Tile based Rendering 二 tbr and tbdr 优化建议tiled based deferred rendering
http://www.seas.upenn.edu/~pcozzi/OpenGLInsights/OpenGLInsights-TileBasedArchitectures.pdf
tbr 和tbdr是gpu的一种架构 硬件层面的事情和deferred shading是两回事
有关blend的开销
immediate模式 要走相对较慢的 memory read-modify-write framebuffer
tile based模式 就在on chip tile buffer上用专门的硬件做了 基本没有开销 而如果在shader里面写会占shader吞吐量
所以这段的建议就是如果做透明的话 推荐用blend 而不在shader里做
而透明与不透明相比 透明(无论哪种方式alpha blend, alpha test, alpha to coverage)总会导致 对于透明物体后面的fragment来讲hidden surface removal 和earlyz 失效
==============
===================
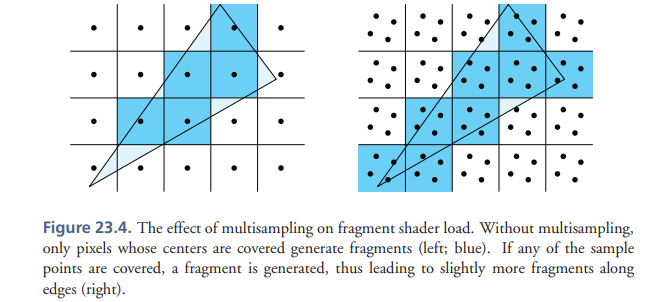
tbr multisampling对带宽的影响情况是这样的
multisamp的瓶颈是带宽, 4x为例 访问framebuffer的带宽变为之前的4倍 (一个pixel 4个sample)
如果是tbt这部分 都在tile buffer上做 做完 一次送到framebuffer (resolved 之后 相当于一个pixel1个sample)
开销包含以下两部分
1.tile buffer上的大小需要4倍,厂商在开ms的情况下,减小tile size 为了省下buffer大小,这对性能有些许冲击,half size不会导致half performace
如果程序的瓶颈是shading吞吐量 tile buffer size减小 只会对性能有很很轻微的影响(比几乎无影响高一点 minor impact也就是除非程序瓶颈就是在这里了
2 第二种类型的开销在immediate mode下也是同样存在的 会增加大概10%的fragments(数量)的计算 具体数量取决于场景
不只是cover center的 frag参与 只要cover sample的 frags都会算在内
==============
介于profile 不那么准确好用了
建议 开发初期 确定复杂度预算 trigngles ,textures ,shader complexity等等,这个我有做
来避免 geometry 超过一个最高的量引发的切分 性能会大幅下降
它最后说这段很诡异 应该是举了个反例: 你在draw 后面加glclear ,那个draw可能不会被提交 引擎这边给优化掉了之类吧
要确保命令按预期执行 应该是这意思
=========================================
总结 performance的核心是 测试 测试 测试 因为硬件 driver都是不同的
对于tb GPU
1. clear color , depth ,stencil在每帧开始的时候
2.For each framebuffer, bind it once during the frame, and submit all the commands for the frame before unbinding it or using the results.
