ARM920T的Cache
转载自:http://www.eefocus.com/mcu-dsp/242034
ARM920T有16K的数据Cache和16K的指令Cache,这两个Cache是基本相同的,数据Cache多了一些写回内存的机制,后面我们以数据Cache为例来介绍Cache的基本原理。我们已经知道,Cache中的存储单位是Cache Line,ARM920T的一个Cache Line是32字节,因此16K的Cache由512条Cache Line组成。要了解Cache的基本原理,我们从如何设计Cache这个问题入手。
设计Cache的一种最朴素的想法是,把VA分成以32字节为单位,从任何一个对齐到32字节地址边界的VA开始连续的32个字节(比如0x00-0x1f,0x20-0x3f,0x40-0x5f等等)都可以缓存到512条Cache Line中的任何一条。那么一条Cache Line中的32个字节怎么知道是来自哪个VA的呢?这就需要把VA也保存在Cache中,由于这32字节的起始地址是对齐到32字节地址边界的,末5位全为0,因此只需要保存VA[31:5]即可,这称为VA Tag[4],Tag是VA的一部分,是Cache Line中数据的标识,表明这32字节数据来自哪个VA。这样设计的Cache称为全相联Cache(Fully Associative Cache),图示如下:
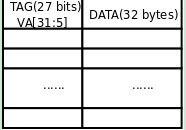
图 1. 全相联Cache
给定一个VA,如何在Cache中查找对应的数据呢?首先到Cache中比较查找哪一行的Tag等于VA[31:5],找到对应的Cache Line后,再根据VA[4:0]决定要访问的是该Cache Line缓存的32个字节中的哪一个字节。由于有512条Cache Line,如果这个VA没有缓存在Cache中则需要比较512次才知道,这是最坏的情况,也是最常见的情况,下面我们要改进Cache的设计来解决这个问题。
全相联Cache的特点是任何VA都可以缓存到任何一条Cache Line,给定一个VA做查找时,由于它有可能缓存在512条Cache Line中的任何一条,就只好全部都找一遍了。如果限定某一个VA只允许缓存在某一条Cache Line中,那么查找的过程就快多了:检查一下应该缓存这个VA的那条Cache Line,看Tag一致不一致,如果一致就是Cache Hit,如果不一致就是Cache Miss,可以直接访问物理内存而不必再找其它Cache Line了。这种设计称为直接映射Cache(Direct Mapped Cache),如下图所示:
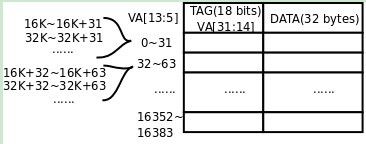
图 2. 直接映射Cache
地址0~31应该缓存在第1条Cache Line中,地址32~63应该缓存在第2条Cache Line中,依此类推,地址16352~16383应该缓存在第512条Cache Line中,下一个地址应该是16384(16K)了,我们又回到开头,地址16K~16K+31应该缓存在第1条Cache Line中,地址16K+32~16K+63应该缓存在第2条Cache Line中,依此类推,再次回到开头的地址应该是32K,32K~32K+31应该缓存在第1条Cache Line中,32K+32~32K+63应该缓存在第2条Cache Line中,依此类推。读者应该可以总结出规律了:给定一个VA,将它除以16K得的余数决定了它应该缓存在哪一条Cache Line中,那么除以16K的商数部分就应该是VA Tag,用以区别Cache Line中缓存的到底是0还是16K还是32K地址上的数据。那么除以16K的商数和余数怎么表示呢?VA[31:14]就是除以16K的商数,VA[13:0]就是余数,所以上图的Tag处标着VA[31:14]。余数VA[13:0]是16K Cache里的一个字节偏移量,而Cache是按32字节一个Cache Line组织的,所以余数中的高位VA[13:5]决定了是第几条Cache Line,余数中的低位VA[4:0]决定了Cache Line内的字节偏移量。验算一下,VA[13:5]一共是9位,作为Cache Line的编号可以表示的Cache Line数目正是512条。
直接映射Cache虽然查找速度很快,但也有缺点。比如,地址0~31、16K~16K+31、32K~32K+31都应该缓存到第1条Cache Line中,假如我们程序第一次访问地址30,地址0~31的数据就从内存加载到第1条Cache Line,以便下次访问能更快一些,但是我们程序第二次访问的却是地址32770,地址32K~32K+31的数据就要从内存加载到第1条Cache Line,把Cache Line里原来存的地址0~31的数据替换掉,以便下次访问能更快一些,但是我们程序第三次访问的却是地址16392……这样下去,Cache起不到任何加速作用,形同虚设,这种问题称为Cache抖动(Cache Thrash)。全相联Cache就不会有这种问题,因为任何VA都可以缓存到任何一条Cache Line,可以把先后几次访问的VA缓存到不同的Cache Line,就不会相互冲突。
