Laxcus大数据管理系统2.0(12)- 第十章 运行
第十章 运行
本章将介绍一些Laxcus集群基本运行、使用情况,结合图片和表格表示。地点是我们的大数据实验室,使用我们的实验集群。数据来自于我们的合作伙伴,软件平台混合了Windows和Fedora Linux两个操作系统,硬件因为一直以来的测试需要,显得参差不齐,从10年前的旧机器到今天最新的设备都有。这样的环境虽然不足以反映目前商业运营的集群现实状况,但是在反映Laxcus集群和集群基础硬件性能参数时,仍然具有一定的代表性。为了更好反映测试结果,我们将多用户多集群的Laxcus部署成单用户单集群环境(一个主域集群加一个子域集群和一个注册用户)。网络传输都按照默认规定,采取了流量控制措施。
10.1 配置
首先介绍这个实验集群的基本情况,我们把配置分成两部分:硬件的计算机、软件的节点,用两张表说明,可以从中一窥集群的端倪。因为Data/Work节点要执行数据存储和计算工作,所以大量计算机分配给它们。本次测试没有数据构造业务,Build节点就只保留一台做为冗余。在这个集群里,因为每台计算机的硬件配置很不相同,数据也不是平均分布的,这直接导致Data节点产生的数据量不一致,和Work节点的计算时间长短不一,Call节点做为它们的协调者,会尽量去平衡这种不平均现象。其它不怎么产生计算压力的节点就用一台,或者合用一台计算机。
|
部件 |
类型数据 |
|
CPU |
Pentium III、Pentium IV、CORE、ATOM、ARM32 |
|
内存 |
512M - 4G |
|
硬盘 |
20G - 2TB,IDE/STTA/SSD,Data、Work、Build、Call节点会部署多个硬盘 |
|
网卡 |
100M/1G |
|
带宽 |
1G |
表10.1.1 硬件情况
|
节点 |
说明 |
|
Top |
1个,与HOME/TASK/AID合用1台物理计算机 |
|
Home |
1个,与Top共享使用 |
|
Task |
1个,与Top共享使用 |
|
Aid |
1个,与Top共享使用 |
|
Log |
1个,独立使用1台物理计算机 |
|
Call |
3个,部署在3台物理计算机上 |
|
Data |
24个,部署在24台物理计算机上 |
|
Work |
20个,部署在20台物理计算机上 |
|
Build |
3个,部署在3台物理计算机上 |
|
Watch |
2个,共享1台物理计算机,分别监视TOP/HOME两个集群 |
|
Front |
8个,部署在2台物理计算机上。 |
表10.1.2 节点情况
10.2 管理
管理是Laxcus集群一项基础服务。它包含两个部分:管理员对集群的管理,用户对所拥有数据的管理。集群的管理,由管理员通过Watch站点实施。用户对自己数据的管理,由用户通过Front节点实施。所有管理工作都是通过命令实施,其中有些命令可以被管理员和用户共用。另外为减少管理员的工作负担,部分由管理员实施的工作也可以指定某个用户代为处理,如对用户账号授权这样的管理工作。但是大部分命令都有它们明确的操作归属,不允许随意使用,即使被错误发出,也不会被集群接受。
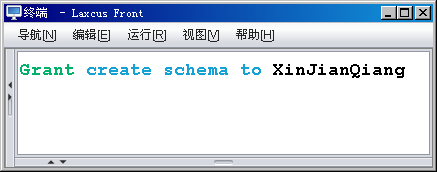
图10.2.1 拥有管理员权限的注册用户,对另一个注册用户授权
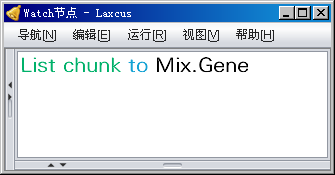
图10.2.2 显示数据块的分布节点和数据量 (管理员操作)
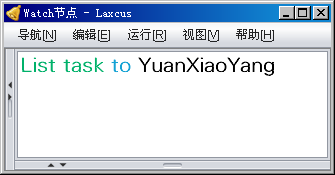
