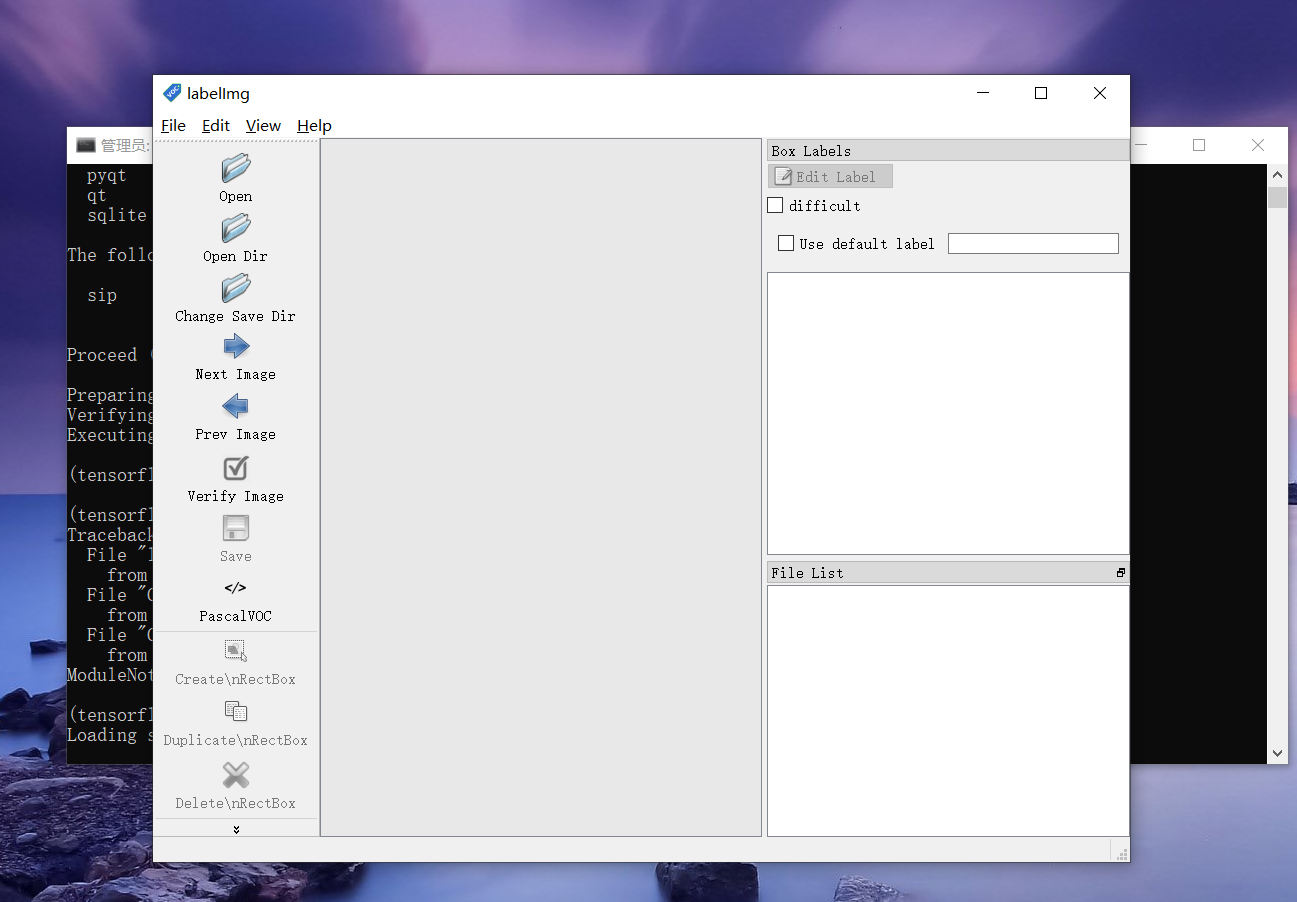
最后执行 python labelImg.py,如果提示缺少包则安装就行
运行结果如图2
3 labelImg软件的使用
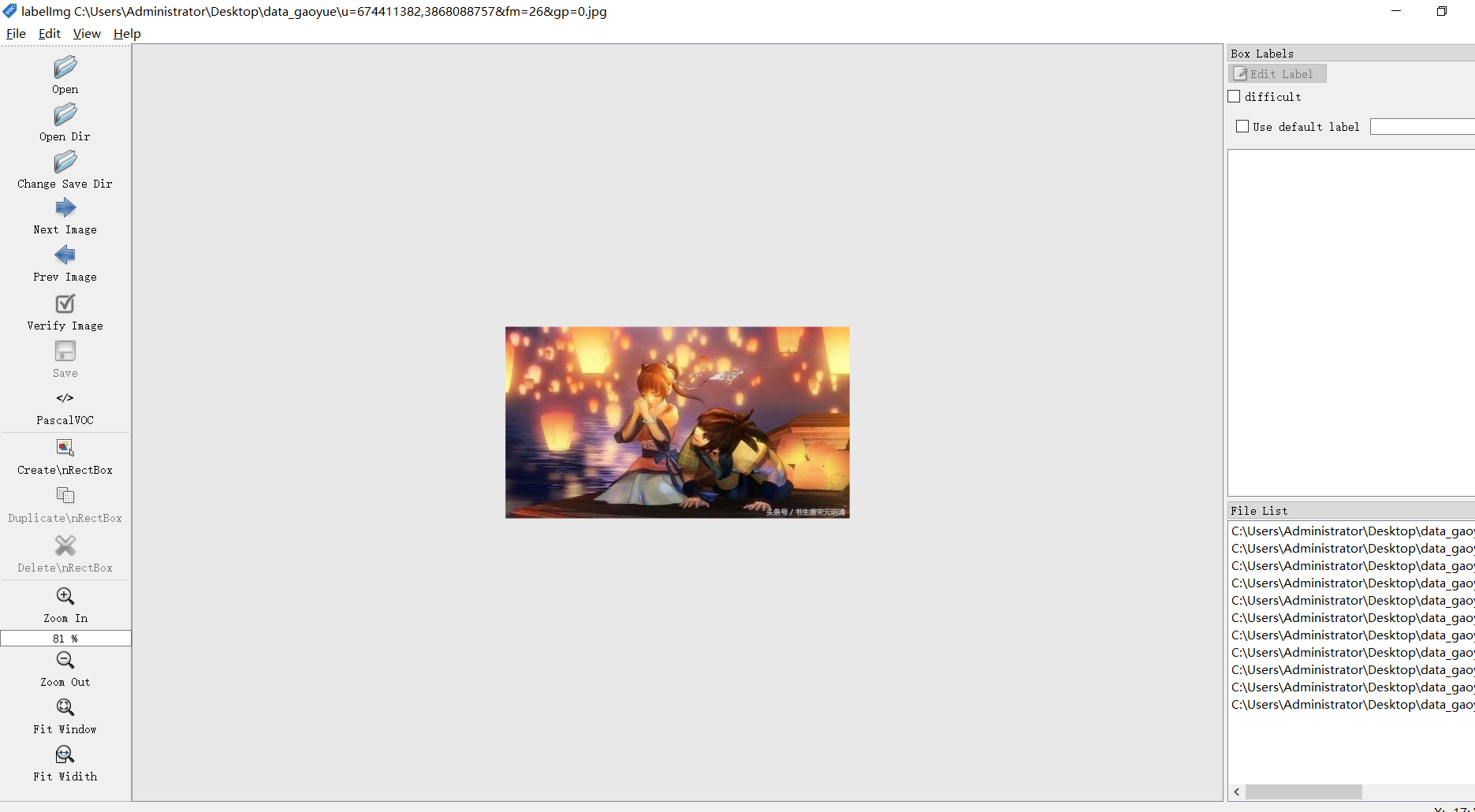
点击Open Dir打开数据集所在的文件夹,将图片导入。如图3所示。
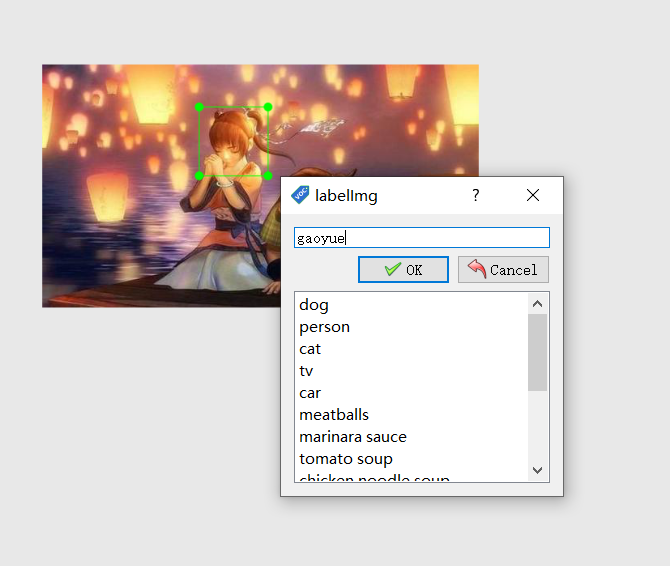
在界面中按下w键,选择你的目标,然后在弹出的框中为你的目标确定一个名字。如图4
标记完之后每张图片都有一个对应的xml文件,如图5所示
4 标签文件的格式转换(一定要将这一步中的代码放在object_detection文件夹下)
(1)xml转csv
代码(xml_to_csv.py)
# -*- coding: utf-8 -*- import os
import glob
import pandas as pd
import xml.etree.ElementTree as ET os.chdir('C:/Code/models-master/research/object_detection/my_train_images/train') # 这个是我文件夹的目录,改成你自己的
path = 'C:/Code/models-master/research/object_detection/my_train_images/train' # 训练图片的路径,改成你自己的 def xml_to_csv(path):
xml_list = []
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall('object'):
value = (root.find('filename').text,
int(root.find('size')[0].text),
int(root.find('size')[1].text),
member[0].text,
int(member[4][0].text),
int(member[4][1].text),
int(member[4][2].text),
int(member[4][3].text)
)
xml_list.append(value)
column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df def main():
image_path = path
xml_df = xml_to_csv(image_path)
xml_df.to_csv('gaoyue_train.csv', index=None) # 输出xsv文件的名字,改成你自己的
print('Successfully converted xml to csv.') main()
