C json实战引擎 一 , 实现解析部分
引言
以前可能是去年的去年,写了一个 c json 解析引擎用于一个统计实验数据项目开发中. 基本上能用. 去年在网上
看见了好多开源的c json引擎 .对其中一个比较标准的 cJSON 引擎 深入学习了一下.
以前那个和cJSON对比了一下, 觉得 以前写的那个 优点是 空间小, 速度快, 因为采用的是 用时解析.而cJSON采用
的是递归下降分析, 结构也比较大.最后 决定再重构一个用的cjson. 目前设计思路以通用为主.
其实 结构 就决定 所有. 等同人的性格.
参照资料
1.json 标准 http://www.json.org/
2.cJSON 源码 https://sourceforge.net/projects/cjson/
吐槽一下
网上很多朋友 推荐看cJSON源码, 因为就700多行,可以看看学学. 真的吗 看下面 摘录的代码
void cJSON_ReplaceItemInObject(cJSON *object, const char *string, cJSON *newitem) { int i = ;cJSON *c = object->child;while (c && cJSON_strcasecmp(c->string, string))i++, c = c->next;if (c) { newitem->string = cJSON_strdup(string);cJSON_ReplaceItemInArray(object, i, newitem); } }
上面就是cJSON中常出现的代码格式,确实 700多行, 这个700多行全部分开可能要 1400行. 对于这些说700行的朋友只能是呵呵.
但有一点,看了很多nb的json引擎,也就 cJSON最容易理解了.最容易学习了. 性能还行. 这个是不得不说的优点.
后面 再扯一点, 这篇博文也可以理解为cJSON的深入剖析. 最后我采用递归下降分析 语法,构造 cjson_t 结构. 设计比cJSON更好用,更高效.
前言
每次写博文,发现写的好长,不关注的人很难理解, 这次采用一种新思路. 先将通用的简单的C开发技巧 . 后面再讲主题.
1. 积累的C开发 技巧 看完这个 你就已经赚了, 后面就可以不看了
首先我们分享一个 string convert number 的程序, 首先看下面代码.
// 分析数值的子函数,写的可以
double parse_number(const char* str)
{
double n = 0.0, ns = 1.0, nd = 0.0; //n把偶才能值, ns表示开始正负, 负为-1, nd 表示小数后面位数
int e = , es = ; //e表示后面指数, es表示 指数的正负,负为-1
char c; if ((c = *str) == '-' || c == '+') {
ns = c == '-' ? -1.0 : 1.0; //正负号检测, 1表示负数
++str;
}
//处理整数部分
for (c = *str; c >= '' && c <= ''; c = *++str)
n = n * + c - '';
if (c == '.')
for (; (c = *++str) >= '' && c <= ''; --nd)
n = n * + c - ''; // 处理科学计数法
if (c == 'e' || c == 'E') {
if ((c = *++str) == '+') //处理指数部分
++str;
else if (c == '-')
es = -, ++str;
for (; (c = *str) >= '' && c <= ''; ++str)
e = e * + c - '';
} //返回最终结果 number = +/- number.fraction * 10^+/- exponent
n = ns * n * pow(10.0, nd + es * e);
return n;
}
推荐有心的人多写几遍, 支持 +19.09 -19.0 19.567e123 -19.09E-9 这些转换. 这是项目工程代码,久经考验.
面试也常考. 没啥意思 , 那还有一个 不错的技巧 如下
/*
* 10.1 这里是一个 在 DEBUG 模式下的测试宏
*
* 用法 :
* DEBUG_CODE({
* puts("debug start...");
* });
*/
#ifndef DEBUG_CODE
# ifdef _DEBUG
# define DEBUG_CODE(code) code
# else
# define DEBUG_CODE(code)
# endif // ! _DEBUG
#endif // !DEBUG_CODE
这是个 测试code 宏, 有时候我们想 DEBUG下 测试代码在 Release 模式 删除 . 就用上面宏 .在gcc 下 需要 加上 -I_DEBUG
使用举例如下
/*
* 根据索引得到这个数组中对象
* array : 数组对象
* idx : 查找的索引 必须 [0,cjson_getlen(array)) 范围内
* : 返回查找到的当前对象
*/
cjson_t
cjson_getarray(cjson_t array, int idx)
{
cjson_t c;
DEBUG_CODE({
if (!array || idx < ) {
SL_FATAL("array:%p, idx=%d params is error!", array, idx);
return NULL;
}
}); for (c = array->child; c&&idx > ; c = c->next)
--idx; return c;
}
是不是很酷. 到这里 可以认为 值了学到了. 后面不好懂,可看可不看了!
