求最小生成树——Kruskal算法和Prim算法
给定一个带权值的无向图,要求权值之和最小的生成树,常用的算法有Kruskal算法和Prim算法。这两个算法其实都是贪心思想的使用,但又能求出最优解。(代码借鉴http://blog.csdn.net/u014488381)
一.Kruskal算法
Kruskal算法的基本思想:先将所有边按权值从小到大排序,然后按顺序选取每条边,假如一条边的两个端点不在同一个集合中,就将这两个端点合并到同一个集合中;假如两个端点在同一个集合中,说明这两个端点已经连通了,就将当前这条边舍弃掉;当所有顶点都在同一个集合时,说明最小生成树已经形成。(写代码的时候会将所有边遍历一遍)
来看一个例子:
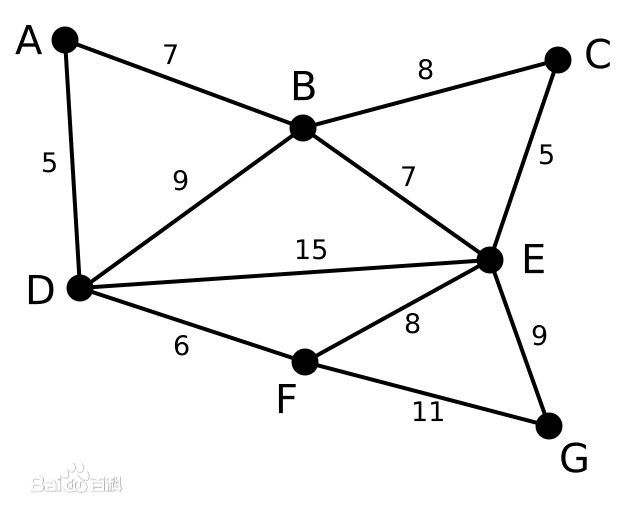
步骤:
(1)先根据权值把边排序:
AD 5
CE 5
DF 6
AB 7
BE 7
BC 8
EF 8
BD 9
EG 9
FG 11
(2)
选择AD这条边,将A、D加到同一个集合1中
选择CE这条边,将C、E加到同一个集合2中(不同于AD的集合)
选择DF这条边,由于D已经在集合1中,因此将F加入到集合1中,集合变为A、D、F
选择AB这条边,同理,集合1变为A、B、D、F
选择BE这条边,由于B在集合1中,E在集合2中,因此将两个集合合并,形成一个新的集合ABCDEF
由于E、F已经在同一集合中,舍弃掉BC这条边;同理舍弃掉EF、BD
选择EG这条边,此时所有元素都已经在同一集合中,最小生成树形成
象征性地舍弃掉FG这条边
实现代码如下:
#include <iostream>
#include <cstring>
#define MaxSize 20
using namespace std; struct Edge{
int begin;
int end;
int weight;
};
struct Graph{
char ver[MaxSize + ];
int edg[MaxSize][MaxSize];
}; void CreateGraph(Graph *g) {
int VertexNum;
char Ver;
int i = ;
cout << "输入图的顶点:" << endl;
while ((Ver = getchar()) != '\n') {
g->ver[i] = Ver;
i++;
}
g->ver[i] = '\0';
VertexNum = strlen(g->ver);
cout << "输入相应的邻接矩阵" << endl;
for (int i = ; i < VertexNum; i++) {
for (int j = ; j < VertexNum; j++) {
cin >> g->edg[i][j]; //输入0则为没有边相连啊
}
}
} void PrintGraph(Graph g) {
int VertexNum = strlen(g.ver);
cout << "图的顶点为:" << endl;
for (int i = ; i < VertexNum; i++) {
cout << g.ver[i] << " ";
}
cout << endl;
cout << "图的邻接矩阵为:" << endl;
for (int i = ; i < VertexNum; i++) {
for (int j = ; j < VertexNum; j++) {
cout << g.edg[i][j] << " ";
}
cout << endl;
}
} int getVerNum(Graph g) {
return strlen(g.ver);
} int getEdgeNum(Graph g) {
int res = ;
int VertexNum = getVerNum(g);
for (int i = ; i < VertexNum; i++) {
//邻接矩阵对称,计算上三角元素和即可
for (int j = i + /*假设没有自己指向自己的*/; j < VertexNum; j++) {
if (g.edg[i][j] != ) res++;
}
}
return res;
} Edge *CreateEdges(Graph g) {
int k = ;
int EdgeNum = getEdgeNum(g);
int VertexNum = getVerNum(g);
Edge * p = new Edge[EdgeNum];
for (int i = ; i < VertexNum; i++) {
for (int j = i; j < VertexNum; j++) {
if (g.edg[i][j] != ) {
p[k].begin = i;
p[k].end = j;
p[k].weight = g.edg[i][j];
k++;
}
}
}
for (int i = ; i < EdgeNum - ; i++) {
Edge minWeightEdge = p[i];
for (int j = i + ; j < EdgeNum; j++) {
if (minWeightEdge.weight > p[j].weight) {
Edge temp = minWeightEdge;
minWeightEdge = p[j];
p[j] = temp;
}
}
p[i] = minWeightEdge;
}
return p;
} void Kruskal(Graph g) {
