MySQL入门第二天——记录操作与连接查询
常见SQL语法,请参见w3school:http://www.w3school.com.cn/sql/sql_distinct.asp
易百教程:http://www.yiibai.com/sql/first-normal-form.html
更多MySQL教程,参见菜鸟教程:http://www.runoob.com/mysql/mysql-transaction.html
一、记录操作
1.插入记录
1.普通插入

实例:其中对于主键的操作,自增情况下,插入Null值即可(当然也可以是DEFAULT),当然省略插入列名称,所有列都需要赋值
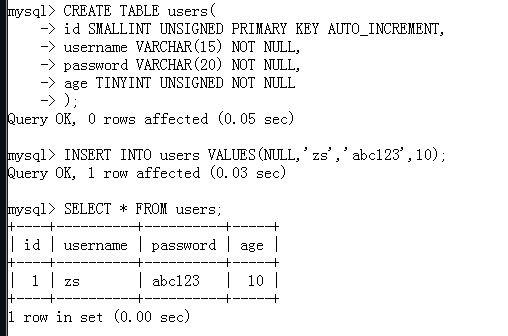
同样,MySQL还支持表达式(甚至是函数)
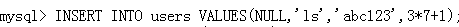
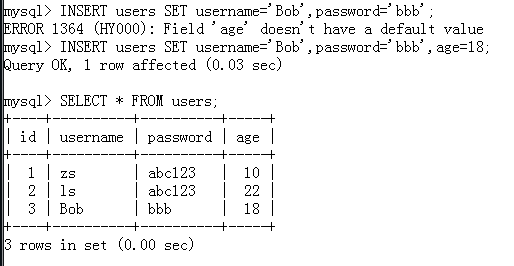
2.INSERT/SET形式插入

实例:由于这里定义表时未给字段设置默认值,当有字段有默认值时,可以不插入(使用默认值)
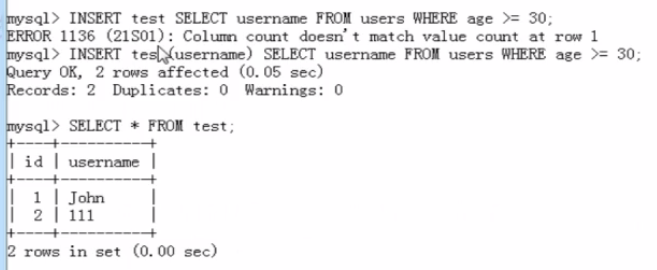
3.INSERT/SELECT插入

实例:

可以插入多条记录:
批量插入的性能分析:http://blog.csdn.net/eason_oracle/article/details/51537310
https://www.cnblogs.com/caicaizi/p/5849979.html
对于使用mybaits批量插入的操作示例:http://blog.csdn.net/bianfu2008zhi/article/details/54572339
2.更新记录
同样,支持WHERE条件的子查询
实例:
/*这里SET的顺序是不影响的,更新给C2的C1值是小于100的那个值,而不是更新成100之后把100赋给C2*/ UPDATE tb1 SET C1 = 100,C2 = C1 WHERE C1 < 100

更新多列(当然是可以条件更新的,未加条件是更新所有的记录,通过受影响的行便可以看到)

3.删除记录
几乎总是先查后删
支持使用WHERE子查询进行限定

实例:删除后再插入时,id依旧是自增的,不会自动补充

在开始查询表达式前,请先牢记SQL执行顺序:http://www.cnblogs.com/qanholas/archive/2010/10/24/1859924.html

通过这个顺序我们也能彻底知道为什么SELECT只能查询分组列和聚合函数了!
关于其中的ON 和 WHERE的顺序关键就是虚表的生成,详细可以参见:http://blog.csdn.net/xc008/article/details/2872310
4.查询表达式解析
查询结果总是以一个表的形式返回(即使只有一个值),因此查询结果可以作为另一个查询的表等的拓展。

查询表达式

实例:
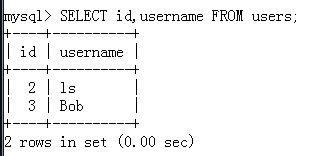
推荐使用别名时加上关键字:AS
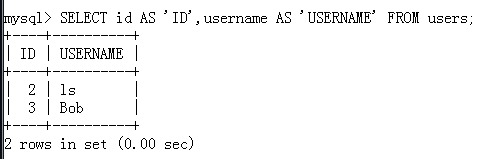
5.条件查询——比较条件(><=,不等于的标准写法<>)/范围条件(BETWEEN AND)/组成员(IN)/模式匹配(LIKE)/Null值匹配(IS [NOT[ NULL)

