Python爬虫学习(2): httplib
httplib模块实现了HTTP和HTTPS的客户端部分,但是一般不直接使用,经常通过urllib来进行HTTP,HTTPS的相关操作。
如果需要查看其源代码可以通过查找命令定位:
find / -name "httplib.py"
整个请求过程的状态转移图如下所示:

httplib提供如下的类:
1. httplib.HTTPConnection(host[, port[, strict[, timeout[, source_address]]]])
一个HTTPConnection实例表示一次与HTTP server的连机事务,在实例化的时候至少需要一个主机地址。port参数如果没有指定会默认采用80端口。strict参数的默认值是false,当这个值为true的时候,如果状态行(status line)不是HTTP/1.0 or 1.1,则会引发BadStatusLine错误。timeout参数指定在多长时间后还未连接到主机则停止此联机行为。source_address参数是二元组形式(host,port),指定发起连接的客户机的IP和端口。
>>> h1 = httplib.HTTPConnection('www.cwi.nl')
>>> h2 = httplib.HTTPConnection('www.cwi.nl:80')
>>> h3 = httplib.HTTPConnection('www.cwi.nl', 80)
>>> h3 = httplib.HTTPConnection('www.cwi.nl', 80, timeout=10)
其包含如下几个方法:
1.1 HTTPConnection.request(method, url[, body[, headers]])
以method方法来访问url地址,body参数可以是需要发送的数据字符串,还可以是文件对象,其将会在发送完headers之后发送出去。headers参数对应HTTP headers中需要的内容。如果headers参数没有指定,则headers中的Content-Length会根据body的大小自动添加(字符串的长度或者是文件的大小)。
1.2 HTTPConnection.getresponse()
一般在调用request之后用来获取返回结果,此方法返回一个HTTPResponse对象。
注意: 在发送一个新的请求之前要先读取返回的结果,否则会出错。源文件中对应的部分如下:
# Note: if a prior response exists, then we *can* start a new request.
# We are not allowed to begin fetching the response to this new
# request, however, until that prior response is complete.
#
if self.__state == _CS_IDLE:
self.__state = _CS_REQ_STARTED
else:
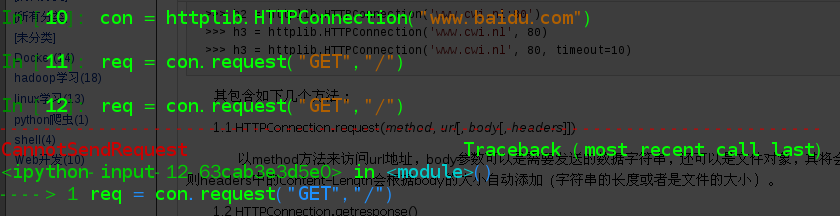
raise CannotSendRequest()
测试实例:
1.3 HTTPConnection.set_debuglevel(level)
设置调试级别(相关的调试信息会打印出来),默认值是0,表示不打印调试信息。
In [14]: con = httplib.HTTPConnection("www.baidu.com")
In [15]: con.set_debuglevel(1)
# 请求过程中会输出一些调式信息
In [16]: req = con.request("GET","/")
send: 'GET / HTTP/1.1\r\nHost: www.baidu.com\r\nAccept-Encoding: identity\r\n\r\n'
1.4 HTTPConnection.connect()
当HTTPConnection对象创建的时候自动连接到服务器
1.5 HTTPConnection.close()
你懂的
你除了直接调用request()方法来访问服务器,还可以以下边4步实现此功能:
1.6.1 HTTPConnection.putrequest(request, selector[, skip_host[, skip_accept_encoding]]):
这是连接到服务器之后的第一步操作
1.6.2 HTTPConnection.putheader(header, argument[, ...])
发送请求头
1.6.3 HTTPConnection.endheaders(message_body=None)
向服务器发送一空行表示请求头的结束。
1.6.4 HTTPConnection.send(data)
向服务器发送数据。应该在endheaders函数调用之后,getresponse函数之前调用。
2. httplib.HTTPSConnection(host[, port[, key_file[, cert_file[, strict[, timeout[, source_address[, context]]]]]]])
这是HTTPConnection的一个子类,通过SSL来和安全主机交互,采用的默认端口是443.如果参数context指定时候,这其此参数必须是ssl.SSLContext(描述SSL的各种信息)的实例。
key_file和cert_file参数已经弃用。
3. httplib.HTTPResponse(sock, debuglevel=0, strict=0)
这个类会在成功连接后返回,不会被用户直接初始化。
HTTPResponse.read([amt]):
返回响应结果,或者读取下amt个字节
In [23]: response = con.getresponse() In [24]: response.read(10)
Out[24]: '<!DOCTYPE '
HTTPResponse.getheader(name[, default])
获取指定文件头中指定的内容
In [26]: response.getheader("server")
Out[26]: 'BWS/1.1'
In [27]: response.getheader("date")
Out[27]: 'Mon, 17 Oct 2016 10:59:40 GMT'
In [28]: response.getheader("Date")
Out[28]: 'Mon, 17 Oct 2016 10:59:40 GMT'
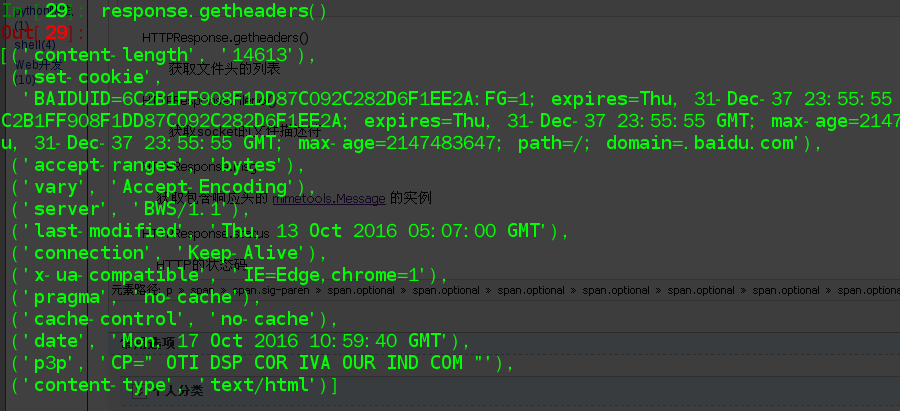
HTTPResponse.getheaders()
获取文件头的列表
HTTPResponse.fileno()
获取socket的文件描述符
HTTPResponse.msg-
获取包含响应头的
mimetools.Message的实例In [30]: message = response.msg
In [31]: message
Out[31]: <httplib.HTTPMessage instance at 0x39610e0>
# 获取响应头信息
In [33]: dict = message.dict
In [34]: dict
Out[34]:
{'accept-ranges': 'bytes',
'cache-control': 'no-cache',
'connection': 'Keep-Alive',
'content-length': '',
'content-type': 'text/html',
'date': 'Mon, 17 Oct 2016 10:59:40 GMT',
'last-modified': 'Thu, 13 Oct 2016 05:07:00 GMT',
'p3p': 'CP=" OTI DSP COR IVA OUR IND COM "',
'pragma': 'no-cache',
'server': 'BWS/1.1',
'set-cookie': 'BAIDUID=6C2B1FF908F1DD87C092C282D6F1EE2A:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com, BIDUPSID=6C2B1FF908F1DD87C092C282D6F1EE2A; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com, PSTM=1476701980; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com',
'vary': 'Accept-Encoding',
'x-ua-compatible': 'IE=Edge,chrome=1'}
HTTPResponse.status
HTTP的状态码
HTTPResponse.reason
In [35]: response.reason
Out[35]: 'OK'
4. httplib.HTTPMessage
这个类中存储HTTP的响应头信息。其通过 mimetools.Message实现,并提供处理头的使用函数,不会被用户实例化。
参考地址: https://docs.python.org/2/library/httplib.html#httplib.HTTPSConnection
Python爬虫学习(2): httplib的更多相关文章
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- python爬虫学习 —— 总目录
开篇 作为一个C党,接触python之后学习了爬虫. 和AC算法题的快感类似,从网络上爬取各种数据也很有意思. 准备写一系列文章,整理一下学习历程,也给后来者提供一点便利. 我是目录 听说你叫爬虫 - ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫学习:四、headers和data的获取
之前在学习爬虫时,偶尔会遇到一些问题是有些网站需要登录后才能爬取内容,有的网站会识别是否是由浏览器发出的请求. 一.headers的获取 就以博客园的首页为例:http://www.cnblogs.c ...
