Python爬虫中文小说网点查找小说并且保存到txt(含中文乱码处理方法)
从某些网站看小说的时候经常出现垃圾广告,一气之下写个爬虫,把小说链接抓取下来保存到txt,用requests_html全部搞定,代码简单,容易上手.
中间遇到最大的问题就是编码问题,第一抓取下来的小说内容保持到txt时出现乱码,第二url编码问题,第三UnicodeEncodeError
先贴源代码,后边再把思路还有遇到的问题详细说明。
from requests_html import HTMLSession as hs def get_story(url):
global f
session=hs()
r=session.get(url,headers=headers)
r.html.encoding='GBK'
title=list(r.html.find('title'))[0].text#获取小说标题
nr=list(r.html.find('.nr_nr'))[0].text#获取小说内容
nextpage=list(r.html.find('#pb_next'))[0].absolute_links#获取下一章节绝对链接
nextpage=list(nextpage)[0]
if(nr[0:10]=="_Middle();"):
nr=nr[11:]
if(nr[-14:]=='本章未完,点击下一页继续阅读'):
nr=nr[:-15]
print(title,r.url)
f.write(title)
f.write('\n\n')
f.write(nr)
f.write('\n\n')
return nextpage def search_story():
global BOOKURL
global BOOKNAME
haveno=[]
booklist=[]
bookname=input("请输入要查找的小说名:\n")
session=hs()
payload={'searchtype':'articlename','searchkey':bookname.encode('GBK'),'t_btnsearch':''}
r=session.get(url,headers=headers,params=payload)
haveno=list(r.html.find('.havno'))#haveno有值,则查找结果如果为空
booklist=list(r.html.find('.list-item'))#booklist有值,则有多本查找结果
while(True):
if(haveno!=[] and booklist==[]):
print('Sorry~!暂时没有搜索到您需要的内容!请重新输入')
search_story()
break
elif(haveno==[] and booklist!=[]):
print("查找到{}本小说".format(len(booklist)))
for book in booklist:
print(book.text,book.absolute_links)
search_story()
break
else:
print("查找到结果,小说链接:",r.url)
BOOKURL=r.url
BOOKNAME=bookname
break global BOOKURL
global BOOKNAME
url='http://m.50zw.net/modules/article/waps.php'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.170 Safari/537.36 OPR/53.0.2907.99'
} search_story()
chapterurl=BOOKURL.replace("book","chapters")
session=hs()
r=session.get(chapterurl,headers=headers)
ch1url=list(r.html.find('.even'))[0].absolute_links#获取第一章节绝对链接
ch1url=list(ch1url)[0]
global f
f=open(BOOKNAME+'.txt', 'a',encoding='gb18030',errors='ignore')
print("开始下载,每一章节都需要爬到,速度快不了,请等候。。。。\n")
nextpage=get_story(ch1url)
while(nextpage!=BOOKURL):
nextpage=get_story(nextpage)
f.close
爬虫思路及遇到的问题分析如下:
先查找小说,并且把小说链接抓取下来,以网站http://m.50zw.net/modules/article/waps.php为例,首先在浏览器中打开链接并且右键点检查,选择Network标签,我用的是chrome浏览器,按F1设置把Network底下的Preserve log勾选上,方便接下来查找log,以搜索‘帝后世无双’为例,搜索到结果后直接跳到了此本小说的url:http://m.50zw.net/book_86004/
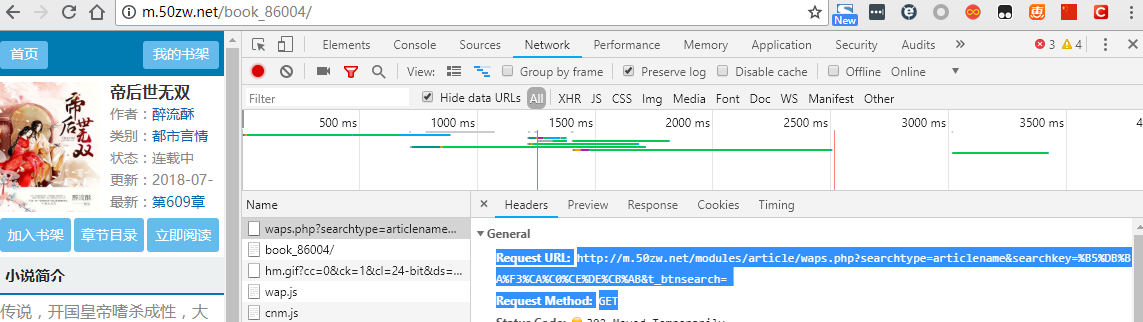
查看到请求方式是GET,Request URL是 http://m.50zw.net/modules/article/waps.php?searchtype=articlename&searchkey=%B5%DB%BA%F3%CA%C0%CE%DE%CB%AB&t_btnsearch=