关于LIKE的转义与通配符的补充:http://blog.csdn.net/feng19821209/article/details/38759417
# 快速使用
LIKE '%5/%%' ESCAPE '/'
select 1 where 'ABC%DE' like 'ABC[%]DE'

6.分组查询:分组查询强烈推荐一个清晰简单的分组讲解博文:http://www.cnblogs.com/snsdzjlz320/p/5738226.html
多列分组同理:
姓名 班级 性别 分数
张1 1班 男 60
张2 1班 女 70
张3 1班 男 80
张4 1班 女 80
张5 2班 男 70
张6 2班 女 60
张7 2班 男 80
select 班级,性别,AVG(分数) as 平均分
from test
group 班级,性别
得出的结果是
班级 性别 平均分
1班 男 70
1班 女 75
2班 男 75
2班 女 60
之前提到过SQSL在对NULL是按照不相等处理的(两个NULL都是未知,认为不相等),但在分组这里,分组列如果为NULL,将会划为一组!

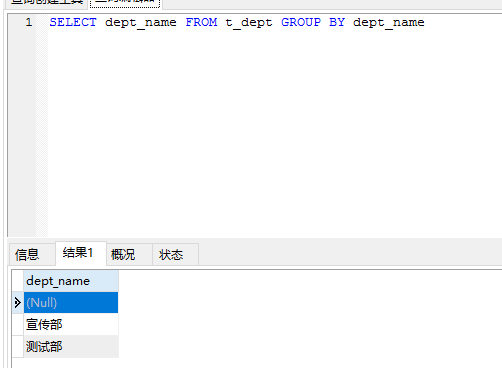

实例:其中GROUP BY后的数字 1 ,表示SELECT后第一个出现的字段
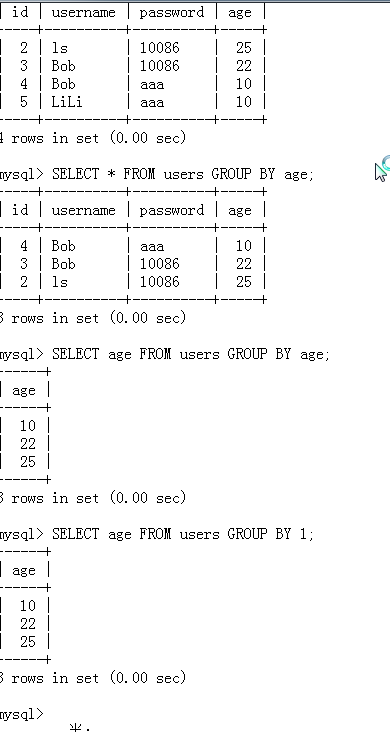
7.分组条件——筛选那些符合条件的“组”

实例:HAVING 后要么是聚合函数,要么是前面查询的字段,也就是说,必须是对“组”的操作

使用聚合函数过滤:(这里也就是分组后组内数量超过1时过滤出来)

8.排序

实例:默认ASC升序

多个字段排序,按照排序字段先后,当第一个排序字段无法区分时,使用后续的排序字段

当一个查询结果是一个计算结果(或者聚合函数)而又没有别名的时候,可以通过字段号(字段顺序从1开始)来指定:
SELECT dept_id,dept_name
FROM t_dept
ORDER BY 1 DESC
补充:union联合查询——用于显示查询结果
条件:
两个表(查询得到的结果表)必须具有相同的字段数目和字段类型
不能对两个表的中的一个排序,只能对最终结果排序
图解:——查询出来的结果是没有字段名的,如果非要排序,请使用字段号
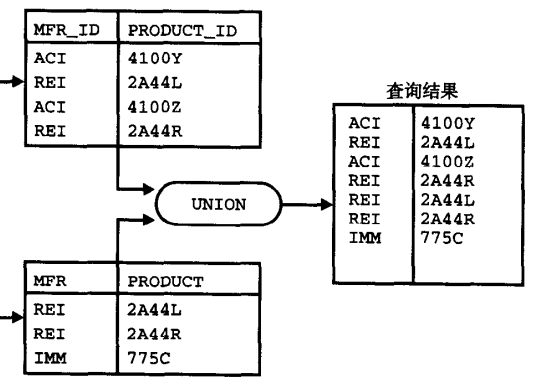
关于UNION/UNION ALL请参见SQL教程
9.限制查询结果

