Hadoop安装全教程 Ubuntu14.04+Java1.8.0+Hadoop2.7.6
最近听了一个关于大数据的大牛的经验分享,在分享的最后大牛给我们一个他之前写好的关于大数据和地理应用demo。这个demo需要在Linux环境上搭建Hadoop平台。这次就简单的分享一下我关于在
Linux虚拟机上搭建Hadoop平台的一些经验和遇到的一些问题以及问题的解决办法。
首先我们这次搭建的环境是hadoop。hadoop实现了分布式文件系统,它可以部署在一些廉价的硬件环境上,并且提供了高吞吐量来访问应用程序的数据,非常适合那些有着大数据集的应用程序。而且最重要的是,hadoop是开源的。
这次我们将要在一台计算机(虚拟机)上安装我们的hadoop实验环境。如果你还没有安装虚拟机,请百度查看VMware workstations Pro 12的安装教程。如果你还没有在虚拟机中安装Linux操作系统,请百度在VMware下安装Ubuntu或者centos的教程。
安装的模式是单机模式和伪分布模式。单机模式是在hadoop解压缩之后默认选择的最精简模式,在这个模式中,core-site.xml ,hdfs-site.xml和hadoop-env.sh中的配置信息默认为空,在安装时需要我们自己去配置填写。伪分布模式就是hadoop运行在单集群上,这个模式比单机模式多了代码调试功能,并且启用了HDFS功能而且能够和几个守护进程进行交互
本文中安装的是Ubuntu14.04LTS+java 1.8.0_101+Hadoop 2.7.6
一、Linux上JAVA环境的安装
首先在Linux上安装hadoop之前我们需要了解,hadoop是基于java开发的一款程序。所以我们需要在安装hadoop之前保证我们的Linux上有java环境。下面我们就来介绍一些如何在Linux上安装java1.8.0_101。
在安装java之前我们需要检查系统中有没有安装java,使用java -version命令来查看是否安装了java,如果安装了其他版本的java请在卸载之后安装java1.8.0。
首先我们需要在oracle官网上下载我们需要的JDK安装包,JDK就是Java Development Kit 这个开发工具中包含了java运行所必须的运行环境。你可以在这个网址中下载到本文所述的java1.8.0_101的Linux版本安装包,注意在下载安装包的时候请选择适合你的操作系统版本的位数文件进行下载(这里的操作系统指的是你的虚拟机中安装的Linux的版本,可以通过uname -a指令来查看你当前的Linux版本)
www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
在完成下载之后,我们将得到一个后缀名为.tar.gz的压缩包,这时我们将这个文件解压缩到/usr/java/目录下(请在解压缩之前新建这个目录)