int VertexNum = getVerNum(g);
int EdgeNum = getEdgeNum(g);
Edge *p = CreateEdges(g);
int *index = new int[VertexNum]; //index数组,其元素为连通分量的编号,index[i]==index[j]表示编号为i和j的顶点在同一连通分量中
int *MSTEdge = new int[VertexNum - ]; //用来存储已确定的最小生成树的**边的编号**,共VertexNum-1条边
int k = ;
int WeightSum = ;
int IndexBegin, IndexEnd;
for (int i = ; i < VertexNum; i++) {
index[i] = -; //初始化所有index为-1
}
for (int i = ; i < VertexNum - ; i++) {
for (int j = ; j < EdgeNum; j++) {
if ( !(index[p[j].begin] >= && index[p[j].end] >= && index[p[j].begin] == index[p[j].end] /*若成立表明p[j].begin和p[j].end已在同一连通块中(且可相互到达,废话)*/) ) {
MSTEdge[i] = j;
if (index[p[j].begin] == - && index[p[j].end] == -) {
index[p[j].begin] = index[p[j].end] = i;
}
else if (index[p[j].begin] == - && index[p[j].end] >= ) {
index[p[j].begin] = i;
IndexEnd = index[p[j].end];
for (int n = ; n < VertexNum; n++) {
if (index[n] == IndexEnd) {
index[n] == i;
}
}
}
else if (index[p[j].begin] >= && index[p[j].end] == -) {
index[p[j].end] = i;
IndexBegin = index[p[j].begin];
/*将连通分量合并(或者说将没加入连通分量的顶点加进去,然后将原来连通分量的值改了)*/
for (int n = ; n < VertexNum; n++) {
if (index[n] == IndexBegin) {
index[n] == i;
}
}
}
else {
IndexBegin = index[p[j].begin];
IndexEnd = index[p[j].end];
for (int n = ; n < VertexNum; n++) {
if (index[n] == IndexBegin || index[n] == IndexEnd) {
index[n] = i;
}
}
}
break;
}
}
}
cout << "MST的边为:" << endl;
for (int i = ; i < VertexNum - ; i++) {
cout << g.ver[p[MSTEdge[i]].begin] << "--" << g.ver[p[MSTEdge[i]].end] << endl;
WeightSum += p[MSTEdge[i]].weight;
}
cout << "MST的权值为:" << WeightSum << endl;
}
二.Prim算法(代码还没理解)
Prim算法的基本思想:设置两个存放顶点的集合,第一个集合初始化为空,第二个集合初始化为一个包含所有顶点的集合。首先把图中的任意一个顶点a放进第一个集合,然后在第二个集合中找到一个顶点b,使b到第一个集合中的任意一点的权值最小,然后把b从第二个集合移到第一个集合。接着在第二个集合中找到顶点c,使c到a或b的权值比到第二个集合中的其他任何顶点到a或b的权值都要小,然后把c从第二个集合移到第一个集合中。以此类推,当第二个集合中的顶点全部移到第一个集合时,最小生成树产生。
以上面的图再次作为例子:
设第一个集合为V,第二个集合为U。
V={A}, U={B, C, D, E, F, G}
(1)A连接了两个顶点,B和D,AB权值为7,AD权值为5,选择权值小的一条边和相应的顶点D,将D加入集合V中。V={A, D}, U={B, C, E, F, G}
(2)观察包含V中的元素A和D的边,AB权值为7,BD权值为9,DE权值为15,DF权值为6,将F加入V中。V={A, D, F}, U={B, C, E, G}
(3)依次将B(AB)、E(BE)、C(CE)、G(EG)加入到集合V中。
(4)最小生成树的边包括:AD DF AB BE CE EG,problem solved
实现代码如下:
#include <iostream>
#include <vector>
#include <cstring>
using namespace std;
#define MaxSize 20
struct Graph{
char ver[MaxSize + ];
int edg[MaxSize][MaxSize];
}; void CreateGraph(Graph *g) {
int VertexNum;
char Ver;
int i = ;
