java 并发(五)---AbstractQueuedSynchronizer(5)
问题 :
- ArrayBlockQueue 和 LinkedBlockQueue 的区别
- 两者的实现又是怎么样的
- 应用场景
BlockingQueue
概述
blockingQueue 是个接口,从名字上看就可以知道它是个阻塞队列,里面定义了增删改查的方法。四种不同的方法用于不同的场景中使用:
1、抛出异常;
2、返回特殊值(null 或 true/false,取决于具体的操作);
3、阻塞等待此操作,直到这个操作成功;
4、阻塞等待此操作,直到成功或者超时指定时间。总结如下:

下面我们重点看一下 put 方法 和 take 方法 。这两个方法都会阻塞。
ArrayBlockQueue
ArrayBlockQueue队列使用了一个锁和两个ConditionObject 对象来控制的对象的put 和 take 。
源码分析
1 public void put(E e) throws InterruptedException {
2 checkNotNull(e);
3 final ReentrantLock lock = this.lock;
4 //获取锁,要是获取不到就会放在sync queue ,可中断
5 lock.lockInterruptibly();
6 try {
7 while (count == items.length)
8 //当前数量达到了满的状态,向 NotFull wait queue 尾部加入一个元素 等待唤醒
9 notFull.await();
10 enqueue(e);
11 } finally {
12 lock.unlock();
13 }
14 }
1 /**
2 * Inserts element at current put position, advances, and signals.
3 * Call only when holding lock.
4 *
5 * NotEmpty wait queue 队列唤醒,就是NotEmpty wait queue 里面要是有元素的话
6 * 就会上移一个元素到同步队列
7 *
8 */
9 private void enqueue(E x) {
10 // assert lock.getHoldCount() == 1;
11 // assert items[putIndex] == null;
12 final Object[] items = this.items;
13 items[putIndex] = x;
14 if (++putIndex == items.length)
15 putIndex = 0;
16 count++;
17 notEmpty.signal();
18 }
1 //可以看到返回值是是从对象数组中取出一个数据,同时唤醒 NotFull wait queue()
2 private E dequeue() {
3 // assert lock.getHoldCount() == 1;
4 // assert items[takeIndex] != null;
5 final Object[] items = this.items;
6 @SuppressWarnings("unchecked")
7 E x = (E) items[takeIndex];
8 items[takeIndex] = null;
9 if (++takeIndex == items.length)
10 takeIndex = 0;
11 count--;
12 if (itrs != null)
13 itrs.elementDequeued();
14 notFull.signal();
15 return x;
16 }
假如出现如下场景,四个线程同时先执行take (),那么当第一个线程进入
LinkedBlockQueue
LinkedBlockQueue 使用了两个锁,一把 takeLock 和一把 putLock ,还有两个ConditionObject 对象来并发控制。
源码分析
这里假设有一个零件小H需要进入工厂加工的情景。
1 //小H将准备进入工厂被加工了,目前在工厂外排队
2 public void put(E e) throws InterruptedException {
3 if (e == null) throw new NullPointerException();
4 // Note: convention in all put/take/etc is to preset local var
5 // holding count negative to indicate failure unless set.
6 int c = -1;
7 Node<E> node = new Node<E>(e);
8 final ReentrantLock putLock = this.putLock;
9 final AtomicInteger count = this.count;
10 //获取锁
11 putLock.lockInterruptibly();
12 try {
13 /*
14 * Note that count is used in wait guard even though it is
15 * not protected by lock. This works because count can
16 * only decrease at this point (all other puts are shut
17 * out by lock), and we (or some other waiting put) are
18 * signalled if it ever changes from capacity. Similarly
19 * for all other uses of count in other wait guards.
20 */
21 while (count.get() == capacity) {
22 //notFull wait queue 容量满了,阻塞
23 notFull.await();
24 }
25 //加入队列,两种情况走到这里 : 1.别唤醒,由于容量满了 2.没满直接加入进来
26 enqueue(node);
27 c = count.getAndIncrement();
28 //要是此时,容量还有空余通知后面的进来
29 if (c + 1 < capacity)
30 notFull.signal();
31 } finally {
32 //释放锁
33 putLock.unlock();
34 }
35 //里面只有本来是没有元素的,现在加入了一个,唤醒 NotEmpty
36 if (c == 0)
37 signalNotEmpty();
38
39 }
1 //小H进入了工厂,将要被拿去加工了
2 public E take() throws InterruptedException {
3 E x;
4 int c = -1;
5 final AtomicInteger count = this.count;
6 final ReentrantLock takeLock = this.takeLock;
7 //获得 takeLock
8 takeLock.lockInterruptibly();
9 try {
10 //要是此时容量是空的,空的必定是取不出东西,那么阻塞
11 while (count.get() == 0) {
12 notEmpty.await();
13 }
14 //取出一个元素
15 x = dequeue();
16 c = count.getAndDecrement();
17 //只要容量大于1 ,唤醒 notEmpty,意味着“通知下一位进来被加工”
18 if (c > 1)
19 notEmpty.signal();
20 } finally {
21 takeLock.unlock();
22 }
23 //假如此时容量已满,既然拿出一个被加工了,那么意味着可以通知外面排队的进来多点被加工
24 if (c == capacity)
25 signalNotFull();
26 return x;
27 }
take 方法注意一下,当容量没有元素的时候就会调用 notEmpty.await() , ConditionObject的 await 方法会释放掉当前线程所有的锁,并在wait queue 中阻塞。(此处不理解,先要了解 ConditionObject 的用法 ),所有当有多个线程在容量没元素的情况下去获取元素,都会阻塞,等待唤醒。
LinkedListQueue 中,要想唤醒线程就要获取锁,为了尽量少地获取锁或是相互调用,“cascading notifies”将被使用。
cascading notifies 是什么
LinkedBlockQueue 开头有一段注释,为了最小限度地使put 操作获取takeLock 和 putLock ,使用了cascading notifies 。什么意思呢?(第二段注解可以看到是关于实现弱一致性的迭代器)
1 /*
2 * A variant of the "two lock queue" algorithm. The putLock gates
3 * entry to put (and offer), and has an associated condition for
4 * waiting puts. Similarly for the takeLock. The "count" field
5 * that they both rely on is maintained as an atomic to avoid
6 * needing to get both locks in most cases. Also, to minimize need
7 * for puts to get takeLock and vice-versa, cascading notifies are
8 * used. When a put notices that it has enabled at least one take,
9 * it signals taker. That taker in turn signals others if more
10 * items have been entered since the signal. And symmetrically for
11 * takes signalling puts. Operations such as remove(Object) and
12 * iterators acquire both locks.
