Laxcus大数据管理系统2.0(5)- 第二章 数据组织
第二章 数据组织
在数据的组织结构设计上,Laxcus严格遵循数据和数据描述分离的原则,这个理念与关系数据库完全一致。在此基础上,为了保证大规模数据存取和计算的需要,我们设计了大量新的数据处理技术。同时出于兼顾用户使用习惯和简化数据处理的目的,继续沿用了一些关系数据库的设计和定义,其中不乏对SQL做适量的修订。在这些变化中,核心仍然是以关系代数的理念去处理数据,以及类自然语言风格的数据描述。所以用户在使用体验上,和关系数据库相比,不会感觉到有太多的差异。
本章将介绍Laxcus数据结构的组成,并对其中的一些修订和修订原因做出说明。
2.1 基础
Laxcus沿袭了关系数据库的用户模型、逻辑模型、存储模型的三层结构。对于逻辑模型,遵循用户账号、数据库、表的结构序列,即用户账号下可以建立多个数据库,数据库下可以建立多个表,在表之下是数据文件。因为Laxcus的多集群架构,支持表跨节点跨集群存在。在逻辑描述上,表是行的集合,行由多列构成,每一列对应一个数据值。实体的行,最多容纳32767列(0x7FFF),这个尺寸足以满足各种数据应用需要。在列的基础上,可以建立索引,通过索引实现对表的快速检索。用户的配置数据经过加密后,会保存到Top节点的数据字典里。
在兼容SQL方面,SQL的管理控制语句、数据定义语句、数据操作语句,以及运算符、关键字、大部分SQL函数,被完整继承下来。用户依然可以按照SQL标准进行操作。被支持的还有“空值”,包括NULL和EMPTY。二者的区别是,NULL表示数据值未定义或者不知道,适用于所有数据类型;EMPTY只用在字符或者字节数组上,表示数据值确定且是0长度。做为SQL核心的4个操作语句也得到支持,并在此基础上扩展了SELECT嵌套语句、ORDER BY、GROUP BY子句,另外也可以使用LIKE关键字进行模糊检索。
|
管理语句 |
说明 |
|
CREATE USER |
建立一个用户账号和密码 |
|
ALTER USER |
修改用户账号的密码 |
|
DROP USER |
删除一个用户账号及其下的所有数据资料 |
|
GRANT |
对用户账号下的某个操作授权 |
|
REVOKE |
收回用户账号下的某个操作权利 |
表2.1.1 管理语句
|
数据定义 |
说明 |
|
CREATE DATABASE |
建立一个数据库 |
|
DROP DATABASE |
删除一个数据库及其下的所有表 |
|
CREATE TABLE |
建立一个表 |
|
DROP TABLE |
删除一个表和其下的所有数据 |
表2.1.2 数据定义语句
|
数据操作 |
说明 |
|
INSERT |
写入记录 |
|
DELETE |
删除记录 |
|
UPDATE |
更新记录 |
|
SELECT |
查询记录 |
|
JOIN |
连接查询 |
表2.1.3 数据操作语句
|
运算符类型 |
运算符 |
说明 |
|
比较运算符 |
= |
等于 |
|
> |
大于 |
|
|
< |
小于 |
|
|
>= |
大于等于 |
|
|
<= |
小于等于 |
|
|
<> != |
不等于 |
|
|
逻辑运算符 |
not |
非 |
|
and |
与 |
|
|
or |
或 |
|
|
between ... and |
在某些数据范围内 |
|
|
in |
满足多个条件之一 |
|
|
like |
模糊查询,匹配特定符串 |
|
|
赋符运算符 |
= |
对变量赋值 |
表2.1.4 运算符
2.2 数据类型
