storm 入门原理介绍
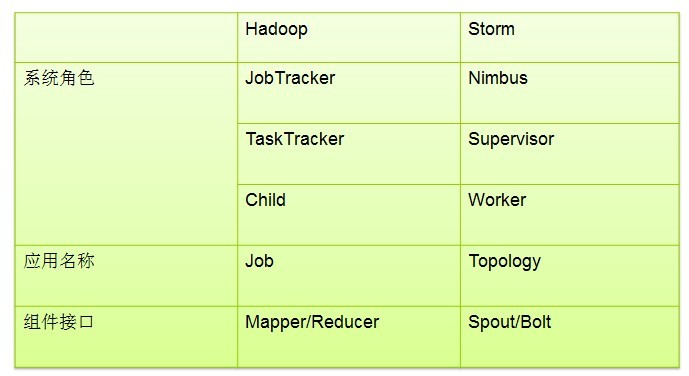
1.hadoop有master与slave,Storm与之对应的节点是什么?
2.Storm控制节点上面运行一个后台程序被称之为什么?
3.Supervisor的作用是什么?
4.Topology与Worker之间的关系是什么?
5.Nimbus和Supervisor之间的所有协调工作有master来完成,还是Zookeeper集群完成?
6.storm稳定的原因是什么?
7.如何运行Topology?
strom jar all-your-code.jar backtype.storm.MyTopology arg1 arg2
8.spout是什么?
9.bolt是什么?
10.Topology由两部分组成?
11.stream grouping有几种?
Storm对于实时计算的的意义相当于Hadoop对于批处理的意义。Hadoop为我们提供了Map和Reduce原语,使我们对数据进行批处理变的非常的简单和优美。同样,Storm也对数据的实时计算提供了简单Spout和Bolt原语。
Storm适用的场景:
1、流数据处理:Storm可以用来用来处理源源不断的消息,并将处理之后的结果保存到持久化介质中。
2、分布式RPC:由于Storm的处理组件都是分布式的,而且处理延迟都极低,所以可以Storm可以做为一个通用的分布式RPC框架来使用。
1、准备工作
2、一个Storm集群的基本组件
而在Storm上面你运行的是Topology。它们是非常不一样的 — 一个关键的区别是: 一个MapReduce Job最终会结束,
而一个Topology运永远运行(除非你显式的杀掉他)。
node)。控制节点上面运行一个后台程序:Nimbus,
它的作用类似Hadoop里面的JobTracker。Nimbus负责在集群里面分布代码,分配工作给机器, 并且监控状态。
TaskTracker)。Supervisor会监听分配给它那台机器的工作,根据需要
启动/关闭工作进程。每一个工作进程执行一个Topology(类似 Job)的一个子集;一个运行的Topology由运行在很多机器上的很多工作进程
Worker(类似 Child)组成。
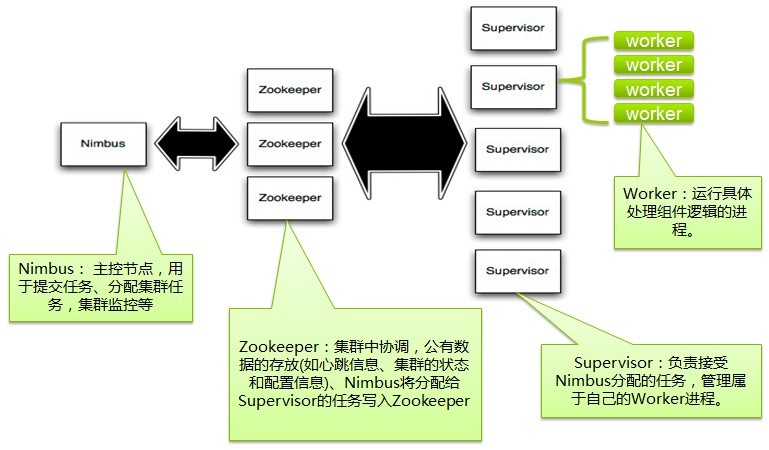
Nimbus和Supervisor之间的所有协调工作都是通过一个Zookeeper集群来完成。并且,nimbus进程和supervisor都是快
速失败(fail-fast)和无状态的。所有的状态要么在Zookeeper里面, 要么在本地磁盘上。这也就意味着你可以用kill
-9来杀死nimbus和supervisor进程, 然后再重启它们,它们可以继续工作,
就好像什么都没有发生过似的。这个设计使得storm不可思议的稳定。
3、Topologies
- strom jar all-your-code.jar backtype.storm.MyTopology arg1 arg2
复制代码
-based语言提交的最简单的方法, 看一下文章: 在生产集群上运行topology去看看怎么启动以及停止topologies。
4、Stream
比如从一些tweet里面计算出热门话题, 需要多个步骤, 从而也就需要多个bolt。 Bolt可以做任何事情: 运行函数, 过滤tuple,
做一些聚合, 做一些合并以及访问数据库等等。