13 *
14 * Visibility between writers and readers is provided as follows:
15 *
16 * Whenever an element is enqueued, the putLock is acquired and
17 * count updated. A subsequent reader guarantees visibility to the
18 * enqueued Node by either acquiring the putLock (via fullyLock)
19 * or by acquiring the takeLock, and then reading n = count.get();
20 * this gives visibility to the first n items.
21 *
22 * To implement weakly consistent iterators, it appears we need to
23 * keep all Nodes GC-reachable from a predecessor dequeued Node.
24 * That would cause two problems:
25 * - allow a rogue Iterator to cause unbounded memory retention
26 * - cause cross-generational linking of old Nodes to new Nodes if
27 * a Node was tenured while live, which generational GCs have a
28 * hard time dealing with, causing repeated major collections.
29 * However, only non-deleted Nodes need to be reachable from
30 * dequeued Nodes, and reachability does not necessarily have to
31 * be of the kind understood by the GC. We use the trick of
32 * linking a Node that has just been dequeued to itself. Such a
33 * self-link implicitly means to advance to head.next.
34 */
从字面上意思翻译过来就是“流水式通知/唤醒” ,我们设想一下要是 这是一个生产和消费队列,有多个消费者,当生产以后,马上就通知了一下消费者,那么我的put 每回都要获取 两把锁(一把用于放进元素,一把用于通知 NotEmpty queue 有元素进来了)。为了尽量地减少锁的获取,在put 方法 :
1 //put 方法
2 if (c == 0)
3 signalNotEmpty();
4
5
6 //take 方法
7 if (c > 1)
8 notEmpty.signal();
只有在第一个元素进来时就去唤醒,后面的要是多个消费者阻塞在 take 方法中,有一个被唤醒消费后,就会完成后又唤醒下一个,直至消费完成。
self-link是什么
自链接。在注释的最后一段阐述了这个问题。为了实现“弱一致性的”迭代器,我们需要让所有从被删除的前任(前面指向你的节点)节点中的所有节点都是 可回收的,即被删除了都应该是可回收的。那么这样就会出现两个问题 :
- 可能导致一个怀有恶意的迭代器会占用大量内容空间
- 节点跨代引用问题
以下解释一下出现这两个问题的原因。
以下图片和部分分析来自参考资料,感谢那位作者,写得很不错!
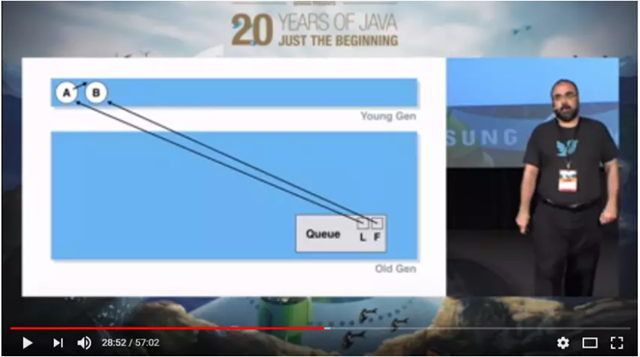
两个新元素A和B入队列,在Young Gen
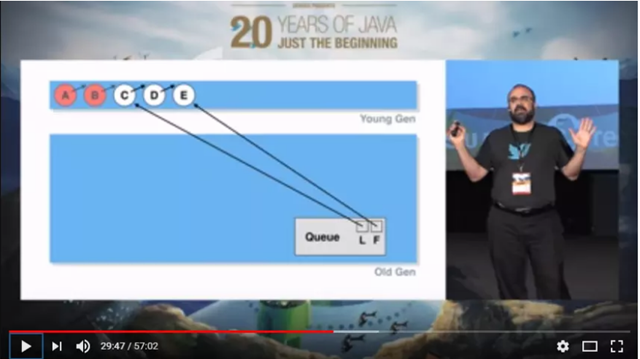
A和B出队列,新元素C D E入队列,这时候A和B还在Young Gen,在minor gc的时候直接回收掉
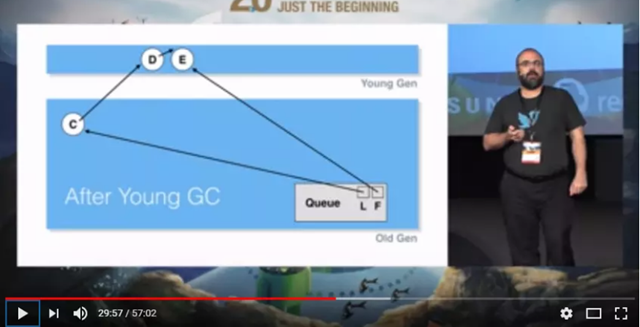
C元素进入Old Gen
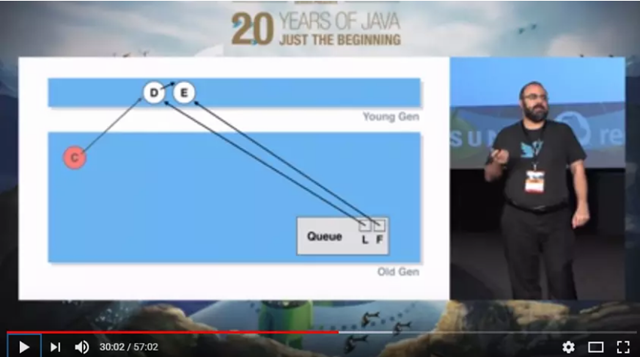
C元素出队列,但是是在Old Gen,需要Major GC才会回收,而Major GC发生的频率比较低,C会在Old Gen保留比较长时间
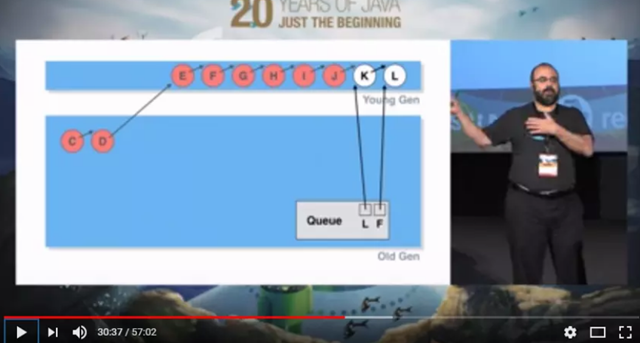
D到J都已经出队列,但是由于有Old Gen的C的引用,在minor GC的时候不会回收
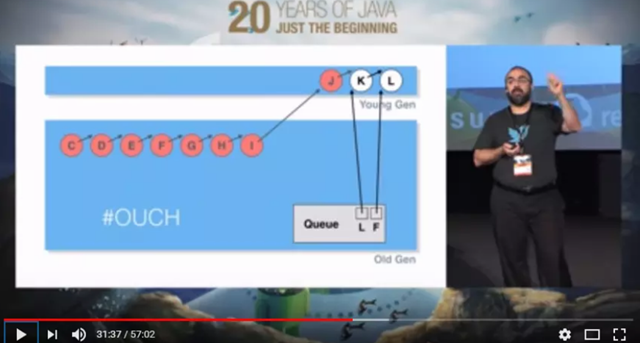
D-I全部进入Old Gen
跨代引用造成的后果是大量本应该在Minor GC回收的对象进入Old Gen,在Minor GC的时候需要复制大量的对象,在Major的时候需要回收更多对象,而且还不好并行回收,因此GC压力很大。