正文
1. json 的语法解析 分析
恭喜到这里了,上面第一个分享的函数还有一种好思路 是 整数部分 和 小数部分分开算,后面再加起来. 就到这里吧.
json 的语法解析 同
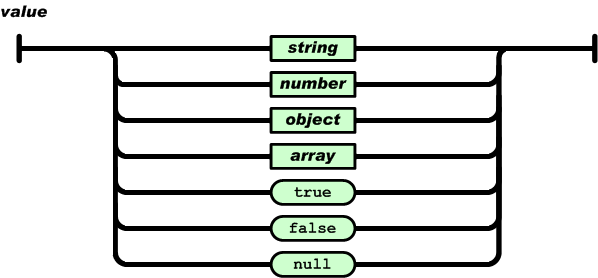
从 value 解析开始 遇到的 string number true false null 直接解析
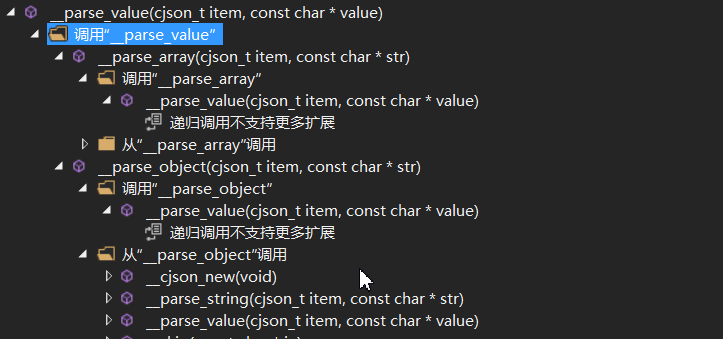
到 array , object 开始解析的时候 解析完毕直接 到value 解析, 这样递归下降解析完成 函数调用的流程图如下:
例如value 解析如下
// 将value 转换塞入 item json值中一部分
static const char* __parse_value(cjson_t item, const char* value)
{
char c;
if ((value) && (c = *value)) {
switch (c) {
// n = null, f = false, t = true
case 'n' : return item->type = _CJSON_NULL, value + ;
case 'f' : return item->type = _CJSON_FALSE, value + ;
case 't' : return item->type = _CJSON_TRUE, item->vd = 1.0, value + ;
case '\"': return __parse_string(item, value);
case '' : case '': case '': case '': case '': case '': case '': case '': case '': case '':
case '+' : case '-': return __parse_number(item, value);
case '[' : return __parse_array(item, value);
case '{' : return __parse_object(item, value);
}
}
// 循环到这里是意外 数据
SL_WARNING("params value = %s!", value);
return NULL;
}
这里是 value函数入口, 再以 array处理为例 流程 如下
// 分析数组的子函数, 采用递归下降分析
static const char* __parse_array(cjson_t item, const char* str)
{
cjson_t child;
if (*str != '[') {
SL_WARNING("array str error start: %s.", str);
return NULL;
} item->type = _CJSON_ARRAY;
str = __skip(str + );
if (*str == ']') // 低估提前结束
return str + ; item->child = child = __cjson_new();
str = __skip(__parse_value(child, str));
if (!str) {//解析失败 直接返回
SL_WARNING("array str error e n d one: %s.", str);
return NULL;
}
while (*str == ',') {
cjson_t nitem = __cjson_new();
child->next = nitem;
nitem->prev = child;
child = nitem;
str = __skip(__parse_value(child, __skip(str + )));
if (!str) {// 写代码是一件很爽的事
SL_WARNING("array str error e n d two: %s.", str);
return NULL;
}
} if (*str != ']') {
SL_WARNING("array str error e n d: %s.", str);
return NULL;
}
return str + ; // 跳过']'
}
主要看 while中内容,挨个分析 数组中内容,最后又导向于 value中.
大体流程就如上了,通过间接递归处理了 json语法的语句.
