Python学习笔记 | 关于python数据对象 hashable & unhashable 的理解
写在前面
Hash(哈希、散列)是一个将大体量数据转化为很小数据的过程,甚至可以仅仅是一个数字,以便我们可以在O(1)的时间复杂度下查询它,所以,哈希对高效的算法和数据结构很重要。
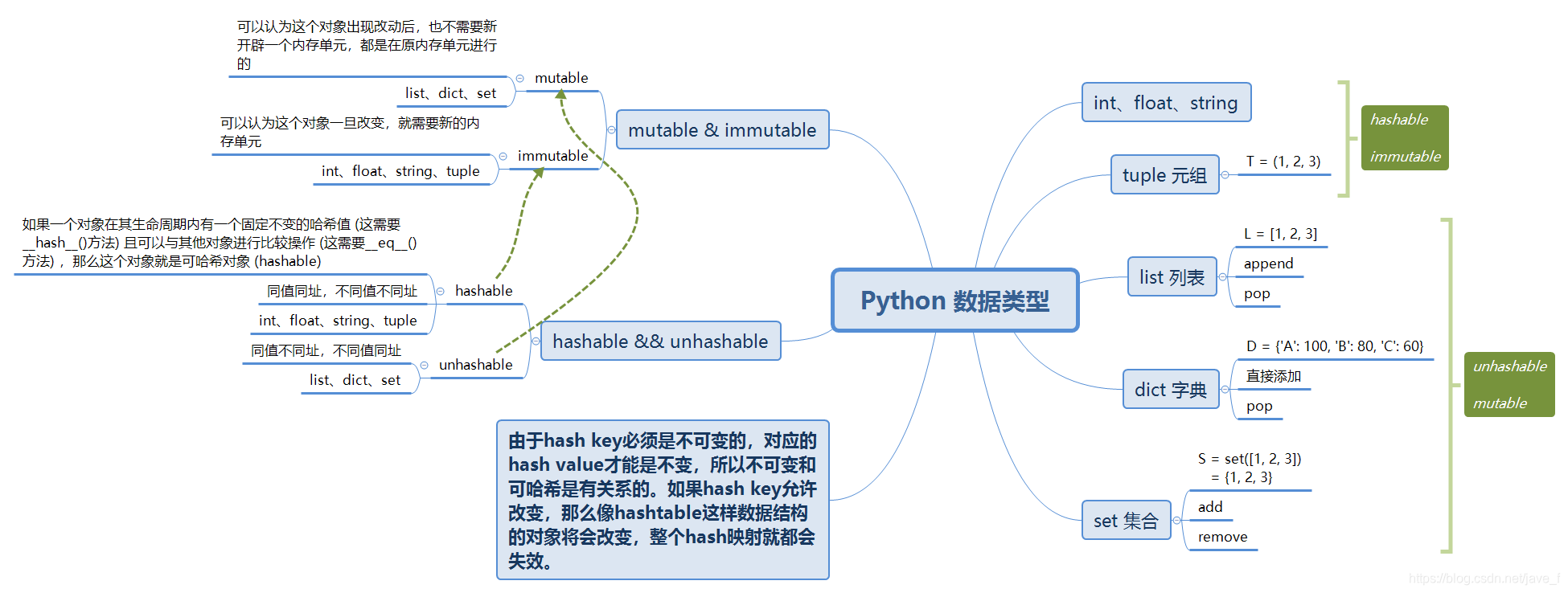
immutable(不可改变性)是指一些对象在被创建之后不会因为某些方式改变,特别是针对任何可以改变哈希对象的哈希值的方式。
由于hash key必须是不可变(immutable)的,对应的hash value才能是不变,所以不可变(immutable)和可哈希(hashable)是有关系的。如果hash key允许改变,那么像hashtable这样数据结构的对象将会改变,整个hash映射就都会失效。
具体以例来看,元组(tuple)对象是不可变的(immutable),字典(dict)的键(key)必须是可以哈希的(hashable)。
hashable & unhashable
官方文档:

如果一个对象在其生命周期内有一个固定不变的哈希值 (这需要__hash__()方法) 且可以与其他对象进行比较操作 (这需要__eq__()或 __cmp__()方法) ,那么这个对象就是可哈希对象 (hashable) 。可哈希对象必须有相同的哈希值才算作相等。
由于字典 (dict) 的键 (key) 和集合 (set) 元素使用到了哈希值,所以只有可哈希 (hashable) 对象才能被用作字典的键和集合的元素。
所有python内置的不可变(immutable)对象(tuple等)都是可哈希的,同时,可变容器 (比如:列表 (list) 或者字典 (dict) ) 都是不可哈希的。用户自定义的类的实例默认情况下都是可哈希的;它们跟其它对象都不相等 (除了它们自己) ,它们的哈希值来自id()方法。
mutable & immutable
(转自 https://www.jianshu.com/p/49f940b2c03e)
首先要明白的是当我们在聊可变与不可变对象时,我们聊的是Python的内置对象。自己定义的对象通常我们不去讨论它是不是可变的,毕竟Python本身是一门动态语言,需要的话我们随时可以给自己定义的这个对象添加其它的属性和方法。
提到Python内置的不可变对象我们能想到的往往有数字、字符串、元组等,提到Python内置的可变对象我们能想到的又有列表、字典等。我们是依据什么把其中的一些对象归于可变,又把另一些归于不可变的呢?
其实这种归类的办法很简单:当我们改变一个对象的值的时候,如果能维持其id值不变,我们就说这个对象是可变,否则我们就说这个对象不可变。
实例检测
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# unhashable 可变对象
# 如list、dict、set:同值不同址,不同值同址
# hashable 不可变对象
# 如int、str、char、tuple:同值同址,不同值不同址
# 怎么判断可变不可变 ?
# 改个值,看id是不是一样,id一样的为可变,则不可哈希。id出现变化,则为不可变,可哈希
# list
L = [1, 2, 3]
L2 = [1, 2, 3]
print('id(L)', id(L))
print('id(L2)', id(L2))
L[0] = 4
print('id(L)', id(L)) # unhashable
'''---------------------
id(L) 2763485176456
id(L2) 2763485176520
id(L) 2763485176456
---------------------'''
# dict
D = {'A':100, 'A-':90, 'B':80, 'C':70}
D2 = {'A':100, 'A-':90, 'B':80, 'C':70}
print('id(D)', id(D))
print('id(D2)', id(D2))
D['A'] = 99
print('id(D)', id(D)) # unhashable
'''---------------------