Bolt处理输入的Stream,并产生新的输出Stream。Bolt可以执行过滤、函数操作、Join、操作数据库等任何操作。Bolt是一个被动的
角色,其接口中有一个execute(Tuple input)方法,在接收到消息之后会调用此函数,用户可以在此方法中执行自己的处理逻辑。
你可以把topology提交给storm的集群来运行。topology的结构在Topology那一段已经说过了,这里就不再赘述了。
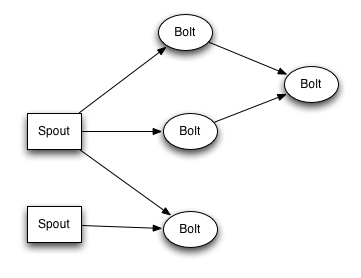
5、数据模型(Data Model)
在我的理解里面一个tuple可以看作一个没有方法的java对象。总体来看,storm支持所有的基本类型、字符串以及字节数组作为tuple的值类
型。你也可以使用你自己定义的类型来作为值类型, 只要你实现对应的序列化器(serializer)。


public class DoubleAndTripleBoltimplementsIRichBolt {
private OutputCollectorBase _collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollectorBase collector) {
_collector = collector;
}
@Override
public void execute(Tuple input) {
intval = input.getInteger(0);
_collector.emit(input,newValues(val*2, val*3));
_collector.ack(input);
}
@Override
public void cleanup() {
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(newFields("double","triple"));
}
}
TopologyBuilder builder =newTopologyBuilder();
builder.setSpout(1,newTestWordSpout(),10);
builder.setBolt(2,newExclamationBolt(),3)
.shuffleGrouping(1);
builder.setBolt(3,newExclamationBolt(),2)
.shuffleGrouping(2);
这里第一个Bolt声明它要读取spout所发射的所有的tuple — 使用shuffle
grouping。而第二个bolt声明它读取第一个bolt所发射的tuple。shuffle
grouping表示所有的tuple会被随机的分发给bolt的所有task。给task分发tuple的策略有很多种,后面会介绍。
builder.setBolt(3,newExclamationBolt(),5)
.shuffleGrouping(1)
.shuffleGrouping(2);
让我们深入地看一下这个topology里面的spout和bolt是怎么实现的。Spout负责发射新的tuple到这个topology里面来。 TestWordSpout从["nathan", "mike", "jackson", "golda", "bertels"]里面随机选择一个单词发射出来。TestWordSpout里面的nextTuple()方法是这样定义的:
public void nextTuple() {
Utils.sleep(100);
finalString[] words =newString[] {"nathan","mike",
"jackson","golda","bertels"};
finalRandom rand =newRandom();
finalString word = words[rand.nextInt(words.length)];
_collector.emit(newValues(word));
}
public static class ExclamationBoltimplementsIRichBolt {
OutputCollector _collector;
public void prepare(Map conf, TopologyContext context,
OutputCollector collector) {
_collector = collector;
}
public void execute(Tuple tuple) {
_collector.emit(tuple,newValues(tuple.getString(0) +"!!!"));
_collector.ack(tuple);
}
public void cleanup() {
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(newFields("word"));
}
}
让我们看看怎么以local mode运行ExclamationToplogy。
本地模式对开发和测试来说比较有用。 你运行storm-starter里面的topology的时候它们就是以本地模式运行的,
你可以看到topology里面的每一个组件在发射什么消息。
你同时也把topology的代码提交了。master负责分发你的代码并且负责给你的topolgoy分配工作进程。如果一个工作进程挂掉了,
master节点会把认为重新分配到其它节点。关于如何在一个集群上面运行topology, 你可以看看Running topologies on a
production cluster文章。
Config conf =newConfig();
conf.setDebug(true);
conf.setNumWorkers(2); LocalCluster cluster =newLocalCluster();
cluster.submitTopology("test", conf, builder.createTopology());
Utils.sleep(10000);
cluster.killTopology("test");
cluster.shutdown();
这个代码定义通过定义一个LocalCluster对象来定义一个进程内的集群。提交topology给这个虚拟的集群和提交topology给分布式集
群是一样的。通过调用submitTopology方法来提交topology,
它接受三个参数:要运行的topology的名字,一个配置对象以及要运行的topology本身。
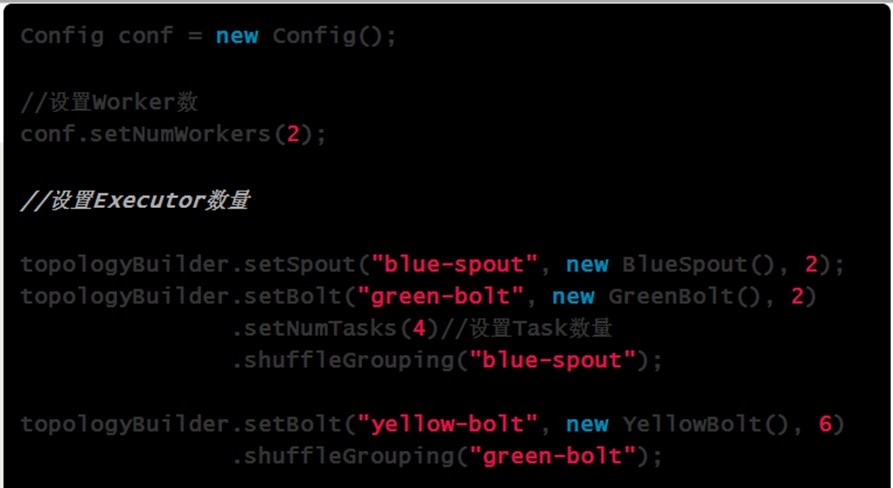
- TOPOLOGY_WORKERS(setNumWorkers) 定义你希望集群分配多少个工作进程给你来执行这个topology.