这步是在避免framebuffer的bind
3.latency for gpu query
4.保证多边形数量在合理范围,避免那次跳崖式下跌
5.有了隐藏面消除 不需要对opaquel从前向后排序(powerVR),不是tb的gpu需要这样做,考虑用z pre pass
6.多利用cheap的multisample
7.移动平台performance和电量消耗取平衡 两者都要兼顾
=================
tbr 透明要不要cpu排序?? (要排, opaque不排是因为被剔掉了
对于这种情况 是不是完全隐藏面消除就失效了 一个不透明场景 前面蒙上一层透明面片
我估计这是对一个tile来讲的 场景不要大块很多透明 透明后面不要太多东西 省掉的是透明后面frag的计算
这段括号里的理解是不对的 粒度肯定不是tile是pixel 分两个passtrans就不会使opaque的hsr失效 后面有论证
===============
基本方法:1 减少状态切换
2 texture 压缩
3.减少drawcalls
4.降低shader复杂度
各种差异性 导致优化需要持续profiling 并试验
所以我们不应该记一些方法 而是要知道 每种特性如何影响性能
(这两点深切赞同)
锁低帧可以延长电量
在达到目标帧率之后还可以持续优化 以减少电量消耗
移动平台 performance and power consumption
带宽--移动数据 费电
immediate mode下pixel需要 read depth/stencil write depth/stencil(opt) write color 这里消耗带宽
tbr可以省电 把数据放在计算器旁边(on-chip) 最后往framebuffer放一次
GPU的tbr就是为了省带宽 进而省电
depth/stencil test和blend都是在tile上做
tbdr的gpu 会用专门的硬件单元 收集到所有的vertex 的信息 用相应的数据结构 包含vertex position ,vertex output, triangle indices, fragment state等
这部分叫做frame data/polygon lists/parameter buffer
这部分是有开销的 如果曲面细分导致vertex过多 这部分开销就会抵消掉tbdr的优势
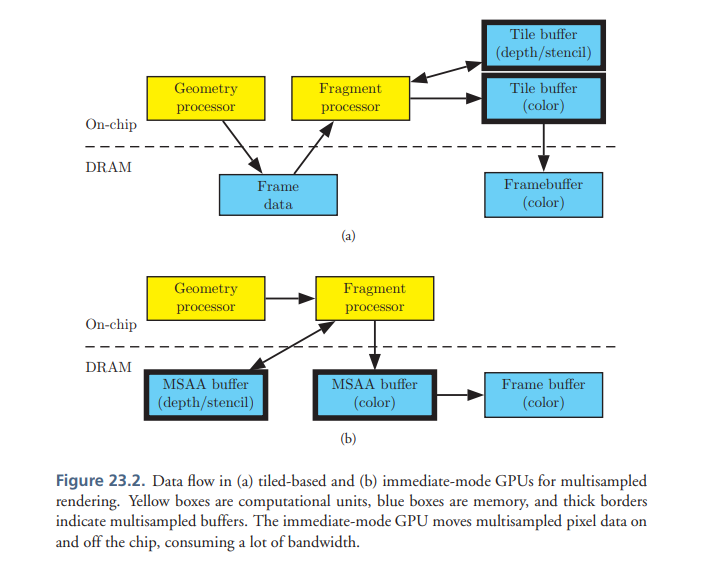
tbdr mode 在每一帧构造的是上文提到的frame data(所有vertex)信息 而不是frame buffer 在性能调优的时候需要铭记这一点
drawcall越多这部分数据就越大
(看到一个黑科技using half the depth range on alternate frames to avoid clearing the depth buffer 这个应该是immediate 模式下 为了避免清depth的一种方法 分开用
避免写这两块buffer都到了这种程度 说明开销很高了)
tbdr要clear 避免tile buffer copy回 framebuffer 和从framebuffer copy数据去tilebuffer
相关mask也设置上
clear只是clear 推荐用e EXT_discard_framebuffer 这个扩展可以真正告诉driver 那部分frame buffer的内容可以丢弃 driver可以做他想做的比如rtt时候复用framebuffer不用再copy一份了
====================================
扩展里面提供了一种按tile局部更新的方法(好方法啊!)比如 ui界面很多地方不用更新只是某个图标更新 那其它地方只是从framebuffercopy到tilebuffer就可以
这个不默认提供 因为copy有开销 参见clear那部分
glStartTilingQCOM(x , y , width , height , GL_NONE );
glClear ( GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT | GL_STENCIL_BUFFER_BIT);
glViewport(x , y , width , height );
// Draw the scene
glEndTilingQCOM( GL_COLOR_BUFFER_BIT0_QCOM); eglSwapBuffers(dpy , surface );
这两个扩展EGL_SWAP_BEHAVIOR to EGL_BUFFER_PRESERVED.