id(D) 2763485641608
id(D2) 2763485641680
id(D) 2763485641608
---------------------'''
# set
S = set([1, 2, 3])
S2 = set([1, 2, 3])
print('id(S)', id(S))
print('id(S2)', id(S2))
S.remove(1)
print('id(S)', id(S)) # unhashable
'''---------------------
id(S) 1905131096776
id(S2) 1905131094088
id(S) 1905131096776
---------------------'''
# int
a = 666
b = 666
print('hash(a):', hash(a))
print('hash(b):', hash(b))
print('id(a)', id(a))
print('id(b)', id(b))
a = 555
print('hash(a):', hash(a))
print('id(a)', id(a)) # hashable
'''---------------------
hash(a): 666
hash(b): 666
id(a) 1905130526128
id(b) 1905130526128
hash(a): 555
id(a) 1905131082192
---------------------'''
# float
a = 1.2
b = 1.2
print('hash(a):', hash(a))
print('hash(b):', hash(b))
print('id(a)', id(a))
print('id(b)', id(b))
a = 1.1
print('hash(a):', hash(a))
print('id(a)', id(a)) # hashable
'''---------------------
hash(a): 461168601842738689
hash(b): 461168601842738689
id(a) 2682206597600
id(b) 2682206597600
hash(a): 230584300921369601
id(a) 2682206597624
---------------------'''
# str
c = 'ZJ'
d = 'ZJ'
print('id(c)', id(c))
print('id(d)', id(d))
c = 'YF'
print('id(a)', id(c)) # hashable
'''---------------------
hash(c): 3106900240887856397
hash(d): 3106900240887856397
id(c) 1642181677384
id(d) 1642181677384
hash(c): -2749512413466868010
id(c) 1642181677608
---------------------'''
# tuple
T = (1, 2, 3)
T2 = (1, 2, 3)
print('hash(T):', hash(T))
print('hash(T2):', hash(T2))
print('id(T)', id(T))
print('id(T2)', id(T2))
'''---------------------
hash(T): 2528502973977326415
hash(T2): 2528502973977326415
id(T) 2325794115656
id(T2) 2325794115656
---------------------'''
# tuple2
T = (1, [1, 2], 3)
T2 = (1, [1, 2], 3)
print('id(T)', id(T))
print('id(T2)', id(T2))
T[1][0] = 4
print('id(T)', id(T)) # hashable
'''---------------------
id(T) 2979746926664
id(T2) 2979747407048
