(一)Lucene——基本概念介绍
1. Lucene是什么
Lucene 是一个基于 Java 的全文信息检索工具包,它不是一个完整的搜索应用程序,而是为你的应用程序提供索引和搜索功能。Lucene 目前是 Apache Jakarta 家族中的一个开源项目。也是目前最为流行的基于 Java 开源全文检索工具包。
2. 全文检索的应用场景
- 搜索引擎
- 站内搜索
- 文件系统搜索
3. 全文检索的定义
全文检索首先对要搜索的文档进行分词,然后形成索引,通过查询索引来查询文档。
全文检索就是先创建索引,然后根据索引来进行搜索的过程,就叫全文检索。
比如:字典
字典的偏旁部首页,就类似于luence的索引;字典的具体内容,就类似于luence的文档内容。
4. Lucene实现全文检索的流程
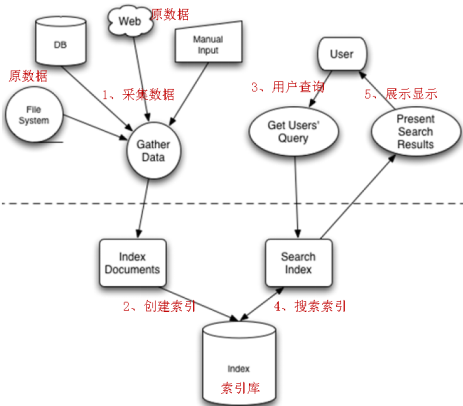
全文检索的流程:索引流程、搜索流程
- 索引流程:采集数据—》文档处理—》存储到索引库中
- 搜索流程:输入查询条件—》通过lucene的查询器查询索引—》从索引库中取出结—》视图渲染
Lucene本身不能进行视图渲染。
6. Lucene 软件包分析
Lucene 软件包的发布形式是一个 JAR 文件,下面介绍这个 JAR 文件里面的主要的 JAVA 包。
- Package: org.apache.lucene.document
这个包提供了一些为封装要索引的文档所需要的类,比如 Document, Field。这样,每一个文档最终被封装成了一个 Document 对象。 - Package: org.apache.lucene.analysis
这个包主要功能是对文档进行分词,因为文档在建立索引之前必须要进行分词,所以这个包的作用可以看成是为建立索引做准备工作。 - Package: org.apache.lucene.index
这个包提供了一些类来协助创建索引以及对创建好的索引进行更新。这里面有两个基础的类:IndexWriter 和 IndexReader,其中 IndexWriter 是用来创建索引并添加文档到索引中的,IndexReader 是用来删除索引中的文档的。 - Package: org.apache.lucene.search
这个包提供了对在建立好的索引上进行搜索所需要的类。比如 IndexSearcher 和 Hits, IndexSearcher 定义了在指定的索引上进行搜索的方法,Hits 用来保存搜索得到的结果。
7. 索引相关概念
为了对文档进行索引,Lucene 提供了五个基础的类,他们分别是 Document, Field, IndexWriter, Analyzer, Directory。下面分别介绍一下这五个类的用途:
- Document
Document 是用来描述文档的,这里的文档可以指一个 HTML 页面,一封电子邮件,或者是一个文本文件。一个 Document 对象由多个 Field 对象组成的。可以把一个 Document 对象想象成数据库中的一个记录,而每个 Field 对象就是记录的一个字段。 - Field
Field 对象是用来描述一个文档的某个属性的,比如一封电子邮件的标题和内容可以用两个 Field 对象分别描述。 - Analyzer
在一个文档被索引之前,首先需要对文档内容进行分词处理,这部分工作就是由 Analyzer 来做的。Analyzer 类是一个抽象类,它有多个实现。针对不同的语言和应用需要选择适合的 Analyzer。Analyzer 把分词后的内容交给 IndexWriter 来建立索引。 - IndexWriter
IndexWriter 是 Lucene 用来创建索引的一个核心的类,他的作用是把一个个的 Document 对象加到索引中来。 - Directory
这个类代表了 Lucene 的索引的存储的位置,这是一个抽象类,它目前有两个实现,第一个是 FSDirectory,它表示一个存储在文件系统中的索引的位置。第二个是 RAMDirectory,它表示一个存储在内存当中的索引的位置。
