二叉树、平衡二叉树、B-Tree与B+Tree
本文总结自:https://blog.csdn.net/chuixue24/article/details/80027689
二叉树(B树,binary tree)
左子树的键值 < 根的键值 < 右子树的键值
该二叉树的节点进行查找深度为1的节点的查找次数为1,深度为2的查找次数为2,深度为n的节点的查找次数为n
若想二叉树的查询效率尽可能高,需要这棵二叉树是平衡的,从而引出新的定义——平衡二叉树,或称AVL树。
平衡二叉树(AVL树,Adelson-Velskii and Landis tree)
任何节点的两个子树的高度最大差为1
备注:高度:从其最低后代节点往上数的节点个数
平衡多路二叉树(B- 树/B_树/B树,balance- tree)
多路:即节点不再是两个子节点,可以有多个
B-Tree是为磁盘等外存储设备设计的一种平衡查找树。
系统从磁盘读取数据到内存时是以磁盘块(block)为基本单位的,位于同一个磁盘块中的数据会被一次性读取出来,而不是需要什么取什么。
而InnoDB存储引擎中有页(Page)的概念,页是其磁盘管理的最小单位。InnoDB存储引擎中默认每个页的大小为16KB,可通过参数innodb_page_size将页的大小设置为4K、8K、16K。
而一个磁盘块的存储空间往往没有这么大,因此InnoDB每次申请磁盘空间时都会是若干地址连续磁盘块来达到页的大小16KB。
InnoDB在把磁盘数据读入到磁盘时会以页为基本单位,在查询数据时,如果一个页中的每条数据都能有助于定位数据记录的具体位置,那么将会减少磁盘I/O次数,提高查询效率。
B-Tree结构的数据可以让系统高效的找到数据所在的磁盘块。
以下为每页的结构:
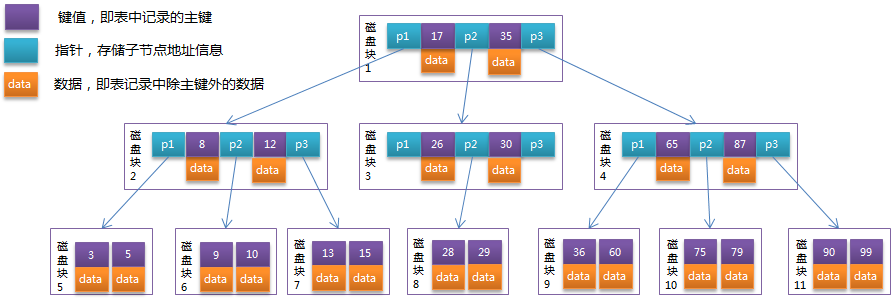
每个节点占用一个盘块的磁盘空间,一个节点上有两个升序排序的关键字和三个指向子树根节点的指针,指针存储的是子节点所在磁盘块的地址。
两个关键词划分成的三个范围域对应三个指针指向的子树的数据的范围域。以根节点为例:关键字为17和35,P1指针指向的子树的数据范围为小于17,P2指针指向的子树的数据范围为17~35,P3指针指向的子树的数据范围为大于35。
模拟查找关键字29的过程:
- 根据根节点找到磁盘块1,读入内存。【磁盘I/O操作第1次】
- 比较关键字29在区间(17,35),找到磁盘块1的指针P2。
- 根据P2指针找到磁盘块3,读入内存。【磁盘I/O操作第2次】
- 比较关键字29在区间(26,30),找到磁盘块3的指针P2。
- 根据P2指针找到磁盘块8,读入内存。【磁盘I/O操作第3次】
- 在磁盘块8中的关键字列表中找到关键字29。
分析上面过程,发现需要3次磁盘I/O操作,和3次内存查找操作。由于内存中的关键字是一个有序表结构,可以利用二分法查找提高效率。而3次磁盘I/O操作是影响整个B-Tree查找效率的决定因素。B-Tree相对于AVLTree缩减了节点个数,使每次磁盘I/O取到内存的数据都发挥了作用,从而提高了查询效率。