2.cjson 的 结构分析
首先看 结构文件
// json 中几种数据类型定义
#define _CJSON_FALSE (0)
#define _CJSON_TRUE (1)
#define _CJSON_NULL (2)
#define _CJSON_NUMBER (3)
#define _CJSON_STRING (4)
#define _CJSON_ARRAY (5)
#define _CJSON_OBJECT (6) #define _CJSON_ISREF (256) //set 时候用如果是引用就不释放了
#define _CJSON_ISCONST (512) //set时候用, 如果是const char* 就不释放了 struct cjson {
struct cjson *next, *prev;
struct cjson *child; // type == _CJSON_ARRAY or type == _CJSON_OBJECT 那么 child 就不为空 int type;
char *key; // json内容那块的 key名称
char *vs; // type == _CJSON_STRING, 是一个字符串
double vd; // type == _CJSON_NUMBER, 是一个num值, ((int)c->vd) 转成int 或 bool
}; //定义cjson_t json类型
typedef struct cjson* cjson_t;
来分析一下 struct cjson 中结构字段意思, 其中 next,prev 理解为双向链表, 为了查找同一层的 对象.例如
[1,2,3,4,[6,5]] 其中 1,2,3,4, [6,5] 就是同一层, 6,5 是同一层
4->next 后面 的 child 就是 [6,5]每次解析到新的 array 或 object 都用child 导向它.
type 表示类型 默认有其中 [0,6], 如上 _CJSON_*
key 用于关联对象.
是不是很好理解
这里提供接口如下
/*
* 这个宏,协助我们得到 int 值 或 bool 值
*
* item : 待处理的目标cjson_t结点
*/
#define cjson_getint(item) \
((int)((item)->vd)) /*
* 删除json串内容
* c : 待释放json_t串内容
*/
extern void cjson_delete(cjson_t* pc); /*
* 对json字符串解析返回解析后的结果
* jstr : 待解析的字符串
*/
extern cjson_t cjson_parse(const char* jstr); /*
* 根据 item当前结点的 next 一直寻找到 NULL, 返回个数
*推荐是数组使用
* array : 待处理的cjson_t数组对象
* : 返回这个数组中长度
*/
extern int cjson_getlen(cjson_t array); /*
* 根据索引得到这个数组中对象
* array : 数组对象
* idx : 查找的索引 必须 [0,cjson_getlen(array)) 范围内
* : 返回查找到的当前对象
*/
extern cjson_t cjson_getarray(cjson_t array, int idx); /*
* 根据key得到这个对象 相应位置的值
* object : 待处理对象中值
* key : 寻找的key
* : 返回 查找 cjson_t 对象
*/
extern cjson_t cjson_getobject(cjson_t object, const char* key);
看一遍是不是就理解了,看代码还是比较好懂的. 自己写就难一点了. 主要难在
设计 => 开发 => 测试 => 优化 => 设计 => 开发 => 测试 .................................. 流程很多,出一个好东西最难的是时间和执着.
3.cjson 部分源码分析
先看最重要的 内存释放代码
// 删除cjson
static void __cjson_delete(cjson_t c)
{
cjson_t next;
while (c) {
next = c->next;
//递归删除儿子
if (!(c->type & _CJSON_ISREF)) {
if (c->child) //如果不是尾递归,那就先递归
__cjson_delete(c->child);
if (c->vs)
free(c->vs);
}
else if (!(c->type & _CJSON_ISCONST) && c->key)
free(c->key);
free(c);
c = next;
}
} /*
* 删除json串内容,最近老是受清华的老学生打击, 会起来的......
* c : 待释放json_t串内容
*/
void
cjson_delete(cjson_t* pc)
{
if (!pc || !*pc)
return;
__cjson_delete(*pc);
*pc = NULL;
}
上面做法是 防止野指针, 用时间换安全. 时间空间安全 三要素,基本就是编程三大元素. 上面 _CJSOn_ISREF 是为了 set 后面设计留的, 添加了不需要释放的东西
我们就不处理.
在看一个获取关联对象的值
/*
* 根据key得到这个对象 相应位置的值
* object : 待处理对象中值
* key : 寻找的key
* : 返回 查找 cjson_t 对象
*/
cjson_t
cjson_getobject(cjson_t object, const char* key)
{
cjson_t c;
DEBUG_CODE({
if (!object || !key || !*key) {
SL_FATAL("object:%p, key=%s params is error!", object, key);
return NULL;
}
}); for (c = object->child; c && str_icmp(key, c->key); c = c->next)
; return c;
}
是不是很容易 一下都明白了. 其中 str_icmp 上一篇博文中好像讲过源码 如下
/*
* 这是个不区分大小写的比较函数
* ls : 左边比较字符串
* rs : 右边比较字符串
* : 返回 ls>rs => >0 ; ls = rs => 0 ; ls<rs => <0
*/
int
str_icmp(const char* ls, const char* rs)
{
int l, r;
if(!ls || !rs)
return (int)ls - (int)rs; do {
if((l=*ls++)>='a' && l<='z')
l -= 'a' - 'A';
if((r=*rs++)>='a' && r<='z')
r -= 'a' - 'A';
} while(l && l==r); return l-r;
}
到这里 目前 了解的设计基本就完工了.