图10.2.3 显示用户分布任务组件的分布节点和全部组件命名(管理员操作)

图10.2.4 显示全部在线用户数(管理员操作)

图10.2.5 加载数据块索引到内存(用户操作,提高检索速度)

图10.2.6 加载数据块到内存(用户操作,实现内存计算)
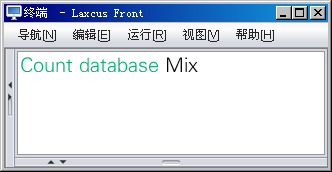
图10.2.7 统计数据库
(共用,管理员返回下属表名、节点地址、数据块数、尺寸,用户没有节点地址)
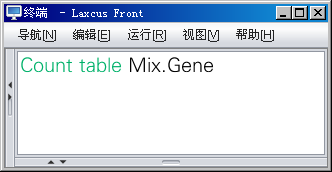
图10.2.8 统计数据表
(共用,管理员返回节点地址、数据块数、尺寸,用户没有节点地址)
10.3 元数据
在Laxcus集群运行过程中,元数据是一项很重要的参考指标,它大体反映了每一个节点的当前的负载和运行情况。如果把这些元数据综合起来,可以进一步获得一个集群的运行信息。或者按照不同要求,对不同的元数据进行分类、对照、聚合、比较,又可以反映出集群某一局部的运行状态。
Laxcus集群的元数据只对集群管理员开放,用户不具备这项权利。在实际的集群管理维护中,管理员通过Watch节点向集群发出命令来获得元数据,使管理员可以快速了解集群运行情况,是管理员工作的重要辅助手段。通过元数据管理员可以很快检查、发现集群可能存在的运行问题,或者在实施一项工作前,通过元数据获得必要的预判,再决定接下来的工作是否处理和处理方向。
目前元数据都是以文字和表格的形式显示出来,下一步将提供图表化和图像化的显示方案,这样管理员将获得更丰富和直接的显示效果。这项改进工作已经在项目日程中。
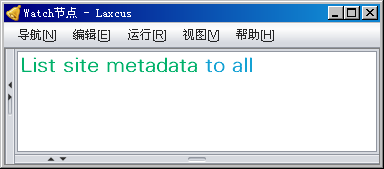
图10.3.1 显示全部运行节点元数据

图10.3.2 显示用户数据产生的全部元数据
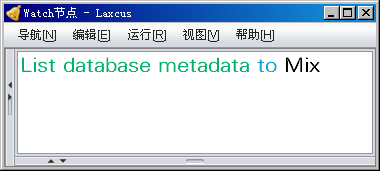
图10.3.3 显示数据库元数据和它的部署节点、数据量
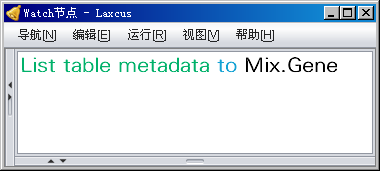
图10.3.4 显示数据表元数据和它的部署节点、数据量
|
节点类型 |
节点数量 |
元数据尺寸 |
关联数据尺寸 |
|
Top |
1 |
0.372M |
- |
|
Home |
1 |
0.692M |
- |
|
Task |
1 |
1.731M |
- |
|
Aid |
1 |
0.053M |
- |
|
Watch |
1 |
1.528M |
- |
|
Log |
1 |
0.339M |
- |
|
Data |
24 |
5.712M - 28.729M |
623.182GB - 4.851TB |
|
Work |
20 |
0.131M - 0.257M |
- |
|
Build |
1 |
0.180M |
- |
|
Call |
3 |
1.361M - 6.749M |
8.302TB - 47.276TB |
表10.3.1 测试集群元数据列表
10.4 数据操作
在Laxcus大数据系统中,数据操作被归为用户使用部分。现在主要通过Conduct 、Establish两个命令来实现大规模数据处理。另外考虑到用户的使用习惯,我们还完整兼容了SQL四个主要命令:Insert、Select、Delete、Update。在实际应用中,由于直接操作Select会产生巨量数据,给Front节点带来雪崩现象,造成Front节点瘫痪,所以极少被直接使用,而是把它嵌入到Conduct、Establish命令中组合使用。