这是 LinkedBlockQueue 的迭代器。
1 public Iterator<E> iterator() {
2 return new Itr();
3 }
4
1 private class Itr implements Iterator<E> {
2 /*
3 * Basic weakly-consistent iterator. At all times hold the next
4 * item to hand out so that if hasNext() reports true, we will
5 * still have it to return even if lost race with a take etc.
6 */
7
8 private Node<E> current;
9 private Node<E> lastRet;
10 private E currentElement;
11
12 Itr() {
13 fullyLock();
14 try {
15 current = head.next;
16 if (current != null)
17 currentElement = current.item;
18 } finally {
19 fullyUnlock();
20 }
21 }
22
23 public boolean hasNext() {
24 return current != null;
25 }
26
27 /**
28 * Returns the next live successor of p, or null if no such.
29 *
30 * Unlike other traversal methods, iterators need to handle both:
31 * - dequeued nodes (p.next == p)
32 * - (possibly multiple) interior removed nodes (p.item == null)
33 */
34 private Node<E> nextNode(Node<E> p) {
35 for (;;) {
36 Node<E> s = p.next;
37 if (s == p)
38 return head.next;
39 if (s == null || s.item != null)
40 return s;
41 p = s;
42 }
43 }
44
45 public E next() {
46 fullyLock();
47 try {
48 if (current == null)
49 throw new NoSuchElementException();
50 E x = currentElement;
51 lastRet = current;
52 current = nextNode(current);
53 currentElement = (current == null) ? null : current.item;
54 return x;
55 } finally {
56 fullyUnlock();
57 }
58 }
1 private E dequeue() {
2 // assert takeLock.isHeldByCurrentThread();
3 // assert head.item == null;
4 Node<E> h = head;
5 Node<E> first = h.next;
6 h.next = h; // help GC
7 head = first;
8 E x = first.item;
9 first.item = null;
10 return x;
11 }
说到并发集合的迭代器不得不提到官方文档中这段话。就是他们的 Iterators 和 Spliterators 提供的 “弱一致性”相比于 “fast-fail”的区别 : weakly consistent iterators
Most concurrent Collection implementations (including most Queues) also differ from the usual
java.utilconventions in that their Iterators and Spliterators provide weakly consistent rather than fast-fail traversal:
- they may proceed concurrently with other operations
- they will never throw
ConcurrentModificationException - they are guaranteed to traverse elements as they existed upon construction exactly once, and may (but are not guaranteed to) reflect any modifications subsequent to construction.