4.cjson 源码源码展示
这里就是普通展示所有的源码 首先是 cjson.h
#ifndef _H_CJSON
#define _H_CJSON // json 中几种数据类型定义
#define _CJSON_FALSE (0)
#define _CJSON_TRUE (1)
#define _CJSON_NULL (2)
#define _CJSON_NUMBER (3)
#define _CJSON_STRING (4)
#define _CJSON_ARRAY (5)
#define _CJSON_OBJECT (6) #define _CJSON_ISREF (256) //set 时候用如果是引用就不释放了
#define _CJSON_ISCONST (512) //set时候用, 如果是const char* 就不释放了 struct cjson {
struct cjson *next, *prev;
struct cjson *child; // type == _CJSON_ARRAY or type == _CJSON_OBJECT 那么 child 就不为空 int type;
char *key; // json内容那块的 key名称
char *vs; // type == _CJSON_STRING, 是一个字符串
double vd; // type == _CJSON_NUMBER, 是一个num值, ((int)c->vd) 转成int 或 bool
}; //定义cjson_t json类型
typedef struct cjson* cjson_t; /*
* 这个宏,协助我们得到 int 值 或 bool 值
*
* item : 待处理的目标cjson_t结点
*/
#define cjson_getint(item) \
((int)((item)->vd)) /*
* 删除json串内容
* c : 待释放json_t串内容
*/
extern void cjson_delete(cjson_t* pc); /*
* 对json字符串解析返回解析后的结果
* jstr : 待解析的字符串
*/
extern cjson_t cjson_parse(const char* jstr); /*
* 根据 item当前结点的 next 一直寻找到 NULL, 返回个数
*推荐是数组使用
* array : 待处理的cjson_t数组对象
* : 返回这个数组中长度
*/
extern int cjson_getlen(cjson_t array); /*
* 根据索引得到这个数组中对象
* array : 数组对象
* idx : 查找的索引 必须 [0,cjson_getlen(array)) 范围内
* : 返回查找到的当前对象
*/
extern cjson_t cjson_getarray(cjson_t array, int idx); /*
* 根据key得到这个对象 相应位置的值
* object : 待处理对象中值
* key : 寻找的key
* : 返回 查找 cjson_t 对象
*/
extern cjson_t cjson_getobject(cjson_t object, const char* key); #endif // !_H_CJSON
后买你是 cjson.c 的实现
#include <cjson.h>
#include <schead.h>
#include <sclog.h>
#include <tstring.h>
#include <math.h> // 删除cjson
static void __cjson_delete(cjson_t c)
{
cjson_t next;
while (c) {
next = c->next;
//递归删除儿子
if (!(c->type & _CJSON_ISREF)) {
if (c->child) //如果不是尾递归,那就先递归
__cjson_delete(c->child);
if (c->vs)
free(c->vs);
}
else if (!(c->type & _CJSON_ISCONST) && c->key)
free(c->key);
free(c);
c = next;
}
} /*
* 删除json串内容,最近老是受清华的老学生打击, 会起来的......
* c : 待释放json_t串内容
*/
void
cjson_delete(cjson_t* pc)
{
if (!pc || !*pc)
return;
__cjson_delete(*pc);
*pc = NULL;
} //构造一个空 cjson 对象
static inline cjson_t __cjson_new(void)
{
cjson_t c = calloc(, sizeof(struct cjson));
if (!c) {
SL_FATAL("calloc sizeof struct cjson error!");
exit(_RT_EM);
}
return c;
} // 简化的代码段,用宏来简化代码书写 , 16进制处理
#define __parse_hex4_code(c, h) \
if (c >= '' && c <= '') \
h += c - ''; \
else if (c >= 'A' && c <= 'F') \
h += + c - 'A'; \
else if (c >= 'a' && c <= 'z') \
h += + c - 'F'; \
else \
return // 等到unicode char代码
static unsigned __parse_hex4(const char* str)
{
unsigned h = ;
char c = *str;
//第一轮
__parse_hex4_code(c, h);
h <<= ;
c = *++str;
//第二轮
__parse_hex4_code(c, h);
h <<= ;
c = *++str;
//第三轮
__parse_hex4_code(c, h);
h <<= ;
c = *++str;
//第四轮
__parse_hex4_code(c, h); return h;
} // 分析字符串的子函数,
static const char* __parse_string(cjson_t item, const char* str)
{