目前各种关系数据库上的数据类型,因为产品和版本原因,数量也不尽相同。在实际应用中,最常用到的大约10余个。根据这种现状,我们在设计数据类型时做了简化处理,取消了其中大部分比较少用的数据类型,保留了一批基础数据类型,另外考虑到网络应用需求,新增加了一批数据类型,同时对某些数据类型进行了合并,最后把它们分为两大类:固定长的数值类型、可变长的数组类型。见表2.2所示。数值类型在不同操作系统平台上都是统一的,数组类型的长度范围在0 - 2G字节之间,可以随输入数据自动调整,这个尺寸足以容纳当前各种文本、图片、视频、音频等多媒体内容。因为这个尺寸对用户来说已经足够大,用户在输入数据时,可以忽略列长度问题。在字符选择上,为了适用于多语言的混合环境,字符类型内码统一采用Unicode编码,因此就避免了乱码现象。Laxcus字符定义是,单字节的Char对应UTF8编码,双字节的WChar对应UTF16 Big Endian编码,四字节的HChar对应UTF32编码。用户在设计表的时候可以根据需要选择。例如英文环境应该使用Char,东亚语系内码和西里尔文字都是双字节,采用WChar更合适。
|
数据类型 |
标识 |
字长 |
范围 |
|||
|
数组 类型 |
字节 |
原始类型 |
RAW(BINARY) |
8 |
0 - 2G |
|
|
媒体 |
文档 |
DOCUMENT |
8 |
|||
|
图像 |
IMAGE |
|||||
|
音频 |
AUDIO |
|||||
|
视频 |
VIDEO |
|||||
|
字符 |
单字符 |
CHAR |
8 |
|||
|
宽字符 |
WCHAR |
16 |
||||
|
大字符 |
HCHAR |
32 |
||||
|
数值类型 |
数值 |
短整型 |
SHORT (SMALLINT) |
16 |
-32768 - 32767 |
|
|
整型 |
INT |
32 |
-2147483648 - 2147483647 |
|||
|
长整型 |
LONG (BIGINT) |
64 |
-9223373036854775808 - 9223373036854775807 |
|||
|
单浮点 |
FLOAT |
32 |
-3.40E+38 - 3.40E+38 |
|||
|
双浮点 |
DOUBLE |
64 |
-1.79E+308 - 1.79E+308 |
|||
|
时间日期 |
日期 |
DATE |
32 |
1年1月1日 - 9999年12月31日 |
||
|
时间 |
TIME |
32 |
0时0分0秒0毫秒 - 23时59分59秒999毫秒 |
|||
|
时间戳 |
TIMESTAMP |
64 |
1年1月1日0时0分0秒0毫秒 - 9999年12月31日23时59分59秒999毫秒 |
|||
表2.2 数据类型
2.3 全局数据库
在Laxcus大数据系统里,数据库被定义成“全局”的。这个“全局”意味着每一个数据库的名称,在整个主域集群里都是唯一的,不允许出现重叠现象,即使分属两个用户也不可以。比如,当A用户建立一个名为“Product”的数据库后,B用户再建立“Product”数据库将被系统拒绝。
采用全局数据库是出于简化系统设计和减少操作环节的考量。这样节点在运行过程中,因为数据库不存在同名歧义的可能性,系统可以很容易判断每一个数据库和用户的对应关系,可以减少许多不必要的作业流程。
2.4 跨数据库操作
我们在进行数据结构规划设计时,经常需要定义一个或者几个数据库,再这些数据库之下,又定义不同需求的表,然后录入不同性质的数据。同时,我们还需要设置一些公共参数,把它们放在一个或者几个表里,为了便于管理和使用,又常常希望放在一个数据库里,在数据处理时,可以给分散在不同数据库下的数据表共同使用。