再回到源码,生成迭代器的时候只是返回一个Itr对象,在Itr的构造方法内会调用next 方法。我们设想以下的情景 :
- 队列中最开始有A B C D四个元素
- 这个时候生成迭代器,current指向A,currentElement值为A
- 迭代还没开始,A B C出队列,且都是self-link,队列中只剩下D
- 由于A还有current引用,B和C 没有其他引用,这个时候如果GC了B和C可以回收掉
- 开始迭代,由于current指向A,不为空,且currentElement的值为A,因此A肯定会输出,然后再输出D,这里就体现了weakly consistent,A已经出队列,但是迭代的时候却还在。
因此一个简单的
self-link就解决了上面所说单向链表的跨代GC问题。如果把h.next = h改成h.next = null可以吗?还是考虑上面的情况,在2中current指向A,但是A指向null,3和4都没问题,GC正常;但是5的时候会出问题,current指向A,不为空,且currentElement的值为A,因此A还是会输出;在nextNode(A)函数中Node<E> s = p.next;为null,s==null成立,直接返回null,迭代结束,不会输出D。
总结来说,self-link解决了两个问题:1. GC跨代引用问题 2. 作为已经出队列的元素的标识,这里可以看Node类中的注释,和开头贴的注释的最后一句:self-link含蓄地暗示要跳到head.next。
ArrayBlockQueue 和 LinkedBlockQueue 的异同
同 :
- 都是支持有界的(bounded)、阻塞的(blocking)的队列,按照FIFO(先进先出)原则出现元素
- 内部实现都是使用到了ReentranLock 和 ConditionObject
- 都适用于生产者-消费者的模式
异 :
- ArrayBlockingQueue 初始化时可以指定大小,LinkBlockingQueue可以不指定,默认为 65535
- ArrayBlockingQueue 是基于数组操作的,常常在大多数并发场景下比 LinkBlockingQueue(基于链表操作的)有更好的性能官方文档
- ArrayBlockingQueue 使用一把锁控制放入和拿出,而 LinkBlockingQueue 使用两把锁控制放入和拿出(即锁分离)
SynchronousQueue
Synchronous 应用场景
Synchronous queues are similar to rendezvous channels used in CSP and Ada. They are well suited for handoff designs, in which an object running in one thread must sync up with an object running in another thread
in order to hand it some information, event, or task.
同步队列类似于CSP和Ada中使用的集合点通道。它们非常适合切换设计,其中在一个线程中运行的对象必须与在另一个线程中运行的对象同步为了传递一些信息,事件或任务。
首先看一下构造方法。同步队列的原理就是一个生产者对应一个消费者,一一对应,等不到就阻塞,等到了就牵走。
1 /**
2 * Creates a {@code SynchronousQueue} with nonfair access policy.
3 */
4 public SynchronousQueue() {
5 this(false);
6 }
7
8 /**
9 * Creates a {@code SynchronousQueue} with the specified fairness policy.
10 *
11 * @param fair if true, waiting threads contend in FIFO order for
12 * access; otherwise the order is unspecified.
13 */
14 public SynchronousQueue(boolean fair) {
15 transferer = fair ? new TransferQueue<E>() : new TransferStack<E>();
16 }
同步队列分为公平模式和非公平模式,可以看到默认的非公平采用的 TransferStack ,而公平模式采用的是 TransferQueue,同步队列的操作实际上就是在这个 transfer 中进行操作的,我们先来看一下默认的非公平模式 ,既然是非公平模式,那么一定不是按顺序。
Stack和Queue 各自的优势是什么?(官方文档)
The performance of the two is generally similar. Fifo usually supports higher throughput under
contention but Lifo maintains higher thread locality in common applications.
FIFO: First in, First out.先进先出。
LIFO: Last in, First out.后进先出。
FIFO 通常支持更高的吞吐量在同等条件下,而 LIFO 则可以保持更好的线程局部性在大部分应用中。
我们首先看源码之前需要知道 : FULFILL 指的是一个消费者和一个生产者进行配对。我们假设有这么样的一个流程 :
put –> put –> take –> take
思路跟着流程走一遍。先看非公平模式下的
TransferStack
1 public void put(E e) throws InterruptedException {
2 if (e == null) throw new NullPointerException();
3 if (transferer.transfer(e, false, 0) == null) {
4 Thread.interrupted();
5 throw new InterruptedException();
6 }
7 }
1 /**
2 * Retrieves and removes the head of this queue, waiting if necessary
3 * for another thread to insert it.
4 *
5 * @return the head of this queue
6 * @throws InterruptedException {@inheritDoc}
7 */
8 public E take() throws InterruptedException {
9 E e = transferer.transfer(null, false, 0);
10 if (e != null)
11 return e;
12 Thread.interrupted();
13 throw new InterruptedException();
14 }
1
2 @SuppressWarnings("unchecked")
3 E transfer(E e, boolean timed, long nanos) {
4 /*
5 * Basic algorithm is to loop trying one of three actions:
6 *
7 * 1. If apparently empty or already containing nodes of same
8 * mode, try to push node on stack and wait for a match,
9 * returning it, or null if cancelled.
10 *
11 * 2. If apparently containing node of complementary mode,
12 * try to push a fulfilling node on to stack, match
13 * with corresponding waiting node, pop both from
14 * stack, and return matched item. The matching or
15 * unlinking might not actually be necessary because of
16 * other threads performing action 3:
17 *
18 * 3. If top of stack already holds another fulfilling node,
19 * help it out by doing its match and/or pop
20 * operations, and then continue. The code for helping
21 * is essentially the same as for fulfilling, except
22 * that it doesn't return the item.
