自制操作系统Antz(4)——进入保护模式 (下) 实现内核并从硬盘载入
Antz系统更新地址: https://www.cnblogs.com/LexMoon/category/1262287.html
Linux内核源码分析地址:https://www.cnblogs.com/LexMoon/category/1267413.html
目前已经完成了MBR的雏形,并且直接操作显卡完成了屏幕的内容显示。接下来我们要改造之前的MBR,做一个大的改进,使MBR可以读取硬盘,因为我们的MBR受限制于512字节大小,在这么小的空间里没法为内核准备好环境,更不要说加载内核到内存中并运行了,所以我们需要在另一个程序中完成初始化环境与加载内核的任务,这个程序我们叫做loader。loader这个程序放在哪里呢?如何去执行呢?这就是这次MBR改进的任务了,我们需要从硬盘上去把loader加载到内存中,并把执行权的接力棒交给它。
在第一天讲过了,MBR是在硬盘的第0扇区,第一扇区是空闲的,但是离的太近总是感觉不安全,所以我们将loader放到第二扇区。MBR从第二扇区中把它都出来,然后放到哪里呢?
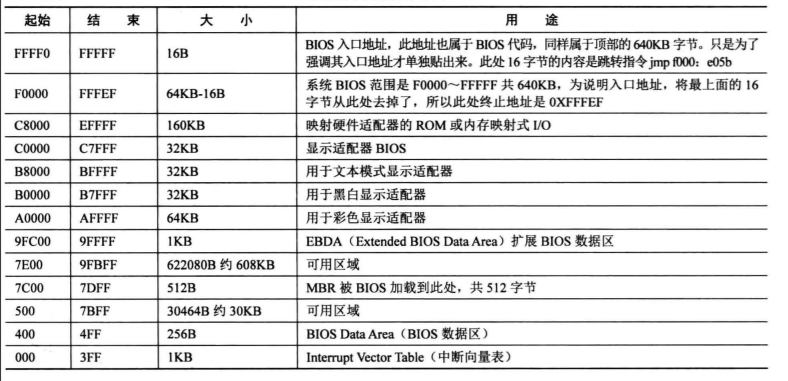
原则上空闲位置都是可以的。图中7E00~9FBFF和500~7BFF这两段可用区域都可以。随着功能的添加,内核必然会越来越大,所以我们尽量把loader放在低处,所以我选择为了0x500处。
说完了本次的基本任务和流程,接下来就是关键的问题了,如何操作硬盘?
0. 关于硬盘
关于硬盘的种类历史此处不做介绍。
如有兴趣可参考:硬盘
我们先来讲讲它的工作原理,如图是机械硬盘的示意图。
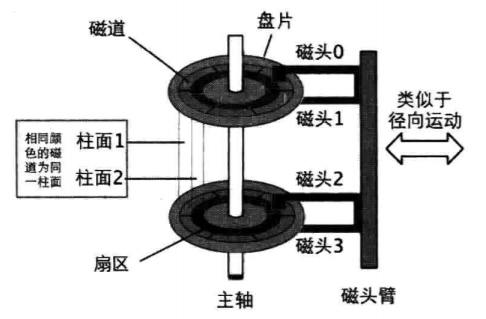
主轴上面有两个盘片,其实不止两个,这里只是示意性画了两个。盘片固定在主轴上随主轴高速转动,每个盘片分为上下两面,每个面都存储有数据,每个盘面都各有一个磁头来读取数据,故一个盘片对应两个磁头(注意盘片和盘面,不要看混)。由于盘面和磁头是一一对应的关系,故用磁头号来标识盘面号,磁头0对应盘面0,磁头1对应盘面1,从0开始计数,盘面0就是第一个盘面。磁头不会自己在盘片上移动,它需要被固定在磁头臂上,在磁头臂的带动下,沿着盘片的边缘向圆心的方向来回摆动,注意摆动的轨迹是个弧,并不是绝对径向地直来直去。一方面是因为磁头臂是步进电机驱动的,磁头臂一段时步进电机主轴,另一端的磁头,电机每次都会转动一个角度,所以带动磁头臂在“画圆”,而磁头位于磁头臂的另一端,所以也跟着呈钟摆运动,轨迹时弧线,并不是直线。另一方面,磁头读取数据也不需要做直来直去的运动,能否找到数据,只跟它最终落点有关,和中间路径形状无关,所以一方面盘面自转,另一方面磁头摆动,使得磁头可以盘面任意位置的数据。
说完了运动,在说存储逻辑,盘片表面时用于存储数据的磁性介质,为了更有效的管理磁盘,这些磁性介质也被“格式化”成易于管理的格局,即将盘面划分成了多个同心环,以同心环画扇形,扇形与每个同心环相交的弧状区域作为最基本的数据存储单元。这个同心环就称为磁道,而同心环上弧状的扇形部分就称为扇区,它作为我们硬盘存储数据的最基本单位,大小是512字节。我们写入数据最终是写入了扇形的扇区中。注意,磁道是一个环,不是线,线上可无法存储数据。磁头臂带动磁头在盘片上方移动,就是在找磁道的位置,盘片高速自转,就是在磁道内定位扇区。