出于这样的考虑,Laxcus大数据系统支持跨数据库的数据表操作。这样就形成了在一个用户账号下,在数据操作时,所有表与表之间,不用事先声明,就可以实现完全的互通互调用。在精简了系统设计和集中数据资源的同时,也减少了数据处理过程中很多不必要的麻烦,方便了用户快速处理数据,提高了数据处理的灵活性和效率。
在实际应用中,这项功能对数据检索非常有利,诸如连接查询 (Join)和嵌套查询(Sub select)这样的操作。跨数据库操作不会出现数据混乱,因为它们都要接受Aid节点的管理,被Aid节点有序地按照所属条件分别执行。
2.5 固定表
在关系数据库里,表结构是可以随时修改变化的,但是在Laxcus,这项功能被停止使用,表结构一旦定义禁止修改。禁止的原因在于大数据所处的现实环境。试想一下,在一个由上千台计算机组成的集群环境里,如果允许修改表结构,会有什么反应?所有正在运行和关联的任务将被迫停止,新的任务将转入队列中堆积和等待;全部数据内容将按照新的表结构重新组织和排列。这种变化和等待的过程,是任何一个大数据集群所不能承受的。囿于这种现实情况,Laxcus规定,表的结构一旦正式确定不允许修改。
由于表的不可修改,同时被改变的还有对索引的定义。按照SQL规范,“CREATE INDEX”是在“CREATE TABLE”之后进行的操作。现在将它们合并到一起,在定义列的时候,指定这个列是否成为索引。
对索引的解释,Laxcus也做了调整。新的规定是,一个表中只能有一个列成为主索引(Prime Index)和任意多个列的副索引(Slave Index)。副索引概念与SQL没有差别,主索引除了具有副索引的功能,主要用于指示数据排列位置,即将有相同值的列组织到一起。例外的是,对于列存储模型,所有列成员,即使用户不定义索引,其列值也能够自动做为索引使用,同时不增加磁盘和内容开销。但是两种存储模型都需要定义一个主索引,因为涉及到数据内容在磁盘和内存上的排列。
另外,为适应大数据处理需要,在建表命令中增加了一批新的内容,这些参数主要在“Create Table”和“数据库名.表名”之间声明,列声明中也有新的定义。这些参数都是可选的,不声明的时候,系统将使用默认值。请参见图2.5和表2.5。
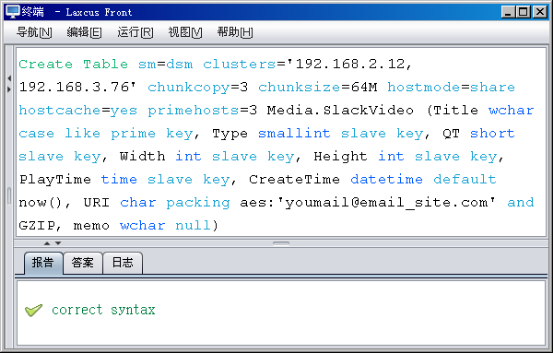
图2.5 数据库建表命令语句
|
关键字 |
说明 |
|
SM |
存储模型。NSM:行存储模型;DSM:列存储模型 |
|
CLUSTERS |
子域集群,一个或多个Home地址,或者指定数字 |
|
CHUNKSIZE |
数据块尺寸,以兆为单位 |
|
CHUNKCOPY |
同质数据块数据,包括一个主块和任意个从块 |
|
HOSTMODE |
表对节点所有权。SHARE:共享主机;EXCLUSIVE:独亨主机 |
|
HOSTCACHE |
数据块缓存,根据热度由节点选择是否自动加载 |
|
PRIMEHOSTS |
表初始拥有的Data主节点数量,以后随数据诸量自动增加 |
|
NULL|NOT NULL |
支持空值或者否(适用所有数据类型) |
|
EMPTY|NOT EMPTY |
支持这值或者否(只限字符串和字节数组) |
|
CASE|NOT CASE |
字符串大小写敏感或者否 |
|
LIKE|NOT LIKE |
字符串允许模糊查询或者否 |
|
DEFAULT |
列的默认值,根据类型支持数值、数组、字符串、SQL函数 |
|
PRIME KEY|SLAVE KEY |
主/从索引,如是数组类型,指定从0下标开始的索引长度 |
|
PACKING |
数组列内容的加密、压缩,若加密提供密码 |