id(T) 2979746926664
---------------------'''
# 补充说明
# 虽然字符串有个replace()方法,也确实变出了'Abc',但变量a最后仍是'abc'
a = 'abc'
print('a:', a)
print('a:', a.replace('a', 'A'))
print('a:', a)
'''---------------------
a: abc
a: Abc
a: abc
---------------------'''
# 这是因为 a.replace('a', 'A') 相当于
b = a.replace('a', 'A') # replace方法创建了一个新字符串'Abc'并返回
# Summary:
# 对于不变对象来说, 调用对象自身的任意方法, 也不会改变该对象自身的内容。
# 相反, 这些方法会创建新的对象并返回, 这样, 就保证了不可变对象本身永远是不可变的。
>>> class A:
... pass
...
>>> cls_a = A()
>>> cls_b = A()
>>> cls_a
<A object at 0x000001890DB69898>
>>> cls_b
<A object at 0x000001890DB6EDD8>
>>> cls_a.__hash__()
-9223371931345262199
>>> cls_b.__hash__()
-9223371931345260835
>>> id(cls_a)
1688152217752
>>> id(cls_b)
1688152239576
# 这里两个对象(cls_a和cls_b)哈希值和id都不一样
# 由于用户自定义的类的实例其哈希值与id有关,所以id值和哈希值都不相同,就如官方文档里说的,实例只跟自己相等。
Python内置的可哈希对象可以使用hash()或者__hash__()方法来查看它的哈希值,如:a.__hash__()或者hash(a),而id()函数用于获取对象的内存地址。
后续思考
使用key-value存储结构的dict在Python中非常有用,选择不可变对象作为key很重要,最常用的key是字符串。
tuple虽然是不可变对象,但试试把(1, 2, 3)和(1, [2, 3])放入dict或set中
# tuple是不变对象,试试把(1, 2, 3)和(1, [2, 3])放入dict或set中
T = (1, 2, 3)
T2 = (1, [2, 3])
D = {T: 100}
print('D:', D)
'''-----------------
D: {(1, 2, 3): 100}
-----------------'''
# D2 = {T2: 100} # TypeError: unhashable type: 'list'
# print('D2:', D2)
S = set([T])
print('S:', S)
'''-----------------
S: {(1, 2, 3)}
-----------------'''
# S = set([T2]) # TypeError: unhashable type: 'list'
# print('S:', S)
参考文章
- 聊一聊Python中的hashable和immutable
- python-对象之hashable&unhashable与immutable&mutable
- What do you mean by hashable in Python?

Python学习笔记 | 关于python数据对象 hashable & unhashable 的理解的更多相关文章
- python学习笔记:python对象
一.python对象 python使用对象模型来存储数据,构造任何类型的值都是一个对象.所有的python对象都拥有三个特性:身份.类型和值. 身份:每个对象都有一个唯一的身份标识自己,对象的身份可以 ...
- Python学习笔记之—— File(文件) 对象常用函数
file 对象使用 open 函数来创建,下表列出了 file 对象常用的函数: 1.file.close() close() 方法用于关闭一个已打开的文件.关闭后的文件不能再进行读写操作, 否则会触 ...
