洗礼灵魂,修炼python(62)--爬虫篇—模仿游戏
前言
《模仿游戏》这个电影相信如果你是搞IT的,即使没看过也听过吧?电影讲述了计算机之父——阿兰-图灵的一些在当时来讲算是计算机史里的里程碑事迹了。而【模仿游戏】这个名字咋一看,貌似和电影没啥关系,原名叫The Imitation Game,翻译过来就是模仿游戏,最开始其实是图灵的计算机相关测试,大概意思是如果计算机多次工作与人类似的工作,那么它可以智能的模仿人类的处理事务的方式来进行工作,在那个时代算是闻所未闻的,就像我现在跟正在读这篇博文的读者说“我其实很帅”一样,反正是没多少人信的对吧?好的,关于电影里的或者阿兰-图灵的话题,暂且不提,不深究这些,我只说字面意思上的模仿游戏
正题
前面学了那么多模块啊,什么方法属性,请求啥的,相信你不说精通,至少你可以爬一个网站了吧?
其实,我想说,爬虫真的不仅限于此,之前我提过,访问一个网站时,网站服务器可以看到客户端访问信息,以及以什么方式访问,如果是程序访问,原则是不行的,所以会被拒绝访问,因此需要修改参数来隐藏,我们已经学过的就是修改报文头部信息,模仿成浏览器式的访问,但这个还是有个问题,由于使用同一个IP多次访问,网站服务器不管user-agent是否是程序还是浏览器人为访问,都直接拒绝访问,或者显示验证页,让你输入验证码才行,网络爬虫自然是无法输入验证码的,输入验证码的相信你都知道吧,其实现在很多网站都有验证码才能过,这种就是简单防爬虫手段。
那么解决方法是什么呢?
有三个:
1.设置延迟,尽量的模仿人为访问的速度
2.设置代理IP
3.写高级爬虫程序过验证码(因为涉及更多扩展知识,这里暂且不提)
有了前两个方法,你写出来的爬虫程序就基本算是进阶级爬虫了,有了第三个方法,那么就是高级爬虫了。
本篇博文就说说前两个方法:
第一个方法就是导入time模块,然后在觉得该停顿的地方停顿对吧?time模块前面已经提过了,忘记了的,自己会去看吧。
具体怎么实行呢?好的,这里有一个小项目,写一个翻译程序,不管你用百度翻译,还是有道翻译,还是谷歌翻译,还是什么翻译,写一个简单的翻译程序出来,自己动手搞一个看看,前提是你必须稍微的会看一点点html代码,不然确实很吃力的,不需要会很多,只要能看懂个大概就行,不用去恶补html语法标签啥的
(请确保你已经思考过了,再看下面的。)
运行环境是python3
- import urllib.request
- import urllib.parse
- import json,time
- content=0
- head={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'}
- while True:
- content=input("请输入需要翻译的内容(或者输入quit退出):")
- if content!='quit':
- url="http://fanyi.baidu.com/v2transapi"
- data={}
- data['from']='zh'
- data['to']='en'
- data['query']=content
- data['transtype']='translang'
- data['
- data=urllib.parse.urlencode(data).encode("utf-8")
- req=urllib.request.Request(url,data,head)
- response=urllib.request.urlopen(req)
- html=response.read().decode("utf-8")
- target=json.loads(html)
- tgt=target['trans_result']['data'][0]['dst']
- print("翻译的结果是:%s"% tgt)
- time.sleep(3)
- else:
- break
结果测试:
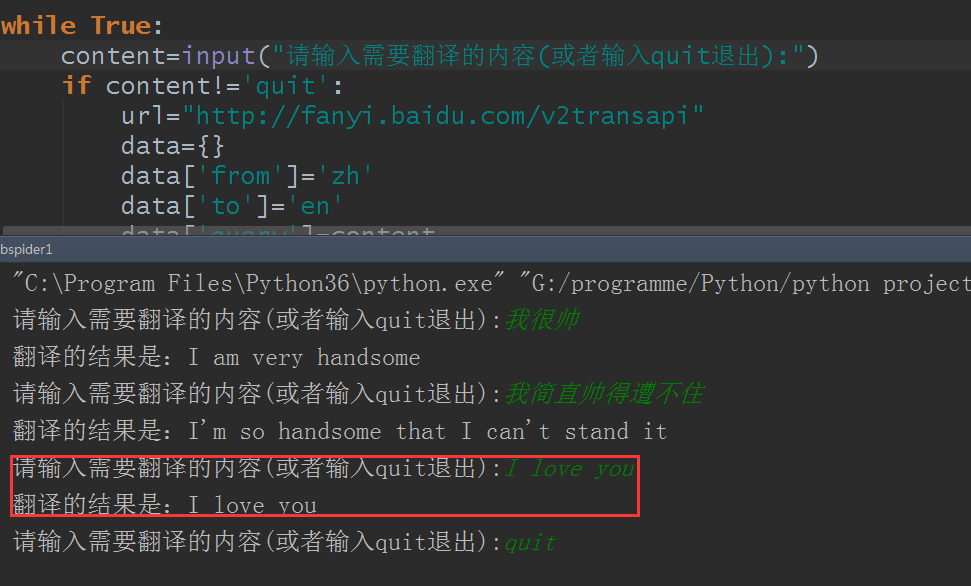
好的,完美翻译,不过这里还是有点小问题,比如只能中文翻译成英文,不能智能翻译,然后如果是用有道翻译或者其他什么翻译的又怎么写呢?好的,这些问题留为作业,自己去研究吧
好的,那么第二个方法,代理IP怎么搞呢?