- Python爬虫学习:二、爬虫的初步尝试
我使用的编辑器是IDLE,版本为Python2.7.11,Windows平台. 本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:二.爬虫的初步尝试 1.尝试抓取指定网页 ...
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
- python爬虫学习视频资料免费送,用起来非常666
当我们浏览网页的时候,经常会看到像下面这些好看的图片,你是否想把这些图片保存下载下来. 我们最常规的做法就是通过鼠标右键,选择另存为.但有些图片点击鼠标右键的时候并没有另存为选项,或者你可以通过截图工 ...
- python爬虫学习笔记(一)——环境配置(windows系统)
在进行python爬虫学习前,需要进行如下准备工作: python3+pip官方配置 1.Anaconda(推荐,包括python和相关库) [推荐地址:清华镜像] https://mirrors ...
- [转]《Python爬虫学习系列教程》
<Python爬虫学习系列教程>学习笔记 http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多. ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
随机推荐
- Day4-python基础之函数
本次学习内容: 字典查询快的原因 字符编码 函数定义 局部变量.全局变量 返回值 嵌套函数 递归(二分查找) 三元运算 map lamba 函数式编程 高阶函数 内置函数 字典查询快的原因: 字典占用 ...
- Windows中创建桌面快捷方式
Windows中创建桌面快捷方式 -------------- -------------- -------------- --------------
- Google Map API V3开发(4)
Google Map API V3开发(1) Google Map API V3开发(2) Google Map API V3开发(3) Google Map API V3开发(4) Google M ...
- 什么?你还不会写JQuery 插件
前言 如今做web开发,jquery 几乎是必不可少的,就连vs神器在2010版本开始将Jquery 及ui 内置web项目里了.至于使用jquery好处这里就不再赘述了,用过的都知道.今天我们来讨论 ...
- MyBatis学习总结(一)——MyBatis快速入门
一.Mybatis介绍 MyBatis是一个支持普通SQL查询,存储过程和高级映射的优秀持久层框架.MyBatis消除了几乎所有的JDBC代码和参数的手工设置以及对结果集的检索封装.MyBatis可以 ...
- 查看修改Linux时区和时间
查看/修改Linux时区和时间 一.时区 1. 查看当前时区 date -R 2. 修改设置时区 方法(1) tzselect 方法(2) 仅限于RedHat Linux 和 CentOS timec ...
- C语言基础(7)-float,double,long double类型
1.定义方式 3.14这个就是一个浮点常量,3f是一个浮点类型的常量 float a;//定义了一个浮点类型的小数变量,名字叫a double b;//定义了一个double类型的变量,名字叫b lo ...
- VBA笔记(二)——基础语法
数据类型 VBA提供了15种标准数据类型,具体见下表: 变量 Sub 变量学习() 'Dim 变量名 As 数据类型 Dim str1 As String '声明定长的String变量 '使用变量类型 ...
- hzwer模拟赛 Hzwer的陨石
题目描述 Description 经过不懈的努力,Hzwer召唤了很多陨石.已知Hzwer的地图上共有n个区域,且一开始的时候第i个陨石掉在了第i个区域.有电力喷射背包的ndsf很自豪,他认为搬陨石很 ...
- tomcat相关问题
动态资源:需要转换成静态资源后再响应给客户端,例如:jsp.servlet,其他语言的动态资源有:asp.php 静态资源:无需转发即可直接响应给客户端,例如:html.css.javascript ...