然后分析出请求参数有三个,searchtype先固定用图书名来查找,而searchkey我们输入的是”敌后世无双“,url encoding成了%B5%DB%BA%F3%CA%C0%CE%DE%CB%AB,我们在python ide里边分别输入:
"敌后世无双".encode('GBK'):b'\xb5\xd0\xba\xf3\xca\xc0\xce\xde\xcb\xab'
"敌后世无双".encode('utf-8'):b'\xe6\x95\x8c\xe5\x90\x8e\xe4\xb8\x96\xe6\x97\xa0\xe5\x8f\x8c'
对照输出结果我们知道这里url编码采用的是GBK
接下来我们用代码来验证我们分析的结果
from requests_html import HTMLSession as hs
url='http://m.50zw.net/modules/article/waps.php'
payload={'searchtype':'articlename','searchkey':'帝后世无双','t_btnsearch':''}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.170 Safari/537.36 OPR/53.0.2907.99'
}
session=hs()
r=session.get(url,headers=headers,params=payload)
print(r.url)
运行结果:
http://m.50zw.net/modules/article/waps.php?searchtype=articlename&searchkey=%E5%B8%9D%E5%90%8E%E4%B8%96%E6%97%A0%E5%8F%8C&t_btnsearch=
比较得到的url跟我们刚才手动输入后得到的url有出入,代码里边如果没有指定编码格式的话了这里url编码默认是urf-8,因为编码问题我们没有得到我们想要的结果,那接下来我们修改代码指定编码试试
payload={'searchtype':'articlename','searchkey':'帝后世无双'.encode('GBK'),'t_btnsearch':''}
这回运行结果得到我们想要的url:
http://m.50zw.net/book_86004/
好,成功了!!!
那接下来我们要获取第一章节的链接,中间用到了requests_html来抓取绝对链接
bookurl='http://m.50zw.net/book_86004/'
chapterurl=bookurl.replace("book","chapters")
session=hs()
r=session.get(chapterurl,headers=headers)
ch1url=list(r.html.find('.even'))[0].absolute_links
ch1url=list(ch1url)[0]
print(ch1url)
运行结果:
http://m.50zw.net/book_86004/26127777.html
成功取得第一章节链接
接下来我们开始获取小说内容并且获取下一章链接直到把整本小说下载下来为止,
在这个部分遇到UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' in position 46:illegal multibyte sequence,这个问题最终在用open函数打开txt时加两个参数解决encoding='gb18030',errors='ignore'.
在之前也用过另外一种方案,就是把u'\xa0'替换成跟它等效的u' ',虽然解决了'\xa0'的error,可是后来又出现了’\xb0'的error,总不能出现一个类似的rror就修改代码替换一次,所以这个方案被放弃掉.
session=hs()
r=session.get(ch1url,headers=headers)
title=list(r.html.find('title'))[0].text
nr=list(r.html.find('.nr_nr'))[0].text
##nr=nr.replace(u'\xa0',u' ')
nextpage=list(r.html.find('#pb_next'))[0].absolute_links
nextpage=list(nextpage)[0]
if(nr[0:10]=="_Middle();"):
nr=nr[11:]
if(nr[-14:]=='本章未完,点击下一页继续阅读'):
nr=nr[:-15]
print(title,r.url)
print(nextpage)
f=open('帝后世无双.txt', 'a',encoding='gb18030',errors='ignore')
f.write(title)
f.write('\n\n')
f.write(nr)
f.write('\n\n')
Python爬虫中文小说网点查找小说并且保存到txt(含中文乱码处理方法)的更多相关文章
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- 关于爬取数据保存到json文件,中文是unicode解决方式
流程: 爬取的数据处理为列表,包含字典.里面包含中文, 经过json.dumps,保存到json文件中, 发现里面的中文显示未\ue768这样子 查阅资料发现,json.dumps 有一个参数.ens ...