表2.5 数据库建表关键字
2.6 取消视图
在SQL的定义中,视图是一个虚拟表,是对实体表和其它视图的关联和映射,做为一个数据描述存在于系统中,被视为用户和实体表之间的过渡而存在。视图具有向用户屏蔽实体表数据结构的作用,也具有在改变表数据结构时,不用改变上层描述的能力。只是在数据处理时,视图才将数据操作重新定位到实体表上,然后向用户返回经过它处理重组后的新的数据集合。
如果遵守SQL这套定义,把视图转移到大数据环境,它在处理海量数据时,就要进行视图和表之间的关联和转换,这无疑将增加运行开销,降低处理效率,同时也加大了系统设计难度,与我们追求简单、快捷的设计初衷相悖。另外Laxcus为取代视图提供了一套新的技术方案:数据构建。这项技术提供了对一个表或者多个表的分析、组合能力,并且具有比视图更大的灵活性和高效率。另外一个更重要的原因是:在Laxcus体系里,用户、数据之间的概念和关系已经与关系数据库大不一样,关系数据库提供视图的初衷是向部分用户屏蔽表数据结构,或者改变表数据结构而不用改变上层表述,而Laxcus的用户拥有对自己数据的全部管理权和使用权,表的数据结构也是固定的,这样的设计如果移植到Laxcus显然有悖常理。鉴于这些原因,综合比较之后,Laxcus取消了视图。
2.7 带Where子句的Select检索
在关系数据库上,SELECT检索不带WHERE语句将返回表下的全部记录。按此推理,计算机集群上的操作也应该返回一样的结果,但是这样的操作转移大数据环境下,面对巨大的数据压力将导致灾难性的后果:计算机会因为瞬间暴发的庞大数据量,在还来不及处理时,就造成内存溢出和软件系统崩溃;网络也会因为这些瞬间涌现的巨大流量,出现数据风暴,造成网络阻塞。接下来的可能是大面积故障和连带的波及影响扩大化,造成整个集群的故障,从而被迫中断数据处理业务,造成不可挽回的损失。这种情况显然是不可接受的。另外,在现实的应用环境里,全网络全数据的检索操作其实并没有太多实际意义。
因为上述原因,Laxcus对数据检索提出这样的规定,基本的数据检索操作必须是“SELECT-FROM-WHERE”语句块,否则将视为非法,拒绝执行。这项检查工作将在Front节点上分析执行,然后在集群里还有进一步的判断。
2.8 数组列的压缩和加密
我们在使用很多网络应用的时候,经常会在其中保存一些敏感和关键的内容,比如银行卡密码、电子邮件账号、手机电话、家庭地址等私密性很强的信息。这些信息,通常是不希望被别人知道的,包括网络管理人员。还有一些内容,例如像网页或者文档这样的文本数据,通常会很长,如果采用明文的方式保存会占用大量磁盘空间,将其压缩再保存就能有效减少空间占用量,况且文本数据的压缩比率都是非常高的。
Laxcus提供了这样一个选项,能够对这类信息进行加密和压缩。见图2.5和表2.5,这里对格式进行说明。“Packing”是对数组列内容进行压缩和加密的关键字。压缩和加密可以同时声明,也可以任选其一声明,如果只声明其中一种,要去掉连接它们的“AND”关键字。做加密声明时,同时需要提供密码。密码可以是任何语种的和不定长的字符串,在建表时会转换为UTF8码保存。压缩和加密的算法名称是固定的,已经支持的压缩算法有:GZIP、ZIP,以及加密算法:AES、DES、3DES、BLOWFISH。
数组列的压缩和加密由用户定义,在建表时输入。在此后的处理过程中,算法和密码也只对用户可见。
特别声明:无论数组列是否被压缩和加密,都不影响其做为索引的使用。
2.9 事务