cout << "输入图的顶点:" << endl;
while ((Ver = getchar()) != '\n') {
g->ver[i] = Ver;
i++;
}
g->ver[i] = '\0';
VertexNum = strlen(g->ver);
cout << "输入相应的邻接矩阵" << endl;
for (int i = ; i < VertexNum; i++) {
for (int j = ; j < VertexNum; j++) {
cin >> g->edg[i][j]; //输入0则为没有边相连啊
}
}
} void PrintGraph(Graph g) {
int VertexNum = strlen(g.ver);
cout << "图的顶点为:" << endl;
for (int i = ; i < VertexNum; i++) {
cout << g.ver[i] << " ";
}
cout << endl;
cout << "图的邻接矩阵为:" << endl;
for (int i = ; i < VertexNum; i++) {
for (int j = ; j < VertexNum; j++) {
cout << g.edg[i][j] << " ";
}
cout << endl;
}
} int getVerNum(Graph g) {
return strlen(g.ver);
} //将不邻接的顶点之间的权值设为
void SetWeight(Graph *g) {
for (int i = ; i < getVerNum(*g); i++) {
for (int j = ; j < getVerNum(*g); j++) {
if (g->edg[i][j] == ) {
g->edg[i][j] = INT_MAX;
}
}
}
} void Prim(Graph g, int *parent) {
//V为所有顶点的集合,U为最小生成树的节点集合
int lowcost[MaxSize]; //lowcost[k]保存着编号为k的顶点到U中所有顶点的最小权值
int closest[MaxSize]; //closest[k]保存着U到V-U中编号为k的顶点权值最小的顶点的编号
int used[MaxSize];
int min;
int VertexNum = getVerNum(g);
for (int i = ; i < VertexNum; i++) {
lowcost[i] = g.edg[][i];
closest[i] = ;
used[i] = ;
parent[i] = -;
}
used[] = ;
for (int i = ; i < VertexNum - ; i++) {
int j = ;
min = INT_MAX;
for (int k = ; k < VertexNum; k++) { //找到V-U中的与U中顶点组成的最小权值的边的顶点编号
if (used[k] == && lowcost[k] < min) {
min = lowcost[k];
j = k;
}
}
parent[j] = closest[j];
used[j] = ;
for (int k = ; k < VertexNum; k++) { //由于j顶点加入U中,更新lowcost和closest数组中的元素,检测V-U中的顶点到j顶点的权值是否比j加入U之前的lowcost数组的元素小
if (used[k] == && g.edg[j][k] < lowcost[k]) {
lowcost[k] = g.edg[j][k];
closest[k] = j;
}
}
}
} void PrintMST(Graph g, int *parent) {
int VertexNum = getVerNum(g);
int weight = ;
cout << "MST的边为:" << endl;
for (int i = ; i < VertexNum; i++) {
cout << g.ver[parent[i]] << "--" << g.ver[i] << endl;
weight += g.edg[parent[i]][i];
}
cout << "MST的权值为" << weight << endl;
} int main() {
Graph g;
int parent[];
CreateGraph(&g);
PrintGraph(g);
SetWeight(&g);
Prim(g, parent);
PrintMST(g, parent);
return ;
}
三.Kruskal算法和Prim算法的适用情况
Kruskal算法适用于边稀疏的情况(要进行排序),Prim算法适用于边稠密的情况。
求最小生成树——Kruskal算法和Prim算法的更多相关文章
- 贪心算法-最小生成树Kruskal算法和Prim算法
Kruskal算法: 不断地选择未被选中的边中权重最轻且不会形成环的一条. 简单的理解: 不停地循环,每一次都寻找两个顶点,这两个顶点不在同一个真子集里,且边上的权值最小. 把找到的这两个顶点联合起来 ...
- 最小生成树之Kruskal算法和Prim算法
依据图的深度优先遍历和广度优先遍历,能够用最少的边连接全部的顶点,并且不会形成回路. 这样的连接全部顶点并且路径唯一的树型结构称为生成树或扩展树.实际中.希望产生的生成树的全部边的权值和最小,称之为最 ...