==========================
Flushing
glflush--提交command buffer 清空缓存(cb相关的 包含其它资源buffer) 拿framebuffer的时候会引发flush 执行完命令才能拿结果
这里讲了一下
1.framebuffer 如果要访问 肯定需要先把里面的东西shader完 即使是再gpu里访问也是一样的
2.如果glBindFramebuffer会导致前面那个fm2 unbound 这样fm2会shade return
这就解释了为什么要减少不必要的framebuffer bound 最好的情况是用到的fm一帧只绑一次(这段出现的fm都是destination)
这就解释了为什么smpass cubemap pass reflection pass都是一个在前面
3. vertex一直增加会引发一个是平时flush开销16倍的flush (面片在几十万级别不会触发 1M也没事 大了没测)
通过提前的测试找到这个vertex的数量避免这种问题发生
===============================
Latency
最后一段latency的问题
数据被同时访问时会存在driver的 copy on write 费memory 解决方法是 把一块资源一次更新好 不要改一下给gpu处理下再改再给gpu
============================================
Hidden Surface Removal
overdraw 部分的开销分析
immediate 两部分开销1overdraw的shading计算2判断遮挡时对depth color buffer 的访问写回
tbr 2没有 只有1 所以上层要有深度从近到远排序 利用earlyz把1去掉
tbdr(powervr) 2没有 1也完全没有 这样就不需要上层对opaque排序了
hsr失效 :
fragment里面替换遮挡像素
discard,sample mask,alpha test,alphatocoverage, blend
所以这些应该只在需要的时候开 即使有切换状态的开销
没有hsr的平台考虑 z pre pass
可以去掉大量overdraw shader计算
开销分析
immediate 1depth pass 的开销 2带宽开销 两个pass都访问depth
tbr 1depth pass 的开销 2没有访问memory的带宽开销(直接在tile上做了),有pass1到pass2 copy frame data的开销(vertex那些)
这样看来这个zprepass的实现 复用了gpu内部的信息--frame data这是怎么做到的--render to vertex buffer 上层做
https://www.csee.umbc.edu/~olano/s2006c03/scheuermann.pdf 这个是dx9的 很旧了 新的直接用gs输出vb再拿来用之类的就可以
所以 带宽limited的app tbr架构的用zprepass会比immediate有效些
=============
mali fpk forward pixel kill
===============
发现个好东西 opengl insights.pdf
=============
总结
1.一个pass开始的时候clear (或者用ext discard) framebuffer--color depth stencil
2.避免反复绑定framebuffer,一开始绑好,之后这块buffer上的cmd尽可能一次提交
3.考虑tbr,tbdr的latency和传统模式有区别需要处理 ocquery用上一帧数据,不要卡住当前帧,vb cb动态更新有copy EGL KHR image pixmap or GLX EXT texture from pixmap这俩扩展也会卡住,考虑latency的意思就是关注那些会卡住当前帧的事情 cpu等gpu返回
4.顶点个数需要测出来 这块显卡的上限 在technique stander的时候做 各个显卡 找到那个16倍flush
5.tbdr不用上层 opaque排序,没有hsr就手写zprepass
6.考虑使用廉价multisample
7.关注用电量高于帧率
=============
我之前忽视了一点 tbdr意味着处理的粒度是一个pass
而不是一个frame 不是只有一次flush才会触发 frame buffer 的read/write
切换rt都会的 read pix也会
在一个pass之内 rt上每块tile vs会全部处理完 在最后deferred 处理fs 之后blit到frame buffer上
--------以上这种理解意味着 如果 场景后面有pp 之后画ui中间切过rt ui透明并不会使rsr失效 因为隐藏面那个pass已经提过frame buffer了
之后额外又有一次 frame buffer 到tile mem的blit 又往上画了透明 ui所以没有多少消耗 (没有让复杂场景的隐藏面消除失效)
=======================所以这段profiling的看法更新一下
profiling 的话 gpu query在此类硬件上 以pass为粒度是可用的,但metal对gpu query的支持不是很友善 是cmd starttime endtime
(运行时 用gpu query拿精确时间 实时显示 是个人认为最有效的方法 )
硬件的处理顺序是 每个pass 所有vertex 之后按tile处理fragment这样拿到的commend buffer里面的 粒度不在pass之内的marker是可用的
此平台推荐方法 debug menu做开关检验impact ,用某些工具
=========
接着这点 我又有了新的认识 这就是为什么opaque transparent分开分俩pass的原因
这样transparent就不会让opaque 的隐藏面消除失效了 opaque的东西已经提交了
opaque-alpla test ---alpha blend 提交顺序