static unsigned char __marks[] = { 0x00, 0x00, 0xC0, 0xE0, 0xF0, 0xF8, 0xFC };
const char *ptr;
char *nptr, *out;
int len;
char c;
unsigned uc, nuc; if (*str != '\"') { // 检查是否是字符串内容
SL_WARNING("need \\\" str => %s error!", str);
return NULL;
} for (ptr = str + , len = ; (c = *ptr++) != '\"' && c; ++len)
if (c == '\\') //跳过转义字符
++ptr;
if (!(out = malloc(len + ))) {
SL_FATAL("malloc %d size error!", len + );
return NULL;
}
// 这里复制拷贝内容
for (ptr = str + , nptr = out; (c = *ptr) != '\"' && c; ++ptr) {
if (c != '\\') {
*nptr++ = c;
continue;
}
// 处理转义字符
switch ((c = *++ptr)) {
case 'b': *nptr++ = '\b'; break;
case 'f': *nptr++ = '\f'; break;
case 'n': *nptr++ = '\n'; break;
case 'r': *nptr++ = '\r'; break;
case 't': *nptr++ = '\t'; break;
case 'u': // 将utf16 => utf8, 专门的utf处理代码
uc = __parse_hex4(ptr + );
ptr += ;//跳过后面四个字符, unicode
if ((uc >= 0xDC00 && uc <= 0xDFFF) || uc == ) break; /* check for invalid. */ if (uc >= 0xD800 && uc <= 0xDBFF) /* UTF16 surrogate pairs. */
{
if (ptr[] != '\\' || ptr[] != 'u')
break; /* missing second-half of surrogate. */
nuc = __parse_hex4(ptr + );
ptr += ;
if (nuc < 0xDC00 || nuc>0xDFFF)
break; /* invalid second-half of surrogate. */
uc = 0x10000 + (((uc & 0x3FF) << ) | (nuc & 0x3FF));
} len = ;
if (uc < 0x80)
len = ;
else if (uc < 0x800)
len = ;
else if (uc < 0x10000)
len = ;
nptr += len; switch (len) {
case : *--nptr = ((uc | 0x80) & 0xBF); uc >>= ;
case : *--nptr = ((uc | 0x80) & 0xBF); uc >>= ;
case : *--nptr = ((uc | 0x80) & 0xBF); uc >>= ;
case : *--nptr = (uc | __marks[len]);
}
nptr += len;
break;
default: *nptr++ = c;
}
} *nptr = '\0';
if (c == '\"')
++ptr;
item->vs = out;
item->type = _CJSON_STRING;
return ptr;
} // 分析数值的子函数,写的可以
static const char* __parse_number(cjson_t item, const char* str)
{
double n = 0.0, ns = 1.0, nd = 0.0; //n把偶才能值, ns表示开始正负, 负为-1, nd 表示小数后面位数
int e = , es = ; //e表示后面指数, es表示 指数的正负,负为-1
char c; if ((c = *str) == '-' || c == '+') {
ns = c == '-' ? -1.0 : 1.0; //正负号检测, 1表示负数
++str;
}
//处理整数部分
for (c = *str; c >= '' && c <= ''; c = *++str)
n = n * + c - '';
if (c == '.')
for (; (c = *++str) >= '' && c <= ''; --nd)
n = n * + c - ''; // 处理科学计数法
if (c == 'e' || c == 'E') {
if ((c = *++str) == '+') //处理指数部分
++str;
else if (c == '-')
es = -, ++str;
for (; (c = *str) >= '' && c <= ''; ++str)
e = e * + c - '';
} //返回最终结果 number = +/- number.fraction * 10^+/- exponent
n = ns * n * pow(10.0, nd + es * e);
item->vd = n;
item->type = _CJSON_NUMBER;
return str;
} // 跳过不需要处理的字符
static const char* __skip(const char* in)
{
if (in && *in && *in <= ) {
unsigned char c;
while ((c = *++in) && c <= )
;
}
return in;
} // 递归下降分析 需要声明这些函数
static const char* __parse_array(cjson_t item, const char* str);
static const char* __parse_object(cjson_t item, const char* str);
static const char* __parse_value(cjson_t item, const char* value); // 分析数组的子函数, 采用递归下降分析