Front节点是用户操作数据的入口。在很多运营环境中,大多数时候,它被用户做为驱动程序,嵌入到其它软件中使用,其中使用最多的SQL命令是Insert。图形界面和字符界面的Front节点起着辅助作用,主要是用在用户的数据管理上。

图10.4.1 检索数据
10.5 Sort Benchmark测试
我们设计了一个Sort Benchmark测试,通过一个分布环境下的数据排序工作,追踪数据的产生、写入、读取、传输、计算这一系列执行流程。在考察一个集群的数据处理能力的同时,也对集群中的CPU、硬盘、内存、网络设备等主要硬件部件进行性能考核。测试使用一套分布任务组件展开,组件名称是“SortBenchmark”。按照Laxcus大数据系统要求,这个命名在整个主域集群是唯一的,现在已经检查通过,并且发布到集群上。SortBenchmark基于Diffuse/Converge算法,对应操作命令是Conduct。为了防止多并发竞用影响观察效果,集群里只运行一个任务。我们用一个Front节点发送命令,它会把命令先发送给Aid节点,再转发到其中一个Call节点上。这个Call节点会根据命令的参数,检查和分配后续数据处理工作,并监管整个工作直到完成。Front节点将等待Call节点的反馈结果,然后撤销Aid节点上的记录,并把测试数据打印了计算机屏幕上。
10.5.1 排序测试
如图10.5.1.1所示,测试从Front节点开始,图形窗口上,Conduct命令中的关键字被高亮显示。其中"sites"表示要求的节点数,"writeto"表示测试报告被写入的本机磁盘文件。"from、to、put"都是Conduct命令的阶段类型关键字,其它是自定义参数关键字,此次排序操作被要求按照升序排序,中间数据写入硬盘,SortBenchmark默认产生的随机数是64位长整型long。
整个命令的表述是:SortBenchmark组件要求产生2000M的随机数排序,分给20个Data.From阶段任务去执行。每个Data.From阶段任务负责产生100M的随机数,随机数将按照Work.To阶段任务的20个节点数要求,把100M数据切割成20个5M数据,每个5M数据会有一个对应的“模”值。之后把数据写入硬盘,并把20个5M的数据映像成一组元数据,返回给Call节点。Call节点将对20个Data节点的元数据进行平衡计算,通过拆分重组后,对应Work.To的20个节点数,产生20组新的元数据(这些元数据中指明了Data节点地址和数据位置),分配给Work节点。如果所有Data.From阶段任务产生的随机数是完全平均的(这是理想状态,现实中不会有绝对的平均),那么每个Work.To阶段任务,将启动20个连接,去20个Data.From阶段任务中,拿走其中一个5M数据,并把20个5M数据在本地内存重新合并成100M的数据。这时,按照Call节点给每个Work.To的编号排列,每个Work.To阶段任务中保存的随机数,它们之间已经形成链接关系(当前Work.To阶段任务保存的最后一个排序数字,总比下个任务第一个排序数字大)。此时再对100M数据进行升序排序,就产生了最后的计算结果。
出于对Front节点计算机性能考虑,2000M的数据量实在太大,接收下来要花很长一段时间,这将影响到统计总计算时间,况且也没有必要接收这些数据,所以在Work.To排序后,数据将丢弃,只返回一个排序测试报告(实际是SortBenchmark自定义自解释的元数据)给Front节点。