实例:两个参数含义分别是:从第几条开始(下标从0开始),要几条记录,只给一个参数时,默认起始从0第一条记录开始

10.查询表达式
CAST:类型强转:
-- 详细类型请参照SQL数据类型
SELECT NAME CAST PRICE AS VARCHAR FROM order WHERE CUST = 'CAST 2017' AS INTEGER
CASE:类似编程语言的 if...else
完整CASE实例分析,请参见:https://www.cnblogs.com/maanshancss/p/4036608.html
UPDATE Personnel
SET salary = CASE WHEN salary >= 5000
THEN salary * 0.9
WHEN salary >= 2000 AND salary < 4600
THEN salary * 1.15
ELSE salary END;
二、子查询与连接查询
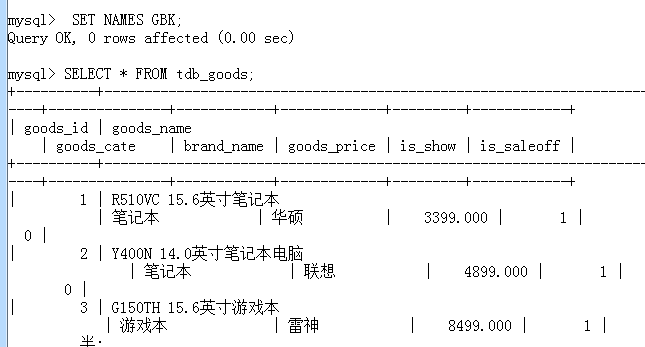
若控制台显示中文乱码:(显示不友好可以使用 \G 进行网格显示)
1.子查询——能使用连接可以使用连接取代子查询


1.比较运算产生的子查询
在标准的SQL中每执行一次WHERE过滤,将要执行一次子查询来判断过滤条件,当然其实很多时候子查询查出来的值都是一样的,无需每次
傻傻的去计算 (商用的SQL会做相关的优化),当然,在使用外部应用的时候无法使用这种优化,这种情况称为“关联子查询”
并且这里子查询可以引用主查询的字段(外部引用)
-- 最后的OFFICE即为主表的OFFICE字段(外部引用)
SELECT
CITY
FROM
OFFICES
WHERE
TARGET > (SELECT SUM(QUOTA) FROM SALES WHERE REP_OFFICE = OFFCIE)

实例:
查询大于平均价格的记录:



比如说 > ANY,只要大于最小值就行了
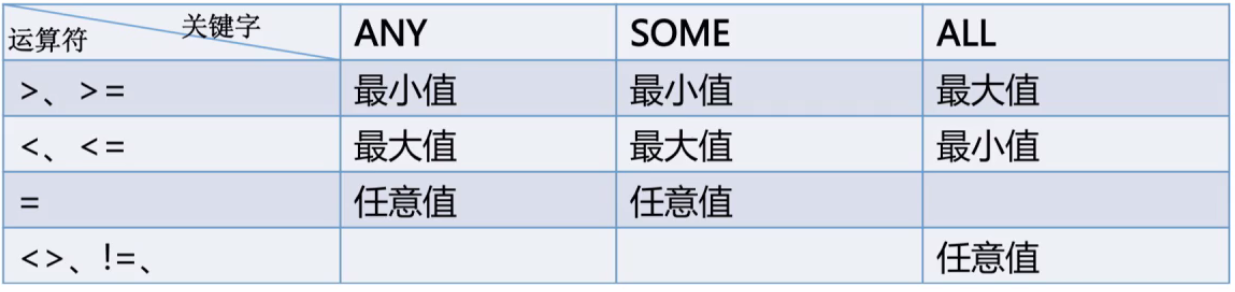
>ANY:比任意一个大(> MIN()),> ALL则为 > MAX,也就是上图的> ANY 相当于>最小值
实例:

2.由[NOT] IN/EXISTS引发的子查询
select * from TableIn where exists(select BID from TableEx where BNAME=TableIn.ANAME)
select * from TableIn where ANAME in(select BNAME from TableEx)
根据《SQL完全手册》,总是使用SELECT * 在EXISTS子句中
通常情况下,IN不会走索引(MySQL高级随笔有相关介绍),所以请谨慎使用IN!