磁道的编号和磁头的编号也是从0开始,相同编号的磁道组成的管状区域就称为柱面。柱面有什么用呢? 机械硬盘大的寻道时间是整个硬盘的瓶颈,为了减少寻道时间,就尽量在存储上下功夫。寻道,简而言之就是在磁头在磁道间跳转,跳转所需要的时间就是寻道时间。柱面就可以减少寻道的时间。至于原理,可以这样理解,当我们要存储的数据少于一个磁道的存储量时,我们可以直接存储在一个磁道里面,而不需要跳转到其他磁道(不需要寻道)。当要存储量大于一个磁道时,需要多次寻道,而寻道会浪费大量时间,如果我们使用柱面,存满一个磁道后,将剩下的数据存储在其他盘面的相同磁道号处,就可以避免寻道了,反过来,读取数据也是这样,以此,盘面越多,硬盘越快。
扇区的编号与磁道磁头不同,它是从1开始编号的,而且一个扇区只对当前磁道有效,所以各个磁道间的扇区编号都相同,至于一个磁道中的扇区数量多少与厂商有关,一般都是63个扇区。磁头如何找到所需的扇区呢? 每个扇区其实都是有自己的头部的,头部之后才是512字节的存储区,头部包含了扇区自身的信息,哪些信息可以唯一定位一个扇区呢? 当然是磁头号,磁道号和扇区号了。
1. 控制硬盘之前
之前在直接操作显存中说过,CPU不会直接与这些设备联系,而是与IO接口通信,再由IO接口向下传达信息,CPU与硬盘的联系就是通过硬盘控制器。
硬盘控制器与硬盘的关系就好像显卡与显示器。关于硬盘的接口,你可能听说过PATA和SATA,ATA是一种全球化的标准,PATA是并行ATA,SATA是后来的串行ATA。以前的主机一般至支持4个并行PATA,在串行SATA出现之后,支持几块硬盘完全取决于主板能力。
两种类型线缆完全不一样,PATA接口的线缆也称为IDE线,一个IDE线上可以挂两块硬盘,一个是主盘,一个是从盘。主盘从盘分工很明显,很多工作都要靠主盘来进行,比如系统就要装在主盘上。随着时代发展,兼容性的提升,主盘从盘已经没有了区别。之前说一个主板支持四块PATA硬盘,那么就是两个IDE线接口。这两个接口也是以0开始编号的,分别是IDE0,IDE1。不过按照ATA的说法,这两个插槽接口叫做通道,IDE0就是Primary通道,IDE1就是Secondary通道。SATA硬盘也是兼容PATA的编程接口。(这里不要把主盘从盘和通道弄混了)。
硬盘是一个很复杂的结构,我们暂时只需要知道一部分端口就可以了。
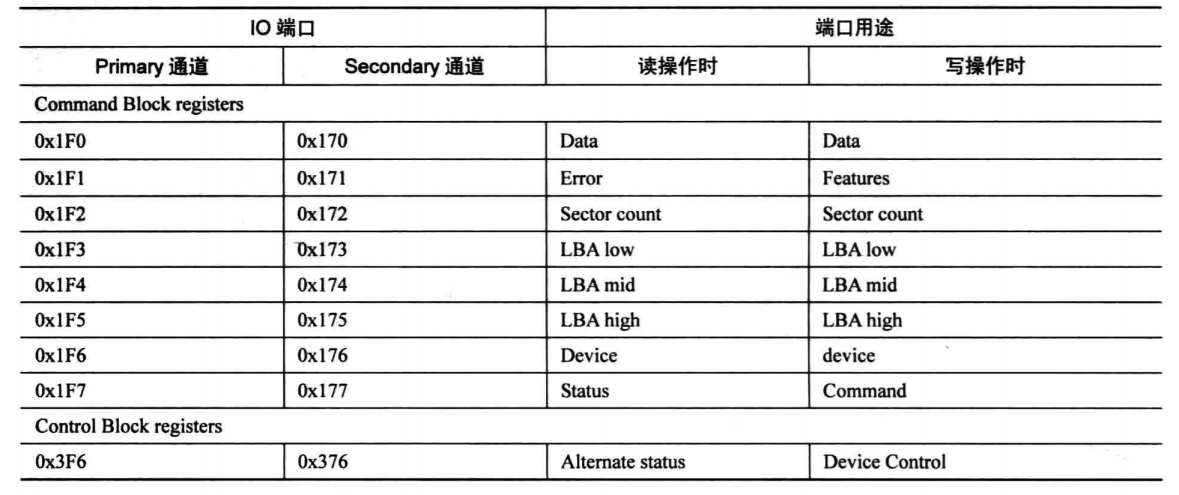
端口可以分为两组,Command Block registers和Control Block registers。 Command Block registers用于向硬盘启动器写入命令字或者从硬盘控制器获取硬盘状态,Control Block registers用于控制硬盘工作状态。