图10.5.1.1是基于硬盘的排序,Data.From将随机数据生成后,写入到硬盘,然后在Work.To请求下,又从硬盘读出。我们前面多次提到过,硬盘是数据处理过程中的最大瓶颈,会消耗很多输入输出时间,所以在图10.5.1.2中,我们调用7.8节所提的中数据数据写入接口(MidWriter),每个Data.From存储100M数据的位置,由默认的硬盘改为内存,省略了写/读硬盘过程,这样SortBenchmark整个处理流程不再接触硬盘,成为一次流式排序操作,排序结果明显比基于硬盘的排序方式快了很多。
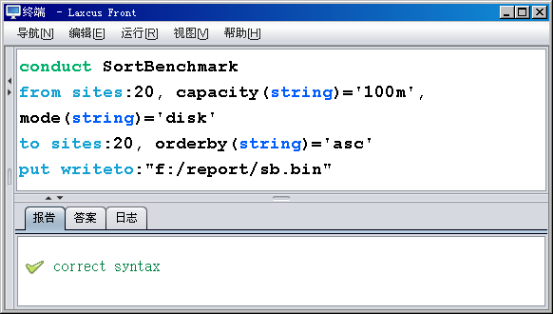
图10.5.1.1 基于硬盘的Sort Benchmark排序
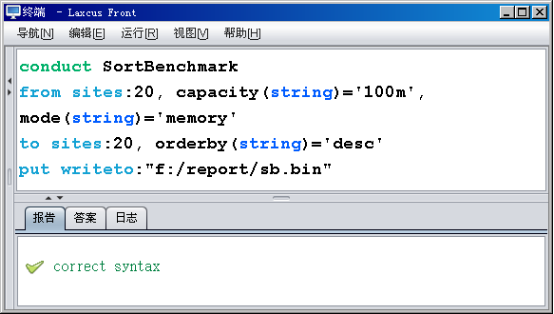
图10.5.1.2 基于内存的Sort Benchmark排序
|
节点 |
节点工作说明 |
节点数 |
连接数 |
数据量 |
平均单位量 |
最大用时(毫秒) |
最小用时(毫秒) |
平均用时(毫秒) |
|
Data |
产生随机数 |
20 |
- |
100M |
5M |
3862 |
1351 |
1703 |
|
数据写入硬盘 |
20 |
- |
100M |
5M |
1538 |
327 |
1021 |
|
|
从硬盘读数据 |
20 |
- |
100M |
5M |
1095 |
177 |
692 |
|
|
Call |
平均分配数据 |
1 |
- |
- |
- |
1 |
- |
- |
|
Work |
网络传输 |
20 |
20 |
100M |
5M |
214 |
196 |
202 |
|
排序 |
20 |
- |
100M |
- |
23724 |
12731 |
16198 |
|
|
Front |
执行和等待 |
1 |
1 |
2000M |
- |
30771 |
- |
- |
表10.5.1.1 基于硬盘的Sort Benchmark排序
|
节点 |
节点工作说明 |
节点数 |
连接数 |
数据量 |
平均单位量 |
最大用时(毫秒) |
最小用时(毫秒) |
平均用时(毫秒) |
|
Data |
产生随机数 |
20 |
- |
100M |
5M |
3831 |
1369 |
1707 |
|
数据写入硬盘 |
- |
- |
- |
- |
- |
- |
- |
|
|
从硬盘读数据 |
- |
- |
- |
- |
- |
- |
- |
|
|
Call |
平均分配数据 |
1 |
- |
- |
- |
0 |
- |
- |
|
Work |
网络传输 |
20 |
20 |
100M |
5M |
229 |
193 |
205 |
|
排序 |
20 |
- |
100M |
- |
24061 |
12577 |
16430 |
|
|
Front |
执行和等待 |
1 |
1 |
2000M |
- |
28527 |
- |
- |
表10.5.1.2 基于内存的Sort Benchmark排序
10.5.2 排序分析
从上述两组对比测试数据可以看出,数据的产生、传输、排序阶段,它们的平均处理时间是接近的。但是同一阶段的并行任务之间,它们的处理时间差距则很大,这是由于硬件配置不一致所造成。这种最快和最慢之间的差距,是导致数据排序木桶短板现象的直接原因。造成下一阶段的等待时间,由上一阶段的最慢那个线程决定,如此迭代下去,将严重影响整体排序处理效果。这是目前很多大数据处理普遍存在的现象。所以在运营的集群环境中,负责数据处理工作同一类型的节点,如果能够使用相同的硬件配置,将有效减少这种拖滞问题。
