5、爬虫之scrapy框架
一 scrapy框架简介
1 介绍
Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速、简单、可扩展的方式从网站中提取所需的数据。但目前Scrapy的用途十分广泛,可用于如数据挖掘、监测和自动化测试等领域,也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架。因此Scrapy使用了一种非阻塞(又名异步)的代码来实现并发。
整体架构大致如下:
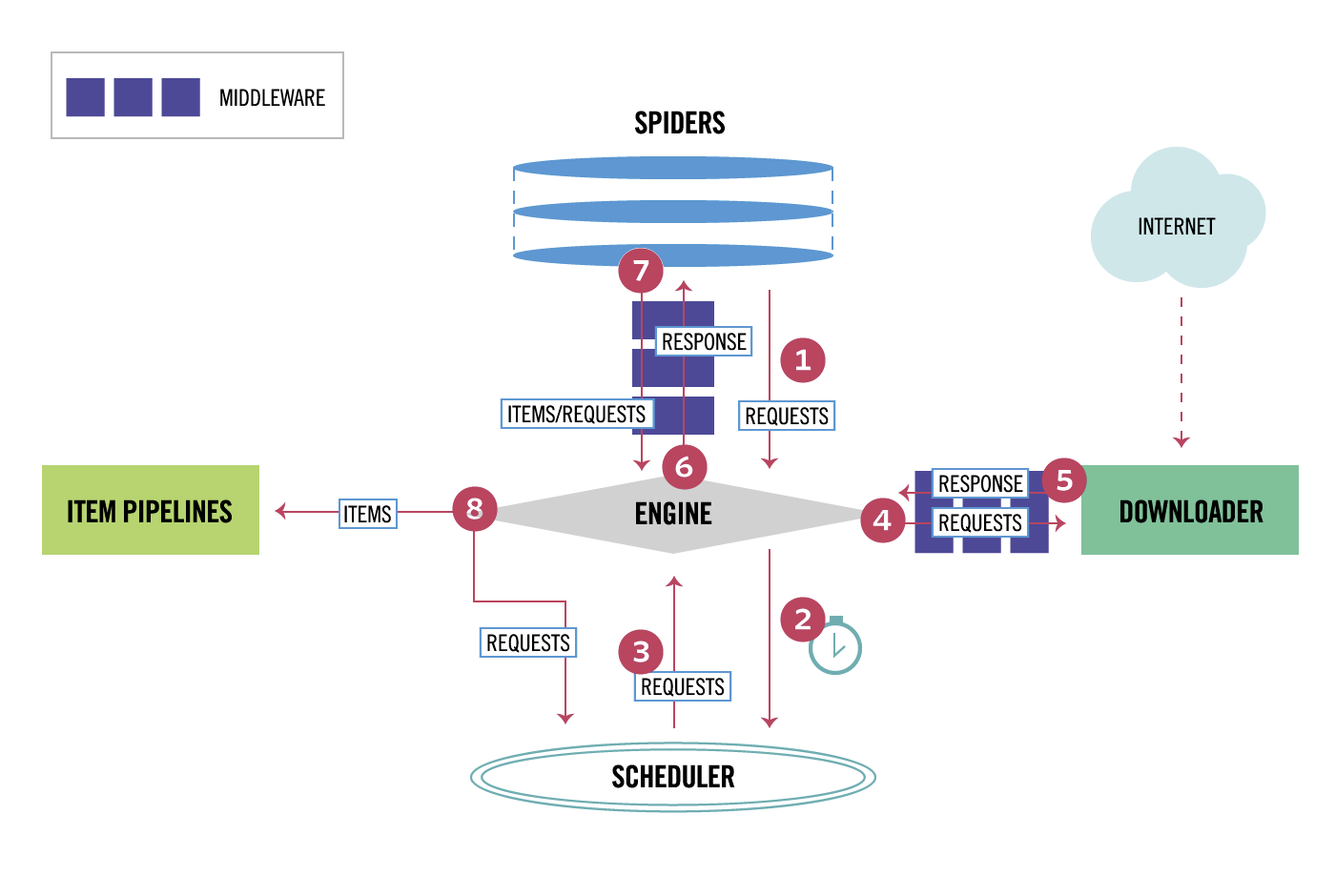
Components:
1、引擎(EGINE)
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。有关详细信息,请参见上面的数据流部分。
2、调度器(SCHEDULER)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
3、下载器(DOWLOADER)
用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的
4、爬虫(SPIDERS)
SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求
5、项目管道(ITEM PIPLINES)
在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作
下载器中间件(Downloader Middlewares)位于Scrapy引擎和下载器之间,主要用来处理从EGINE传到DOWLOADER的请求request,已经从DOWNLOADER传到EGINE的响应response,
你可用该中间件做以下几件事:
(1) process a request just before it is sent to the Downloader (i.e. right before Scrapy sends the request to the website);
(2) change received response before passing it to a spider;
(3) send a new Request instead of passing received response to a spider;
(4) pass response to a spider without fetching a web page;
(5) silently drop some requests.
