day058 聚合 分组查询 自定义标签过滤器 外部调用django环境 事务和锁
1.聚合(aggregate)
聚合的主要语法:
from django.db.models import Avg , Max , Min , Count
models.类名 .objects.all().aggregate(聚合函数(字段名))
也可以给聚合函数手动加一个名字 : aggregate(c=count(字段名))
上面这句话的意思是,从类名这个对象中得到你想要聚合(avg,max,min,count)的字段
目前常用的聚合函数有: avg(平均值) , max(最大值) , min(最小值) ,count(计数,有多少个个数)
如果你需要不止一个聚合,可以向aggregate()字句中添加另一个参数,比如:
book.objects.aggregate( Avg(price) , Min(price), Max(price) )
2.分组(annotate)
sql语句 : select * from 表名 group by 以什么进行分组 ;
在orm中,
models.book.objects.values('依据什么字段进行分组').annotate(聚合函数)
例子: 从emp表中找到最高的工资
models.emp.objects.values(dep).annotate(c=Max(salary)) #注意 annotate里面必须写个聚合函数,不然没有意义,并且必须有个别名,别名随便写,但是必须有,用哪个字段分组,values里面就写哪个字段,annotate其实就是对分组结果的统计,统计你需要什么
单表查询:
查询每一个部门(dep)的名称以及对应员工(emp)的平均薪水
models.emp.objects.values('dep_id__name').annotate(av=Avg('salary'))
查询每个部门的Id以及对应的员工的最大的年龄
models.emp.objects.values(dep_id).annotate(max=Max(age))
连表:
models.emp.objects.values(dep__name).annotate(a=Count(id),b=Max(age))
3.F查询: (某数大于,小于某数的查询方式) 如果要查询小于等于可以用 ''~'' 符 ,表示非,小于
语法:
查询a数大于b数的内容
models.book.objects.filter(a__gt=F(b))
查询a数小于b数两倍的内容
models.book.objects.filter(a__lt=F(b)*2)
修改操作也可以使用F函数,比如将每一本书的价格提高10元:
new_price=models.book.objects.update(price=F(price)+10)
4.Q查询:(常与 ''|'' 连用)
语法:
查询姓张的作者或者年龄为28岁的人
models.author.objects.filter(Q(name='张')|Q(age=28))
语法:
查询姓张的作者并且年龄为28岁的人
models.author.objects.filter(Q(name="张"),Q(age=28))
5.orm原生sql语句
Django提供两种方法使用原始SQL进行查询,
一种是raw()方法,进行原始SQL查询并返回模型实例,另一种是完全避开模型层,直接执行自定义的SQL语句.
另一种是extra方法,
6. Python脚本中使用Django环境
import os if __name__ == '__main__':
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "BMS.settings")
import django
django.setup() from app01 import models #引入也要写在上面三句之后 books = models.Book.objects.all()
print(books)
7.自定义标签和过滤器
自定义过滤器:
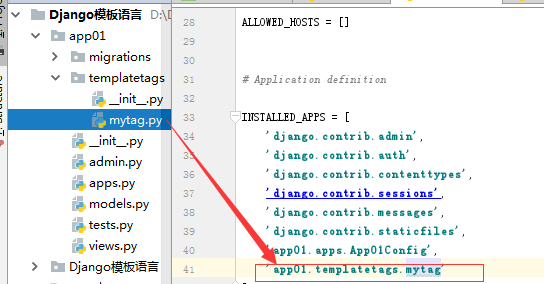
1.在settings中的INSTALLED_APPS配置当前app,不然django无法找到自定义的simple_tag
2.在app中创建tempatetags模块(模块名只能是templatetags)
3.创建任意.py文件,如: my_tags.py
from django import template
from django.urls.safestring import mark_safe register=template.Library() #register的名字是固定的,不可改变
步骤1: 创建一个文件夹,名必须为tempatetags
步骤2: tempatetags中创建.py文件, 导入
from django import template
from django.urls.safestring import mark_safe
步骤3: 在settings中注册
步骤4:写你自己要写的过滤器,比如: 你要将所有的'o'替换成'x'
@register.filter #固定死的
def myreplace(a,b): #最多接收连个参数,而且这个过滤器可以放到if判断和for循环等语句里面
来使用
return a.replace(o,b)
步骤5:在HTML文件中写
在开头引入你创建的py文件
{% load 创建的py文件 %}
然后在你想要过滤的地方写你自定义的过滤器
{{ name|myreplace:'内容' }} 此时就把你的name内容中的'o'全部替换成了'x'
自定义标签:(不能用在if ,for循环里面)
前三步的步骤是相同的
步骤4:
也是写一个函数
@register.simple_tag #也是固定不变的
def func(v1,v2,v3):
过滤内容
步骤5:
在HTML文件中,写你自定义的标签
{% func 属性1 属性2 属性3 ...%}
day058 聚合 分组查询 自定义标签过滤器 外部调用django环境 事务和锁的更多相关文章
- day056-58 django多表增加和查询基于对象和基于双下划线的多表查询聚合 分组查询 自定义标签过滤器 外部调用django环境 事务和锁
一.多表的创建 from django.db import models # Create your models here. class Author(models.Model): id = mod ...