为了达到快速的数据处理效果,把存储中间数据的位置,从硬盘改为内存,这是流式处理的基本原理。这种方案带的好处就是数据处理速度确实加快了,但是缺点也很明显:提供云计算或者集群服务的运营商要采购更多内存,这样就增加了设备投入成本,对运营商来说是一件“奢侈”的服务方案。另外根据我们的市场调查,目前需要快速数据处理业务方案的用户比例并不高。
10.5.3 排序优化
上述排序仍然存在一个问题:100M的数据量,对于一台计算机来说,计算量实在不小,这从Work.To阶段任务的排序时间就可以看出。如果能让Work.To把每次的数据量变得更小一些,分成多个批次排序,这样总数据量没有变,但是总计算时间会相应缩短。再采用衔接的办法,把数据按照“模”方式串联起,会得到和上述一样的排序结果。
这个测试很容易,有兴趣的读者可以在自己的计算机上尝试一下,看看1个10M的数据排序时间,和10个1M数据排序的时间,它们有多少差别。
图10.5.3.1展示了这样一个改进,在Conduct命令的From阶段增加一个“next_split(int)=5”自定义参数。这样就把在原来每个5M基础上的数据,再分成5份,实际上形成了100个1M的数据单元。Data.From每次产生的随机数,被分到100个1M单元中的一个,返回的模值,也由原来100/20的关系,变成100/100的关系。在Work.To阶段,相应需要启动100个连接,每个连接拿加加属于自己的一块数据,再按照20*1M,分成5个20M的数据,每个20M的数据为一个单位进行排序,5次排序后,再按照它们的模值串联起来,形成最后的排序结果。
如果希望将总处理时间进一步提高,“next_split(int)=5”这个参数还可以再增加,使得Work.To单次排序数据量更小,然后再结合“模”衔接,得到更快的排序效果。另外现在的计算机已经普遍使用多核CPU,这样在排序时,同一时间可以并发多个线程,将使得总排序时间获得进一步改善。
需要说明一点,这里忽略了socket问题。因为本次排序,集群中只有一个任务,单机并发100个连接和产生的流量尚在可接受范围内,但是在实际的运营环境中,这种并发连接可能会产生很大的数据流量,按照Laxcus流量控制机制的规定,超过环境条件许可的连接和流量将受到限制,所以实际效果可能并不如意,这一点用户应该注意。

图10.5.3.1 基于内存的细分排序
Laxcus大数据管理系统2.0(12)- 第十章 运行的更多相关文章
- Laxcus大数据管理系统2.0(5)- 第二章 数据组织
第二章 数据组织 在数据的组织结构设计上,Laxcus严格遵循数据和数据描述分离的原则,这个理念与关系数据库完全一致.在此基础上,为了保证大规模数据存取和计算的需要,我们设计了大量新的数据处理技术.同 ...
- Laxcus大数据管理系统2.0(8)- 第六章 网络通信
第六章 网络通信 Laxcus大数据管理系统网络建立在TCP/IP网络之上,从2.0版本开始,同时支持IPv4和IPv6两种网络地址.网络通信是Laxcus体系里最基础和重要的一环,为了能够利用有限的 ...
- Laxcus大数据管理系统2.0(3)- 第一章 基础概述 1.2 产品特点
1.2 产品特点 Laxcus大数据管理系统运行在计算机集群上,特别强调软件对分布资源可随机增减的适应性.这种运行过程中数据动态波动和需要瞬时感知的特点,完全不同与传统的集中处理模式.这个特性衍生出一 ...
- Laxcus大数据管理系统2.0 (1) - 摘要和目录
Laxcus大数据管理系统 (version 2.0) Laxcus大数据实验室 摘要 Laxcus是Laxcus大数据实验室全体系全功能设计研发的多用户多集群大数据管理系统,支持一到百万台级节点,提 ...