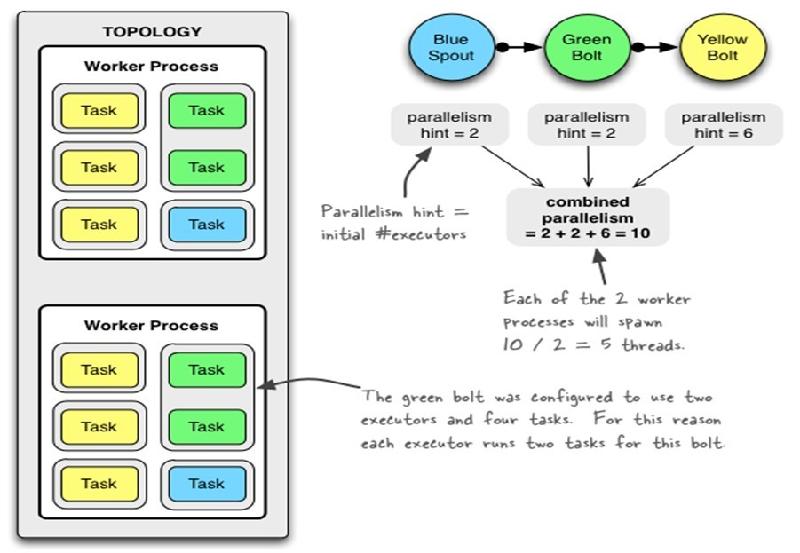
topology里面的每个组件会被需要线程来执行。每个组件到底用多少个线程是通过setBolt和setSpout来指定的。这些线程都运行在工作进
程里面. 每一个工作进程包含一些节点的一些工作线程。比如, 如果你指定300个线程,60个进程, 那么每个工作进程里面要执行6个线程,
而这6个线程可能属于不同的组件(Spout, Bolt)。你可以通过调整每个组件的并行度以及这些线程所在的进程数量来调整topology的性能。 - TOPOLOGY_DEBUG(setDebug), 当它被设置成true的话, storm会记录下每个组件所发射的每条消息。这在本地环境调试topology很有用, 但是在线上这么做的话会影响性能的。
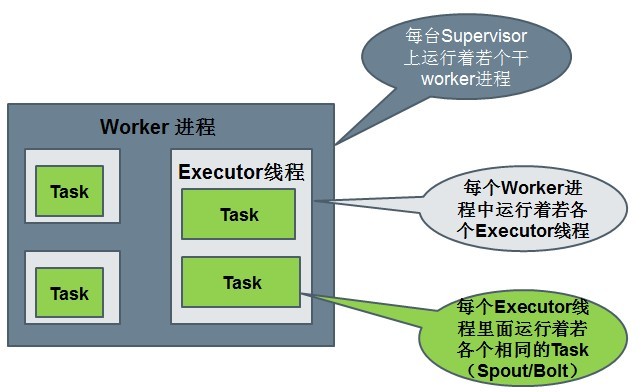
Worker processes(进程)
Executors (threads)(线程)
Tasks

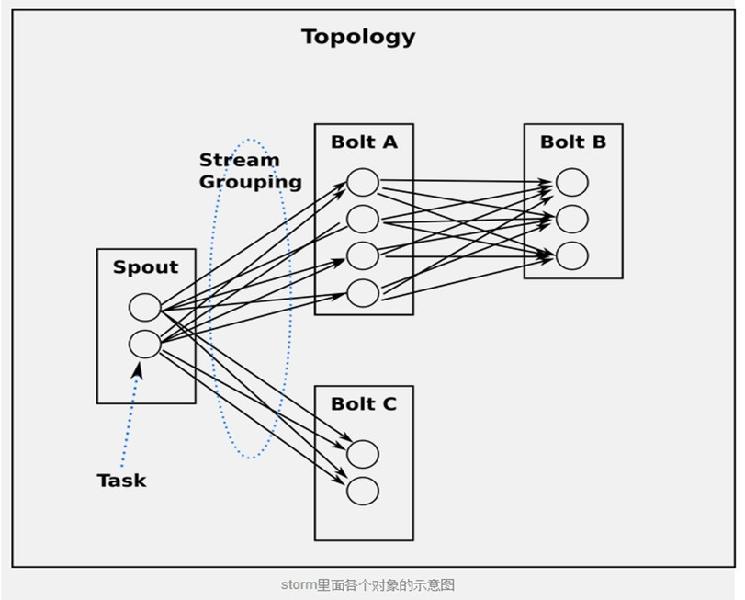
7、流分组策略(Stream grouping)
TopologyBuilder builder =newTopologyBuilder();
builder.setSpout(1,newRandomSentenceSpout(),5);
builder.setBolt(2,newSplitSentence(),8)
.shuffleGrouping(1);
builder.setBolt(3,newWordCount(),12)
.fieldsGrouping(2,newFields("word"));
- 最简单的grouping是shuffle grouping,
它随机发给任何一个task。上面例子里面RandomSentenceSpout和SplitSentence之间用的就是shuffle
grouping, shuffle grouping对各个task的tuple分配的比较均匀。 - 一种更有趣的grouping是fields grouping, SplitSentence和WordCount之间使用的就是fields
grouping, 这种grouping机制保证相同field值的tuple会去同一个task,
这对于WordCount来说非常关键,如果同一个单词不去同一个task, 那么统计出来的单词次数就不对了。
l ShuffleGrouping:随机选择一个Task来发送。
l FiledGrouping:根据Tuple中Fields来做一致性hash,相同hash值的Tuple被发送到相同的Task。
l AllGrouping:广播发送,将每一个Tuple发送到所有的Task。
l GlobalGrouping:所有的Tuple会被发送到某个Bolt中的id最小的那个Task。
l NoneGrouping:不关心Tuple发送给哪个Task来处理,等价于ShuffleGrouping。
l DirectGrouping:直接将Tuple发送到指定的Task来处理。
8、使用别的语言来定义Bolt
storm使用JSON消息通过stdin/stdout来和这些subprocess通信。这个通信协议是一个只有100行的库,