全相联Cache和直接映射Cache各有优缺点,全相联Cache查找很慢,但没有抖动问题,直接映射Cache则正相反。为了得到更好的性能,实际CPU的Cache设计是取两者的折衷,把所有Cache Line分成若干个组,每一组有n条Cache Line,称为n路组相联Cache(n-way Set Associative Cache)。ARM920T采用64路组相联Cache,如下图所示:

图 3. 64路组相联Cache
有了前面两种Cache概念的基础,这种Cache应该很好理解,512条Cache Line分成8组,每组64条,地址0-31、256-587、512-543等等可以缓存到第1组64条Cache Line中的任何一条,地址32-63、288-319、544-575等等可以缓存到第2组64条Cache Line中的任何一条,依此类推。为什么说组相联Cache是全相联和直接映射Cache的一个折衷呢?如果把组分得很大,把全部Cache Line都分到一个组里面去,就变成了全相联Cache;如果把组分得很小,每组只有一个Cache Line,就变成了直接映射Cache。作为练习,请读者自己计算一下为什么VA Tag是VA[31:8],为什么组的编号用VA[7:5]表示。
那么,为什么组相联Cache的性能比直接映射Cache要好呢?一方面,组相联Cache把一条Cache Line上的冲突分散到了64条Cache Line上,起到了64倍的积极作用。而另一方面,应该缓存到同一个组的VA更多了:对于直接映射Cache,在同一个组(也就是同一条Cache Line)互相冲突的VA有4G/512个;对于组相联Cache,在同一个组(64条Cache Line)互相冲突的VA有4G/8个。从这个数量关系来看,组相联Cache又起到了64倍的消极作用。难道这两种作用不会完全抵销吗?我不打算从数学上严格证明,这不是本节的重点,读者可以通过一个生活常识的例子来理解:层数一样多的两栋楼,其中一栋楼是一部电梯,每层三户,而另一栋楼是两部电梯,每层六户,每户的平均人数一样多,你认为在哪个楼里等电梯的时间较短呢?
接下来解释一下有关Cache写回内存的问题。Cache写回内存有两种模式:
Write Back:Cache Line中的数据被CPU核修改时并不立刻写回内存,Cache Line和内存中的数据会暂时不一致,在Cache Line中有一个Dirty位标记这一情况。当一条Cache Line要被其它VA的数据替换时,如果不是Dirty的就直接替换掉,如果是Dirty的就先写回内存再替换。
Write Through:每当CPU核修改Cache Line中的数据时就立刻写回内存,Cache Line和内存中的数据总是一致的。如果有多个CPU或设备同时访问内存,例如采用双口RAM,那么Cache中的数据和内存保持一致就非常重要了,这时相关的内存页面通常配置为Write Through模式。
通过读写CP15的相关寄存器,可以对Cache做以下操作:
Clean:将Cache Line中的数据写回内存,清除Dirty位。在程序中的某些同步点上用于确保Cache Line和内存中的数据一致。
Invalidate:在Cache Line中有一个Invalid位表示无效,将这个位置1,下次要访问时即使VA Tag匹配也重新从内存读取数据。例如进程切换时需要声明前一个进程缓存在Cache中的数据无效。
Lock:将某个地址的数据锁定在Cache中,确保不被替换掉。在实时系统中,这样做可以保证某个地址的数据能在一个确定的时间内访问到。
从Cache中查找要访问的数据时用的是VA,但是Cache写回内存要用PA,如果写回内存时还需要查一遍页表就太没有效率了,所以实际上每条Cache Line中还保存了PA[31:5](PA Tag),完整的Cache构造如下图所示:
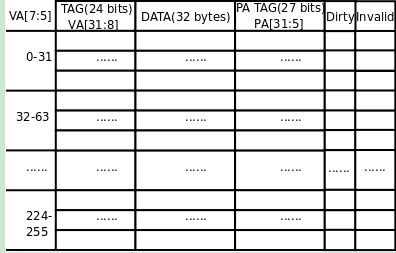
图 4. PA Tag
最后解决我们前面遗留的一个问题:页描述符中的C、B位具体是什么意思?
表 1. 页描述符中C、B位的含义
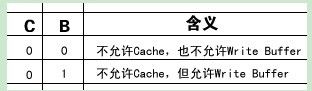
C位为1表示允许Cache,这种情况下用B位来表示Write Through还是Write Back。有些页面不允许Cache,置C位为0,这种情况下可以用B位来选择是否允许使用Write Buffer。Write Buffer也是一种简单的Cache,CPU核执行写指令时可以把数据交给Write Buffer,然后由Write Buffer负责写回内存,这时CPU可以执行后续指令而不必等待写回内存这个较慢的操作结束。想一下,既然有Write Buffer,为什么没有Read Buffer?