事务在2.0版本是一个重要的模块,以管理器的形式运行在Aid站点上。所有数据处理工作都被默认要求执行事务处理流程。就是它们在执行数据操作前,需要通过事务管理器的审核才能实施。事务申请是一个同步串行操作过程,采用队列的“先到先得”原则,总是由排在最前面的申请获得优先使用权。申请成功后的事务会被记录到管理器队列,作为后续事务申请时的判断比较依据,直到它的数据处理工作完成后,才从管理器队列中撤销。没有申请成功的事务将被挂起,直到前面的事务从队列中撤销后才被唤醒。
我们在兼顾大数据并发效率、平衡事务申请要求、保证事务操作精度这几个方面需求考虑下,按照事务操作范围,把事务分为三种类型:用户型事务、数据库型事务、表型事务。用户型事务拥有操纵账号下全部资源的权力,数据库事务可以操作一个或者几个数据库以及下属全部表,表事务只能操作一个或者几个具体的表。三种事务在管理器上的地位是平等的,没有隶属关系。使它们产生关联的是它们所绑定的资源,这是决定一个事务能够获得申请通过、还是被拒绝挂起的依据。
事务另外一个属性是操作状态。事务操作状态被分成“读”和“写”两种。任何一个"写“事务生效,即表示和它关联的资源对象被锁定,不允许再申请,直到这个事务完成,这些资源被解锁,后续“写”申请才能生效。如果是“读”操作事务生效,被关联的资源只做标记,供后续所有事务参考,其它“写”事务仍然拥有锁定这些资源的权力。
综上所述,结合图2.9,在系统运行过程中,事务申请按照如下规则处理:
1.所有类型的"读"事务都可以共享存在。
2.如果队列都是“读”事务,后续一个“写”事务可以获得批准。
3.如果队列中有“写”事务,后续一个“写”事务只要不与它们存在资源冲突,就可以获得批准,否则被拒绝挂起。
4.为了进一步提高数据库事务和表事务的并发效率,在它们之间有一个“数据库名称”比较。当这样的两个"写“事务发生”数据库名称“冲突时,后续“写”事务被挂起,即同名互斥。
5.如果一个事务同时存在“读写”两种状态时,将按照“写”事务规则处理。
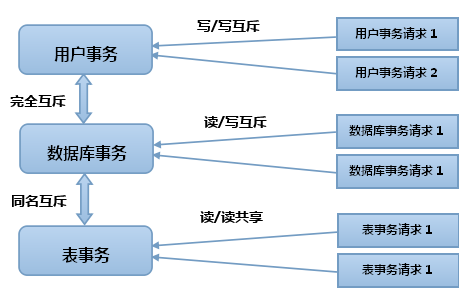
图2.9 Laxcus事务处理
2.10 分布描述语言
分布描述语言(简称DDL)开始于Laxcus 0.1版本,经过0.x、1.x版本加强后,在2.0版本又得到进一步完善。分布描述语言由大量命令组成,使用者在操作界面上输入字符语句命令语句,通过语法解释器解释后,转换成计算机指令,分发到集群上执行。分布描述语言经过这几个版本的完善,现在已经与Laxcus大数据管理系统高度集成,提供了全方位的管理、操纵集群能力,并且贯穿到集群的每一个环节。我们设计分布描述语言的目的在于简化操作人员的工作,希望实现“只需要操作人员通知集群做什么,而不需要去知道集群怎么做”。经过这几个版本的使用调查证明,分布描述语言所带来的效果,已经成为Laxcus大数据管理系统简单、高效处理的基本保证。
以下我们对分布描述语言的基本面貌做些简单的介绍。
2.10.1 三层结构模型
如图2.10.1所示,分布描述语言是一个三层结构模型。命令从Front或者Watch节点发出,来自Front节点的命令属于用户命令,来自Watch节点的命令属于集群管理命令。无论是Front还要Watch,它们的命令都需要经过语法解释器翻译成计算机指令,才能发往集群。用户命令在进入集群执行操作前,首先要通过网关节点(Aid、Call)的检查,在判断是正确并且有效后,网关节点会把这个命令分配给后续相关节点,去执行数据处理和数据管理工作。Watch节点因为位于集群内部,命令被翻译成计算机指令后,会直接发给与命令关联的节点去处理。
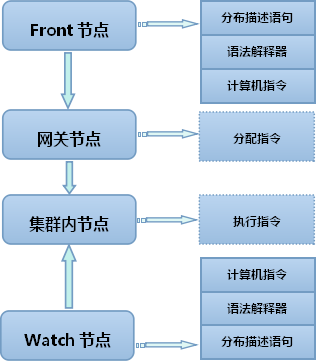
图2.10.1 三层结构模型
2.10.2 命令分类