http://cdn.imgtec.com/sdk-documentation/PowerVR+Series5.Architecture+Guide+for+Developers.pdf
接着上面的路往下理解 如果transparent不会让hsr失效
要注意的是什么呢 是opaque里面的alphatest 我这里还真有这个 先opaque后alphaatest 这样会好些 这里还需要继续理解下
应该是当前tile失效 不仅仅是像素失效
---
前面那篇paper里面 framedata framebuffer这个词误导我了 我现在90%+确定粒度是 pass 不是一帧
https://wiki.mozilla.org/Platform/GFX/MobileGPUs
================================
这个事情我今天完全想明白了
xcode 的instrument印证了我的想法
tbdr的粒度就是 逐个pass的对应 instrument里面每个encoder
我之前很好奇 既然是deferred为什么instrument能query到准确时间
这就是因为 tbdr是deferred到一个pass结束的时候 而不是一帧结束
一个pass结束的时候是个笼统的概念 这个是我2.0的认识
更精确的3.0版本的描述是这样的
fbo的unbound
bind new fbo(not quite sure 比如不是mrt的情况下 因为就一个)
geometry 超大导致的强制flush
swapbuffer
readpixel
等等这些 导致framebuffer resolve
然后接着解释instrument 可以发现encoder的时间是准确的 里面drawcall的时间是总的encoder的时间除以里面drawcall的个数
是估摸的 所以hsr就在这里面咯
并且这个结果也和 metal的api是一致的 这一个encoder就对应一块cmdbuffer metal的gpuquery是拿一个cmd的start-endtime
这样也同时意味着unity的底层 在metal这里是分cmd提交的 这样我就也可以像instrument那样拿到每个pass的时间显示出来了
所以接下来我要做实时显示gpu时间在metal上
==========================================
本文一共三篇比较重要的refs 建议阅读它们仨
=================================================
今天做了测试 印证了我之前的看法
测试用例
alphatest 面片
alphablend 面片
opque面片 (触发hsr)
高费ps
pc 100000 Max
iphonex 1000-100 Max
for(int ind; ind<Max;ind++)
{testdata+=exp(testdata);}
测试结果:
1.手机有hsr功能
2.unity 因为把 opque和trandparent作为两个pass alphablend并没有使opaque的hsr失效
alphablend当然会使transparent pass的hsr失效
3.alphatest的不透明部分hsr是生效的 discard部分 当然hsr失效 --这里更新了一点我之前的认识 alphatest的粒度是像素 不是一个obj 现在想想显而易见 扔掉的肯定是那个像素的depth 在那个pipeline里面那时还有什么obj 或者primitive
还有个测试结果顺便贴下 unity 的aplha blend很费alu的bound
alphatest基本没有开销 这三个都用的surfaceshader(这里数据和实时监测数据不一致 xcodeprofile显示alphatest有4ms开销但实时运行没有。。。<1ms)
hsr是perpixel的
这里的测试有个问题 没有排除上述所谓的hsr只是个earlyz 所以需要增加一步测试 渲染次序 把高费ps提前 之后列结果
=======================================
https://developer.apple.com/documentation/metal/mtldevice/ios_and_tvos_devices/about_gpu_family_4
这篇也很推荐
苹果没有公布A7到A10的 tbdr arch技术细节 但是根据这段能看到和powerVR有不同 apple自己的意思是tbdr有所提升 隐含discard那条 和我测下来 alphatest性能不错也是符合的 问题是unity没用metal2。。。。
=====================================================================
https://www.imgtec.com/blog/the-dr-in-tbdr-deferred-rendering-in-rogue/
遇到透明之后 会flush之前的数据从isp到fs
把这个trans pixel和之前hsr的最后一个(visible) blend 这个和测试数据一直相符合
alphatest
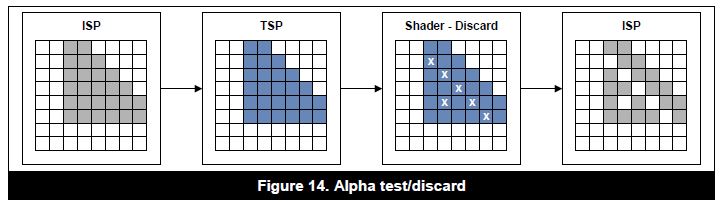
会先刷isp 全部opaque shader算完再把 discard的pixel返回isp
----------------------
powervr有Firmware 把传统驱动(cpu做的)一些graphics process event放到 firmware里减少对cpu的依赖
Tile based Rendering 二 tbr and tbdr 优化建议tiled based deferred rendering的更多相关文章
- Tile based Rendering //后面一段是手机优化建议
https://www.imgtec.com/blog/a-look-at-the-powervr-graphics-architecture-tile-based-rendering/ 一种硬件结构 ...