8. 索引流程
8.1 为什么采集数据
全文检索搜索的内容的格式是多种多样的,比如:视频、mp3、图片、文档等等。对于这种格式不同的数据,需要先将他们采集到本地,然后统一封装到lucene的文档对象中,也就是说需要将存储的内容进行统一才能对它进行查询。
8.2 采集数据的方式
- 对于互联网中的数据,使用爬虫工具(http工具)将网页爬取到本地
- 对于数据库中的数据,使用jdbc程序进行数据采集
- 对于文件系统的数据,使用io流采集
因为目前搜索引擎主要搜索数据的来源是互联网,搜索引擎使用一种爬虫程序抓取网页( 通过http抓取html网页信息),以下是一些爬虫项目:
- Solr(http://lucene.apache.org/solr) ,solr是apache的一个子项目,支持从关系数据库、xml文档中提取原始数据。
- Nutch(http://lucene.apache.org/nutch), Nutch是apache的一个子项目,包括大规模爬虫工具,能够抓取和分辨web网站数据。
- jsoup(http://jsoup.org/ ),jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
- heritrix(http://sourceforge.net/projects/archive-crawler/files/),Heritrix 是一个由 java 开发的、开源的网络爬虫,用户可以使用它来从网上抓取想要的资源。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。
8.3 索引文件的逻辑结构

- 文档域
文档域存储的信息就是采集到的信息,通过Document对象来存储,具体说是通过Document对象中field域来存储数据。
比如:数据库中一条记录会存储一个一个Document对象,数据库中一列会存储成Document中一个field域。
文档域中,Document对象之间是没有关系的。而且每个Document中的field域也不一定一样。 - 索引域
索引域主要是为了搜索使用的。索引域内容是经过lucene分词之后存储的。 - 倒排索引表
传统方法是先找到文件,如何在文件中找内容,在文件内容中匹配搜索关键字,这种方法是顺序扫描方法,数据量大就搜索慢。
倒排索引结构是根据内容(词语)找文档,倒排索引结构也叫反向索引结构,包括索引和文档两部分,索引即词汇表,它是在索引中匹配搜索关键字,由于索引内容量有限并且采用固定优化算法搜索速度很快,找到了索引中的词汇,词汇与文档关联,从而最终找到了文档。

附:
Lucene是开发全文检索功能的工具包,使用时从官方网站下载,并解压。
官方网站:http://lucene.apache.org/ 目前最新版本:7.0.1
下载地址:http://archive.apache.org/dist/lucene/java/ 下载版本:7.0.1
(一)Lucene——基本概念介绍的更多相关文章
- 【Oracle 集群】ORACLE DATABASE 11G RAC 知识图文详细教程之集群概念介绍(一)
集群概念介绍(一)) 白宁超 2015年7月16日 概述:写下本文档的初衷和动力,来源于上篇的<oracle基本操作手册>.oracle基本操作手册是作者研一假期对oracle基础知识学习 ...
- Linux LVM硬盘管理之一:概念介绍
一.LVM概念介绍: LVM是 Logical Volume Manager(逻辑卷管理)的简写,它由Heinz Mauelshagen在Linux 2.4内核上实现.LVM将一个或多个硬盘的分区在逻 ...
- Java SE/ME/EE的概念介绍
转自 Java SE/ME/EE的概念介绍 多数编程语言都有预选编译好的类库以支持各种特定的功能,在Java中,类库以包(package)的形式提供,不同版本的Java提供不同的包,以面向特定的应用. ...