- Django day08 多表操作 (五) 聚合,分组查询 和 F,Q查询
一:聚合,分组查询 二:F, Q查询
- Django之自定义标签,过滤器,以及inclusion_tag
目录 Django之自定义标签,过滤器,以及inclusion_tag 自定义过滤器 自定义标签 inclusion_tag inclusion_tag() 项目实例: inclusion_tag() ...
- Django聚合分组查询、常用字段
首先回顾sql中聚合和分组的概念: 如果没有分组,会把整张表作为一个大组,查询字段必须是聚合结果:如果有分组,分组之后,必须要使用聚合的结果作为having的条件. 聚合查询 聚合:aggregate ...
- day67 ORM模型之高阶用法整理,聚合,分组查询以及F和Q用法,附练习题整理
归纳总结的笔记: day67 ORM 特殊的语法 一个简单的语法 --翻译成--> SQL语句 语法: 1. 操作数据库表 创建表.删除表.修改表 2. 操作数据库行 增.删.改.查 怎么连数据 ...
- Django框架(六)--模板层:变量、过滤器、标签、自定义标签和过滤器
将页面的设计和Python的代码分离开会更干净简洁更容易维护. 我们可以使用 Django的 模板系统 (Template System)来实现这种模式 # django模板修改的视图函数 def c ...
- Django框架之第五篇(模板层) --变量、过滤器、标签、自定义标签、过滤器,模板的继承、模板的注入、静态文件
模板层 模板层就是html页面,Django系统中的(template) 一.视图层给模板传值的两种方法 方式一:通过键值对的形式传参,指名道姓的传参 n = 'xxx'f = 'yyy'return ...
- Django框架(七)—— 模板层:变量、过滤器、标签、自定义标签和过滤器
目录 模板层:变量.过滤器.标签.自定义标签和过滤器 一.模板层变量 1.语法 2.使用 二.模板层之过滤器 1.语法 2.常用过滤器 3.其他过滤器 三.模板值标签 1.for标签 2.if标签 3 ...
- django 组件 自定义过滤器 自定义标签 静态文件配置
组件 将一些功能标签写在一个html文件里,这个文件作为一个组件,如果那个文件需要就直接拿过来使用即可: 这是title.html文件,写了一个导航栏,作为一个公用的组件 <div style= ...
随机推荐
- reactjs中使用高德地图计算两个经纬度之间的距离
第一步下载依赖 npm install --save react-amap 第二步,在组件中使用 import React, { Component } from 'react' import { L ...
- docker安装配置gitlab详细过程
docker安装配置gitlab详细过程 获取镜像 1.方法一 1 docker pull beginor/gitlab-ce:11.0.1-ce.0 2.方法二如果服务器网路不好或者pull不下 ...
- sublime lincense for linux
sublime lincense for linux Sublime Text 3.x (after Build 3133) —– BEGIN LICENSE —–TwitterInc200 User ...
- Docker 基础 (一)
为什么要使用 Docker? 作为一种新兴的虚拟化方式,Docker 跟传统的虚拟化方式相比具有众多的优势.首先,Docker 容器的启动可以在秒级实现,这相比传统的虚拟机方式要快得多. 其次,Doc ...
- MTCNN试用
检测工作想借用MTCNN里的48-net,源码来自CongWeilin Git 下下来就能跑,真是良心 进入pepare_data准备好数据以后进入48-net,目录下有一个pythonLayer.p ...
- 【报错原因】Uncaught SyntaxError: Unexpected token <
实际上是当前页面引入的js文件路径找不到!!! 页面查找不到js文件自动跳转到404.html页面 域名+/404.html
- Vue基础进阶 之 实例方法--生命周期
在上一篇博客中我们知道生命周期的方法: 生命周期: vm.$mount:手动挂载Vue实例: vm.$destroy:销毁Vue实例,清理数据绑定,移除事件监听: vm.$nextTick:将方法中的 ...
- angular7 DOM操作 及 @ViewChild
一.Angular 中的 dom 操作(原生 js) 二.Angular 中的 dom 操作(ViewChild) 三.父子组件中通过 ViewChild 调用子组件 的方法 1.调用子组件给子组件定 ...
- mybatis插入数据并返回主键(oracle)
通常我们执行一个inser语句,即使有返回,也只是会返回影响了多少条数据 @insert("insert into t_user (id,name) values (suser.nextva ...
- python获取当前文件路径以及父文件路径
#当前文件的路径 pwd = os.getcwd() #当前文件的父路径 father_path=os.path.abspath(os.path.dirname(pwd)+os.path.sep+&q ...