tar -zxvf jdk-8u101-linux-x64.tar.gz -C /usr/java/在解压缩之后我们就可以配置我们的环境变量了
vim ~/.bashrc
#写入环境变量export JAVA_HOME=/usr/local/java/jdk1.8.0_172
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
在写完环境变量之后使用
source ~/.bashrc
来使环境变量生效
在配置完之后我们利用
java -version
来查看java是否安装完毕。
二、安装ssh server 实现免密码登录
因为Hadoop需要使用ssh进行通信,所以我们需要在我们的操作系统上安装ssh。在安装之前,我们需要查看系统是否已经安装并且启动了ssh
#查看ssh安装包情况
dpkg -l | grep ssh
#查看是否启动ssh服务
ps -e | grep ssh如果系统中并没有ssh服务,可以使用
sudo apt-get install openssh-server 来安装ssh服务,在安装之后使用
sudo /etc/init.d/ssh start 开启服务。
之后再使用
ps -e | grep ssh来查看服务是否启动。
ssh作为一个安全通信协议,自然就需要通信的时候输入密码,但是因为我们伪分布模式,所以我们将设置免密码登录。
#生成秘钥
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
#导入authorized_keys
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
#测试是否免密码登录localhost
ssh localhost在结束之后关闭机器的防火墙
ufw disable
三、安装Hadoop
在结束了前期的准备工作之后我们可以开始安装我们的Hadoop了
下载Hadoop 下面提供了Hadoop的下载链接
http://hadoop.apache.org/releases.html
下载binary
解压缩下载之后的文件
tar -zxvf hadoop-2.7.6 -C /usr/local/hadoop/在解压缩之间请创建/usr/local/hadoop/目录
下面来写配置文件core-site.xml、hdfs-site.xml、hadoop-env.sh三个文件
这三个文件都在/usr/local/hadoop/hadoop-2.7.3/etc/hadoop/下,在前两个文件中的和中写入如下内容
第一个文件core-site.xml
core-site.xml
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/duanxz/tmp</value>
</property>
请注意/home/duanxz/tmp文件夹要被替换为计算机当前的用户目录中的tmp文件夹没有请创建。
第二个文件hdfs-site.xml
hdfs-site.xml
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
第三个文件hadoop-env.sh中找到如下行然后写入内容
# The java implementation to use.
export JAVA_HOME=/usr/java/jdk1.8.0_101
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.6
export PATH=$PATH:/usr/local/hadoop/hadoop-2.7.6/bin
接下来在系统环境变量中写入Hadoop的环境变量
vim /etc/environment
#在文件的结尾""之内加上
:/usr/local/hadoop/hadoop-2.7.3/bin:/usr/local/hadoop/hadoop-2.7.6/sbin
重启系统
验证Hadoop单机模式安装完成
hadoop version
看到屏幕上显示hadoop的版本号即说明单机模式已经配置完成
接下来就是启动hdfs 使用伪分布模式
第一步格式化
hadoop namenode -format
显示如下内容即成功格式化
...