B+Tree(balance+ tree)
B+Tree是在B-Tree基础上的一种优化,使其更适合实现外存储索引结构,InnoDB存储引擎就是用B+Tree实现其索引结构。
B-Tree结构图中可以看到每个节点中不仅包含数据的key值,还有data值(非叶子节点也有)。而每一个页的存储空间是有限的,
如果data数据较大时将会导致每个节点(即一个页)能存储的key的数量很小,
当存储的数据量很大时同样会导致B-Tree的深度较大,增大查询时的磁盘I/O次数,进而影响查询效率。
在B+Tree中,所有数据记录节点都是按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储key值信息,这样可以大大加大每个节点存储的key值数量,降低B+Tree的高度。
且B+树的所有关键字的具体信息都存储在叶子结点,通常都会使用链表将叶子结点连接起来,遍历叶子结点就能够获取到所有的数据,也就可以进行区间查询,而B树只有中序遍历才能够获取到所有的数据。
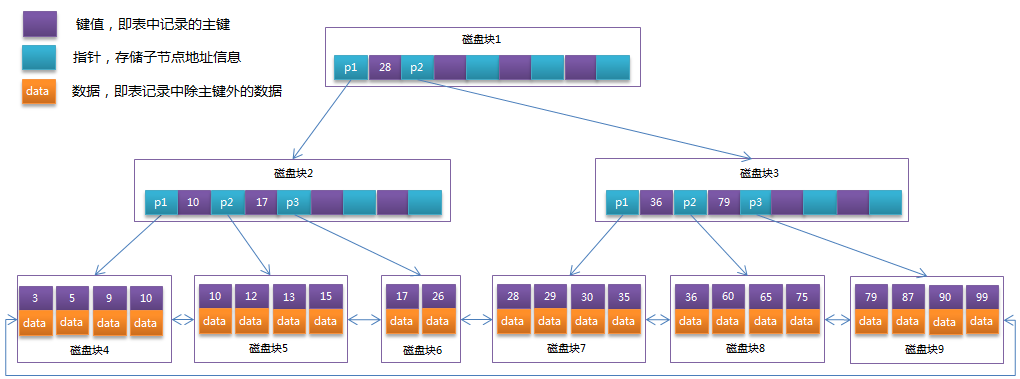
1. 提高深度,提高存储量
2. 适合区间查询
二叉树、平衡二叉树、B-Tree与B+Tree的更多相关文章
- C# 链表 二叉树 平衡二叉树 红黑树 B-Tree B+Tree 索引实现
链表=>二叉树=>平衡二叉树=>红黑树=>B-Tree=>B+Tree 1.链表 链表结构是由许多节点构成的,每个节点都包含两部分: 数据部分:保存该节点的实际数据. 地 ...
- 平衡二叉树(Balanced Binary Tree 或 Height-Balanced Tree)又称AVL树
平衡二叉树(Balanced Binary Tree 或 Height-Balanced Tree)又称AVL树 (a)和(b)都是排序二叉树,但是查找(b)的93节点就需要查找6次,查找(a)的93 ...
- [LeetCode] Encode N-ary Tree to Binary Tree 将N叉树编码为二叉树
Design an algorithm to encode an N-ary tree into a binary tree and decode the binary tree to get the ...
- [线索二叉树] [LeetCode] 不需要栈或者别的辅助空间,完成二叉树的中序遍历。题:Recover Binary Search Tree,Binary Tree Inorder Traversal
既上篇关于二叉搜索树的文章后,这篇文章介绍一种针对二叉树的新的中序遍历方式,它的特点是不需要递归或者使用栈,而是纯粹使用循环的方式,完成中序遍历. 线索二叉树介绍 首先我们引入“线索二叉树”的概念: ...