运行之后可以看到train文件夹下多了一个gaoyue.csv文件,重复上面的代码,更改文件夹,将test数据也生成一个.csv文件。

(2)csv转tfrecord
代码(csv_to_tfrecord.py)
# -*- coding: utf-8 -*- """
Usage:
# From tensorflow/models/
# Create train data:
python generate_tfrecord.py --csv_input=data/tv_vehicle_labels.csv --output_path=train.record
# Create test data:
python generate_tfrecord.py --csv_input=data/test_labels.csv --output_path=test.record
""" import os
import io
import pandas as pd
import tensorflow as tf from PIL import Image
from object_detection.utils import dataset_util
from collections import namedtuple, OrderedDict os.chdir('C:/Code/models-master/research/object_detection') # 当前工作目录 flags = tf.app.flags
flags.DEFINE_string('csv_input', '', 'Path to the CSV input')
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')
FLAGS = flags.FLAGS # TO-DO replace this with label map
def class_text_to_int(row_label):
if row_label == 'gaoyue':
return 1
# elif row_label == 'vehicle':
# return 2
else:
return 0 def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)] def create_tf_example(group, path):
with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size filename = group.filename.encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = [] for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(row['class'].encode('utf8'))
classes.append(class_text_to_int(row['class'])) tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example def main(_):
writer = tf.python_io.TFRecordWriter(FLAGS.output_path)
# path = os.path.join(os.getcwd(), 'images/train')
path = os.path.join(os.getcwd(), 'my_train_images/train') # 当前路径加上你图片存放的路径
examples = pd.read_csv(FLAGS.csv_input)
grouped = split(examples, 'filename')
for group in grouped:
tf_example = create_tf_example(group, path)
writer.write(tf_example.SerializeToString()) writer.close()
output_path = os.path.join(os.getcwd(), FLAGS.output_path)
print('Successfully created the TFRecords: {}'.format(output_path)) if __name__ == '__main__':
tf.app.run()
然后打开Anaconda Prompt cd到你csv_to_tfrecord.py文件所在的地方
输入命令
python csv_to_tfrecord.py --csv_input=my_train_images/test/gaoyue_test.csv --output_path=gaoyue_train.record (csv_to_tfrecord.py为转换的代码文件,csv_input是你要转换的csv文件所在的路径,output_path是你输出tfrecord文件的路径)
运行结果如图所示

生成 gaoyue_train.csv文件

tensorflow目标检测API之建立自己的数据集的更多相关文章
- tensorflow目标检测API之训练自己的数据集
1.训练文件的配置 将生成的csv和record文件都放在新建的mydata文件夹下,并打开object_detection文件夹下的data文件夹,复制一个后缀为.pbtxt的文件到mtdata文件 ...
- tensorflow目标检测API安装及测试
1.环境安装配置 1.1 安装tensorflow 安装tensorflow不再仔细说明,但是版本一定要是1.9 1.2 下载Tensorflow object detection API 下载地址 ...