static const char* __parse_array(cjson_t item, const char* str)
{
cjson_t child;
if (*str != '[') {
SL_WARNING("array str error start: %s.", str);
return NULL;
} item->type = _CJSON_ARRAY;
str = __skip(str + );
if (*str == ']') // 低估提前结束
return str + ; item->child = child = __cjson_new();
str = __skip(__parse_value(child, str));
if (!str) {//解析失败 直接返回
SL_WARNING("array str error e n d one: %s.", str);
return NULL;
}
while (*str == ',') {
cjson_t nitem = __cjson_new();
child->next = nitem;
nitem->prev = child;
child = nitem;
str = __skip(__parse_value(child, __skip(str + )));
if (!str) {// 写代码是一件很爽的事
SL_WARNING("array str error e n d two: %s.", str);
return NULL;
}
} if (*str != ']') {
SL_WARNING("array str error e n d: %s.", str);
return NULL;
}
return str + ; // 跳过']'
} // 分析对象的子函数
static const char* __parse_object(cjson_t item, const char* str)
{
cjson_t child;
if (*str != '{') {
SL_WARNING("object str error start: %s.", str);
return NULL;
} item->type = _CJSON_OBJECT;
str = __skip(str + );
if (*str == '}')
return str + ; //处理结点, 开始读取一个 key
item->child = child = __cjson_new();
str = __skip(__parse_string(child, str));
if (!str || *str != ':') {
SL_WARNING("__skip __parse_string is error : %s!", str);
return NULL;
}
child->key = child->vs;
child->vs = NULL; str = __skip(__parse_value(child, __skip(str + )));
if (!str) {
SL_WARNING("__skip __parse_string is error 2!");
return NULL;
} // 递归解析
while (*str == ',') {
cjson_t nitem = __cjson_new();
child->next = nitem;
nitem->prev = child;
child = nitem;
str = __skip(__parse_string(child, __skip(str + )));
if (!str || *str != ':'){
SL_WARNING("__parse_string need name or no equal ':' %s.", str);
return NULL;
}
child->key = child->vs;
child->vs = NULL; str = __skip(__parse_value(child, __skip(str+)));
if (!str) {
SL_WARNING("__parse_string need item two ':' %s.", str);
return NULL;
}
} if (*str != '}') {
SL_WARNING("object str error e n d: %s.", str);
return NULL;
}
return str + ;
} // 将value 转换塞入 item json值中一部分
static const char* __parse_value(cjson_t item, const char* value)
{
char c;
if ((value) && (c = *value)) {
switch (c) {
// n = null, f = false, t = true
case 'n' : return item->type = _CJSON_NULL, value + ;
case 'f' : return item->type = _CJSON_FALSE, value + ;
case 't' : return item->type = _CJSON_TRUE, item->vd = 1.0, value + ;
case '\"': return __parse_string(item, value);
case '' : case '': case '': case '': case '': case '': case '': case '': case '': case '':
case '+' : case '-': return __parse_number(item, value);
case '[' : return __parse_array(item, value);
case '{' : return __parse_object(item, value);
}
}
// 循环到这里是意外 数据
SL_WARNING("params value = %s!", value);
return NULL;
} /*
* 对json字符串解析返回解析后的结果
* jstr : 待解析的字符串
* : 返回解析好的字符串内容
*/
cjson_t
cjson_parse(const char* jstr)
{
cjson_t c = __cjson_new();
const char* end; if (!(end = __parse_value(c, __skip(jstr)))) {