端口是按照通道给出的,所以不要认为端口是直接针对某块硬盘的,一个通道的主从硬盘都是使用这些端口号的,要想操作某通道上的某块硬盘,需要单独指定。看上面的表格,有一个叫做Device的寄存器,这就是驱动器设备,也就是和硬盘相关的。不过此寄存器是八位的,一个通道上就两块硬盘,指定哪块硬盘只用一位就可以了,至于其他位当然也有用处,很多设置都会集中在此寄存器,其中的第四位便是指定通道上的主或从硬盘,0是主盘,1是从盘。端口用途在读写时是有区别的,比如Primary通道上的0x1F1端口来说,读操作时,如果读取失败,里面存储的是失败状态信息,所以称为error寄存器,并且此时会在0x1F2端口中存储未读的扇区数。写操作时就变成Features寄存器,此寄存器用于写命令参数。至于为什么要把一个寄存器分为两种状态,可能时在早期多加寄存器有很大代价吧。
接下来介绍一下表中各个寄存器的功能。
data寄存器顾名思义就是管理数据的,数据的读写当然是越快越好,所以data寄存器比其他寄存器宽一些,16位。在读硬盘时,硬盘准备好数据后,硬盘控制器将其放在内部的缓存区中,不断读此寄存器便是读出缓存器中的全部数据。在写硬盘时,我们要把数据不断写入此寄存器中,然后数据便会被送入缓存区,硬盘控制器发现这个缓存区中有数据了,便将此处数据写入相应扇区中。
读硬盘时0x171或0x1F1的寄存器叫做Error寄存器,只在读取失败时才有用,里面有记录失败的信息,尚未读取的扇区数在Sector count寄存器中。在写硬盘时,该寄存器叫做Feature寄存器,里面是一些命令需要指定的额外参数。Error和Feature是同一个寄存器,只是在不同情况有不同的名称,它是八位寄存器。
Sector count寄存器用来指定带读取或者带写入的扇区数。硬盘每完成一个扇区,此寄存器中的值就会减一,这是一个八位寄存器,最大值为255,若指定为0,则表示需要操作256个扇区。
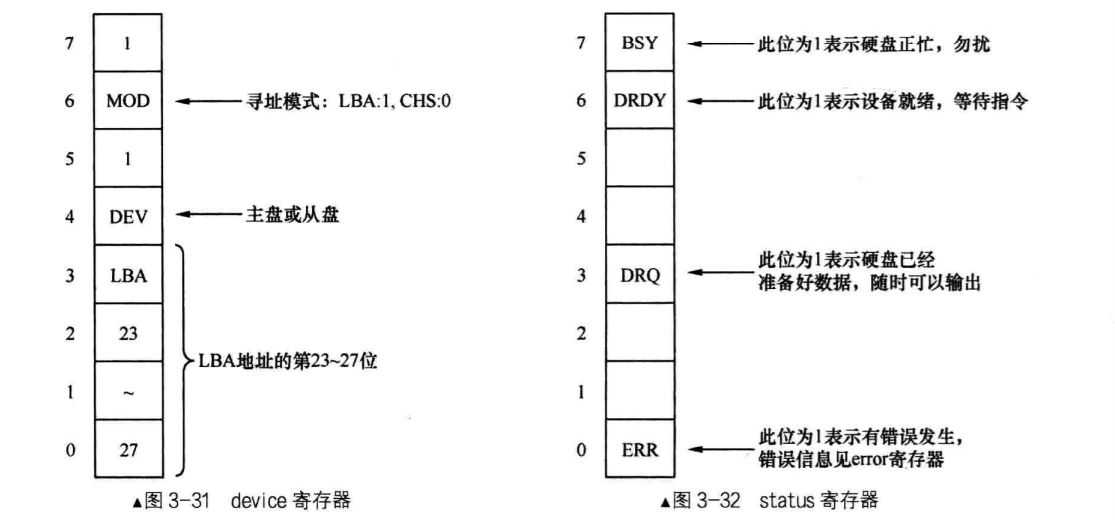
LBA寄存器有LBA low,LBA mid,LBA high三个,它们三个都是8位,LBA low寄存器用来存储28位地址的第0~7位,LBA mid用来存储28位的第8~15位,LBA high寄存器用来存储28位的第16~23位。那么剩下的四位呢? 这就是device寄存器的任务了。
device寄存器是个杂项,它的宽度是八位,第四位是存储LBA的第24位~27位。结合上面的三个LBA寄存器,第四位用来指定通道上的主盘或从盘,0代表从,1代表主。第六位用来存储是否启用LBA方式,1代表LBA模式,0代表CHS模式。另外两位第五位和第七位是固定为1的,称为MBS位,可以不用注意。
读硬盘时,端口0x1F7或0x177的寄存器叫Status,它是8位宽度的寄存器,用来给出硬盘的状态信息。第0位是ERR位,如果此位为1,表示命令出错了,具体原因可见Error寄存器。第三位data request位,如果此位为1,表示数据已经准备好了。第6位为DRDY,表示硬盘就绪。第七位是BSY位,表示硬盘是否繁忙。
写硬盘时,端口0x1F7或0x177的寄存器叫Command,它和Status是同一个,此寄存器用来存储让硬盘执行的命令,把命令写入此寄存器,只要把命令写入此寄存器,硬盘就开始工作了。主要是以下三个命令:
1)identify : 0xEC 硬盘识别
2)read sector : 0x20 即读扇区
3) write sector : 0x30 即写扇区
2. 控制硬盘步骤
有的指令直接往command寄存器中写就可以了,有的还需要feature寄存器中写入参数。最主要的就是command寄存器一定要最后写,因为一旦command寄存器被写入后,硬盘就开始干活了。关于操作步骤如下:
1)先选择通道,往该通道的sector count寄存器中写入带操作的扇区数。
2)往该通道上的三个LBA寄存器写入扇区起始地址的低24位。
3)往device寄存器中写入LBA地址的24~27位,并置第六位为1,使其为LBA模式,设置第4位,选择操作的硬盘(主从)。
4)往该通道上的额command寄存器中写入操作命令。
5)读取该通道上的status寄存器,判断硬盘工作是否完成
6)如果以上步骤是读硬盘,进入下一个步骤。否则,完工
7)将硬盘数据读出
3. 使用硬盘
MBR即将改造成可以读取硬盘,那么我们的内核加载就有了方法。所以我们要学会从另一个程序中完成初始化环境并加载内核,这个程序叫做loader,loader放在第二个扇区,地址之前已经讲过了0x500~0x7BFF区域中。
%include "boot.inc"
SECTION MBR vstart=0x7c00
mov ax,cs
mov ds,ax
mov es,ax
mov ss,ax
mov fs,ax
mov sp,0x7c00
mov ax,0xb800
mov gs,ax mov ax,0x600
mov bx,0x700
mov cx,
mov dx,0x1010
int 0x10 mov byte [gs:0x00],'A'
mov byte [gs:0x01],0xA4 mov byte [gs:0x02],'n'
mov byte [gs:0x03],0x13 mov byte [gs:0x04],'t'
mov byte [gs:0x05],0x52 mov byte [gs:0x06],'z'
mov byte [gs:0x07],0xB1 mov byte [gs:0x08],' '
mov byte [gs:0x09],0xCC mov byte [gs:0x0A],'U'
mov byte [gs:0x0B],0x2B mov byte [gs:0x0C],'h'
mov byte [gs:0x0D],0x6D mov byte [gs:0x0E],'l'
mov byte [gs:0x0F],0x7E mov byte [gs:0x10],' '
mov byte [gs:0x11],0x49 mov byte [gs:0x12],'K'
mov byte [gs:0x13],0xE5 mov byte [gs:0x14],'o'
mov byte [gs:0x15],0x8A mov byte [gs:0x16],'n'
mov byte [gs:0x17],0x96 mov byte [gs:0x18],'e'
mov byte [gs:0x19],0x68 mov eax,LOADER_START_SECTOR
mov bx,LOADER_BASE_ADDR
mov cx,
call rd_disk_m_16 jmp LOADER_BASE_ADDR rd_disk_m_16: mov esi,eax
mov di,cx
mov dx,0x1f2
mov al,cl
out dx,al mov eax,esi mov dx,0x1f3
out dx,al mov cl,
shr eax,cl
mov dx,0x1f4
out dx,al shr eax,cl