6、爬虫中间件(Spider Middlewares)
位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(即responses)和输出(即requests)
下载
#Linux:
pip3 install scrapy
#Windows:
a. pip3 install wheel
b. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
c. 进入下载目录,执行 pip3 install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl
d. pip3 install pywin32
5、爬虫之scrapy框架的更多相关文章
- Python网络爬虫之Scrapy框架(CrawlSpider)
目录 Python网络爬虫之Scrapy框架(CrawlSpider) CrawlSpider使用 爬取糗事百科糗图板块的所有页码数据 Python网络爬虫之Scrapy框架(CrawlSpider) ...
- 爬虫06 /scrapy框架
爬虫06 /scrapy框架 目录 爬虫06 /scrapy框架 1. scrapy概述/安装 2. 基本使用 1. 创建工程 2. 数据分析 3. 持久化存储 3. 全栈数据的爬取 4. 五大核心组 ...
- Python逆向爬虫之scrapy框架,非常详细
爬虫系列目录 目录 Python逆向爬虫之scrapy框架,非常详细 一.爬虫入门 1.1 定义需求 1.2 需求分析 1.2.1 下载某个页面上所有的图片 1.2.2 分页 1.2.3 进行下载图片 ...
- 爬虫之scrapy框架
解析 Scrapy解释 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓 ...
- Python爬虫进阶(Scrapy框架爬虫)
准备工作: 配置环境问题什么的我昨天已经写了,那么今天直接安装三个库 首先第一步: ...
- 爬虫之Scrapy框架介绍
Scrapy介绍 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内 ...
- 16.Python网络爬虫之Scrapy框架(CrawlSpider)
引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法 ...
- python爬虫随笔-scrapy框架(1)——scrapy框架的安装和结构介绍
scrapy框架简介 Scrapy,Python开发的一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 ...
- Python学习---爬虫学习[scrapy框架初识]
Scrapy Scrapy是一个框架,可以帮助我们进行创建项目,运行项目,可以帮我们下载,解析网页,同时支持cookies和自定义其他功能. Scrapy是一个为了爬取网站数据,提取结构性数据而编写的 ...
随机推荐
- Java并发编程笔记之 CountDownLatch闭锁的源码分析
JUC 中倒数计数器 CountDownLatch 的使用与原理分析,当需要等待多个线程执行完毕后在做一件事情时候 CountDownLatch 是比调用线程的 join 方法更好的选择,CountD ...
- Jmeter - 测试 http 接口
前言: 本文主要针对http接口进行测试,使用Jmeter工具实现. Jmter工具设计之初是用于做性能测试的,它在实现对各种接口的调用方面已经做的比较成熟,因此,本次直接使用Jmeter工具来完成对 ...
- netty源码解解析(4.0)-10 ChannelPipleline的默认实现--事件传递及处理
事件触发.传递.处理是DefaultChannelPipleline实现的另一个核心能力.在前面在章节中粗略地讲过了事件的处理流程,本章将会详细地分析其中的所有关键细节.这些关键点包括: 事件触发接口 ...
- BGP笔记
BGP:用于AS与AS之间的路由,但现在也越来越多的用在IDC内部了 BGP是应用层协议,应用TCP协议(唯一一个运用TCP的路由协议) IGP和EGP的区别:IGP运行在一个AS之内,EGP运行在A ...
- [转]Oracle密码过期, 报:ORA-01017: 用户名/口令无效; 登录被拒绝
本文转自:https://blog.csdn.net/jeff06143132/article/details/25696371 连接Oracle,以Oracle用户登陆: $su - oracl ...
- 分部类,分部方法 - 修饰符partial
一.分部类 什么是部分类呢?简单来说就是将一个类型或方法拆分到两个或多个源文件中,每个源文件只包含类型定义的一部分. 当使用自动生成的源时,无须重新创建源文件便可将代码添加到类中.Visual Stu ...
- SqlServer存储过程,学习
存储过程:存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的SQL 语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数) ...
- 【表格设置】HTML中合并单元格,对列组合应用样式,适应各浏览器的内容换行
1.常用表格标签 普通 <table> | <tr> | | <th ...
- Memcached部署和用法
一.Memcached简介 Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态.数据库驱动网 ...
- Nhibernate学习的第一天
书本:https://www.tutorialspoint.com/nhibernate/index.htm 第一天学习内容 概念 Nhibernate是一个ORM框架. ORM框架:将声明的类映射到 ...