SL_WARNING("__parse_value params end = %s!", end);
cjson_delete(&c);
return NULL;
} //这里是否检测 返回测试数据
return c;
} /*
* 根据 item当前结点的 next 一直寻找到 NULL, 返回个数
*推荐是数组使用
* array : 待处理的cjson_t数组对象
* : 返回这个数组中长度
*/
int
cjson_getlen(cjson_t array)
{
int len = ;
if (array)
for (array = array->child; array; array = array->next)
++len; return len;
} /*
* 根据索引得到这个数组中对象
* array : 数组对象
* idx : 查找的索引 必须 [0,cjson_getlen(array)) 范围内
* : 返回查找到的当前对象
*/
cjson_t
cjson_getarray(cjson_t array, int idx)
{
cjson_t c;
DEBUG_CODE({
if (!array || idx < ) {
SL_FATAL("array:%p, idx=%d params is error!", array, idx);
return NULL;
}
}); for (c = array->child; c&&idx > ; c = c->next)
--idx; return c;
} /*
* 根据key得到这个对象 相应位置的值
* object : 待处理对象中值
* key : 寻找的key
* : 返回 查找 cjson_t 对象
*/
cjson_t
cjson_getobject(cjson_t object, const char* key)
{
cjson_t c;
DEBUG_CODE({
if (!object || !key || !*key) {
SL_FATAL("object:%p, key=%s params is error!", object, key);
return NULL;
}
}); for (c = object->child; c && str_icmp(key, c->key); c = c->next)
; return c;
}
后面将给出测试代码
5.cjson 测试代码 展示
测试的 test_cjson.c
#include <schead.h>
#include <sclog.h>
#include <cjson.h> // 测试 cjson 函数
int main(int argc, char* argv[])
{
//注册等待函数
INIT_PAUSE(); //启动日志记录功能
sl_start(); // 第二个 测试 json 串的解析
puts("测试 cjson 是否可用");
char text1[] = "{\n\"name\": \"Jack (\\\"Bee\\\") Nimble\", \n\"format\": {\"type\": \"rect\", \n\"width\": 1920, \n\"height\": 1080, \n\"interlace\": false,\"frame rate\": 24\n}\n}"; cjson_t js = cjson_parse(text1); cjson_t name = cjson_getobject(js, "name");
printf("name => %s\n", name->vs); cjson_t format = cjson_getobject(js, "format");
printf("len(format) => %d\n", cjson_getlen(format)); cjson_t interlace = cjson_getobject(format, "interlace");
printf("interlace => %d\n", cjson_getint(interlace)); cjson_delete(&js); //进行第三组测试 puts(" 测试 数组的读取");
char text2[] = "[\"Sunday\", \"Monday\", \"Tuesday\", \"Wednesday\", \"Thursday\", \"Friday\", \"Saturday\"]";
js = cjson_parse(text2);
int len = cjson_getlen(js);
int i;
for (i = ; i < len; ++i) {
cjson_t item = cjson_getarray(js,i);
printf("%d => %s.\n", i, item->vs);
}
cjson_delete(&js); puts("第三组测试");
char text3[] = "[\n [0, -1, 0],\n [1, 0, 0],\n [0, 0, 1]\n ]\n";
js = cjson_parse(text3);
len = cjson_getlen(js);
for (i = ; i < len; ++i) {
cjson_t item = cjson_getarray(js, i);
printf("%d => %d.\n", i, cjson_getlen(item));
} cjson_delete(&js); return ;
}
运行的结果如下
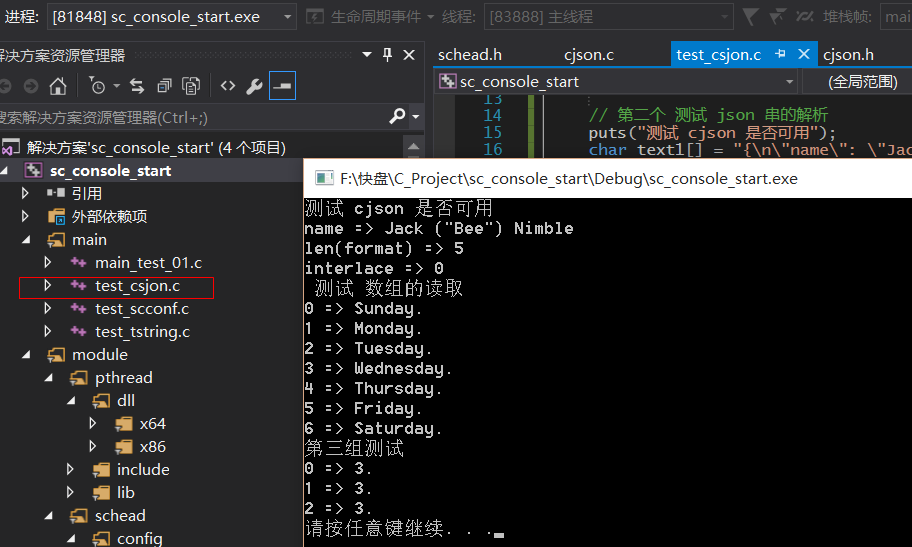
代码一定是跨平台的, 选择window 是为了 提高调试效率采用VS的DEBUG . 在Linux 上就是重复 的调试 , 手累. 吐槽一下 在 Linux 上工作久了,
真心手累. 到这里 cjson 解析部分在工程中生产的代码我们都搭建起来. 还不错,欢迎尝试
后记
错误是难免的, 欢迎吐槽, 下次分析完整的 cjson 使用过程,补充上cjson的 填充构造过程. 欢迎用在自己的项目中. 或者学习一下.
有问题再互相交流.
C json实战引擎 一 , 实现解析部分的更多相关文章
- c json实战引擎四 , 最后❤跳跃
引言 - 以前那些系列 长活短说, 写的最终 scjson 纯c跨平台引擎, 希望在合适场景中替代老的csjon引擎, 速度更快, 更轻巧. 下面也是算一个系列吧. 从cjson 中得到灵感, 外加 ...