代理ip得靠包模块urllib.requet创建代理对象urllib.request.ProxyHandler:
然后代理IP得有几个步骤:
- urllib.request.ProxyHandler()的参数是一个字典{‘类型’:‘代理ip:端口号’}:proxy = urllib.request.ProxyHandler({})
- 定制,创建一个opener:opener= urllib.request.build_opener(proxy_support)
- 安装opener:urllib.request.install_opener(opener)
- 调用opener:opener.open(url)
有了这几个步骤才能代理,在python3里就得这样,如果你要在python2里搞也可以的。
然后这里有个问题,代理IP怎么来呢?这里给个链接,西刺免费代理IP,如果你觉得不行,可以自行网上找了
例:
首先我选了一个代理ip:
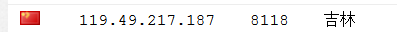
然后写好程序脚本,这里说下,本来没这么想的,但我还是把查询ip的网站用文字打码了,关于查询ip的网站网上很多,你们自己去测试吧,相关原因下面有提到
- import urllib.request
- proxy=urllib.request.ProxyHandler({'http':'119.49.217.187:8118'})
- opener=urllib.request.build_opener(proxy)
- urllib.request.install_opener(opener)
- head={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0'}
- res=urllib.request.Request('http://XXXXX.XXX',headers=head)
- result=urllib.request.urlopen(res).read().decode('utf-8')
- print(result)
结果:

代理成功了,完美
提一下,代码是绝对没问题的,因为我第一次测试都没问题,再次测试就成这样
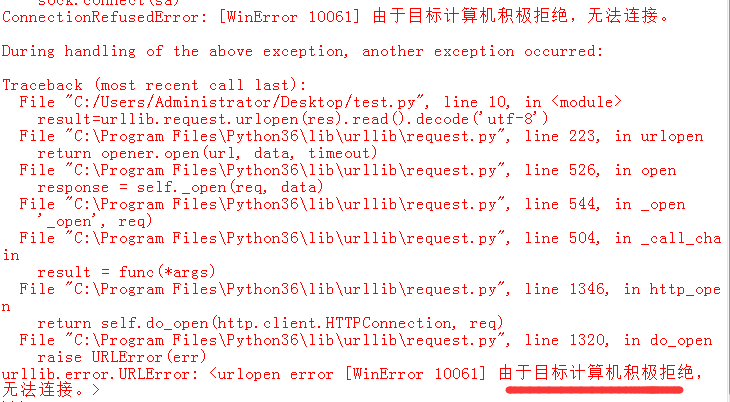
这不是别人网站小气,还是前面博文里说过的,私人网站,没那么抗压,所以都设置了防火墙,如果发现程序异常就拒绝访问,这很正常的,别人网站提供免费的查询,正常查询就好了,如果不设置防火墙,一会儿搞崩一次,一会儿搞崩一次,换成你你高兴不?对吧?
记得作业是改良翻译程序
免责声明
本博文只是为了分享技术和共同学习为目的,并不出于商业目的和用途,也不希望用于商业用途,特此声明。如果内容中测试的贵站的站长有异议,请联系我立即删除
洗礼灵魂,修炼python(62)--爬虫篇—模仿游戏的更多相关文章
- Python学习——爬虫篇
requests 使用requests进行爬取 下面是我编写的第一个爬虫的脚本 import requests # 导入reques ...
- Python学习—爬虫篇之破解ntml登陆问题
之前帮公司爬取过内部的一个问题单网站,要求将每个问题单的下的附件下载下来.一开始的时候我就遇到一个破解登陆验证的大坑...... (╬ ̄皿 ̄)=○ 由于在公司使用的都是内网,代码和网站的描述 ...
- 洗礼灵魂,修炼python(69)--爬虫篇—番外篇之feedparser模块
feedparser模块 1.简介 feedparser是一个Python的Feed解析库,可以处理RSS ,CDF,Atom .使用它我们可从任何 RSS 或 Atom 订阅源得到标题.链接和文章的 ...