- tensorflow2.4与目标检测API在3060显卡上的配置安装
目前,由于3060显卡驱动版本默认>11.0,因此,其不能使用tensorflow1版本的任何接口,所以学习在tf2版本下的目标检测驱动是很有必要的,此配置过程同样适用于任何30系显卡配置tf2 ...
- TensorFlow目标检测(object_detection)api使用
https://github.com/tensorflow/models/tree/master/research/object_detection 深度学习目标检测模型全面综述:Faster R-C ...
- 目标检测:keras-yolo3之制作VOC数据集训练指南
制作VOC数据集指南 Github:https://github.com/hyhouyong/keras-yolo3 LabelImg标注工具(windows环境下):https://github.c ...
- TensorFlow object detection API应用
前一篇讲述了TensorFlow object detection API的安装与配置,现在我们尝试用这个API搭建自己的目标检测模型. 一.准备数据集 本篇旨在人脸识别,在百度图片上下载了120张张 ...
- TensorFlow object detection API应用--配置
目标检测在图形识别的基础上有了更进一步的应用,但是代码也更加繁琐,TensorFlow专门为此开设了一个object detection API,接下来看看怎么使用它. object detectio ...
- TensorFlow Object Detection API中的Faster R-CNN /SSD模型参数调整
关于TensorFlow Object Detection API配置,可以参考之前的文章https://becominghuman.ai/tensorflow-object-detection-ap ...
- 10分钟内基于gpu的目标检测
10分钟内基于gpu的目标检测 Object Detection on GPUs in 10 Minutes 目标检测仍然是自动驾驶和智能视频分析等应用的主要驱动力.目标检测应用程序需要使用大量数据集 ...
随机推荐
- 脑图和MarkDown
使用脑图整理前端体系 根据以下网址整理 http://web.jobbole.com/84062/ http://naotu.baidu.com/ 学习MarkDown语法格式 (一) 标题 在首行插 ...
- 如何使用WPS从正文开始页码为1,而不是从目录开始?
在插入目录前,在最前页插入一个空白页,在这个空白页里面生成目录,双击正文的页脚,点一下出现的与上一节相同的按钮,关闭页眉页脚的同前节,发现与上一节相同这几个字消失后,把目录中的页码删除,不会在影响正文 ...
- 自定义view(14)使用Path绘制复杂图形
灵活使用 Path ,可以画出复杂图形,就像美术生在画板上画复杂图形一样.程序员也可以用代码实现. 1.样板图片 这个是个温度计,它是静态的,温度值是动态变化的,所以要自定义个view.动态显示值,温 ...
- NET Core学习方式(视频)
NET Core学习方式(视频) ASP.NET Core都2.0了,它的普及还是不太好.作为一个.NET的老司机,我觉得.NET Core给我带来了很多的乐趣.Linux, Docker, Clou ...
- Mysql数据库服务启动
1.以系统管理员身份运行cmd.exe(C:\Windows\System32),输入net start mysql 2.在电脑右击->管理->服务和应用程序->服务->mys ...
- C#关键字:yield
yield是C#为了简化遍历操作实现的语法糖.在语句中使用 yield 关键字,表示在该关键字所在的方法.运算符或 get 访问器是迭代器.有两种形式: yield return <expres ...
- AJPFX辨析continue与break的区别
1.break : (1).结束当前整个循环,执行当前循环下边的语句.忽略循环体中任何其它语句和循环条件测试.(2).只能跳出一层循环,如果你的循环是嵌套循环,那么你需要按照你嵌套的层次,逐步使用br ...
- 【踩坑】List 的陷阱
今天测试iReview项目数据的反馈,发现有些语句总无法执行. 经过调试排查后,发现List<自定义类>返回了空集"[]",却无法进入if语句里面,即 if (List ...
- Spring 基础知识 - 依赖注入
所谓的依赖注入是指容器负责创建对象和维护对象间的依赖关系,而不是通过对象本身负责自己的创建和解决自己的依赖. 依赖注入主要目的是为了解耦,体现了一种“组合”的理念. 无论是xml配置.注解配置还是Ja ...
- AngularJS(一):概述
本文也同步发表在我的公众号“我的天空” 在我们之前学习的前端代码编写过程中,总是通过HTML与CSS来进行页面布局,而使用JS来控制页面逻辑,因此,我们习惯于在JS中来操作页面元素,如以下代码,我们希 ...