实例:(其中EXISTS使用的频率较低)


3.使用INSERT / SELECT进行插入
将查询结果写入
以上述例子为例,数据库中存储的分类是中文汉字,这样是很影响性能的,我们改造为使用字典对应的方式简化分类的字段,
创建类似字典表的分类表:
这里20多条记录,如果一条一条匹配倒是还可以接受,但是如果记录是20几万条记录呢?
这里就使用到了我们的 INSERT / SELECT形式:


这样,就把分类表给插入了所有的分类记录了:

但是这样只是把分类表抽取出来了,原表并没有改变,我们来进行 多表更新:
2.多表更新

1.连接分类

2.多表更新
我们需要定义更新内容和参照关系:

3.多表更新——一步到位
回顾我们前面抽取分类的步骤:创建分类表——查询商品分类——插入分类名——参照分类表更新原商品表,现在,我们来试试一步到位:

实例:
以品牌为例,先查询品牌:

建表插入一步到位:

多表更新一步到位:

虽然完成了更新,但我们通过查看表结构可以发现,字段类型还是原来的VARCHAR类型,并没有和参照的对应:(当然实际中我们应当在设计表时就存储对应的id即可)

就当前这个问题,我们可以使用之前的CHANGE来修改列定义列名称:
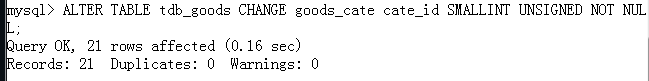
3.连接查询
几个实例可以参考:http://blog.csdn.net/zhangliangzi/article/details/51395940




补充:SQL2标准给出:当有 ON t1.a = t2.a(出现相同名字的字段时),可以使用USING,即以下为等价的
SELECT * FROM t1 LEFT JOIN t2 ON t1.a = t2.a
SELECT * FROM t1 LEFT JOIN t2 USING(a)
1.内连接
只显示符合条件的记录

实例:(以网格形式显示时\G后无需加分号;)

2.外连接——通常,OUTER是可以省略的
左外连接为以左表为准,显示左表的全部记录,右表中不符合记录则对应字段显示NULL(右连接同理)
3.多表连接
mysql> SELECT goods_id,goods_name,cate_name,brand_name,goods_price
-> FROM tdb_goods AS g, tdb_goods_cate AS c, tdb_goods_brands AS b
-> WHERE g.cate_id = c.cate_id AND g.brand_id =b.brand_id;
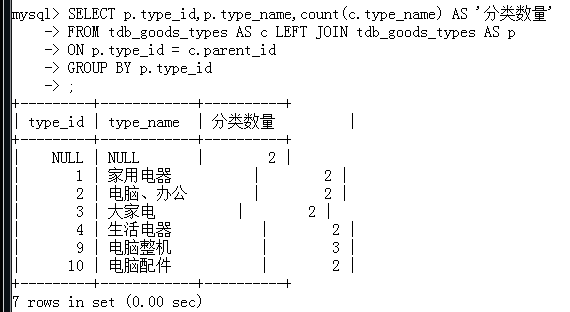
4.无限极分类表设计
实际运用中,很多情况下分类不像举例的那样只有一级的最简单的分类,比如说图书分类,下级有文学类,理学类等,而二级分类下又有细分古代史,近代史,结构力学等等
接下来介绍无限极分类的设计:
创建分类表:(实际的分类表ID可能不会是INT,而会是UUID形式的VARCHAR,请根据实际情况变更)

插入相关的数据:

父ID为0的则为顶级分类:

这种类型的查找,我们可以通过 自身连接
自连接就是自身和自身连接,可以理解为还有一张一样的表,这里我们通过父、子表进行区分联系:
单级查询:

多级查询:(这里仔细捋一捋连接的关系,连接的方向)

当然这种形式肯定不会是我们需要的,我们利用之前的只是稍微改造:
5.多表删除

实例:

