【Spark-core学习之七】 Spark广播变量、累加器
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk1.8
scala-2.10.4(依赖jdk1.8)
spark-1.6
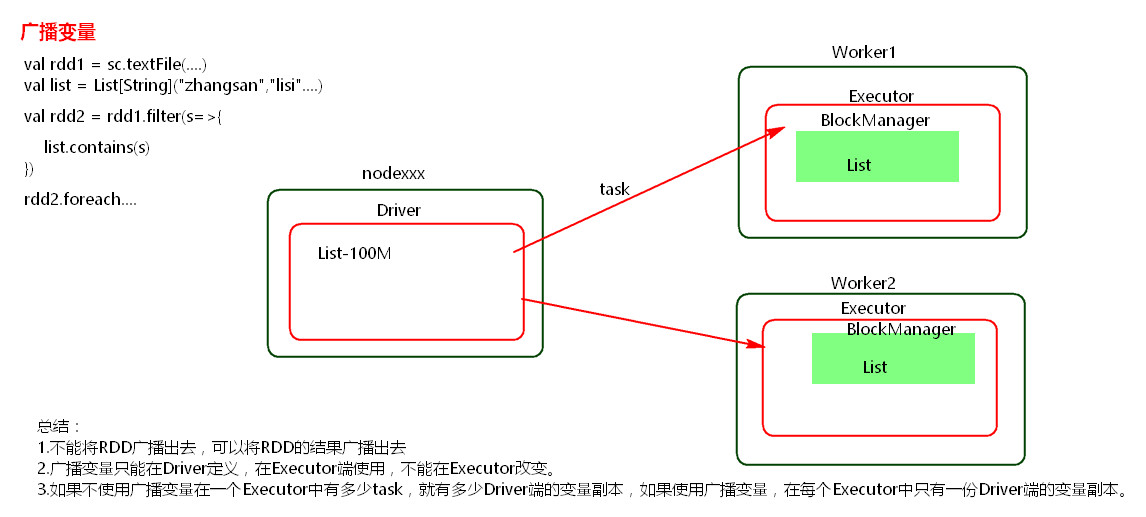
一、广播变量
package com.wjy import org.apache.spark.SparkConf
import org.apache.spark.SparkContext object GuboVal {
def main(args: Array[String]): Unit = {
val conf = new SparkConf();
conf.setMaster("local").setAppName("broadcast");
val sc= new SparkContext(conf); val list = List("hello wjy");
val broadcast = sc.broadcast(list);//定义一个广播变量 val linesRDD = sc.textFile("./data/words.txt");
//广播变量可以在excutor使用
linesRDD.filter{x=>broadcast.value.contains(x)}.foreach(println); sc.stop();
}
}
注意:
(1) 能不能将一个RDD使用广播变量广播出去?
不能,因为RDD是不存储数据的。可以将RDD的结果广播出去。
(2)广播变量只能在Driver端定义,不能在Executor端定义。
(3) 在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
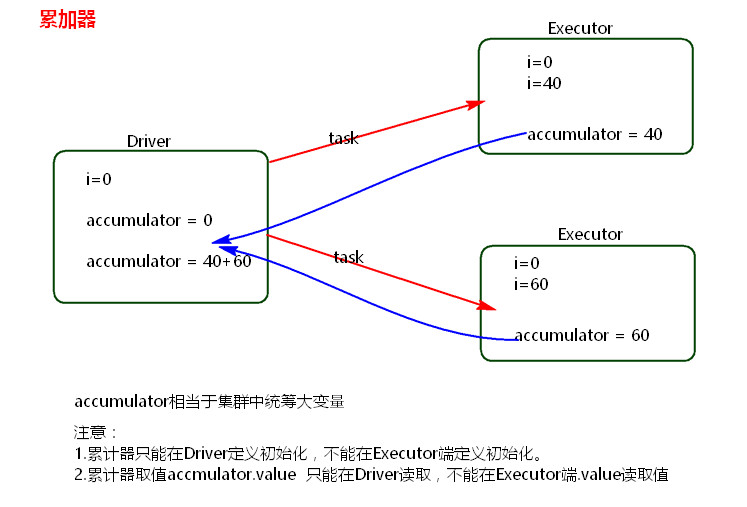
二、累加器
package com.wjy import org.apache.spark.SparkConf
import org.apache.spark.SparkContext object accumulator {
def main(args: Array[String]): Unit = {
val conf =new SparkConf();
conf.setMaster("local").setAppName("accumulator");
val sc = new SparkContext(conf);
//创建累加器 累加器可以是整形 也可以是其他自定义对象
val accumulator = sc.accumulator(0);
//累加器在excutor里累加
sc.textFile("./data/words.txt").foreach(x=>{accumulator.add(1)});
println(accumulator.value); sc.stop();
}
}
注意:
累加器在Driver端定义赋初始值,累加器只能在Driver端读取,在Excutor端更新。
参考:
Spark
【Spark-core学习之七】 Spark广播变量、累加器的更多相关文章
- spark SQL学习(spark连接 mysql)
spark连接mysql(打jar包方式) package wujiadong_sparkSQL import java.util.Properties import org.apache.spark ...