- C json实战引擎 三 , 最后实现部分辅助函数
引言 大学读的是一个很时髦的专业, 学了四年的游戏竞技. 可惜没学好. 但认真过, 比做什么都认真. 见证了 ...... 打的所有游戏人物中 分享一位最喜爱 的 “I've been alone ...
- C json实战引擎 二 , 实现构造部分
引言 这篇博文和前一篇 C json实战引擎一,实现解析部分设计是相同的,都是采用递归下降分析. 这里扯一点 假如你是学生 推荐一本书 给 大家 自制编程语言 http://baike.baidu.c ...
- c json实战引擎五 , 优化重构
引言 scjson是一个小巧的纯c跨平台小巧引擎. 适用于替换老的cJSON引擎的场景. 数据结构和代码布局做了大量改进.优势体现在以下几个方面: 1) 跨平台 (window 10 + VS2017 ...
- c json实战引擎六 , 感觉还行
前言 看到六, 自然有 一二三四五 ... 为什么还要写呢. 可能是它还需要活着 : ) 挣扎升级中 . c json 上面代码也存在于下面项目中(维护的最及时) structc json 这次版本 ...
- Java生鲜电商平台-电商中海量搜索ElasticSearch架构设计实战与源码解析
Java生鲜电商平台-电商中海量搜索ElasticSearch架构设计实战与源码解析 生鲜电商搜索引擎的特点 众所周知,标准的搜索引擎主要分成三个大的部分,第一步是爬虫系统,第二步是数据分析,第三步才 ...
- js中解析json对象:JSON.parse()用于从一个字符串中解析出json对象, JSON.stringify()用于从一个对象解析出字符串。
JSON.parse()用于从一个字符串中解析出json对象. var str = '{"name":"huangxiaojian","age&quo ...
- JSON的简单使用_解析前台传来的JSON数据
package cn.rocker.json; import org.junit.Test; import net.sf.json.JSONArray; import net.sf.json.JSON ...
- 【Java实战】源码解析Java SPI(Service Provider Interface )机制原理
一.背景知识 在阅读开源框架源码时,发现许多框架都支持SPI(Service Provider Interface ),前面有篇文章JDBC对Driver的加载时应用了SPI,参考[Hibernate ...
随机推荐
- vscode Variables Reference
vscode Variables Reference 您可以在以下链接中找到该列表:https://code.visualstudio.com/docs/editor/variables-refere ...
- JSON字符串和Javascript对象字面量
JSON字符串和Javascript对象字面量 JSON是基于Javascript语法的一个子集而创建的,特别是对象和数组字面量语法. 正是由于JSON的这种特殊来历,导致很多Javascript程序 ...
- [NOIP2016 TG D2T3]愤怒的小鸟
题目大意:有一架弹弓位于(0,0)处,每次可以用它向第一象限发射一只小鸟,飞行轨迹均为形如y=ax2+bxy=ax+bx2 y=ax2+bx的曲线,且必须满足a<0(即是下开口的) 平面的第一象 ...
- ARC077D 11 组合数
---题面--- 题解: 做这道题的时候zz了,,,, 写了个很复杂的式子,然而后面重新想就发现很简单了. 考虑用总的情况减去重复的. 假设唯一重复的两个数的位置分别是l和r,那么唯一会导致重复的方案 ...
- Spring源码解析-autowiring自动装配的实现
IoC容器提供了自动依赖装配的方式,为应用IoC容器提供很大的方便.在自动配置中,不需要显式的去指定Bean属性,只需要配置autowiring属性,IoC容器会根据这个属性配置,使用反射的方式查找属 ...
- Codeforces Round #394 (Div. 2)A水 B暴力 C暴力 D二分 E dfs
A. Dasha and Stairs time limit per test 2 seconds memory limit per test 256 megabytes input standard ...
- D-query SPOJ - DQUERY(莫队)统计不同数的数量
Given a sequence of n numbers a1, a2, ..., an and a number of d-queries. A d-query is a pair (i, j) ...
- kali wireless driver install
acer-gateway nv47h94c 1.lspci -nn |grep 0280 get pci-id root@silee:/# lspci -nn |grep 028003:00.0 Ne ...
- 35 个你也许不知道的 Google 开源项目
转载自:http://blog.csdn.net/cnbird2008/article/details/18953113 Google是支持开源运动的最大公司之一,它们现在总共发布有超过500个的开源 ...
- CSS实现三列布局方法总结
aaarticlea/png;base64,iVBORw0KGgoAAAANSUhEUgAABYwAAAI7CAYAAABPx9+YAAARJElEQVR4nO3cwWnDQBBA0TioJrXhTl