23 */
24
25 SNode s = null; // constructed/reused as needed
26 //确定模式,模式的作用是识别是消费者还是生产者
27 int mode = (e == null) ? REQUEST : DATA;
28
29 for (;;) {
30 SNode h = head;
31 //我们的流程是先两次put ,那么两次肯定走这里
32 if (h == null || h.mode == mode) { // empty or same-mode
33 //时间到了
34 if (timed && nanos <= 0) { // can't wait
35 if (h != null && h.isCancelled())
36 casHead(h, h.next); // pop cancelled node
37 else
38 return null;
39
40 //时间没到,cas成功后阻塞
41 } else if (casHead(h, s = snode(s, e, h, mode))) {
42 SNode m = awaitFulfill(s, timed, nanos);
43 if (m == s) { // wait was cancelled
44 clean(s);
45 return null;
46 }
47
48 if ((h = head) != null && h.next == s)
49 casHead(h, s.next); // help s's fulfiller
50 return (E) ((mode == REQUEST) ? m.item : s.item);
51 }
52 } else if (!isFulfilling(h.mode)) { // try to fulfill 当前不是fulfill模式
53 if (h.isCancelled()) // already cancelled
54 casHead(h, h.next); // pop and retry
55 else if (casHead(h, s=snode(s, e, h, FULFILLING|mode))) { //创建一个模式为fullfill的节点,head指向它
56 for (;;) { // loop until matched or waiters disappear
57 SNode m = s.next; // m is s's match
58 if (m == null) { // all waiters are gone
59 casHead(s, null); // pop fulfill node
60 s = null; // use new node next time
61 break; // restart main loop
62 }
63 SNode mn = m.next;
64 //这是就是真正匹配的地方,匹配不到,说明有人在竞争,那么跳过这一个,循环继续!!继续抢
65 if (m.tryMatch(s)) {
66 casHead(s, mn); // pop both s and m 匹配到了,head指针指向匹配到的元素的后面一个元素
67 return (E) ((mode == REQUEST) ? m.item : s.item);
68 } else // lost match
69 s.casNext(m, mn); // help unlink
70 }
71 }
72 } else { // help a fulfiller
73 //走到这说明有人正在匹配,帮助它快点匹配,增加 CAS 的次数
74 SNode m = h.next; // m is h's match
75 if (m == null) // waiter is gone
76 casHead(h, null); // pop fulfilling node
77 else {
78 SNode mn = m.next;
79 if (m.tryMatch(h)) // help match
80 casHead(h, mn); // pop both h and m
81 else // lost match
82 h.casNext(m, mn); // help unlink
83 }
84 }
85 }
86 }
代码苍白无力,上图。
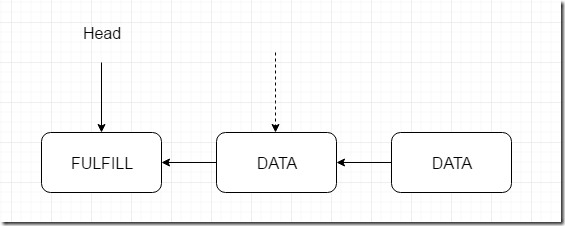
图一 只有一个在匹配的情况
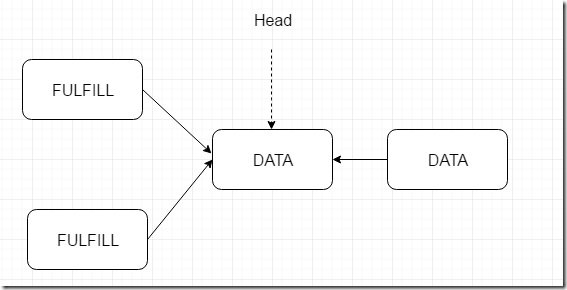
图二 两个消费者竞争匹配
那么有没有可能出现下面的情况呢?
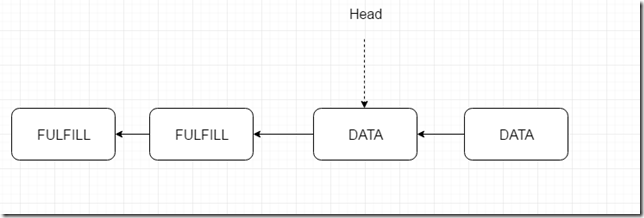
是不可能的,大家可以推一下。
我们可以看到transferStack,新元素的进入都是和 Stack 一样的,最后进的最先被消费。下面是阻塞的方法,看注释
1 SNode awaitFulfill(SNode s, boolean timed, long nanos) {
2 /*
3 * When a node/thread is about to block, it sets its waiter
4 * field and then rechecks state at least one more time
5 * before actually parking, thus covering race vs
6 * fulfiller noticing that waiter is non-null so should be
7 * woken.
8 *
9 * When invoked by nodes that appear at the point of call
10 * to be at the head of the stack, calls to park are
11 * preceded by spins to avoid blocking when producers and
12 * consumers are arriving very close in time. This can
13 * happen enough to bother only on multiprocessors.
14 *
15 * The order of checks for returning out of main loop
16 * reflects fact that interrupts have precedence over
17 * normal returns, which have precedence over
18 * timeouts. (So, on timeout, one last check for match is
19 * done before giving up.) Except that calls from untimed
20 * SynchronousQueue.{poll/offer} don't check interrupts
21 * and don't wait at all, so are trapped in transfer
22 * method rather than calling awaitFulfill.
23 */
24 final long deadline = timed ? System.nanoTime() + nanos : 0L;
25 Thread w = Thread.currentThread();
26 int spins = (shouldSpin(s) ?