- 「拉勾网」薪资调查的小爬虫,并将抓取结果保存到excel中
学习Python也有一段时间了,各种理论知识大体上也算略知一二了,今天就进入实战演练:通过Python来编写一个拉勾网薪资调查的小爬虫. 第一步:分析网站的请求过程 我们在查看拉勾网上的招聘信息的时候 ...
- python爬虫下载小视频和小说(基础)
下载视频: 1 from bs4 import BeautifulSoup 2 import requests 3 import re 4 import urllib 5 6 7 def callba ...
- 一个简易的Python爬虫,将爬取到的数据写入txt文档中
代码如下: import requests import re import os #url url = "http://wiki.akbfun48.com/index.php?title= ...
- python 读取一个文件夹下的所jpg文件保存到txt中
最近需要使用统计一个目录下的所有文件,使用python比较方便,就整理了一下代码. import os def gci(filepath): files = os.listdir(filepath) ...
- java 保存到mysql数据库中文乱码
<property name="jdbcUrl">jdbc:mysql://localhost:3306/company?useUnicode=true&cha ...
- 第二个爬虫之爬取知乎用户回答和文章并将所有内容保存到txt文件中
自从这两天开始学爬虫,就一直想做个爬虫爬知乎.于是就开始动手了. 知乎用户动态采取的是动态加载的方式,也就是先加载一部分的动态,要一直滑道底才会加载另一部分的动态.要爬取全部的动态,就得先获取全部的u ...
- 用python+selenium抓取微博24小时热门话题的前15个并保存到txt中
抓取微博24小时热门话题的前15个,抓取的内容请保存至txt文件中,需要抓取排行.话题和阅读数 #coding=utf-8 from selenium import webdriver import ...
随机推荐
- 微信小程序富文本中的图片大小超出屏幕
这个问题我在小程序社区中提的,后来有个帮我回答了这个问题,我试了一下可以. 解决办法是过滤富文本内容,给图片标签添加一个样式,限制图片的最大宽度. replace(/\<img/gi, '& ...
- MVC+三层+ASP.NET简单登录验证
通过制作一个登录小案例来搭建MVC简单三层 在View --Shared下创建一个母版页: <!DOCTYPE html> <html> <head> <me ...
- Unity打开外部程序exe/Bat文件方案
Unity调用外部程序/Bat文件 本文提供全流程,中文翻译. Chinar 坚持将简单的生活方式,带给世人!(拥有更好的阅读体验 -- 高分辨率用户请根据需求调整网页缩放比例) Chinar -- ...
- Python全栈之路----函数----局部变量
全局变量是定义在函数外部以及代码的变量,全局能用. 局部变量就是定义在函数里的变量,只能在局部生效. 在函数内部,可以引用全局变量. 如果全局和局部都有一个名字相同的变量,在函数内会优先调用函数内的局 ...
- 如何在Linux系统下挂载光盘
工具/原料 Linux 方法/步骤 找到光盘的完整路径名.在命令行输入:ls -l /dev | grep cdrom. 可以看到光盘的名字叫做:cdrom1.然后在命令行执行: mount /d ...
- 远程桌面连接问题,ping服务器ip无法连接主机。
今天是礼拜一,上班的第一天去连公司的服务器,远程桌面竟然登录不上. 试了一下同事的电脑,也是一样的情况无法连接到远程计算机.这下可把我急坏了. 试了很多方法,也重新启动了服务器,重启后同事的win10 ...
- activiti学习第二天
今天我们来发布一个流程,然后查看数据库中都发生了什么变化. 下面我们使用activiti designer设计一个流程.如图 流程很简单,我们先简单后增加难度. 创建流程图的顺序,新建一个文件夹(di ...
- 十八、springcloud(四)熔断器
1.熔断器(Hystrix) a.断路器机制 断路器很好理解, 当Hystrix Command请求后端服务失败数量超过一定比例(默认50%), 断路器会切换到开路状态(Open). 这时所有请求会直 ...
- 论文阅读笔记:【MDNet】
[MDNET]: H Nam, B Han. Learning multi-domain convolutional neural networks for visual tracking[C]. / ...
- c 链表和动态内存分配
兜兜转转又用到了c.c的一些基本却忘记的差不多了(笑哭)!! 动态内存分配 当malloc完将返回的指针类型强制转换成想要的类型后,指针中存有该指针的数据结构,而分配的内存恰好可用于该数据结构. 链表 ...