ARM920T的Cache的更多相关文章
- cache与SDRAM
hugohong hugohong 本版等级: #2 得分:20回复于: 2009-04-19 21:51:03 牛人说的,拿出来分享一下:cache是高速缓冲, 解决高速cpu和相对低速sdra ...
- TLB的作用及工作原理
TLB的作用及工作过程 以下内容摘自<步步惊芯——软核处理器内部设计分析>一书 页表一般都很大,并且存放在内存中,所以处理器引入MMU后,读取指令.数据需要访问两次内存:首先通过查询页表得 ...
- ARM MMU
关于MMU,以下几篇文章写得通俗易懂: s3c6410_MMU地址映射过程详述 追求卓越之--arm MMU详解 基于S3C6410的ARM11学习(十五) MMU来了 这里总结MMU三大作用: 1. ...
- s3c2440之cache
cache高速缓冲存储器注意与块设备页高速缓存进行区别,一个是硬件的实现一个是软件的实现,块设备页高速缓存. s3c2440/s3c2410里面主要有一个arm920t的核,但同时包含几个协处理器,协 ...
- u-boot之ARM920T的start.S分析
cpu/arm920t/start.S程序步骤大致有以下几个 1.设置中断向量表 2.设置CPU模式为SVC32 mode并且关闭IRQ与FIQ中断 3.关闭看门狗 4.屏蔽所有中断 5.判断程序是否 ...
- 虚拟内存,MMU/TLB,PAGE,Cache之间关系
转:http://hi.baidu.com/gilbertjuly/item/6690ba0dfdf57adfdde5b040 虚拟地址VA到物理地址PA以页page为单位.通常page的大小为4K. ...
- ASP.NET Core 折腾笔记二:自己写个完整的Cache缓存类来支持.NET Core
背景: 1:.NET Core 已经没System.Web,也木有了HttpRuntime.Cache,因此,该空间下Cache也木有了. 2:.NET Core 有新的Memory Cache提供, ...
- [Java 缓存] Java Cache之 DCache的简单应用.
前言 上次总结了下本地缓存Guava Cache的简单应用, 这次来继续说下项目中使用的DCache的简单使用. 这里分为几部分进行总结, 1)DCache介绍; 2)DCache配置及使用; 3)使 ...
- Spring cache简单使用guava cache
Spring cache简单使用 前言 spring有一套和各种缓存的集成方式.类似于sl4j,你可以选择log框架实现,也一样可以实现缓存实现,比如ehcache,guava cache. [TOC ...
随机推荐
- 【转】Ubuntu英文系统下安装中文输入法
转自:https://my.oschina.net/No5stranger/blog/290026 ubuntu默认的输入法是ibus,综合网上评论,fcitx的支持者更多,而且个人感觉fcitx也的 ...
- Java删除文件夹和其子文件、文件的拷贝和剪切
1.递归删除目录下的所有文件及子目录下所有文件 //递归删除目录下的所有文件及子目录下所有文件 public static boolean deleteDir(File dir) { if (dir ...
- css图形——三角形
1.css图形简介 在浏览网页的时候,我们经常看见各种图形的效果,而但凡涉及到图形效果,我们第一个想到的就是用图片来实现.但是在前端开发中,为了网站的性能速度,我们都是秉承着少用图片的原生质. 因为图 ...
- 1. qt 入门-整体框架
总结: 本文先通过一个例子介绍了Qt项目的大致组成,即其一个简单的项目框架,如何定义窗口类,绑定信号和槽,然后初始化窗口界面,显示窗口界面,以及将程序的控制权交给Qt库. 然后主要对Qt中的信号与槽机 ...
- CentOS7 linux下yum安装redis以及使用
1.安装redis数据库 yum install redis 2.下载fedora的epel仓库 yum install epel-release 3.启动redis服务 systemctl star ...
- ganglia监控架构
1.我们知道ganglia是C/S结构的,我们熟知的就是一台ganglia server,很多slave.这种结构有什么问题? 1)如果ganglia server出现问题,我们就无法监控到datan ...
- 如何ASP.NET Core Razor中处理Ajax请求[转载]
在ASP.NET Core Razor(以下简称Razor)刚出来的时候,看了一下官方的文档,一直没怎么用过. 今天闲来无事,准备用Rozor做个项目熟练下,结果写第一个页面就卡住了..折腾半天才搞好 ...
- JavaScript之作用域
1. 作用域 变量能够起作用的范围,作用域分为全局作用域和局部作用域 全局作用域: 1. 最外层函数或者在最外层函数外通过var定义的变量: 2. window对象的属性和方法具有全局作用域: 3. ...
- huffman(greedy)
present a file by binary character code,let the less characters can be presented simplier. package g ...
- leetcode题解 1.TwoSum
1. Two Sum Given an array of integers, return indices of the two numbers such that they add up to a ...