mov dx,0x1f5
out dx,al shr eax,cl
and al,0x0f
or al,0xe0
mov dx,0x1f6
out dx,al mov dx,0x1f7
mov al,0x20
out dx,al not_ready:
nop
in al,dx
and al,0x88 cmp al,0x08
jnz not_ready mov ax,di
mov dx,
mul dx
mov cx,ax mov dx,0x1f0 go_on_read:
in ax,dx
mov [bx],ax
add bx,
loop go_on_read
ret times -($-$$) db
db 0x55,0xaa
boot.inc文件内容如下:
;------------- loader和kernel ----------
LOADER_BASE_ADDR equ 0x900
LOADER_START_SECTOR equ 0x2
LOADER_BASE_ADDR就是loader在内存中的位置,LOADER_START_SECTOR说明了loader放在了第二个扇区。
内核加载器如下:
%include "boot.inc"
section loader vstart=LOADER_BASE_ADDR ; 输出背景色绿色,前景色红色,并且跳动的字符串"1 MBR"
mov byte [gs:0x00],''
mov byte [gs:0x01],0xA4 ; A表示绿色背景闪烁,4表示前景色为红色 mov byte [gs:0x02],' '
mov byte [gs:0x03],0xA4 mov byte [gs:0x04],'L'
mov byte [gs:0x05],0xA4 mov byte [gs:0x06],'O'
mov byte [gs:0x07],0xA4 mov byte [gs:0x08],'A'
mov byte [gs:0x09],0xA4 mov byte [gs:0x0a],'D'
mov byte [gs:0x0b],0xA4 mov byte [gs:0x0c],'E'
mov byte [gs:0x0d],0xA4 mov byte [gs:0x0e],'R'
mov byte [gs:0x0f],0xA4 jmp $ ; 通过死循环使程序悬停在此
使用dd命令将之前生成的bin写入第0个扇区,loader生成的bin写入第2个扇区(个人爱好,也可以是第一个,但boot.inc也要改变)。
自制操作系统Antz(4)——进入保护模式 (下) 实现内核并从硬盘载入的更多相关文章
- 自制操作系统Antz(2)——进入保护模式 (上) jmp到保护模式
Antz系统更新地址: https://www.cnblogs.com/LexMoon/category/1262287.htm Linux内核源码分析地址:https://www.cnblogs.c ...
- 自制操作系统Antz(3)——进入保护模式 (中) 直接操作显存
Antz系统更新地址: https://www.cnblogs.com/LexMoon/category/1262287.html Linux内核源码分析地址:https://www.cnblogs. ...