27 (timed ? maxTimedSpins : maxUntimedSpins) : 0);
28 for (;;) {
29 if (w.isInterrupted())
30 s.tryCancel();
31 SNode m = s.match;
32 if (m != null)
33 return m;
34 if (timed) {
35 nanos = deadline - System.nanoTime();
36 if (nanos <= 0L) {
37 s.tryCancel();
38 continue;
39 }
40 }
41 if (spins > 0)
42 spins = shouldSpin(s) ? (spins-1) : 0;
43 else if (s.waiter == null)
44 s.waiter = w; // establish waiter so can park next iter
45 else if (!timed)
46 LockSupport.park(this);
47 else if (nanos > spinForTimeoutThreshold)
48 LockSupport.parkNanos(this, nanos);
49 }
50 }
51
可以看到要是可以自旋就采取自旋的方式,提升性能。
TransferQueue
公平模式下,使用 TransferQueue ,内部有一个Head 还有一个Tail ,新元素插入的都是在tail后面增加。而被消费的元素都是head ,这就是公平模式,一个个需要排队进行。
节点有一个 isData 变量用来识别是不是生产者还是消费者。
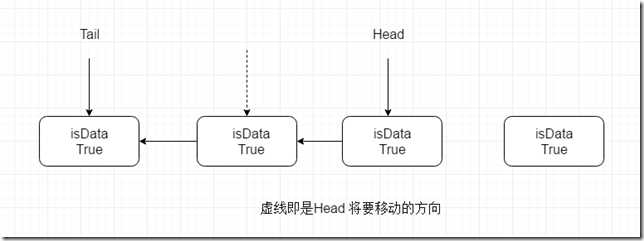
下面源码分析来自 参考文章
1 /**
2 * Puts or takes an item.
3 */
4 Object transfer(Object e, boolean timed, long nanos) {
5
6 QNode s = null; // constructed/reused as needed
7 boolean isData = (e != null);
8
9 for (;;) {
10 QNode t = tail;
11 QNode h = head;
12 if (t == null || h == null) // saw uninitialized value
13 continue; // spin
14
15 // 队列空,或队列中节点类型和当前节点一致,
16 // 即我们说的第一种情况,将节点入队即可。读者要想着这块 if 里面方法其实就是入队
17 if (h == t || t.isData == isData) { // empty or same-mode
18 QNode tn = t.next;
19 // t != tail 说明刚刚有节点入队,continue 即可
20 if (t != tail) // inconsistent read
21 continue;
22 // 有其他节点入队,但是 tail 还是指向原来的,此时设置 tail 即可
23 if (tn != null) { // lagging tail
24 // 这个方法就是:如果 tail 此时为 t 的话,设置为 tn
25 advanceTail(t, tn);
26 continue;
27 }
28 //
29 if (timed && nanos <= 0) // can't wait
30 return null;
31 if (s == null)
32 s = new QNode(e, isData);
33 // 将当前节点,插入到 tail 的后面
34 if (!t.casNext(null, s)) // failed to link in
35 continue;
36
37 // 将当前节点设置为新的 tail
38 advanceTail(t, s); // swing tail and wait
39 // 看到这里,请读者先往下滑到这个方法,看完了以后再回来这里,思路也就不会断了
40 Object x = awaitFulfill(s, e, timed, nanos);
41 // 到这里,说明之前入队的线程被唤醒了,准备往下执行
42 if (x == s) { // wait was cancelled
43 clean(t, s);
44 return null;
45 }
46
47 if (!s.isOffList()) { // not already unlinked
48 advanceHead(t, s); // unlink if head
49 if (x != null) // and forget fields
50 s.item = s;
51 s.waiter = null;
52 }
53 return (x != null) ? x : e;
54
55 // 这里的 else 分支就是上面说的第二种情况,有相应的读或写相匹配的情况
56 } else { // complementary-mode
57 QNode m = h.next; // node to fulfill
58 if (t != tail || m == null || h != head)
59 continue; // inconsistent read
60
61 Object x = m.item;
62 if (isData == (x != null) || // m already fulfilled
63 x == m || // m cancelled
64 !m.casItem(x, e)) { // lost CAS
65 advanceHead(h, m); // dequeue and retry
66 continue;
67 }
68
69 advanceHead(h, m); // successfully fulfilled
70 LockSupport.unpark(m.waiter);
71 return (x != null) ? x : e;
72 }
73 }
74 }
75
76 void advanceTail(QNode t, QNode nt) {
77 if (tail == t)
78 UNSAFE.compareAndSwapObject(this, tailOffset, t, nt);
79 }
后续的方法大家可以认真研究,主要是这两种数据类型的操作要搞清楚。
PriorityBlockingQueue
priority是优先级的意思,PriorityBlockQueue 底层使用二叉平衡树。可以注意到最上面的节点是最小值,并且放在数组的第一个的位置。
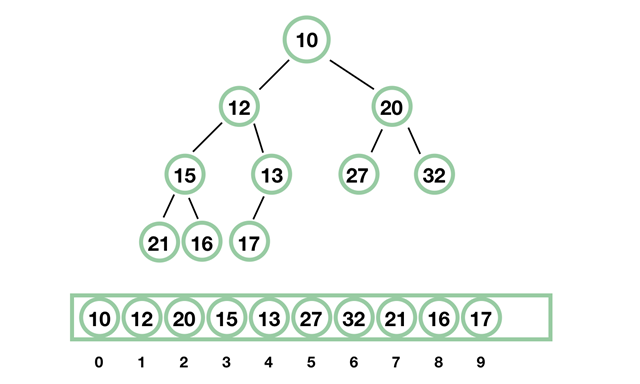
带排序的 BlockingQueue 实现,其并发控制采用的是 ReentrantLock,队列为无界队列(ArrayBlockingQueue 是有界队列,LinkedBlockingQueue 也可以通过在构造函数中传入 capacity 指定队列最大的容量,但是 PriorityBlockingQueue 只能指定初始的队列大小,后面插入元素的时候,如果空间不够的话会自动扩容)。
简单地说,它就是 PriorityQueue 的线程安全版本。不可以插入 null 值,同时,插入队列的对象必须是可比较大小的(comparable),否则报 ClassCastException 异常。它的插入操作 put 方法不会 block,因为它是无界队列(take 方法在队列为空的时候会阻塞)。
既然是继承了BlockQueue 接口,我们直接看 put 和 take 方法。
1 public void put(E e) {
2 offer(e); // never need to block
3 }
4
5
6 //先不考虑扩容
7 public boolean offer(E e) {
8 if (e == null)
9 throw new NullPointerException();