storm团队给这些库开发了对应的Ruby, Python和Fancy版本。
public static class SplitSentenceextendsShellBoltimplementsIRichBolt {
publicSplitSentence() {
super("python","splitsentence.py");
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(newFields("word"));
}
}
SplitSentence继承自ShellBolt并且声明这个Bolt用python来运行,并且参数是: splitsentence.py。下面是splitsentence.py的定义:
importstorm
class SplitSentenceBolt(storm.BasicBolt):
defprocess(self, tup):
words=tup.values[0].split(" ")
forwordinwords:
storm.emit([word])
SplitSentenceBolt().run()
9、可靠的消息处理
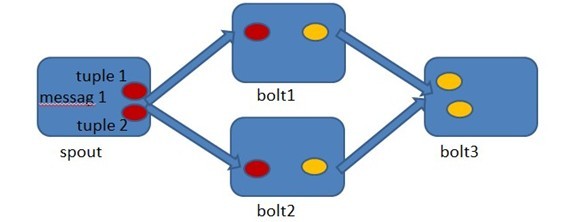
Storm中的每一个Topology中都包含有一个Acker组件。Acker组件的任务就是跟踪从Spout中流出的每一个messageId所绑定
的Tuple树中的所有Tuple的处理情况。如果在用户设置的最大超时时间内这些Tuple没有被完全处理,那么Acker会告诉Spout该消息处理
失败,相反则会告知Spout该消息处理成功。
Tree的RootId。RootId会被传递给Acker以及后续的Bolt来作为该消息单元的唯一标识。同时,无论Spout还是Bolt每次新生成
一个Tuple时,都会赋予该Tuple一个唯一的64位整数的Id。
当Spout发射完某个MessageId对应的源Tuple之后,它会告诉Acker自己发射的RootId以及生成的那些源Tuple的Id。而当
Bolt处理完一个输入Tuple并产生出新的Tuple时,也会告知Acker自己处理的输入Tuple的Id以及新生成的那些Tuple的Id。
Acker只需要对这些Id进行异或运算,就能判断出该RootId对应的消息单元是否成功处理完成了。
原文:http://www.aboutyun.com/thread-7394-1-1.html
storm 入门原理介绍的更多相关文章
- (转发)storm 入门原理介绍
1.hadoop有master与slave,Storm与之对应的节点是什么? 2.Storm控制节点上面运行一个后台程序被称之为什么?3.Supervisor的作用是什么?4.Topology与Wor ...
- storm 入门原理介绍_AboutYUN
转自:http://www.aboutyun.com/thread-7394-1-1.html 了解Storm:http://www.aboutyun.com/thread-9547-1-2.html ...
- storm入门原理介绍
转自:http://www.cnblogs.com/wuxiang/p/5629138.html 1.hadoop有master与slave,Storm与之对应的节点是什么?2.Storm控制节点上面 ...