- 洗礼灵魂,修炼python(72)--爬虫篇—爬虫框架:Scrapy
题外话: 前面学了那么多,相信你已经对python很了解了,对爬虫也很有见解了,然后本来的计划是这样的:(请忽略编号和日期,这个是不定数,我在更博会随时改的) 上面截图的是我的草稿 然后当我开始写博文 ...
- 洗礼灵魂,修炼python(71)--爬虫篇—【转载】xpath/lxml模块,爬虫精髓讲解
Xpath,lxml模块用法 转载的原因和前面的一样,我写的没别人写的好,所以我也不浪费时间了,直接转载这位崔庆才大佬的 原帖链接:传送门 以下为转载内容: --------------------- ...
- 洗礼灵魂,修炼python(70)--爬虫篇—补充知识:json模块
在前面的某一篇中,说完了pickle,但我相信好多朋友都不懂到底有什么用,那么到了爬虫篇,它就大有用处了,而和pickle很相似的就是JSON模块 JSON 1.简介 1)JSON(JavaScrip ...
- 洗礼灵魂,修炼python(63)--爬虫篇—re模块/正则表达式(1)
爬虫篇前面的某一章了,我们要爬取网站页面源代码的数据,要从中获取到我们想要的数据,是不是感觉很费力,确实费力对吧?那么有没有什么有利的工具来解决这个问题呢?那就是这一篇博文的主题—— 正则表达式简介 ...
- 洗礼灵魂,修炼python(50)--爬虫篇—基础认识
爬虫 1.什么是爬虫 爬虫就是昆虫一类的其中一个爬行物种,擅长爬行. 哈哈,开玩笑,在编程里,爬虫其实全名叫网络爬虫,网络爬虫,又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者 ...
- 洗礼灵魂,修炼python(85)-- 知识拾遗篇 —— 深度剖析让人幽怨的编码
编码 这篇博文的主题是,编码问题,老生常谈的问题了对吧?从我这一套的文章来看,前面已经提到好多次编码问题了,的确这个确实很重要,这可是难道了很多能人异士的,当你以为你学懂了,在研究爬虫时你发现你错了, ...
随机推荐
- 【xsy1300】 原题的旅行 最短路+倍增
题目大意:有一个$n$个点,$m$条边的无向图,玩家走过第$i$条边,血槽中的血会下降$v_i$点,如果不足$v_i$点,这人会当场去世. 这$n$个点中,有若干个是关键点,在这些关键点可以将血槽补满 ...
- js按钮 防重复提交
给html 按钮加id属性 例: <button id="addBtn" onclinck="check()"> </button&g ...
- Oracle 插入时间时 报错:ORA-01861: 文字与格式字符串不匹配 的解决办法
一.写sql的方式插入到Oracle中 往oracle中插入时间 '2007-12-28 10:07:24'如果直接按照字符串方式,或者,直接使用to_date('2007-12-28 10:07: ...
- Java的语法糖
1.前言 本文记录内容来自<深入理解Java虚拟机>的第十章早期(编译期)优化其中一节内容,其他的内容个人觉得暂时不需要过多关注,比如语法.词法分析,语义分析和字节码生成的过程等.主要关注 ...
- Spring Data JPA例子[基于Spring Boot、Mysql]
关于Spring Data Spring社区的一个顶级工程,主要用于简化数据(关系型&非关系型)访问,如果我们使用Spring Data来开发程序的话,那么可以省去很多低级别的数据访问操作,如 ...
- 从零开始学 Web 之 HTML5(四)拖拽接口,Web存储,自定义播放器
大家好,这里是「 从零开始学 Web 系列教程 」,并在下列地址同步更新...... github:https://github.com/Daotin/Web 微信公众号:Web前端之巅 博客园:ht ...
- 如何做自己的服务监控?spring boot 1.x服务监控揭秘
1.准备 下载可运行程序:http://www.mkyong.com/spring-boot/spring-boot-hello-world-example-jsp/ 2.添加服务监控依赖 <d ...
- .Net Core缓存组件(MemoryCache)源码解析
一.介绍 由于CPU从内存中读取数据的速度比从磁盘读取快几个数量级,并且存在内存中,减小了数据库访问的压力,所以缓存几乎每个项目都会用到.一般常用的有MemoryCache.Redis.MemoryC ...
- shell的编程结构体(函数、条件结构、循环结构)
bash&shell系列文章:http://www.cnblogs.com/f-ck-need-u/p/7048359.html 1.1 shell函数 在shell中,函数可以被当作命令一样 ...
- Form的enctype属性
Form的enctype属性 一般都使用html的Form表单通过HTTP POST方法发送Request body.下面是一个form: <form action="/process ...