【转】HADOOP HDFS BALANCER介绍及经验总结
转自:http://www.aboutyun.com/thread-7354-1-1.html
- sh $HADOOP_HOME/bin/start-balancer.sh –t 10%
复制代码
这个命令中-t参数后面跟的是HDFS达到平衡状态的磁盘使用率偏差值。如果机器与机器之间磁盘使用率偏差小于10%,那么我们就认为HDFS集群已经达到了平衡的状态。
【转】HADOOP HDFS BALANCER介绍及经验总结的更多相关文章
- HADOOP HDFS BALANCER介绍及经验总结(转)
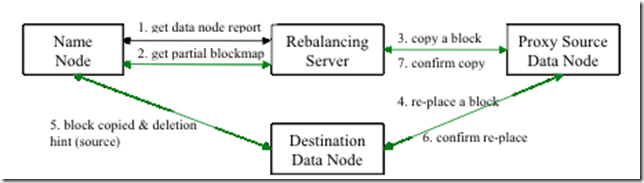
1.集群执行balancer命令,依旧不平衡的原因是什么?该如何解决? 2.尽量不在NameNode上执行start-balancer.sh的原因是什么? 集群平衡介绍 Hadoop的HDFS集群非常 ...
- 【转载】漫谈HADOOP HDFS BALANCER
Hadoop的HDFS集群非常容易出现机器与机器之间磁盘利用率不平衡的情况,比如集群中添加新的数据节点.当HDFS出现不平衡状况的时候,将引发很多问题,比如MR程序无法很好地利用本地计算的优势,机器之 ...
- 【Hadoop离线基础总结】HDFS入门介绍
HDFS入门介绍 概述 HDFS全称为Hadoop Distribute File System,也就是Hadoop分布式文件系统,是Hadoop的核心组件之一. 分布式文件系统是横跨在多台计算机上的 ...
- Hadoop记录-HDFS balancer配置
HDFS balancer配置(可通过CM配置)dfs.datanode.balance.max.concurrent.moves 并行移动的block数量,默认5 dfs.datanode.bala ...
- 【Hadoop离线基础总结】HDFS详细介绍
HDFS详细介绍 分布式文件系统设计思路 概述 只有一台机器时的文件查找:hello.txt /export/servers/hello.txt 如果有多台机器时的文件查找:hello.txt nod ...
- Hadoop HDFS分布式文件系统 常用命令汇总
引言:我们维护hadoop系统的时候,必不可少需要对HDFS分布式文件系统做操作,例如拷贝一个文件/目录,查看HDFS文件系统目录下的内容,删除HDFS文件系统中的内容(文件/目录),还有HDFS管理 ...
- Hadoop HDFS 用户指南
This document is a starting point for users working with Hadoop Distributed File System (HDFS) eithe ...
- Hadoop HDFS负载均衡
Hadoop HDFS负载均衡 转载请注明出处:http://www.cnblogs.com/BYRans/ Hadoop HDFS Hadoop 分布式文件系统(Hadoop Distributed ...
- sudo -u hdfs hdfs balancer出现异常 No lease on /system/balancer.id
16/06/02 20:34:05 INFO balancer.Balancer: namenodes = [hdfs://dlhtHadoop101:8022, hdfs://dlhtHadoop1 ...
随机推荐
- Object、Function、String、Array原生对象扩展方法
JavaScript原生对象的api有些情况下使用并不方便,考虑扩展基于Object.Function.String.Array扩展,参考了prototype.js的部分实现,做了提取和修改,分享下: ...
- 第7章 使用RAID与LVM磁盘阵列技术
章节简述: 您好,此章节为新增加的知识内容,正在努力的排版完善,预习2016年9月中旬完成,感谢您的支持,QQ群:340829. 7.1 磁盘冗余阵列 1988年由加利福尼亚大学伯克利分校发表的文章 ...
- 通过rails console执行sql语句
$ RAILS_ENV=production bundle exec rails c irb(main):008:0> r = ActiveRecord::Base.connection.exe ...
- 关于seajs
(这些文章都是从我的个人主页上粘贴过来的,大家也可以访问我的主页 www.iwangzheng.com) 最近经常听到各种JS前缀的名称,瞬间感觉自己弱爆了,啥都没用过呢,这么下去将来怎么嫁人呢. ...
- [POJ1003]Hangover
[POJ1003]Hangover 试题描述 How far can you make a stack of cards overhang a table? If you have one card, ...
- IOC原理解释
spring ioc它其实是一种降低对象耦合关系的设计思想,通常来说,我们在一个类调用另一个类的方法的时候,需要不断的new新的对象来调用该方法,类与类之间耦合度比较高,有了ioc容器以后,ico容器 ...
- CAS单点登录之mysql数据库用户验证及常见问题
前面已经介绍了CAS服务器的搭建,详情见:搭建CAS单点登录服务器.然而前面只是简单地介绍了服务器的搭建,其验证方式是原始的配置文件的方式,这显然不能满足日常的需求.下面介绍下通过mysql数据库认证 ...
- iOS xib中TableView创建的2种模式
在xcode 5.0中 用xib编辑tableview有2种模式,见下图 其中,dynamic prototype 动态原型 表示tableview会询问它指定的 data source获取数据,如果 ...
- 【JAVA、C++】LeetCode 004 Median of Two Sorted Arrays
There are two sorted arrays nums1 and nums2 of size m and n respectively. Find the median of the two ...
- Ubuntu 用户安装 MATE
MATE 是经典桌面 Gnome 2 的分支,该桌面按照 Windows 用户操作习惯设计,适合于 Windows 转投 Linux 的初级用户,MATE 做了功能改进和新增功能.如:增加窗口管理 ...