- 吴裕雄--天生自然python学习笔记:WEB数据抓取与分析
Web 数据抓取技术具有非常巨大的应用需求及价值, 用 Python 在网页上收集数据,不仅抓取数据的操作简单, 而且其数据分析功能也十分强大. 通过 Python 的时lib 组件中的 urlpar ...
- Python学习笔记:外部数据的输入、存储等操作
查看current工作路径: >>> import os >>> os.getcwd() 'D:\\python' 更改工作路径: >>> os. ...
- python 学习笔记 9 -- Python强大的自省简析
1. 什么是自省? 自省就是自我评价.自我反省.自我批评.自我调控和自我教育,是孔子提出的一种自我道德修养的方法.他说:“见贤思齐焉,见不贤而内自省也.”(<论语·里仁>)当然,我们今天不 ...
- python学习笔记(一):python简介和入门
最近重新开始学习python,之前也自学过一段时间python,对python还算有点了解,本次重新认识python,也算当写一个小小的教程.一.什么是python?python是一种面向对象.解释型 ...
- Python学习笔记 - day12 - Python操作NoSQL
NoSQL(非关系型数据库) NoSQL,指的是非关系型的数据库.NoSQL有时也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称.用于超大规模数据的存储.(例如 ...
- python 学习笔记一——Python安装和IDLE使用
好吧,一直准备学点啥,前些日子也下好了一些python电子书,但之后又没影了.年龄大了,就是不爱学习了.那就现在开始吧. 安装python 3 Mac OS X会预装python 2,Linux的大多 ...
- python学习笔记(python简史)
一.python介绍 python的创始人为吉多·范罗苏姆(Guido van Rossum) 目前python主要应用领域: ·云计算 ·WEB开发 ·科学运算.人工智能 ·系统运维 ·金融:量化交 ...
随机推荐
- NOI2018游记&我的OI历程
day1 今天是报到日,坐着早上9点的飞机到了长沙,午饭时间到达雅礼洋湖. 宿舍还是一模一样,虽然是在女生宿舍. wifi信号还是一样的德行,刻意避开了宿舍内,只好把手机放在窗台上开热点. 饭菜还是如 ...
- ImportError: libQtTest.so.4: cannot open shared
错误: import cv2 File , in <module> from .cv2 import * ImportError: libQtTest.so.: cannot open s ...
- Django【进阶】数据库查询性能相关
之前项目中没有考虑过数据库查询关于效率的问题,如果请求量大,数据庞大,不考虑性能的话肯定不行. tips:如图之前我们遇到过,当添加一张表时,作为原来表的外键,要给个默认值,现在我们写null ...
- printk %pF %pS含义【转】
作者:啐楼链接:https://www.zhihu.com/question/37769890/answer/73532192来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出 ...
- 关于might_sleep的一点说明【转】
转自:http://blog.csdn.net/chen_chuang_/article/details/48462575 这个函数我在看代码时基本上是直接忽略的(因为我知道它实际上不干什么事),不过 ...
- 为什么要用Jedis连接池+浅谈jedis连接池使用
为什么要使用Jedis连接池 Redis作为缓存数据库理论上和MySQL一样需要客户端和服务端建立起来连接进行相关操作,使用MySQL的时候相信大家都会使用一款开源的连接池,例如C3P0.因为直连会消 ...
- yii2 一对多关系的对分页造成的影响
下面代码中关联descies时,匹配较多,造成分页数不对,需要加条件限制: $model = User::find() ->joinWith('app') ->joinWith(['des ...
- 使用js创建select option
var v_select = document.getElementById("selectA"); var v_option = document.createElement( ...
- python基础(2)---数据类型
1.python版本间的差异: 2.x与3.x版本对比 version 2.x 3.x print print " "或者print()打印都可以正常输出 只能print()这种形 ...
- git+jenkins在windows机器上新建一个slave节点【转载】
转至博客:上海-悠悠 前言 我们在跑自动化项目的时候,希望有单独的测试机能跑自动化项目,并且能集成到jenkins上构建任务.如果公司已经有jenkins环境了,那无需重新搭建. 只需在现有的平台基础 ...