- rocketMq概念介绍
rocketMq官网 http://rocketmq.apache.org/ rocketMq逻辑概念介绍 rocketMq逻辑图 备注: 改图片分享自李占卫的网上家园 说明: 在rocketM ...
- java 并发多线程 锁的分类概念介绍 多线程下篇(二)
接下来对锁的概念再次进行深入的介绍 之前反复的提到锁,通常的理解就是,锁---互斥---同步---阻塞 其实这是常用的独占锁(排它锁)的概念,也是一种简单粗暴的解决方案 抗战电影中,经常出现为了阻止日 ...
- Airflow Python工作流引擎的重要概念介绍
Airflow Python工作流引擎的重要概念介绍 - watermelonbig的专栏 - CSDN博客https://blog.csdn.net/watermelonbig/article/de ...
- spring batch (一) 常见的基本的概念介绍
SpringBatch的基本概念介绍 内容来自<Spring Batch 批处理框架>,作者:刘相. 一.配置文件 在项目中使用spring batch 需要在配置文件中声明: 事务管理器 ...
- helm-chart-1-简单概念介绍-仓库搭建-在rancher上的使用
简单的概念介绍: Chart是helm管理的应用的打包格式,一个chart对应一个或一套应用.内部是一系列的yaml描述文件,以为为yaml 服务的文件. 三个部分,helm .tiller.repo ...
- Netty重要概念介绍
Netty重要概念介绍 Bootstrap Netty应用程序通过设置bootstrap(引导)类开始,该类提供了一个用于网络成配置的容器. 一种是用于客户端的Bootstrap 一种是用于服务端的S ...
随机推荐
- JavaScript的程序构成
JavaScript的程序构成主要从以下几方面做个总结:控制语句.函数 .事件驱动及事件处理,希望对读者有些帮助. 控制语句: if条件语句 基本格式 if(表述式) 语句段1: ...... els ...
- [NOIP2016]天天爱跑步(树上差分+线段树合并)
将每个人跑步的路径拆分成x->lca,lca->y两条路径分别考虑: 对于在点i的观察点,这个人(s->t)能被观察到的充要条件为: 1.直向上的路径:w[i]=dep[s]-dep ...
- 【状压dp】互不侵犯KING
互不侵犯KING Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 3866 Solved: 2264[Submit][Status][Discuss] ...
- lightoj 1229 - Treblecross 博弈论
思路:SG函数 枚举先手的每一个位置是否有必胜. 1)如果出现了XXX则必胜: 2)如果出现了XX或X.X则必败: 3)否则计算后手的sg值和. 代码如下: #include<iostream& ...
- 将HTML元素转换成图片供用户下载(html2canvas + canvas2Image)
这是项目中遇到的一个问题,起初觉得把一个html元素生成图片,提供给用户下载的需求挺容易实现的,毕竟看过一些截图的插件,但是在真正操作中遇到了各种各样的问题,比如移动端上截图显示不清晰,html元素中 ...
- fmri 分析数据 fsl & spm 两大平台比对
基于下面这份ppt:Comparing SPM and FSL, by lChris Rorden fsl & spm都是免费的,都很受欢迎.spm更受欢迎. 两者的区别在于何时利用norma ...
- OpenLayers2中的事件_以Popup为例
SATURDAY, 21 MARCH 1-Preface 前几天阅读学习了OpenLayers'Cookbook中的第四章——Working with events. 从AFDS系统的开发项目进行至今 ...
- XenApp应用虚拟化介绍
https://wenku.baidu.com/view/635223c26137ee06eff91864.html
- 如何解决sqlmapapi重启后,任务全部丢失的问题
sqlmapapi的server每次启动时都会创建一个新的数据库,这样之前的扫描记录都会全部丢失 使用python sqlmapapi.py -s可以看大IPC database的位置,这个各个操作系 ...
- static_cast ,reinterpret_cast
用法:static_cast < type-id > ( expression ) 该运算符把expression转换为type-id类型,但没有运行时类型检查来保证转换的安全性.它主要有 ...