10 final ReentrantLock lock = this.lock;
11 //获得锁
12 lock.lock();
13 int n, cap;
14 Object[] array;
15 while ((n = size) >= (cap = (array = queue).length))
16 tryGrow(array, cap);
17 try {
18 //是否有比较器
19 Comparator<? super E> cmp = comparator;
20 //下面就是插入节点了
21 if (cmp == null)
22 siftUpComparable(n, e, array);
23 else
24 siftUpUsingComparator(n, e, array, cmp);
25 size = n + 1;
26 //有可能有消费者在阻塞
27 notEmpty.signal();
28 } finally {
29 lock.unlock();
30 }
31 return true;
32 }
33
34
35
36 //节点插入(上浮---二叉树的上浮操作)
37 private static <T> void siftUpComparable(int k, T x, Object[] array) {
38 Comparable<? super T> key = (Comparable<? super T>) x;
39 while (k > 0) {
40 int parent = (k - 1) >>> 1;
41 Object e = array[parent];
42 //它的节点比parent的大
43 if (key.compareTo((T) e) >= 0)
44 break;
45 //parent的节点比它大,所以它现在的位置应该放它parent 的节点,然后改变一下最终归属位置
46 array[k] = e;
47 k = parent;
48 }
49 //这里得出的 k 是它最终应该在的位置,key是它的值
50 array[k] = key;
51 }
52
主要插入的方法就是二叉树的插入操作。
1 public E take() throws InterruptedException {
2 final ReentrantLock lock = this.lock;
3 lock.lockInterruptibly();
4 E result;
5 try {
6 while ( (result = dequeue()) == null)
7 notEmpty.await();
8 } finally {
9 lock.unlock();
10 }
11 return result;
12 }
13
14
15
16 private E dequeue() {
17 int n = size - 1;
18 if (n < 0)
19 return null;
20 else {
21 Object[] array = queue;
22 //拿第一个节点,看到retrun 返回这个值,那么下面的操作应该就是维持二叉树平衡
23 E result = (E) array[0];
24 E x = (E) array[n];
25 array[n] = null;
26 Comparator<? super E> cmp = comparator;
27 if (cmp == null)
28 siftDownComparable(0, x, array, n);
29 else
30 siftDownUsingComparator(0, x, array, n, cmp);
31 size = n;
32 //返回第一个节点
33 return result;
34 }
35 }
36
37 //下沉操作 (此时 k=0 x=最后一个节点的值 )
38 private static <T> void siftDownComparable(int k, T x, Object[] array,
39 int n) {
40 if (n > 0) {
41 //最后一个节点的位置
42 Comparable<? super T> key = (Comparable<? super T>)x;
43 int half = n >>> 1; // loop while a non-leaf 子页
44 while (k < half) {
45 int child = (k << 1) + 1; // assume left child is least
46 Object c = array[child];
47 int right = child + 1;
48 if (right < n &&
49 ((Comparable<? super T>) c).compareTo((T) array[right]) > 0)
50 c = array[child = right];
51 if (key.compareTo((T) c) <= 0)
52 break;
53 array[k] = c;
54 k = child;
55 }
56 array[k] = key;
57 }
58 }
59
出列,然后二叉平衡树的下沉操作。
现在看一下扩容。
1 private void tryGrow(Object[] array, int oldCap) {
2 lock.unlock(); // must release and then re-acquire main lock 先释放锁再获得锁
3 Object[] newArray = null; //释放后有可能锁被人抢了,所以下面扩容操作一定会有判断措施
4 if (allocationSpinLock == 0 &&
5 UNSAFE.compareAndSwapInt(this, allocationSpinLockOffset,
6 0, 1)) {
7 try {
8 int newCap = oldCap + ((oldCap < 64) ?
9 (oldCap + 2) : // grow faster if small
10 (oldCap >> 1));
11 if (newCap - MAX_ARRAY_SIZE > 0) { // possible overflow
12 int minCap = oldCap + 1;
13 if (minCap < 0 || minCap > MAX_ARRAY_SIZE)
14 throw new OutOfMemoryError();
15 newCap = MAX_ARRAY_SIZE;
16 }
17 if (newCap > oldCap && queue == array)
18 newArray = new Object[newCap];
19 } finally {
20 allocationSpinLock = 0; //用于自旋的一个标志
21 }
22 }
23 //有可能别的线程人家正在操作,线程让步
24 if (newArray == null) // back off if another thread is allocating
25 Thread.yield();
26 lock.lock();
27 //获取锁后有可能扩容大小被改,此时必须判断
28 if (newArray != null && queue == array) {
29 queue = newArray;
30 System.arraycopy(array, 0, newArray, 0, oldCap);
31 }
32 }
33
其他方法可以再深入,下面看一下构造二叉树的方法。在这个类的构造函数里调用了heapify方法
1 public PriorityBlockingQueue(Collection<? extends E> c)
1 /**
2 * Establishes the heap invariant (described above) in the entire tree,
3 * assuming nothing about the order of the elements prior to the call.