MySQL入门第二天——记录操作与连接查询的更多相关文章
- Python/MySQL(二、表操作以及连接)
Python/MySQL(二.表操作以及连接) mysql表操作: 主键:一个表只能有一个主键.主键可以由多列组成. 外键 :可以进行联合外键,操作. mysql> create table y ...
- MySQL入门(函数、条件、连接)
MySQL入门(四) distinct:去重 mysql>: create table t1( id int, x int, y int ); mysql>: insert into t1 ...
- mySQL入门之多表操作
外键 初识外键 外键:引用另一个表中的一列或多列,被引用的列应该具有主键约束或唯一性约束.(外键用于建立和加强两个表数据之间的连接,保证数据的完整和统一性) 主表:被引用的表 从表:引用外键的表 -- ...
- MySQL记录操作(多表查询)
准备 建表与数据准备 #建表 create table department( id int, name varchar(20) ); create table employee( id int pr ...
- MySql 筛选条件、聚合分组、连接查询
筛选条件 比较运算符 等于: = ( 注意!不是 == ) 不等于: != 或 <> 大于: > 大于等于: >= 小于: < 小于等于: <= IS NULL I ...
- MySQL记录操作(单表查询)
单表查询的语法及关键字执行的优先级 单表查询语法 SELECT DISTINCT 字段1,字段2... FROM 表名 WHERE 条件 GROUP BY field HAVING 筛选 ORDER ...
- MySQL入门很简单: 3 操作数据库
登陆:mysq -u root -p 0409 1). 创建, 删除数据库 SHOW DATABASES; 显示已经存在的数据率 CREATE DATABASES 数据库名: 创建数据库 DROP D ...
- Oracle入门第二天(上)——基本查询SQL
一.SQL概述 起源于标准不再赘述,主要分为DDL,DML,DCL 相关介绍,参考MySQL章节:http://www.cnblogs.com/jiangbei/p/6696202.html 二.基本 ...
- Oracle数据库(三)表操作,连接查询,分页
复制表 --复制表 create table new_table as select * from Product --复制表结构不要数据 在where后面跟一个不成立的条件,就会仅复制表的结构而不复 ...
随机推荐
- 调整home和根分区大小
目标:将VolGroup-lv_home缩小到100G,并将剩余的空间添加给VolGroup-lv_root ============================================= ...
- R语言学习笔记2——绘图
R语言提供了非常强大的图形绘制功能.下面来看一个例子: > dose <- c(20, 30, 40, 45, 60)> drugA <- c(16, 20, 27, 40, ...
- Synchronized介绍
来源 https://www.imooc.com/learn/1086 作用 同步方法支持一种简单的策略来防止线程干扰和内存一致性错误,如果一个对象对多个线程可见,则对该对象变量的所有读取或写入都 ...
- MVC学习十一:合并资源文件(BundleConfig)
在BundleConfig.cs文件下 //1.用户可以 手动 添加 js绑定对象,取一个 名字(虚拟路径),添加要绑定的JS文件 路径 bundles.Add(new ScriptBundle(&q ...
- [转] 各种Json解析工具比较 - json-lib/Jackson/Gson/FastJson
JSON技术的调研报告 一 .各个JSON技术的简介和优劣1.json-libjson-lib最开始的也是应用最广泛的json解析工具,json-lib 不好的地方确实是依赖于很多第三方包,包括com ...
- Andorid进阶7—— Ant自动编译打包&发布 android项目
http://www.cnblogs.com/tt_mc/p/3891546.html Eclipse用起来虽然方便,但是编译打包android项目还是比较慢,尤其将应用打包发布到各个渠道时,用Ecl ...
- HDU 1207 汉诺塔II (找规律,递推)
传送门: http://acm.hdu.edu.cn/showproblem.php?pid=1207 汉诺塔II Time Limit: 2000/1000 MS (Java/Others) ...
- Xcode 7提示App Transport Security has blocked a cleartext HTTP (http://) resource load的解决办法
Xcode 7提示App Transport Security has blocked a cleartext HTTP (http://) resource load的解决办法 今天使用Xcod ...
- c++中如 <类名 类名::对象> 是什么意思
CComplex CComplex::add(CComplex &x) (这一句 不懂为何 类名 类名::对象) { CComplex y(real+x.real,image+x.image) ...
- Vue--- 一点车项目 连接数据库
Vue--- 一点车项目 连接数据库 创建连接数据库配置 ###导入 const Koa = require('koa'); const Router = require('koa-router') ...