- 移动GPU渲染原理的流派——IMR、TBR及TBDR
移动GPU渲染原理的流派--IMR.TBR及TBDR 移动GPU相对桌面级的GPU仅仅能算是未长大的小孩子,尽管小孩子在某些场合也能比成人更有优势(比方杂技.柔术之类的表演).但在力量上还是有先天的区 ...
- Firemonkey 原生二维码扫描优化
之前用了ZXing的Delphi版本,运行自带的例子,速度非常慢,与安卓版本的相比查了很多,因此打算使用集成jar的方法,但是总觉得美中不足. 经过一番研究,基本上解决了问题. 主要有两方面的优化: ...
- 百度APP移动端网络深度优化实践分享(二):网络连接优化篇
本文由百度技术团队“蔡锐”原创发表于“百度App技术”公众号,原题为<百度App网络深度优化系列<二>连接优化>,感谢原作者的无私分享. 一.前言 在<百度APP移动端网 ...
- (转载)Android项目实战(二十八):使用Zxing实现二维码及优化实例
Android项目实战(二十八):使用Zxing实现二维码及优化实例 作者:听着music睡 字体:[增加 减小] 类型:转载 时间:2016-11-21我要评论 这篇文章主要介绍了Android项目 ...
- SQL Server性能调优--优化建议(二)
序言 优化建议 库表的合理设计对项目后期的响应时间和吞吐量起到至关重要的地位,它直接影响到了业务所需处理的sql语句的复杂程度,为提高数据库的性能,更多的把逻辑主外键.级联删除.减少check约束.给 ...
- MySQL性能优化方法二:表结构优化
原文链接:http://isky000.com/database/mysql-perfornamce-tuning-schema 很多人都将 数据库设计范式 作为数据库表结构设计“圣经”,认为只要按照 ...
- Tile-Based Deferred Rendering
目前所有的移动设备都使用的是 Tile-Based Deferred Rendering(TBDR) 的渲染架构.TBDR 的基本流程是这样的,当提交渲染命令的时候,GPU 不会立刻进行渲染,而是一帧 ...
- unity优化建议
使用Profiler工具分析内存占用情况 System.ExecutableAndDlls:系统可执行程序和DLL,是只读的内存,用来执行所有的脚本和DLL引用.不同平台和不同硬件得到的值会不一样,可 ...
随机推荐
- C#发送Post请求,带参数,不带参数,指定参数
1.不带参数发送Post请求 /// <summary> /// 指定Post地址使用Get 方式获取全部字符串 /// </summary> /// <param na ...
- canvas 进入游戏点击时苹果手机为什么会闪
canvas 进入游戏点击时苹果手机为什么会闪 ?? 大神门 谁有解决办法???
- 禁止网页右键和复制,ctrl+a都不行。取消页面默认事件【全】。
document.oncontextmenu=new Function("event.returnValue=false");document.onselectstart=new ...
- OpenStack 认证服务 KeyStone连接和用户管理(五)
一) 创建环境变量链接keyston vim adminrc export OS_USERNAME=admin export OS_PASSWORD=redhat export OS_PROJECT_ ...
- react native项目增加devtools工具
第一步:安装react devtools工具 在当前项目中打开命令行,添加react devtools工具,因为运行的工具有九十几M,下载时需要时间,请耐心等待 yarn add react-devt ...
- Codeforces 1082 C. Multi-Subject Competition-有点意思 (Educational Codeforces Round 55 (Rated for Div. 2))
C. Multi-Subject Competition time limit per test 2 seconds memory limit per test 256 megabytes input ...
- Flask实战第51天:cms添加轮播图后端代码逻辑完成
首先,我们需要给轮播图设计一张表,因为轮播图前端要展示,CMS要管理,所以我们在apps下新建个models.py 编辑apps.models.py from exts import db from ...
- JZYZOJ 1382 光棍组织 状压dp
http://172.20.6.3/Problem_Show.asp?id=1382 水得过分了,本来以为要用lzx学长的写法写,抱着试试看的想法写了个特暴力的dp+dfs,过了,真是... ...
- 【图论】Popular Cows
[POJ2186]Popular Cows Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 34752 Accepted: ...
- BZOJ 4802 欧拉函数(Pollard_Rho)
[题目链接] http://www.lydsy.com/JudgeOnline/problem.php?id=4802 [题目大意] 已知N,求phi(N),N<=10^18 [题解] 我们用P ...