- 【Spark调优】Broadcast广播变量
[业务场景] 在Spark的统计开发过程中,肯定会遇到类似小维表join大业务表的场景,或者需要在算子函数中使用外部变量的场景(尤其是大变量,比如100M以上的大集合),那么此时应该使用Spark的广 ...
- 【spark core学习---算子总结(java版本) (第1部分)】
map算子 flatMap算子 mapParitions算子 filter算子 mapParttionsWithIndex算子 sample算子 distinct算子 groupByKey算子 red ...
- Spark Core源代码分析: Spark任务运行模型
DAGScheduler 面向stage的调度层,为job生成以stage组成的DAG,提交TaskSet给TaskScheduler运行. 每个Stage内,都是独立的tasks,他们共同运行同一个 ...
- Spark Core源代码分析: Spark任务模型
概述 一个Spark的Job分为多个stage,最后一个stage会包含一个或多个ResultTask,前面的stages会包含一个或多个ShuffleMapTasks. ResultTask运行并将 ...
- spark SQL学习(spark连接hive)
spark 读取hive中的数据 scala> import org.apache.spark.sql.hive.HiveContext import org.apache.spark.sql. ...
- Spark RDD持久化、广播变量和累加器
Spark RDD持久化 RDD持久化工作原理 Spark非常重要的一个功能特性就是可以将RDD持久化在内存中.当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内 ...
- Spark共享变量(广播变量、累加器)
转载自:https://blog.csdn.net/Android_xue/article/details/79780463 Spark两种共享变量:广播变量(broadcast variable)与 ...
- spark累加器、广播变量
一言以蔽之: 累加器就是只写变量 通常就是做事件统计用的 因为rdd是在不同的excutor去执行的 你在不同excutor中累加的结果 没办法汇总到一起 这个时候就需要累加器来帮忙完成 广播变量是只 ...
- Spark 3.x Spark Core详解 & 性能优化
Spark Core 1. 概述 Spark 是一种基于内存的快速.通用.可扩展的大数据分析计算引擎 1.1 Hadoop vs Spark 上面流程对应Hadoop的处理流程,下面对应着Spark的 ...
随机推荐
- Ubuntu下安装antlr-4.7.1
简介:antlr工具将语法文件转换成可以识别该语法文件所描述的语言的程序. 例如:给定一个识别json的语法,antlr工具将会根据该语法生成一个程序,该程序可以通过antlr运行库来识别输入的jso ...
- windows 安装python pip Could not install packages due to anEnvironmentError: [WinError 5] 拒绝访问
找打 C:\Windows\System32 文件夹下面的cmd.exe点开后运行python -m pip install --upgrade pip 即解决问题了.
- mysql存储过程异常处理
DELIMITER $$ USE `mtnoh_aaa_platform`$$ DROP PROCEDURE IF EXISTS `proc_eoms_electric_power_generatio ...
- C# StackExchange.Redis 用法总结
安装 StackExchange.Redis 在 NuGet 中搜索 StackExchange.Redis 和 Newtonsoft.Json,直接点击按钮安装即可. StackExchange.R ...
- linux Ubuntu系统安装百度aip
1.下载百度api pip install baidu-aip 2.配置视频转码工具ffmpeg Ubuntu16.04下安装FFmpeg(超简单版) 第一步:添加源. sudo add-apt-re ...
- poj 1873
哇实验室里正在吵架,爽死了! wf水题.显然二进制枚举,注意剪枝,val>ans的时候剪一下,不然会tle.然后就没惹. 我老人家一开始写了个 感觉非常垃圾,wa了一发又t了一发. 感觉自己可以 ...
- hdu 1704 Rank (floyd闭包)
Rank Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submis ...
- C/C++预处理器
关于预处理器 首先时预处理器的条件指令 什么是预处理指令? 预处理指令是以#号开头的代码行.#号必须是该行除了任何空白字符外的第一个字符.#后是指令关键字,在关键字和#号之间允许存在任意个数的空白字符 ...
- eclipse连接mysql数据库实现怎删改查操作实例(附带源码)
package model; public class User { private int id; private String name; private String password; pub ...
- java学习(一)--- 基础语法
学习内容来 自菜鸟教程 http://www.runoob.com/java/java-object-classes.html Java基础 Java:一个Java程序可以认为是一系列的对象组合, ...