- Algorithm --> Kruskal算法和Prim算法
最小生成树之Kruskal算法和Prim算法 Kruskal多用于稀疏图,prim多用于稠密图. 根据图的深度优先遍历和广度优先遍历,可以用最少的边连接所有的顶点,而且不会形成回路.这种连接所有顶点并 ...
- 最小生成数kruskal算法和prim算法
定义 连通图:在无向图中,若任意两个顶点vivi与vjvj都有路径相通,则称该无向图为连通图. 强连通图:在有向图中,若任意两个顶点vivi与vjvj都有路径相通,则称该有向图为强连通图. 连通网:在 ...
- 最小生成树的两种方法(Kruskal算法和Prim算法)
关于图的几个概念定义: 连通图:在无向图中,若任意两个顶点vivi与vjvj都有路径相通,则称该无向图为连通图. 强连通图:在有向图中,若任意两个顶点vivi与vjvj都有路径相通,则称该有向图为强连 ...
- 最小生成树(次小生成树)(最小生成树不唯一) 模板:Kruskal算法和 Prim算法
Kruskal模板:按照边权排序,开始从最小边生成树 #include<algorithm> #include<stdio.h> #include<string.h> ...
- 求最小生成树——Kruskal算法
给定一个带权值的无向图,要求权值之和最小的生成树,常用的算法有Kruskal算法和Prim算法.这篇文章先介绍Kruskal算法. Kruskal算法的基本思想:先将所有边按权值从小到大排序,然后按顺 ...
- Prim算法和Dijkstra算法的异同
Prim算法和Dijkstra算法的异同 之前一直觉得Prim和Dijkstra很相似,但是没有仔细对比: 今天看了下,主要有以下几点: 1: Prim是计算最小生成树的算法,比如为N个村庄修路,怎么 ...
- 使用Apriori算法和FP-growth算法进行关联分析
系列文章:<机器学习实战>学习笔记 最近看了<机器学习实战>中的第11章(使用Apriori算法进行关联分析)和第12章(使用FP-growth算法来高效发现频繁项集).正如章 ...
随机推荐
- python进阶九_网络编程
Python网络编程一 一.一些基本概念 在Python网络编程这一节中会涉及到非常多网络相关的术语.对于一些最主要的概念,如TCP/IP,Socket等等不再赘述,不明确的能够自己去查一查,对于一些 ...
- ytu 2231: 交集问题(线性表)(数据结构,链表练习)
2231: 交集问题(线性表) Time Limit: 1 Sec Memory Limit: 128 MBSubmit: 6 Solved: 3[Submit][Status][Web Boar ...
- (转)使用 python Matplotlib 库绘图
运行一个简单的程序例子: import matplotlib.pyplot as plt plt.plot([1,2,3]) plt.ylabel('some numbers') plt.show() ...
- lighttpd mysql php简单教程
lighttpd mysql php简单教程 lighttpd+php5+mysql+Debian etch lighttpd是速度最快的静态web server,mysql最通用的的database ...
- uiautomatorviewer.bat使用方法
在android目录下找到uiautomatorviewer.bat,然后双击,页面的第二个按钮连接设备 D:\Program Files\android-sdk-windows\tools\uiau ...
- AndroidManifest.xml文件详解(activity)(三)四种工作模式
android:launchMode 这个属性定义了应该如何启动Activity的一个指令.有四种工作模式会跟Intent对象中的Activity标记(FLAG_ACTIVITY_*常量)结合在一起用 ...
- 认识tornado(四)
接下来我们看一下helloword.py的唯一一个handler. 1 class MainHandler(tornado.web.RequestHandler): 2 def get(self): ...
- JZOJ.5231【NOIP2017模拟8.5】序列问题
Description Input 输入文件名为seq.in.首先输入n.接下来输入n个数,描述序列 A. Output 输出文件名为seq.out.输出一行一个整数代表答案. Sample ...
- 160810、Java Object类
Object 类位于 java.lang 包中,是所有 Java 类的祖先,Java 中的每个类都由它扩展而来. 定义Java类时如果没有显示的指明父类,那么就默认继承了 Object 类.例如: p ...
- Powershell Get-FileHash
File Hash (Get-FileHash C:\fso\myfile.txt).hash Get-FileHash C:\Users\Andris\Downloads\Contoso8_1_EN ...