- Leetcode之深度优先搜索(DFS)专题-199. 二叉树的右视图(Binary Tree Right Side View)
Leetcode之深度优先搜索(DFS)专题-199. 二叉树的右视图(Binary Tree Right Side View) 深度优先搜索的解题详细介绍,点击 给定一棵二叉树,想象自己站在它的右侧 ...
- 二叉树 & 平衡二叉树 算法(Java实现)
二叉树 比如我要依次插入10.3.1.8.23.15.28.先插入10作为根节点: 然后插入3,比10小,放在左边: 再插入1,比10和3小,放在3左边: 再插入8,比10小,比3大,放在3右边: 再 ...
- 找出 int 数组的平衡点 & 二叉树 / 平衡二叉树 / 满二叉树 / 完全二叉树 / 二叉查找树
找出 int 数组的平衡点 左右两边和相等, 若存在返回平衡点的值(可能由多个); 若不存在返回 -1; ``java int [] arr = {2,3,4,2,4}; ```js const ar ...
- 将百分制转换为5分制的算法 Binary Search Tree ordered binary tree sorted binary tree Huffman Tree
1.二叉搜索树:去一个陌生的城市问路到目的地: for each node, all elements in its left subtree are less-or-equal to the nod ...
- B-Tree、B+Tree和B*Tree
B-Tree(这儿可不是减号,就是常规意义的BTree) 是一种多路搜索树: 1.定义任意非叶子结点最多只有M个儿子:且M>2: 2.根结点的儿子数为[2, M]: 3.除根结点以外的非叶子结点 ...
随机推荐
- 怎么用ChemDraw 15.1 Pro绘制彩色结构
ChemOffice 15是最新的ChemDraw化学工具套件,合理的使用这套软件可以大幅度的提高研究人员的工作效率.也有一些化学老师使用这套化学绘图软件教学,其可以绘制彩色结构有效增强教案说服力并吸 ...
- poj 3414(简单bfs)
题目链接:http://poj.org/problem?id=3414 思路:bfs简单应用,增对瓶A或者瓶B进行分析就可以了,一共6种状态. #include<iostream> #in ...
- php面试题笔试题 比较有用
一.选择题1.php的源代码是 (A )A.开放的 B.封闭的 C.需购买的 D.完全不可见的2.php的输出语句是 ( C )A.out.print B.response.write C.echo ...
- 【BZOJ4380】[POI2015]Myjnie 区间DP
[BZOJ4380][POI2015]Myjnie Description 有n家洗车店从左往右排成一排,每家店都有一个正整数价格p[i].有m个人要来消费,第i个人会驶过第a[i]个开始一直到第b[ ...
- beetl模板的${!}用法
转自:http://ibeetl.com/guide/#beetl 2.20. 安全输出 安全输出是任何一个模板引擎必须重视的问题,否则,将极大困扰模板开发者.Beetl中,如果要输出的模板变量为nu ...
- VMware虚拟机Host-Only(仅主机模式)
转载于:https://www.linuxidc.com/Linux/2016-09/135521p3.htm 三.Host-Only(仅主机模式) Host-Only模式其实就是NAT模式去除了虚拟 ...
- 巨蟒python全栈开发-第22天 内置常用模块1
一.今日主要内容 1.简单了解模块 你写的每一个py文件都是一个模块 数据结构(队列,栈(重点)) 还有一些我们一直在使用的模块 buildins 内置模块.print,input random 主要 ...
- 巨蟒python全栈开发数据库前端5:JavaScript1
1.js介绍&变量&基础数据类型 2.类型查询&运算符&if判断&for循环 3.while循环&三元运算符 4.函数 5.今日总结 1.js介绍&am ...
- Powershell About Active Directory Group Membership of a domain user
使用Get-User命令去寻找group membership of a domain user $((Get-ADUser Wendy -Properties *).MemberOf -split ...
- Frequent Values-线段树求解出现最多的数
Frequent Values(poj 3368) 注意:以下答案为离线作答结果,并非能通过poj,若要通过poj,需要修改函数接口,因为以下程序接受半封闭区间(s,e],同时还需要修改输入数据的顺序 ...