...
16/09/24 23:39:53 INFO common.Storage: Storage directory /home/windghoul/tmp/dfs/name has been successfully formatted.
...
...
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at ubuntu/127.0.1.1
************************************************************/启动hdfs
sbin/start-all.sh显示进程
jps看到屏幕上显示如下内容即说明hdfs已经成功
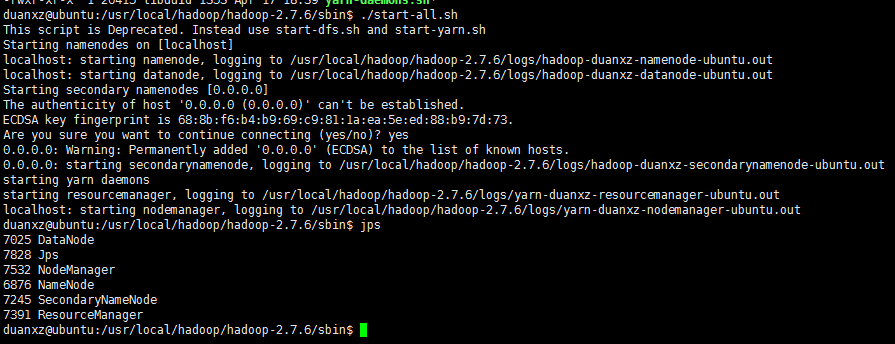
停止hdfs
sbin/stop-all.sh以上命令行都需要系统路径在hadoop安装路径之下,如果在/home/username下运行,请输入完全路径。
这样我们的hadoop环境就基本搭建完毕,之后我还会写一些关于hadoop的简单应用的分享。
问题解决
Q:我在配置完文件之后在命令行中输入hadoop version并没有显示hadoop的版本号
A:请检查环境变量的配置,尤其是有没有写入hadoop的环境变量,检查/etc/environment下
并且重启您的计算机。
Q:在格式化那里我没有正确的格式化
A:如问题1,在格式化之前请检查hadoop单机模式有没有正确的安装并配置,检查core-site.xml文件有没有正确的配置
Q:在最后启动hdfs的时候总是提醒我输入localhost的密码
A:如果提醒输入密码可能是tmp文件夹的拥有者权限不对,请使用chmod -R a+w /home/duanxz/tmp可能就会解决。
Q:Linux 搭建Hadoop集群执行命令start-dfs.sh报错 permission denied
A:解决方案:对文件敞开权限,对hadoop安装目录执行命令:sudo chmod a+w *
Q:nameNode启动不成功,启动hadoop发现namenode节点无法启动,50070端口无法访问,50030端口正常。
A:查看namenode的启动日志:duanxz@three:/usr/local/hadoop-2.7.6/logs$ more hadoop-duanxz-namenode-three.log

解决方法:为tmp目录增加权限:duanxz@three:~$ sudo chmod -R a+w tmp
Q:nameNode启动失败,日志如下:
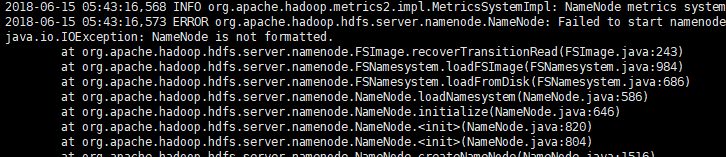
是没有格式化,
hadoop namenode -format
检查namenode是否启动方法如下:
1、jps,查看是否有namenode进程
2、telnet 127.0.0.1 9000

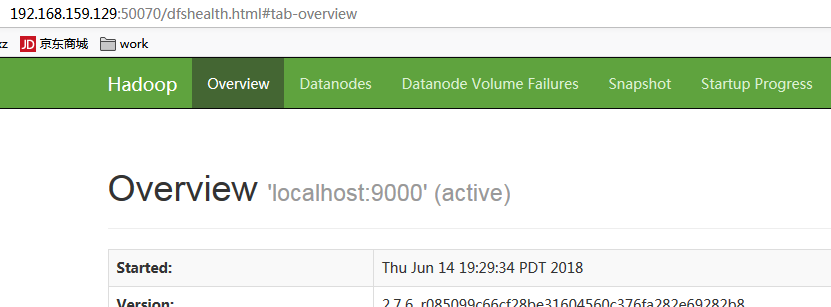
3、访问http://192.168.1.105:50070/
hadoop web控制台页面的端口整理:
50070:hdfs文件管理
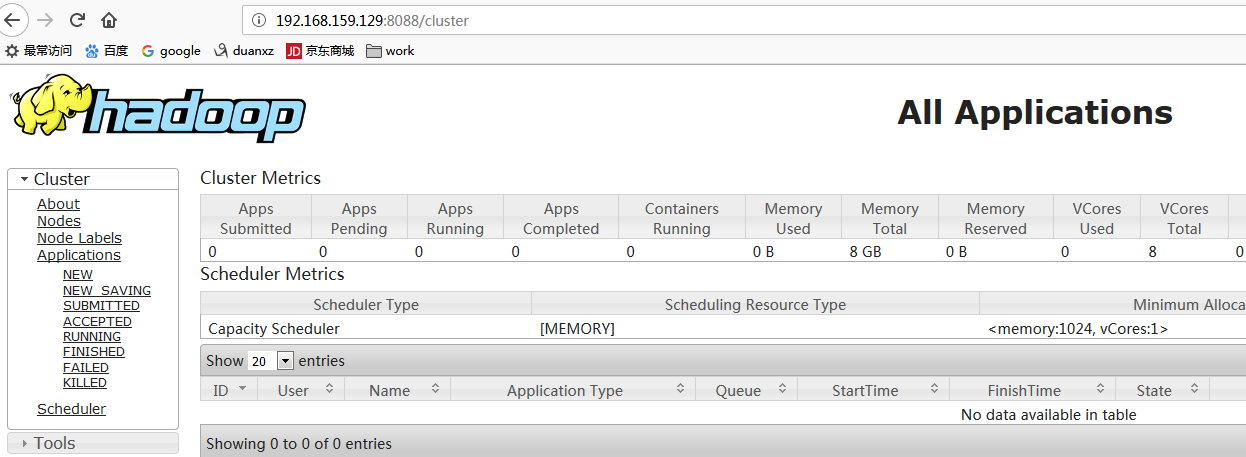
8088:ResourceManager
8042:NodeManager
19888:JobHistory(使用“mr-jobhistory-daemon.sh”来启动JobHistory Server)
下面是我的截图:
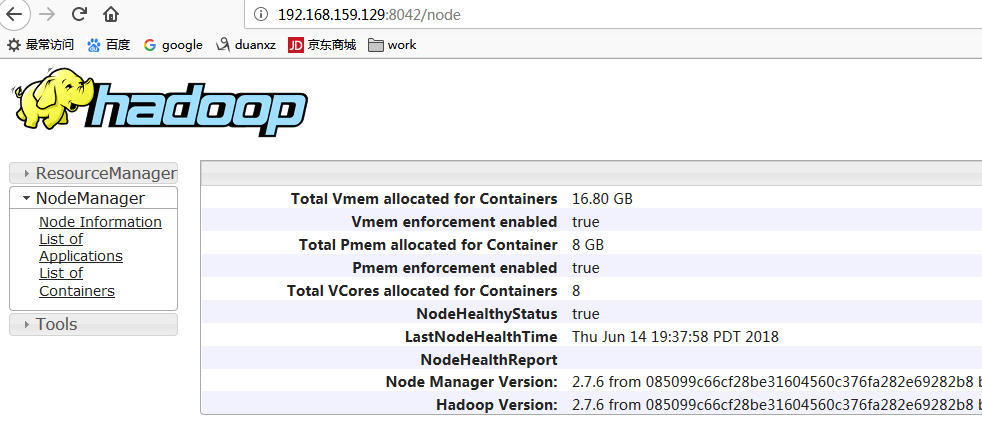
在最后感谢网络上的几位大牛给的之前版本的安装教程
https://blog.csdn.net/windghoul/article/details/52655032
Hadoop安装全教程 Ubuntu14.04+Java1.8.0+Hadoop2.7.6的更多相关文章
- GNU Radio安装教程: Ubuntu14.04 + uhd3.10.0 + gnuradio3.7.10.1
1. 更新和安装依赖项 在编译安装uhd和gnuradio之前,确保已安装所需依赖项.Ubuntu系统运行: sudo apt-get update 安装UHD和GNURadio所需依赖项: On U ...