4 */
5 private void heapify() {
6 Object[] array = queue;
7 int n = size;
8 int half = (n >>> 1) - 1;
9 Comparator<? super E> cmp = comparator;
10 if (cmp == null) {
11 for (int i = half; i >= 0; i--)
12 siftDownComparable(i, (E) array[i], array, n);
13 }
14 else {
15 for (int i = half; i >= 0; i--)
16 siftDownUsingComparator(i, (E) array[i], array, n, cmp);
17 }
18 }
可以看到就是一个个元素进行下沉操作。
总结
- ArrayListQueue 和 LinkedBlockingQueue 都是阻塞,有边界(后者最大是Interger.Max),依照 FIFO ,符合生产者-消费者的队列。前者使用单把锁,后者使用双把锁,前者使用数组作为容器,后者使用链表。
- SynchronousQueue 同步队列使用切换资源的场景。
参考资料 :
java 并发(五)---AbstractQueuedSynchronizer(5)的更多相关文章
- java 并发(五)---AbstractQueuedSynchronizer
文章部分图片和代码来自参考文章. LockSupport 和 CLH 和 ConditionObject 阅读源码首先看一下注解 ,知道了大概的意思后,再进行分析.注释一开始就进行了概括.AQS的实现 ...
- java 并发(五)---AbstractQueuedSynchronizer(4)
问题 : rwl 的底层实现是什么,应用场景是什么 读写锁 ReentrantReadWriteLock 首先我们来了解一下 ReentrantReadWriteLock 的作用是什么?和 Reent ...
- java 并发(五)---AbstractQueuedSynchronizer(3)
文章代码分析和部分图片来自参考文章 问题 : CountDownLatch 和 CyclicBarrier 的区别 认识 CountDownLatch 分析这个类,首先了解一下它所可以 ...
- java 并发(五)---AbstractQueuedSynchronizer(2)
文章部分代码和照片来自参考资料 问题 : ConditionObject 的 await 和 signal 方法是如何实现的 ConditonObject ConditionObjec ...
- Java并发基础类AbstractQueuedSynchronizer的实现原理简介
1.引子 Lock接口的主要实现类ReentrantLock 内部主要是利用一个Sync类型的成员变量sync来委托Lock锁接口的实现,而Sync继承于AbstractQueuedSynchroni ...
- Java并发框架AbstractQueuedSynchronizer(AQS)
1.前言 本文介绍一下Java并发框架AQS,这是大神Doug Lea在JDK5的时候设计的一个抽象类,主要用于并发方面,功能强大.在新增的并发包中,很多工具类都能看到这个的影子,比如:CountDo ...
- Java并发(五):并发,迭代器和容器
在随后的博文中我会继续分析并发包源码,在这里,得分别谈谈容器类和迭代器及其源码,虽然很突兀,但我认为这对于学习Java并发很重要; ConcurrentModificationException: J ...
- Java并发编程-AbstractQueuedSynchronizer源码分析
简介 提供了一个基于FIFO队列,可以用于构建锁或者其他相关同步装置的基础框架.该同步器(以下简称同步器)利用了一个int来表示状态,期望它能够成为实现大部分同步需求的基础.使用的方法是继承,子类通过 ...
- Java并发:AbstractQueuedSynchronizer(AQS)
队列同步器 AbstractQueuedSynchronizer 是一个公共抽象类.提供一个同步器框架,用于实现依赖于先进先出(FIFO)等待队列的阻塞锁和相关同步器(信号量,事件等).使用一个 in ...
随机推荐
- cisco和h3c网络设备中一次性打印全部配置信息
cisco的是全页打印配置信息的命令: #terminal length 0 #show run 华为和h3c的是: >screen-length 0 temporary >display ...
- 包(package)
一个文件夹管理多个模块文件,这个文件夹就被称为包,如下: 既然是多个模块文件,那么涉及多个模块怎么导入呢? ***当前路径下包之间模块导入: import wsg ***不同路径下包之间模块导入: f ...
- PHP初步:在Mac OS X Yosemite下搭建Apache+PHP+Mysql
Mac OS X是基于unix的操作系统,很多软件都集成在系统中.所以,对于配置PHP的开发环境相对于windows和Linux更简单. 1. 启动Apache服务器 打开终端(terminal),查 ...
- js的事件机制二
js的事件机制二 1.给合适的HTML标签添加合适的事件 onchange-----select下拉框 onload-----body标签 单双击-----用户会进行点击动作的HTML元素 鼠标事件 ...
- 2016级算法第一次练习赛-C.斐波那契进阶
870 斐波那契进阶 题目链接:https://buaacoding.cn/problem/870/index 思路 通过读题就可以发现这不是一般的求斐波那契数列,所以用数组存下所有的答案是不现实的. ...
- 百度地图 Infowidow 内容(content 下标签) 点击事件
需要监听 infowindow 的打开事件 ,查看InfoWindow API 实现 html 点击效果 代码 var infoWindow = that.createDangerInfoWindo ...
- 为什么我会选择走 Java 这条路?
阅读本文大概需要 2.8 分钟. 作者:黄小斜 文章来源:微信公众号[程序员江湖] 最近有一些小伙伴问我,为什么当初选择走Java这条路,为什么不做C++.前端之类的方向呢,另外还有一些声音:研究 ...
- List<Type> 随机
public List<T> GetRandomList<T>(List<T> inputList){ //Copy to a array T[] copyArra ...
- WinForm GDI编程:Graphics画布类
命名空间: using System.Drawing;//提供对GDI+基本图形功能的访问 using System.Drawing.Drawing2D;//提供高级的二维和矢量图像功能 using ...
- Java中的RSA加解密工具类:RSAUtils
本人手写已测试,大家可以参考使用 package com.mirana.frame.utils.encrypt; import com.mirana.frame.utils.log.LogUtils; ...