如上所述,分布描述语言中的命令分为两大类:集群管理命令、用户命令。集群管理命令由管理员从Watch节点发出,用来控制、检查集群和节点的工作状态、分布资源。用户命令由用户从Front节点发出,主要是执行数据操纵和数据管理。因为分布描述语言兼容SQL,SQL中的所有命令被划入用户命令队列里。集群管理命令和用户命令在系统中是完全平行的,没有交集,也不允许互相使用。在权限等级上,所有集群管理命令都拥有比用户命令更高的操作权限。这体现在命令的被调用过程中,比如当两类命令同时出现在一个节点时,集群管理命令总是比用户命令优先获得执行的权力。不过在系统实际运行时,在集群中工作的基本都是用户命令,集群管理命令偶尔出现,而且也不会产生太多计算压力,所以这种优先权并不容易体现出来。
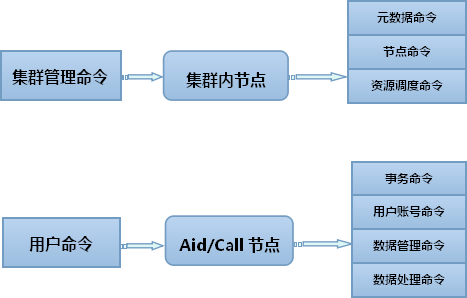
图2.10.2 集群管理命令和用户命令
2.10.3 自定义参数
在过去几个版本的演进过程中,有越来越多的用户要求系统提供一种在命令中存在、不需要系统理解、由用户自行处理的数据。这些数据的表现上,有时候可能是一个数字,有时候是一个字符串,也可能是一张图片,或者其它经过格式化处理的信息。它们成为命令的一部分,参与到用户的数据处理工作中。
顺应这一项发展需求,同时也为了规范化数据样式,提高数据处理效率,在2.0版本中,分布描述语言正式支持自定义参数,并且对自定义参数做出这样的规定:参数格式由Laxcus提供,内容由用户自己解释。如图2.10.3所示,自定义参数被分解成三部分:名称、类型、数值。其中名称由用户自由定义,类型是系统规定,类型在名称之后,被括号包围。类型分为数字型和数组型两组。数字类型包括bool、short、int、long、ushort、uint、ulong、float、double,数组类型包括string(char)、byte、image、object。为保证传输过程时的内码一致,用户输入的string数值会被转为UTF8编码。如果自定义参数是一个数组类型,那么数值需要被单括号包围,如果自定义是数字类型则不需要。这种样式的自定义参数被语法解释器解释后,将存入到命令的自定义参数队列,随命令一起分发到集群上,在需要它发挥作用的位置参与数据处理工作。
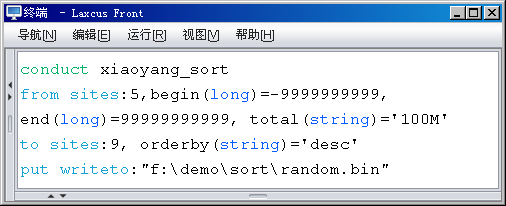
图2.10.3 分布描述语言自定义参数
Laxcus大数据管理系统2.0(5)- 第二章 数据组织的更多相关文章
- Laxcus大数据管理系统2.0(9)- 第七章 分布任务组件
第七章 分布任务组件 Laxcus 2.0版本的分布任务组件,是在1.x版本的基础上,重新整合中间件和分布计算技术,按照新增加的功能,设计的一套新的.分布状态下运行的数据计算组件和数据构建组件,以及依 ...
- Laxcus大数据管理系统2.0(3)- 第一章 基础概述 1.2 产品特点
1.2 产品特点 Laxcus大数据管理系统运行在计算机集群上,特别强调软件对分布资源可随机增减的适应性.这种运行过程中数据动态波动和需要瞬时感知的特点,完全不同与传统的集中处理模式.这个特性衍生出一 ...
- Laxcus大数据管理系统2.0 (1) - 摘要和目录
Laxcus大数据管理系统 (version 2.0) Laxcus大数据实验室 摘要 Laxcus是Laxcus大数据实验室全体系全功能设计研发的多用户多集群大数据管理系统,支持一到百万台级节点,提 ...
- Laxcus大数据管理系统2.0(10)- 第八章 安全
第八章 安全 由于安全问题对大数据系统乃至当前社会的重要性,我们在Laxcus 2.0版本实现了全体系的安全管理策略.同时我们也考虑到系统的不同环节对安全管理的需求是不一样的,所以有选择地做了不同的安 ...