- 自制操作系统Antz -- 系列文章
自制操作系统Antz day10——实现shell(上) AntzUhl 2018-10-10 16:25 阅读:192 评论:0 Linux内核源码分析 day01——内存寻址 AntzUhl ...
- 自制操作系统Antz(5)——深入理解保护模式与进入方法
Antz系统更新地址: https://www.cnblogs.com/LexMoon/category/1262287.html Linux内核源码分析地址:https://www.cnblogs. ...
- ActiveX IE保护模式下的低权限操作路径及Windows操作系统特殊路径
参考理解IE保护模式:https://blog.csdn.net/xt_xiaotian/article/details/5336809 文件帮助类: public class FileHelp { ...
- ASM:《X86汇编语言-从实模式到保护模式》第17章:保护模式下中断和异常的处理与抢占式多任务
★PART1:中断和异常概述 1. 中断(Interrupt) 中断包括硬件中断和软中断.硬件中断是由外围设备发出的中断信号引发的,以请求处理器提供服务.当I/O接口发出中断请求的时候,会被像8259 ...
- 软件调试——IA-32 保护模式下寄存器一览
最近在看张银奎先生的<调试软件>一书,想将关键的技术记录下来,以便日后查阅,也分享给想看之人吧. 1 通用寄存器 EAX,EBX,ECX,EDX:用于运算的通用寄存器,可以使用AX,BX等 ...
- ASM:《X86汇编语言-从实模式到保护模式》第14章:保护模式下的特权保护和任务概述
★PART1:32位保护模式下任务的隔离和特权级保护 这一章是全书的重点之一,这一张必须要理解特权级(包括CPL,RPL和DPL的含义)是什么,调用门的使用,还有LDT和TSS的工作原理(15章着重 ...
- ASM:《X86汇编语言-从实模式到保护模式》第13章:保护模式下内核的加载,程序的动态加载和执行
★PART1:32位保护模式下内核简易模型 1. 内核的结构,功能和加载 每个内核的主引导程序都会有所不同,因为内核都会有不同的结构.有时候主引导程序的一些段和内核段是可以共用的(事实上加载完内核以后 ...
随机推荐
- 茶馆小人书 (AFO)
茶馆小人书 ——AFO 乌云重重地压住了整个天际,阴风凛冽袭人,随着远方穹顶上的几声闷响,豆大的雨点便开始清洗这座城市.北方的雨,就是这么突然.任性,恰似北方人的性情,豪放不羁,一旦开始便不可收拾 ...
- B - Assignment
Tom owns a company and he is the boss. There are n staffs which are numbered from 1 to n in this com ...
- 把项目挂载到composer上
1.打开composer的安装包列表网站,点击submit 2.把刚才初始化了composer的项目push到github上(至于怎么push,最简单就是用git了) 3.然后把github的网址复制 ...
- 萌新 学习 vuex
vuex官网文档 https://vuex.vuejs.org/zh-cn/ 注: Mutation事件使用commit触发, Actions事件使用dispatch触发 安装 npm install ...
- vue文件中引入外部js
1.在项目的入口文件中(app.js)定义remoteScript标签 Vue.component('remote-script', { render: function (createElement ...
- NYOJ - 矩形嵌套(经典dp)
矩形嵌套时间限制:3000 ms | 内存限制:65535 KB 描述 有n个矩形,每个矩形可以用a,b来描述,表示长和宽.矩形X(a,b)可以嵌套在矩形Y(c,d)中当且仅当a<c,b< ...
- git 回滚指定行
Stage the parts you want with git add -p, then discard (git checkout -- filename) the unstaged chang ...
- position inherit 定位
inherit 继承父元素 定位 举例 : <div class="father"> <p></p> </div> div{ ...
- 调用微信定位功能 lat _ lng php方法
{:wx_jssdk_config("false")} //最主要的这一句 没有这一句在微信浏览器里是无法调用的定位功能的.下面有这个方法说明 <script> wx. ...
- 2018-2019-2 20165330《网络对抗技术》Exp5 MSF基础应用
目录 基础问题 相关知识 实验目的 实验内容 实验步骤 离实战还缺些什么技术或步骤? 实验总结与体会 实验目的 本实践目标是掌握metasploit的基本应用方式,重点常用的三种攻击方式的思路 返回目 ...