- Laxcus大数据管理系统2.0(9)- 第七章 分布任务组件
第七章 分布任务组件 Laxcus 2.0版本的分布任务组件,是在1.x版本的基础上,重新整合中间件和分布计算技术,按照新增加的功能,设计的一套新的.分布状态下运行的数据计算组件和数据构建组件,以及依 ...
- Laxcus大数据管理系统2.0(10)- 第八章 安全
第八章 安全 由于安全问题对大数据系统乃至当前社会的重要性,我们在Laxcus 2.0版本实现了全体系的安全管理策略.同时我们也考虑到系统的不同环节对安全管理的需求是不一样的,所以有选择地做了不同的安 ...
- Laxcus大数据管理系统2.0(6)- 第四章 数据计算
第四章 数据计算 Laxcus所有数据计算工作都是通过网络实施.相较于集中计算,在网络间进行的数据计算更适合处理那些数据量大.复杂的.耗时长的计算任务.能够实施网络计算的前提是数据可以被分割,就是把一 ...
- Laxcus大数据管理系统2.0(14)- 后记
后记 Laxcus最早源于一个失败的搜索引擎项目,项目最后虽然终止了,但是项目中的部分技术,包括FIXP协议.Diffuse/Converge算法.以及很多新的数据处理理念却得以保留下来,这些成为后来 ...
- Laxcus大数据管理系统2.0(5)- 第三章 数据存取
第三章 数据存取 当前的很多大数据处理工作,一次计算产生几十个GB.或者几十个TB的数据已是正常现象,驱动数百.数千.甚至上万个计算机节点并行运行也已经不足为奇.但是在数据处理的后面,对于这种在网络间 ...
随机推荐
- TortoiseSVN 分支创建与合并
前提准备: 确保本地Work Copy 和 服务器上的 版本一致.( 所有代码都提交到SVN,并update一次) 1 从主干创建分支代码 在本地Work Copy 选中项目文件夹,鼠标右键选择 ...
- 使用OrgChart插件生成家谱组织结构图
1.orgchart插件: github地址:https://github.com/dabeng/OrgChart 2.前端代码: //1.加载树形数据:ajax请求获取json格式的数据(flag参 ...
- python3 基于tcp 简单client和server
客户端代码 from socket import * #客户端 client=socket(AF_INET,SOCK_STREAM) #通讯地址 client.connect(('172.18.100 ...
- MySQL中的事件/定时任务
转载自:http://www.cnblogs.com/chenpi/p/5137310.html 什么是事件 一组SQL集,用来执行定时任务,跟触发器很像,都是被动执行的,事件是因为时间到了触发执行, ...
- 关于MySQL优化问题
众所周知在数据量庞大的情况下普通的SQL语句已经满足不了我们的需要了,这个时候就需要DBA去进行数据库的优化,而我们作为一名开发人员不能对数据库进行优化这时该怎么办呢?答案是只能在SQL语句上面进行优 ...
- 解决IDEA打印到控制台的中文内容乱码
File-->Settings-->Editor-->File Encodings->将图中内容均设置为UTF-8--->点击+号选中自己的项目->Apply--& ...
- margin中的bug解决方法
margin bug问题 : 当做子元素中使用margin-top: 50px;父子元素都会跑出50px, 解决方法: 在父元素中使用下面三种任意一种都可以. 方法一:给父元素加边框 border: ...
- php http_build_query stream_context_create post请求
<?php function send_post($url, $post_data) { $postdata = http_build_query($post_data); $options = ...
- Python图像处理:图像腐蚀与图像膨胀
图像的膨胀(Dilation)和腐蚀(Erosion)是两种基本的形态学运算,主要用来寻找图像中的极大区域和极小区域.其中膨胀类似于“领域扩张”,将图像中的高亮区域或白色部分进行扩张,其运行结果图比原 ...
- Django的安装创建与连接数据库
HTTP协议简介 HTTP是一个客户端终端(用户)和服务器端(网站)请求和应答的标准(TCP).通过使用网 页浏览器.网络爬虫或者其它的工具,客户端发起一个HTTP请求到服务器上指定端口(默认端 口为 ...