- Laxcus大数据管理系统2.0(8)- 第六章 网络通信
第六章 网络通信 Laxcus大数据管理系统网络建立在TCP/IP网络之上,从2.0版本开始,同时支持IPv4和IPv6两种网络地址.网络通信是Laxcus体系里最基础和重要的一环,为了能够利用有限的 ...
- Laxcus大数据管理系统2.0(6)- 第四章 数据计算
第四章 数据计算 Laxcus所有数据计算工作都是通过网络实施.相较于集中计算,在网络间进行的数据计算更适合处理那些数据量大.复杂的.耗时长的计算任务.能够实施网络计算的前提是数据可以被分割,就是把一 ...
- Laxcus大数据管理系统2.0(14)- 后记
后记 Laxcus最早源于一个失败的搜索引擎项目,项目最后虽然终止了,但是项目中的部分技术,包括FIXP协议.Diffuse/Converge算法.以及很多新的数据处理理念却得以保留下来,这些成为后来 ...
- Laxcus大数据管理系统2.0(11)- 第九章 容错
第九章 容错 在当前,由于集群庞大的组织体系和复杂性,以及用户普遍要求低成本硬件,使得集群在运行过程中发生的错误概率,远远高于单一且性能稳定的小型机服务器,并且集群在运行过程中几乎是不允许停止的,这就 ...
- Laxcus大数据管理系统2.0(12)- 第十章 运行
第十章 运行 本章将介绍一些Laxcus集群基本运行.使用情况,结合图片和表格表示.地点是我们的大数据实验室,使用我们的实验集群.数据来自于我们的合作伙伴,软件平台混合了Windows和Fedora ...
随机推荐
- 浏览器-Tomcat服务器-请求与响应
浏览器访问服务器,本质就是请求资源. 比如请求静态资源:index.html,我们在浏览器地址栏输入:www.a.com/index.html,浏览器为了支持HTTP协议,发送的数据必须符合HTTP协 ...
- 二、SQL语句映射文件(2)增删改查、参数、缓存
//备注:该博客引自:http://limingnihao.iteye.com/blog/106076 2.2 select 一个select 元素非常简单.例如: Xml代码 收藏代码 <!- ...
- Angularjs,WebAPI 搭建一个简易权限管理系统 —— 基本功能演示(二)
目录 前言 Angularjs名词与概念 Angularjs 基本功能演示 系统业务与实现 WebAPI项目主体结构 Angularjs 前端主体结构 基本功能演示(二) 非常抱歉这个月实在太忙,一直 ...
- mybatis hellworld
用maven来进行搭建项目的~~ 1. 搭建环境 pom.xml <project xmlns="http://maven.apache.org/POM/4.0.0" x ...
- Force.com微信开发系列(五)自定义菜单进阶及语音识别
在上文里我们介绍了如何通过Force.com平台里为微信账号添加自定义菜单,本文里我们将进一步介绍如何查询菜单以及删除菜单的相关知识,最后会介绍微信平台如何进行语音识别的相关技术. 查询菜单 与创建菜 ...
- Sharepoint学习笔记—习题系列--70-573习题解析 -(Q104-Q106)
Question 104You plan to create a workflow that has the following three activities: CreateTask OnTask ...
- WKWebView API精讲(OC)
WKWebView API精讲(OC) 前言 鉴于LL同志对笔者说:“能不能写个OC版本的WKWebView的使用教程?”,还积极打赏了30RMB,笔者又怎么好意思拒绝呢,于是才有了下文. 所有看到本 ...
- 【读书笔记】iOS-UIFont-动态下载系统提供的多种中文字体网址
苹果可使用的字体列表: https://support.apple.com/zh-cn/HT202599 动态下载字体的代码demo: https://developer.apple.com/libr ...
- SQL JOIN
- IOS 杂笔-2(协议)
1.协议的定义 @protocol 协议名称 <NSObject> //方法声明列表 @end; 2.如何遵守协议 (1)类遵守协议 @protocol 类名:父类名 <协议名称1, ...