- storm原理介绍
目录 storm原理介绍 一.原理介绍 二.配置 三.并行度 (一)storm拓扑的并行度可以从以下4个维度进行设置: (二)并行度的设置方法 (三)示例 四.分组 五.可靠性 (一)spout (二 ...
- 《Storm入门》中文版
本文翻译自<Getting Started With Storm>译者:吴京润 编辑:郭蕾 方腾飞 本书的译文仅限于学习和研究之用,没有原作者和译者的授权不能用于商业用途. 译者序 ...
- Kylin系列之二:原理介绍
Kylin系列之二:原理介绍 2018年4月15日 15:52 因何而生 Kylin和hive的区别 1. hive主要是离线分析平台,适用于已经有成熟的报表体系,每天只要定时运行即可. 2. Kyl ...
- Apache Storm内部原理分析
转自:http://shiyanjun.cn/archives/1472.html 本文算是个人对Storm应用和学习的一个总结,由于不太懂Clojure语言,所以无法更多地从源码分析,但是参考了官网 ...
- kafka集群原理介绍
目录 kafka集群原理介绍 (一)基础理论 二.配置文件 三.错误处理 kafka集群原理介绍 @(博客文章)[kafka|大数据] 本系统文章共三篇,分别为 1.kafka集群原理介绍了以下几个方 ...
- storm入门demo
一.storm入门demo的介绍 storm的入门helloworld有2种方式,一种是本地的,另一种是远程. 本地实现: 本地写好demo之后,不用搭建storm集群,下载storm的相关jar包即 ...
随机推荐
- oracle忘记密码
1.输入命令: sqlplus /nolog ,进入oracle控制台,并输入 conn /as sysdba;以DBA角色进入. 2.连接成功后,输入"select username fr ...
- LinuxMysql命令操作数据库
键入命令mysql -uroot -p密码查看所有表:mysql> show databases;进入表use multidomain_db;删除表:DROP table colour 执行sq ...
- 设计模式--适配器模式Adapter(结构型)
一.适配器模式 适配器模式的主要作用是在新接口和老接口之间进行适配.将一个类的接口转换成客户端期望的另外一个接口.其实适配器模式有点无赖之举,在前期设计的时候,我们就不应该考虑适配器模式,而应该通过重 ...
- Python之str()与repr()的区别
Python之str()与repr()的区别 str()一般是将数值转成字符串,主要面向用户. repr()是将一个对象转成字符串显示,注意只是显示用,有些对象转成字符串没有直接的意思.如list, ...
- XML 基础
linux下xml编辑器 vim gedit editix wonderful;免费30天;可以进行有效性检查 xerces oxygen 收费 xmlcopyedit serna free 是ser ...
- html JS 打开本地程序及文件
在网页打开本地应用程序示例: 一.在本地注册表自定义协议:以自定义调用Viso为例 1.在HKEY_CLASSES_ROOT下添加项ZVISIO. 2.修改ZVISIO项下的"(默认)&qu ...
- ios 弹出不同的键盘
iOS 提供了10种键盘类型,在开发中,我们可以根据不同的需求,选择不同的键盘样式,例如,当我们只需要输入手机号码时,可以选择纯数字类型的键盘(NumbersAndPunctuation),当我们需要 ...
- HTTP协议请求响应过程和HTTPS工作原理
HTTP协议 HTTP协议主要应用是在服务器和客户端之间,客户端接受超文本. 服务器按照一定规则,发送到客户端(一般是浏览器)的传送通信协议.与之类似的还有文件传送协议(file transfer p ...
- setInterval的停止与启动
最近写代码,需要停止interval之后再重新启动,开始使用代码如下,发现无法重新启动 function func(){console.log("print")} //定时任务 v ...
- 【Android进阶学习】shape和selector的结合使用(转)
原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否则将追究法律责任.http://liangruijun.blog.51cto.com/3061169/732310 ...