- Legacy安装win7和Ubuntu14.04双系统
Legacy安装win7和Ubuntu14.04双系统 安装环境 Legacy启动模式(传统引导) 笔记本已安装win7 硬盘启动顺序为: U盘 硬盘 光驱 安装方法 制作U盘启动盘 在Ubuntu官 ...
- DL服务器主机环境配置(ubuntu14.04+GTX1080+cuda8.0)解决桌面重复登录
DL服务器主机环境配置(ubuntu14.04+GTX1080+cuda8.0)解决桌面重复登录 前面部分是自己的记录,后面方案部分是成功安装驱动+桌面的正解 问题的开始在于:登录不了桌面,停留在重复 ...
- Cloudera Manager安装之Cloudera Manager安装前准备(Ubuntu14.04)(一)
其实,基本思路跟如下差不多,我就不多详细说了,贴出主要图. 博主,我是直接借鉴下面这位博主,来进行安装的!(灰常感谢他们!) 在线和离线安装Cloudera CDH 5.6.0 Cloudera M ...
- caffe+Ubuntu14.04.10 +cuda7.0/7.5+CuDNNv4 安装
特别说明: Caffe 官网地址:http://caffe.berkeleyvision.org/ 本文为作者亲自实验完成,但仅限用于学术交流使用,使用本指南造成的任何不良后果由使用者自行承担,与本文 ...
- 【转】光盘和U盘安装win7和ubuntu14.04全步骤
详细步骤见原链接:http://brianway.github.io/2016/01/18/linux-win7-ubuntu-setup-by-USBandCD/ 安装Linux步骤 1. 在win ...
- caffe+NVIDIA安装+CUDA-7.5+ubuntu14.04(显卡GTX1080)
首先强调,我们实验室的机器是3.3w的机器,老板专门买来给我们搞深度学习,其中显卡是NVIDIA GeForce GTX1080(最近新出的,装了两块),cpu是intel i7处理器3.3Ghz, ...
- win8.1下安装双系统ubuntu14.04.3
一.去ubuntu官网下载长期支持版的系统,64位还是32位由物理内存而定,4G以下用32位,4G以上(包括4G)使用64位. 二.若64位的系统,下载下来的文件名应该是ubuntukylin-14. ...
- LAMP_源码安装全教程
第一步:准备安装软件 httpd-2.4.7.tar.gz, apr-1.4.6.tar.gz, apr-util-1.4.1.tar.gz,mysql-5.5.tar.gz,php-5.4.tar. ...
随机推荐
- HDFS源码分析DataXceiver之整体流程
在<HDFS源码分析之DataXceiverServer>一文中,我们了解到在DataNode中,有一个后台工作的线程DataXceiverServer.它被用于接收来自客户端或其他数据节 ...
- /usr/bin/mysqld_safe_helper: Cannot change uid/gid (errno: 1) (转)
From: https://www.rootusers.com/how-to-fix-mariadb-10-0-29-selinux-update-failure/ 安装mysql 10.0.29后, ...
- python 基础 7.0 import 导入
一. python 常用内置模块的使用(datetime,logging,os,command) 在日常的开发工作中,我们要写很多的python 代码,如果都写在一个文件中,会导致代码特别 ...
- hdoj 1116 Play on Words 【并查集】+【欧拉路】
Play on Words Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) T ...
- php 整合 微博登录
现在很多网站都整合了便捷的第三方登录,如QQ登录.新浪微博.搜狐.网易等,为用户提供不少方便和节约时间.我们可以选择使用JS或SDK实现第三方提供用户授权API,本文主要讲解 JAVA SDK 新浪微 ...
- springMvc 4.0 jackson包改变
使用之前的json包出包java.lang.NoClassDefFoundError: com/fasterxml/jackson/core/JsonProcessingException错误. sp ...
- div中p标签自动换行
只需要设置div的width属性,p标签加上word-break:break-word属性就会自动换行 ----------------2016.7.1-------------------- 今天在 ...
- 关于android R.java文件无法创建的问题
R.java文件无法创建的原因网上有很多说法普遍是以下两种: 1. xml文件有错误: 解决方法就是找到哪个xml有错然后把错误修复就OK了. 2.编码问题 这时候只要把xml文件的编码改成utf8就 ...
- HDU - 1213 How Many Tables 【并查集】
题目链接 http://acm.hdu.edu.cn/showproblem.php?pid=1213 题意 给出N个人 M对关系 找出共有几对连通块 思路 并查集 AC代码 #include < ...
- 怎么升级iOS10教程
在前两天的开发者大会上刚推出了iOS10,我介绍一下怎么升级到iOS10的办法.所有人只用一个iPhone就可以升级到iOS10,不需要电脑,也不需要开发者账号. http://bbs.feng.co ...